
目录
什么是逻辑斯蒂(Logistic)回归?
1.线性回归函数
2. 逻辑函数(Sigmoid函数)
3. Logistic回归函数
Logistic回归分类器
梯度上升算法
python实现梯度上升算法
1.普通梯度上升算法(在每次更新回归系数(最优参数)时,都需要遍历整个数据集。)
2.随机梯度上升算法
【实战】用Logistic回归模型诊断糖尿病
Logistic回归的一般过程
数据样本收集
数据处理
Sigmoid函数
梯度上升算法寻找**优化系数
训练Logistic回归模型并测试
计算测试结果的正确率
设置步长、迭代次数等参数开始测试
测试结果
Logistic回归模型总结
什么是逻辑斯蒂(Logistic)回归?
由于逻辑斯蒂回归的原理是用逻辑函数把线性回归的结果(-∞,∞)映射到(0,1),故先介绍线性回归函数和逻辑函数。
1.线性回归函数
线性回归函数的数学表达式:
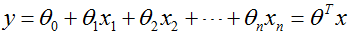
其中xi是自变量,y是因变量,y的值域为(-∞,∞),θ0是常数项,θi(i=1,2,...,n)是待求系数,不同的权重θi反映了自变量对因变量不同的贡献程度。我们初中学过的一元一次方程:y=a+bx,这种只包括一个自变量和一个因变量的回归分析称为一元线性回归分析。初中学过的二元一次方程:y = a+b1x1+b2x2,三元一次方程:y = a+b1x1+b2x2+b3x3,这种回归分析中包括两个或两个以上自变量的回归分析,称为多元线性回归分析。不管是一元线性回归分析还是多元线性回归分析,都是线性回归分析。
2. 逻辑函数(Sigmoid函数)
Sigmoid函数数学表达式:
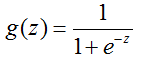
Sigmoid函数的图像:

从图像可以看到当x为0时,Sigmoid函数值为0.5。随着x的增大,对应的Sigmoid函数的值将逼近于1;而随着x的减小,Sigmoid函数的值将逼近于0,而Sigmoid函数的值域在(0,1)之间,而概率P也是在0到1之间,因此我们可以把Sigmoid的值域和概率联系起来
3. Logistic回归函数
Logistic回归的原理是用Sigmoid函数把线性回归的结果从(-∞,∞)映射到(0,1)。我们用公式描述上面这句话:
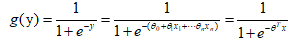
把线性回归函数的结果y,放到sigmod函数中去,就构造了Logistic回归函数。 由y的值域和sigmod函数的值域知,在Logistic回归函数中用sigmod函数把线性回归的结果(-∞,∞)映射到(0,1),得到的这个结果类似一个概率值。
我们转换一下逻辑回归函数,过程如下:
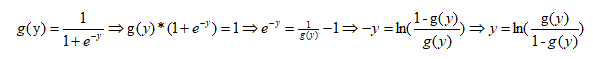

因此Logistic回归属于对数线性模型,也被称为对数几率回归。
Logistic回归分类器
为了实现logistic回归分类器,我们可以在每个分类特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和带入sigmoid函数中。进而得到一个范围在0-1之间的数值。最后设定一个阈值,在大于阈值时判定为1,否则判定为0。以上便是逻辑斯谛回归算法是思想,公式就是分类器的函数形式。 确定了logistic分类函数,有了分类函数,我们输入特征向量就可以得出实例属于某个类别的概率。但这里有个问题,权重![]() (回归系数)我们是不确定的。我们需要求得**的回归系数,从而使得分类器尽可能的精确。 **回归系数
(回归系数)我们是不确定的。我们需要求得**的回归系数,从而使得分类器尽可能的精确。 **回归系数![]() 的确定,可以用极大似然法、牛顿法、最优化方法(也就是梯度上升和梯度下降法)。下面重点介绍梯度上升法实现Logistic回归分类。
的确定,可以用极大似然法、牛顿法、最优化方法(也就是梯度上升和梯度下降法)。下面重点介绍梯度上升法实现Logistic回归分类。
梯度上升算法
梯度上升法基于的思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为∇ ,则函数f(x,y)的梯度由下式表示:

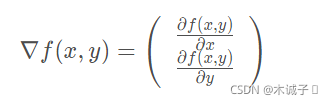
这个梯度意味着要沿x的方向移动![]() ,沿y的方向移动
,沿y的方向移动![]() 其中,函数f(x,y)必须要在待计算的点上有定义并且可微。一个具体的函数例子见下图。
其中,函数f(x,y)必须要在待计算的点上有定义并且可微。一个具体的函数例子见下图。
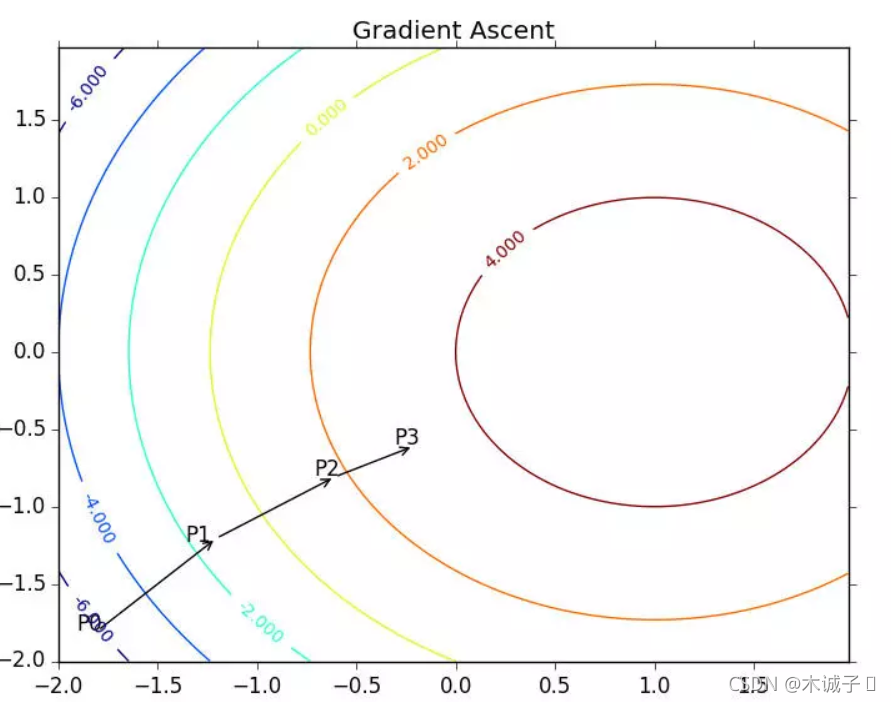
梯度上升算法到达每个点后都会重新估计移动的方向。从P0开始,计算完该点的梯度,函数就根据梯度移动到下一点P1。在P1点,梯度再次被重新计算,并沿新的梯度方向移动到P2.如此循环迭代,知道满足通知条件。迭代的过程中,梯度算子总是保证我们能选取到**的移动方向
上图中的梯度上升算法沿梯度方向移动了一步。可以看到,梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为步长,记作α \alphaα。用向量来表示的话,梯度上升算法的迭代公式如下:
![]()
