
一、MFCC
在任意一个Automatic speech recognition 系统中,第一步就是提取特征。换句话说,我们需要把音频信号中具有辨识性的成分提取出来,然后把其他的乱七八糟的信息扔掉,例如背景噪声啊,情绪啊等等。

搞清语音是怎么产生的对于我们理解语音有很大帮助。人通过声道产生声音,声道的shape(形状?)决定了发出怎样的声音。声道的shape包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素phoneme进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而MFCCs就是一种准确描述这个包络的一种特征。
MFCCs(Mel Frequency Cepstral Coefficents)是一种在自动语音和说话人识别中广泛使用的特征。它是在1980年由Davis和Mermelstein搞出来的。从那时起。在语音识别领域,MFCCs在人工特征方面可谓是鹤立鸡群,一枝独秀,从未被超越啊(至于说Deep Learning的特征学习那是后话了)。
好,到这里,我们提到了一个很重要的关键词:声道的形状,然后知道它很重要,还知道它可以在语音短时功率谱的包络中显示出来。哎,那什么是功率谱?什么是包络?什么是MFCCs?它为什么有效?如何得到?下面咱们慢慢道来。
一、声谱图(Spectrogram)
我们处理的是语音信号,那么如何去描述它很重要。因为不同的描述方式放映它不同的信息。那怎样的描述方式才利于我们观测,利于我们理解呢?这里我们先来了解一个叫声谱图的东西。
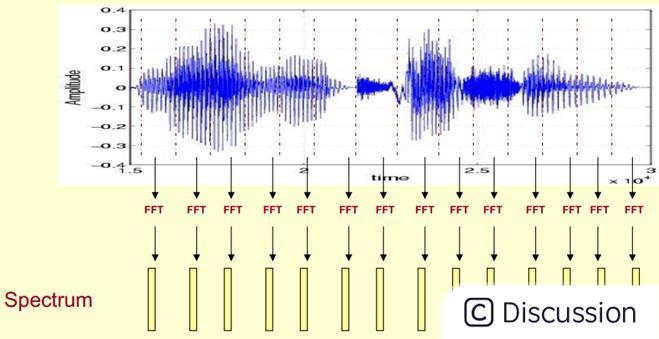
这里,这段语音被分为很多帧,每帧语音都对应于一个频谱(通过短时FFT计算) ,频谱表示频率与能量的关系。在实际使用中,频谱图有三种,即线性振幅谱、对数振幅谱、自功率谱(对数振幅谱中各谱线的振幅都作了对数计算,所以其纵坐标的单位是dB(分贝)。这个变换的目的是使那些振幅较低的成分相对高振幅成分得以拉高,以便观察掩盖在低幅噪声中的周期信号)。

我们先将其中一帧语音的频谱通过坐标表示出来,如上图左。现在我们将左边的频谱旋转90度。得到中间的图。然后把这些幅度映射到一个灰度级表示(也可以理解为将连续的幅度量化为256个量化值?),0表示黑,255表示白色。幅度值越大,相应的区域越黑。这样就得到了最右边的图。那为什么要这样呢?为的是增加时间这个维度,这样就可以显示一段语音而不是一帧语音的频谱,而且可以直观的看到静态和动态的信息。优点稍后呈上。
这样我们会得到一个随着时间变化的频谱图,这个就是描述语音信号的spectrogram声谱图。