该公式将一直迭代执行,直至达到某个停止条件为止,b比如迭代次数达到某个值或者算法达到某个可以允许的误差范围。如果是梯度下降法,那就是按梯度上升的反方向迭代公式即可,对应的公式如下: ![]()
python实现梯度上升算法
1.普通梯度上升算法(在每次更新回归系数(最优参数)时,都需要遍历整个数据集。)
def gradAscent(dataMatIn, classLabels):#梯度上升:dataMatIn:2维NumPy数组,100*3矩阵;classLabels:类别标签,1*100行向量 dataMatrix = mat(dataMatIn)#特征矩阵 labelMat = mat(classLabels).transpose()#类标签矩阵:100*1列向量 m,n = shape(dataMatrix) alpha = 0.001#向目标移动的步长 maxCycles = 500#迭代次数 weights = ones((n,1))#n*1列向量:3行1列 for k in range(maxCycles): h = sigmoid(dataMatrix*weights)#100*3*3*1=100*1,dataMatrix * weights代表不止一次乘积计算,事实上包含了300次乘积 error = (labelMat - h)#真实类别与预测类别的差值 weights = weights + alpha * dataMatrix.transpose()* error#w:=w+α▽wf(w) return weights讯享网
2.随机梯度上升算法
普通梯度上升算法,在每次更新回归系数时都需要遍历整个数据集,在数十亿样本上该算法复杂度太高。改进方法:随机梯度上升算法:一次仅用一个样本点更新回归系数。)
讯享网def stocGradAscent0(dataMatrix, classLabels): m, n = shape(dataMatrix) alpha = 0.01 weights = ones(n) for i in range(m): h = sigmoid(sum(dataMatrix[i] * weights)) error = classLabels[i] - h weights = weights + alpha * error * dataMatrix[i] return weights
现在我们用一个简单的数据集测试一下这两个算法的分类效果。
数据集testSet有100条样本,两个属性x1,x2
完整测试代码
#coding:utf-8 from numpy import * import matplotlib.pyplot as plt class func: def loadDataSet(self): dataMat = [] labelMat = [] fr = open('testSet.txt') for line in fr.readlines(): # 矩阵的格式【标签,X1,X2】 lineArr = line.strip().split() #插入X1,X2,以及初始化的回归系数(权重),全部设为1.0 dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])]) #插入标签, #必须转换成int类型,因为只有两类 labelMat.append(int(lineArr[2])) return dataMat,labelMat # 使用sigmoid函数进行分类 def sigmoid(self,inX): return 1.0/(1+exp(-inX)) #普通梯度上升 #使用梯度上升算法进行优化,找到**优化系数 #dataMatIn是训练集,三维矩阵,(-0.017612 14.053064 0) #classLabels是类别标签,数值型行向量,需要转置为列向量,取值是0,1 def gradAscent(self,dataMatIn,classLabels): dataMatrix = mat(dataMatIn) #转换为Numpy矩阵数据类型 labelMat = mat(classLabels).transpose() #转置矩阵,便于加权相乘 m,n = shape(dataMatrix) #得到矩阵的行列数,便于设定权重向量的维度 alpha = 0.001 maxCycles = 500 weights = ones((n,1)) #返回一个被1填满的 n * 1 矩阵,作为初始化权重 for k in range(maxCycles): h = self.sigmoid(dataMatrix*weights) erro = (labelMat - h) #labelMat是使用当前回归系数得到的的标签,labelMat是训练集的标签,取值是0,1 weights = weights + alpha * dataMatrix.transpose( ) * erro #根据使用当前权重计算的值与初始值的误差,更改weight, #按照误差的方向调整回归系数 return weights #随机梯度上升 def stocGradAscent0(dataMatrix, classLabels): m, n = shape(dataMatrix) alpha = 0.01 weights = ones(n) for i in range(m): h = sigmoid(sum(dataMatrix[i] * weights)) error = classLabels[i] - h weights = weights + alpha * error * dataMatrix[i] return weights def plotBestFit(self,wei): weights = wei.getA() dataMat,labelMat = self.loadDataSet() dataArr = array(dataMat) n = shape(dataMat)[0] xcord1 = [] ycord1 = [] xcord2 = [] ycord2 = [] #根据标签不同分为两种颜色画图,易于分辨 for i in range(n): if int(labelMat[i]) == 1: xcord1.append(dataArr[i,1]) ycord1.append(dataArr[i,2]) else : xcord2.append(dataArr[i, 1]) ycord2.append(dataArr[i, 2]) fig = plt.figure() ax = fig.add_subplot(111) #将画布分为一行一列的画布,并从第一块开始画 ax.scatter(xcord1,ycord1,s=30,c='red',marker = 's') #scatter散开 ax.scatter(xcord2,ycord2,s=30,c='green') x = arange(-3.0,3.0,1) y = (-weights[0]-weights[1]*x)/weights[2] ax.plot(x,y) plt.xlabel('x1') plt.ylabel('x2') plt.show() if __name__=="__main__": #普通梯度上升 logRegres = func() dataArr,labelMat = logRegres.loadDataSet() weights = logRegres.gradAscent(dataArr,labelMat) logRegres.plotBestFit(weights) #随机梯度上升 logRegres = func() dataArr,labelMat = logRegres.loadDataSet() weights =stocGradAscent0(array(dataArr),labelMat) plotBestFit(weights)运行结果
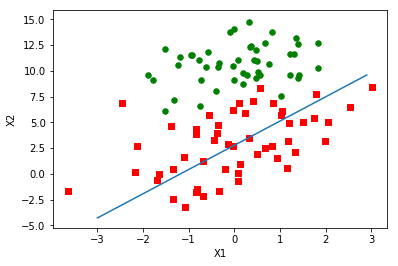
普通梯度上升
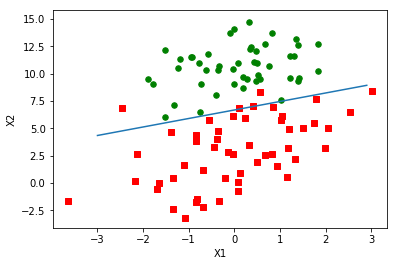
分类结果是很不错,虽然这里是简单且数据集很小,但是这个方法却需要大量的计算(300次乘法)。
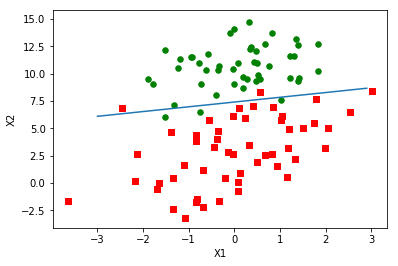
随机梯度上升
拟合效果没有普通梯度上升算法好。这里的分类器错分了三分之一的样本。但是普通梯度上升算法的计算量较大,时间较长,其结果是在整个数据集上迭代了500次才能得到的。而随机梯度上升在整个数据集上只需迭代200次,所以现在还不能分辨哪个算法更好。 通常判断优化算法优劣的可靠方法是看它是否收敛,也就是说参数是否达到稳定值,是否不断地变化。下图展示随机梯度上升算法在 200 次迭代过程中回归系数的变化情况。其中的系数2,也就是 X2 只经过了 50 次迭代就达到了稳定值,但系数 1 和 0 则需要更多次的迭代。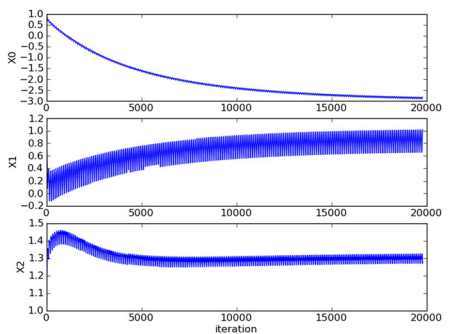
针对欠拟合这个问题,我们对随机梯度上升算法进行优化
讯享网# 随机梯度上升算法(优化) def stocGradAscent1(dataMatrix, classLabels, numIter=150): m,n = shape(dataMatrix) weights = ones(n) for j in range(numIter): # [0, 1, 2 .. m-1] dataIndex = list(range(m)) for i in range(m): alpha = 4/(1.0+j+i)+0.0001 randIndex = int(random.uniform(0,len(dataIndex))) # sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn h = sigmoid(sum(dataMatrix[randIndex]*weights)) error = classLabels[randIndex] - h # print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex] weights = weights + alpha * error * dataMatrix[randIndex] del(dataIndex[randIndex]) return weights
运行后效果
现在随机的alpha比固定的alpha收敛速度更快。主要归功于:1.stocGradAscent1()的样本随机机制避免周期性波动;2.stocGradAscent1()收敛更快。这次的随机梯度上升算法仅对数据集做了20次遍历,而之前的普通梯度上升算法是500次。