下图是一段语音的声谱图,很黑的地方就是频谱图中的峰值(共振峰formants)。

那我们为什么要在声谱图中表示语音呢?
首先,音素(Phones)的属性可以更好的在这里面观察出来。另外,通过观察共振峰和它们的转变可以更好的识别声音。隐马尔科夫模型(Hidden Markov Models)就是隐含地对声谱图进行建模以达到好的识别性能。还有一个作用就是它可以直观的评估TTS系统(text to speech)的好坏,直接对比合成的语音和自然的语音声谱图的匹配度即可。
| 通过对语音进行分帧进行时频变换,得到每一帧的FFT频谱再将各帧频谱按照时间顺序排列起来,得到时间-频率-能量分布图。很直观的表现出语音信号随时间的频率中心的变化。 | | ----------------------------------------------------------------------------------- |
二、倒谱分析(Cepstrum Analysis)
下面是一个语音的频谱图。峰值就表示语音的主要频率成分,我们把这些峰值称为共振峰(formants) ,而共振峰就是携带了声音的辨识属性(就是个人身份证一样)。所以它特别重要。用它就可以识别不同的声音。
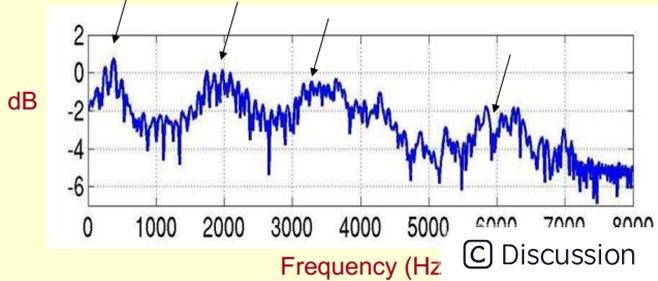
既然它那么重要,那我们就是需要把它提取出来!我们要提取的不仅仅是共振峰的位置,还得提取它们转变的过程。所以我们提取的是频谱的包络(Spectral Envelope)。这包络就是一条连接这些共振峰点的平滑曲线。

我们可以这么理解,将原始的频谱由两部分组成:包络和频谱的细节。这里用到的是对数频谱,所以单位是dB。那现在我们需要把这两部分分离开,这样我们就可以得到包络了。

那怎么把他们分离开呢?也就是,怎么在给定log X[k]的基础上,求得log H[k] 和 log E[k]以满足log X[k] = log H[k] + log E[k]呢?
为了达到这个目标,我们需要Play a Mathematical Trick。这个Trick是什么呢?就是对频谱做FFT。在频谱上做傅里叶变换就相当于逆傅里叶变换Inverse FFT (IFFT) 。需要注意的一点是,我们是在频谱的对数域上面处理的,这也属于Trick的一部分。这时候,在对数频谱上面做IFFT就相当于在一个伪频率(pseudo-frequency)坐标轴上面描述信号。

由上面这个图我们可以看到,包络是主要是低频成分(这时候需要转变思维,这时候的横轴就不要看成是频率了,咱们可以看成时间),我们把它看成是一个每秒4个周期的正弦信号。这样我们在伪坐标轴上面的4Hz的地方给它一个峰值。而频谱的细节部分主要是高频。我们把它看成是一个每秒100个周期的正弦信号。这样我们在伪坐标轴上面的100Hz的地方给它一个峰值。
把它俩叠加起来就是原来的频谱信号了。

在实际中咱们已经知道log X[k],所以我们可以得到了x[k]。那么由图可以知道,h[k]是x[k]的低频部分,那么我们将x[k]通过一个低通滤波器就可以得到h[k]了!没错,到这里咱们就可以将它们分离开了,得到了我们想要的h[k],也就是频谱的包络。
x[k]实际上就是倒谱Cepstrum(这个是一个新造出来的词,把频谱的单词spectrum的前面四个字母顺序倒过来就是倒谱的单词了) 。而我们所关心的h[k]就是倒谱的低频部分。h[k]描述了频谱的包络,它在语音识别中被广泛用于描述特征。
那现在总结下倒谱分析,它实际上是这样一个过程:
1)将原语音信号经过傅里叶变换得到频谱:X[k]=H[k]E[k];
只考虑幅度就是:|X[k] |=|H[k]||E[k] |;
2)我们在两边取对数:log||X[k] ||= log ||H[k] ||+ log ||E[k] ||。
3)再在两边取逆傅里叶变换得到:x[k]=h[k]+e[k]。
这实际上有个专业的名字叫做同态信号处理。它的目的是将非线性问题转化为线性问题的处理方法。对应上面,原来的语音信号实际上是一个卷性信号(声道相当于一个线性时不变系统,声音的产生可以理解为一个激励通过这个系统),第一步通过卷积将其变成了乘性信号(时域的卷积相当于频域的乘积)。第二步通过取对数将乘性信号转化为加性信号,第三步进行逆变换,使其恢复为卷性信号。这时候,虽然前后均是时域序列,但它们所处的离散时域显然不同,所以后者称为倒谱频域。
总结下,倒谱(cepstrum)就是一种信号的傅里叶变换经对数运算后再进行傅里叶反变换得到的谱。它的计算过程如下:

二、DWT
A-DTW必要性
语音识别的匹配需要解决的一个关键问题是说话人对同一个词的两次发音不可能完全相同,这些差异不仅包括音强的大小、频谱的偏移,更重要的是发音时音节的长短不可能完全相同,而且两次发音的音节往往不存在线性对应关系。


设参考模板有M帧矢量{R(1),R(2),…R(m),…,R(M)},R(m)为第m帧的语音特征矢量,测试模板有N帧矢量{T(1),T(2),…T(n),…,T(N)},T(n)是第n帧的语音特征矢量。d(T(in),R(im))表示T中第in帧特征与R中im帧特征之间的欧几里得距离。直接匹配是假设测试模板和参考模板长度相等,即in=im;线性时间规整技术假设说话速度是按不同说话单元的发音长度等比例分布的,即 。这两种假设其实都不符合实际语音的发音情况,我们需要一种更加符合实际情况的非线性时间规整技术,也就是DTW算法。三种匹配模式的对比:
。这两种假设其实都不符合实际语音的发音情况,我们需要一种更加符合实际情况的非线性时间规整技术,也就是DTW算法。三种匹配模式的对比:

B-DTW思路
首先还是介绍下DTW的思想:假设现在有一个标准的参考模板R,是一个M维的向量,即R={R(1),R(2),……,R(m),……,R(M)},每个分量可以是一个数或者是一个更小的向量。现在有一个才测试的模板T,是一个N维向量,即T={T(1),T(2),……,T(n),……,T(N)}同样每个分量可以是一个数或者是一个更小的向量,注意M不一定等于N,但是每个分量的维数应该相同。
由于M不一定等于N,现在要计算R和T的相似度,就不能用以前的欧式距离等类似的度量方法了。那用什么方法呢?DTW就是为了解决这个问题而产生的。
首先我们应该知道R中的一个分量R(m)和T中的一个分量T(n)的维数是相同的,它们之间可以计算相似度(即距离)。在运用DTW前,我们要首先计算R的每一个分量和T中的每一个分量之间的距离,形成一个M*N的矩阵。(为了方便,行数用将标准模板的维数M,列数为待测模板的维数N)。
然后下面的步骤该怎么计算呢?用个例子来看看。
这个例子中假设标准模板R为字母ABCDEF(6个),测试模板T为1234(4个)。R和T中各元素之间的距离已经给出。如下:

既然是模板匹配,所以各分量的先后匹配顺序已经确定了,虽然不是一一对应的。现在题目的目的是要计算出测试模板T和标准模板R之间的距离。因为2个模板的长度不同,所以其对应匹配的关系有很多种,我们需要找出其中距离最短的那条匹配路径。现假设题目满足如下的约束:当从一个方格((i-1,j-1)或者(i-1,j)或者(i,j-1))中到下一个方格(i,j),如果是横着或者竖着的话其距离为d(i,j),如果是斜着对角线过来的则是2d(i,j).其约束条件如下图像所示:

其中g(i,j)表示2个模板都从起始分量逐次匹配,已经到了M中的i分量和T中的j分量,并且匹配到此步是2个模板之间的距离。并且都是在前一次匹配的结果上加d(i,j)或者2d(i,j),然后取最小值。
所以我们将所有的匹配步骤标注后如下:

怎么得来的呢?比如说g(1,1)=4, 当然前提都假设是g(0,0)=0,就是说g(1,1)=g(0,0)+2d(1,1)=0+2*2=4.
g(2,2)=9是一样的道理。首先如果从g(1,2)来算的话是g(2,2)=g(1,2)+d(2,2)=5+4=9,因为是竖着上去的。
如果从g(2,1)来算的话是g(2,2)=g(2,1)+d(2,2)=7+4=11,因为是横着往右走的。
如果从g(1,1)来算的话,g(2,2)=g(1,1)+2*d(2,2)=4+2*4=12.因为是斜着过去的。
综上所述,取最小值为9. 所有g(2,2)=9.
当然在这之前要计算出g(1,1),g(2,1),g(1,2).因此计算g(I,j)也是有一定顺序的。
其基本顺序可以体现在如下:
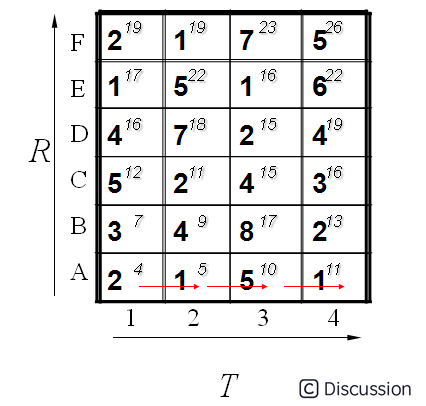
计算了第一排,其中每一个红色的箭头表示最小值来源的那个方向。当计算了第二排后的结果如下:

最后都算完了的结果如下:

到此为止,我们已经得到了答案,即2个模板直接的距离为26. 我们还可以通过回溯找到最短距离的路径,通过箭头方向反推回去。如下所示:

到这里,估计大家动手算一下就会明白了,其实这个就是动态规划的思路:

三、代码
close all; chos=0; possibility=5;messaggio='Insert the number of set: each set determins a class. This set should include a number of speech for each person, with some variations in expression and in the lighting.';while chos~=possibility, chos=menu('speaker identification System','Select speech signal and add to database','Select speech signal for speaker identification','Delete database',... 'speech signal: visualization','Exit'); %-------------------------------------------------------------------------- %-------------------------------------------------------------------------- %-------------------------------------------------------------------------- % Calculate gmm of the speech and Add to Database if chos==1 clc; close all; selezionato=0; while selezionato==0 [namefile,pathname]=uigetfile({'.wav','speech Files (.wav)'},'Chose speech signal'); if namefile~=0selezionato=1; else disp('Select a speech signal'); end end filt=melfilter(150,300,15); fr1=frm(strcat(pathname,namefile),16,8000,1); mc2=train(fr1,filt,20); mc2=mc2(3:18,:); mc1=banshengsin(mc2); s1=pitch(pathname,namefile); a=length(s1); b=length(mc1(1,:)); if a>b s1(b+1:a)=[]; else s1(a+1:b)=0; end mc1=[mc1;s1]; [im is ip]=init(mc1,16); [nim1 nis1 nip1 times]=gmm(im,is,ip,mc1); data=struct('name',{},'means',{},'cov',{},'prob',{},'pitch',{}); if (exist('speech_database.dat')==2) load('speech_database.dat','-mat'); speaker_number=speaker_number+1; prompt={'Enter the name of speaker to add'};
讯享网name='the speaker '; numlines=1; defaultanswer={'no one'}; answer=inputdlg(prompt,name,numlines,defaultanswer); data(speakernumber).name=answer{1,1}; data(speakernumber).means=nim1; data(speakernumber).cov=readcov(nis1); data(speakernumber).prob=nip1; data(speakernumber).pitch=s1; save('speechdatabase.dat','data','speakernumber','-append'); else speakernumber=1;
prompt={'Enter the name of speaker to add'}; name='the speaker '; numlines=1; defaultanswer={'no one'}; answer=inputdlg(prompt,name,numlines,defaultanswer); data(speakernumber).name=answer{1,1}; data(speakernumber).means=nim1; data(speakernumber).cov=readcov(nis1); data(speakernumber).prob=nip1; data(speakernumber).pitch=s1; save('speechdatabase.dat','data','speaker_number'); end讯享网message=strcat('speechsignal was succesfully added to database. speaker is.. ',answer{1,1}) msgbox(message,'speechsignal DataBase','help') end %-------------------------------------------------------------------------- %-------------------------------------------------------------------------- %-------------------------------------------------------------------------- % speaker recognition if chos==2 clc; close all; selezionato=0; while selezionato==0 [namefile,pathname]=uigetfile({'*.wav','speech Files (*.wav)'},'Chose speech signal'); if namefile~=0 selezionato=1; else disp('Select a speech signal'); end end if (exist('speech_database.dat')==2) load('speech_database.dat','-mat'); filt=melfilter(150,300,15);fr=frm(strcat(pathname,namefile),16,8000,3); l=length(fr(1,:)); nosp=length(data); k=0; b=0; r=nosp; while(r~=1) r=floor(r/2); k=k+1; end p(2,nosp)=0;p(1,1)=0; for i=1:nosp p(2,i)=i; end mc4=train(fr,filt,20); mc4=mc4(3:18,:); mc=banshengsin(mc4); pitch2=pitch(pathname,namefile); a=length(pitch2); b=length(mc(1,:)); if a>b pitch2(b+1:a)=[]; else pitch2(a+1:b)=0; end mc=[mc;pitch2]; coff=length(mc(:,1)); o=length(mc(1,:)); frameparts=struct('frame',{}); s=mod(l,k); y=floor(l/k); if s==0 for i=1:k frameparts(i).frame(coff,y)=0; end else for i=1:s frameparts(i).frame(coff,y+1)=0; end for i=s+1:k frameparts(i).frame(coff,y)=0; end end for r=1:k count=1; for i=r:k:l frameparts(r).frame(:,count)=mc(:,i); count=count+1; end end c=length(data); for i=1:k % tic p1=ident2(frameparts(i).frame,filt,data,p); % toc p=upd_pr(p,p1); p=nmax1(p); end p2=p(1)/o; scores=zeros(nosp,1); for i=1:nosp pitch1=data(i).pitch'; % tic scores(i,1)=myDTW(pitch2,pitch1(1:length(pitch2))); % toc end scores; [m,n]=sort(scores);b=p(2,1); if or((p2>-25),b==n) nm=data(b).name; message=strcat('The speaker is : ',nm); msgbox(message,'DataBase Info','help'); else message='the speaker is a stranger.'; msgbox(message,'DataBase Info','help'); end else message='DataBase is empty. No check is possible.'; msgbox(message,'speech DataBase Error','warn');
endend%删除全部数据,或只删除一个人的数据
if chos==3 clc; close all; if (exist('speechdatabase.dat')==2) load('speechdatabase.dat','-mat'); button = questdlg('which speaker do you want to delete?',... 'Genie Question',... 'all','specified','all'); if strcmp(button,'all') delete('speechdatabase.dat'); msgbox('Database was succesfully removed from the current directory.','Database removed','help'); else prompt={'Enter the name of speaker you want to delete'}; name='specified speaker delete'; numlines=1; defaultanswer={'0'}; answer=inputdlg(prompt,name,numlines,defaultanswer); nspeaker=length(data); names=cell(1,nspeaker); for i=1:nspeaker names{1,i}=data(i).name; end [a,b]=ismember(answer{1,1},names); if a==0 warndlg('the speaker is not exist.','Warining') else data(b)=[]; speakernumber=length(data); save('speechdatabase.dat','data','speakernumber','-append'); message=strcat('you have succesfully removed The speaker : ',answer{1,1}); msgbox(message,'specified speaker removed','help'); end end else warndlg('Database is empty.',' Warning ') end end if chos==4 clc; close all; selezionato=0; while selezionato==0 [namefile,pathname]=uigetfile({'.wav','speech signal (.wav)'},'Chose speech signal'); if namefile~=0 [x,fs]=wavread(strcat(pathname,namefile)); selezionato=1; else disp('Select a speech signal'); end讯享网end figure('Name','Selected speech signal'); plot(x); pause; x=trim(x); plot(x); pause; filt=melfilter(150,300,15); fr1=frm(strcat(pathname,namefile),16,8000,1); size(fr1) mc2=train(fr1,filt,20); colormap(1-gray); imagesc(mc2); pause; mc2=mc2(3:18,:); imagesc(mc2); pause; y=bansin(16) plot(y); pause; mc1=banshengsin(mc2); imagesc(mc1); pause; % cor=CorrelogramArray(fr1,x,256); % [pixels frames] = size(cor); % colormap(1-gray); %for j=1:frames % imagesc(reshape(cor(:,j),pixels/256,256)); % drawnow; %end % pitch=CorrelogramPitch(cor,256,8000); % plot(pitch) s11=pitch(pathname,namefile); plot(s11); pause;%[im is ip]=init(mc1,16); % [nim1 nis1 nip1 times]=gmm(im,is,ip,mc1);endend ```


版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/69409.html