因此,通常数据集较小时,选用梯度上升算法就能达到我们想要的数据分类效果;当数据集较大时,为有效地减少了计算量,提高收敛速度,我们选用随机梯度上升算法。
【实战】用Logistic回归模型诊断糖尿病
Logistic回归的一般过程
(1)收集数据: 可以使用任何方法。
(2)准备数据: 由于需要进行距离计算,因此要求数据类型为数值型。当然,结构化数据格式**。
(3)分析数据: 采用任意方法对数据进行分析。
(4)训练算法: 大部分时间将用于训练,训练的目的是为了找到**的分类回归系数。
(5)测试算法: 一旦训练阶段完成,分类将很快完成。
(6)使用算法: 首先,需要输入一些数据,并将其转换成对应的结构化数值;然后,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;最后,可以在输出的类别上做一些其他分析工作。
数据样本收集
本次数据集一共765条样本,每条数据样本记录着健康人员和糖尿病患者的8个身体状况特征值,接下来我们使用Logistic回归模型对样本进行分类。 数据收集来源:http://archive.ics.uci.edu/ml/index.php) 1是糖尿病患者,0是健康人员。
数据处理
我们将样本数据分成五组,分别用这五组样本作为测试集,当某组作为测试集时,就用除该组以外的样本作训练集,然后计算出五组样本的正确率,最后取平均正确率
from random import seed from random import randrange from csv import reader from math import exp def load_csv(filename): dataset = list() with open(filename, 'r') as f: #读取样本数据保存到dataset中 csv_reader = reader(f) for row in csv_reader: if not row: continue else: dataset.append(row) return dataset def str_column_to_float(dataset,column): #将样本数据转换成float类型 for row in dataset: row[column] = float(row[column].strip()) def dataset_minmax(dataset): minmax = list() for i in range(len(dataset[0])): col_values = [row[i] for row in dataset] value_min = min(col_values) value_max = max(col_values) minmax.append([value_min, value_max]) return minmax def normalize_dataset(dataset, minmax): #归一化处理样本数据 for row in dataset: for i in range(len(row)): row[i] = (row[i] - minmax[i][0])/(minmax[i][1] - minmax[i][0]) def cross_validation_split(dataset, n_folds): #将数据样本分成n_folds组 dataset_split = list() dataset_copy = list(dataset) fold_size = int(len(dataset) / n_folds) for i in range(n_folds): fold = list() while len(fold) < fold_size: index = randrange(len(dataset_copy)) fold.append(dataset_copy.pop(index)) dataset_split.append(fold) return dataset_splitSigmoid函数
讯享网def predict(row, coefficients): #Sigmoid函数变形 yhat = coefficients[0] for i in range(len(row)-1): yhat += coefficients[i + 1] * row[i] return 1.0 / (1.0 + exp(-yhat))
梯度上升算法寻找**优化系数
def logistic_regression(train, test, l_rate, n_epoch): predictions = list() coef = coefficients_sgd(train, l_rate, n_epoch) for row in test: yhat = predict(row, coef) yhat = round(yhat) predictions.append(yhat) return(predictions) def coefficients_sgd(train, l_rate, n_epoch): #使用梯度下降算法进行优化,找到**优化系数 coef = [0.0 for i in range(len(train[0]))] for epoch in range(n_epoch): for row in train: yhat = predict(row, coef) error = row[-1] - yhat coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat) for i in range(len(row)-1): coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i] return coef训练Logistic回归模型并测试
讯享网def evaluate_algorithm(dataset, algorithm, n_folds, *args): #训练Logistic回归模型 folds = cross_validation_split(dataset, n_folds) scores = list() for fold in folds: train_set = list(folds) train_set.remove(fold) train_set = sum(train_set, []) test_set = list() for row in fold: row_copy = list(row) test_set.append(row_copy) row_copy[-1] = None predicted = algorithm(train_set, test_set, *args) actual = [row[-1] for row in fold] accuracy = accuracy_metric(actual, predicted) scores.append(accuracy) return scores
计算测试结果的正确率
def accuracy_metric(actual, predicted): #计算Logistic回归模型分类正确率 correct = 0 for i in range(len(actual)): if actual[i] == predicted[i]: correct += 1 return correct / float(len(actual)) * 100.0设置步长、迭代次数等参数开始测试
讯享网if __name__=="__main__": seed(1) filename = 'pima-indians-diabetes.csv' #数据样本名称 dataset = load_csv(filename) for i in range(len(dataset[0])): str_column_to_float(dataset, i) minmax = dataset_minmax(dataset) normalize_dataset(dataset, minmax) n_folds = 5 #样本分组 l_rate = 0.1 #移动步长,也就是学习速率,控制更新的幅度 n_epoch = 1000 #最大迭代次数 scores = evaluate_algorithm(dataset, logistic_regression, n_folds, l_rate, n_epoch) print('五组测试样本的正确率: %s' % scores) print('平均正确率: %.3f%%' % (sum(scores)/float(len(scores))))
测试结果

该Logistic回归模型诊断糖尿病的正确率是:78.301%
Logistic回归模型总结
优点:
- 原理简单,模型清晰,操作高效,背后的概率的推导过程经得住推敲,在研究中,通常以 Logistic 回归模型作为基准,再尝试使用更复杂的算法,可以在大数据场景中使用。
- 使用online learning的方式更新轻松更新参数,不需要重新训练整个模型。
- 基于概率建模,输出值落在0到1之间,并且有概率意义。
- 求出来的参数θi 代表每个特征对输出的影响,可解释性强。
- 无需事先假设数据分布 ,可得到“类别”的近似概率预测(概率值还可用于后续应 用),可直接应用现有数值优化算法(如牛顿法)求取最优解, 具有快速、高效的特点
缺点:
- 对数据依赖性强,很多时候需要做特征工程,且主要用来解决线性可分问题。
- 因为它本质上是一个线性的分类器,所以处理不好特征之间相关的情况,对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转,正好变负号。
- logit变换过程是非线性的,在两端随着变化率微乎其微,而中间的变化很大,很敏感。 导致很多区间的变量变化对目标概率的影响没有区分度,很难确定阀值。
- 当特征空间很大时,性能不好。
- 容易欠拟合,精度不高。
应用场景:
- 在P2P,汽车金融等领域,根据申请人的提供的资料,预测其违约的可能性大小,进而决定是否给其贷款。
- 电商平台根据用于购买记录预测用户下一次是否会购买某件商品。
- (天涯,bbs,微博,豆瓣短评等舆论平台做情感分类器。如根据某网友对某些特定主题的历史评论数据,预测其下次对某类型的主题是否会给出正面的评论。
- 在医疗领域,根据病人症状,预测其肿瘤是良性的还是恶性的。
- 根据CT,流行病学,旅行史,检测试剂结果等特点预测某位疑似病人是否真感染新型冠状病毒。
- 在精准营销领域,预测某个产品的收益。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/70862.html