
引言
语法分析的主要任务:根据给定的文法,识别输入句子的各个成分,从而构造出句子的分析树
大部分程序设计语言的语法构造可以用CFG来描述,CFG以token作为终结符
大部分语法分析器都期望文法是无二义性的,否则,就不能为一个句子构造唯一的语法分析树
语法分析的种类

讯享网
自顶向下分析:从分析树的顶部(根节点)向底部(叶节点)构造分析树;从文法开始符号S推导出串w
自底向上的分析:从分析树的底部(叶节点)向顶部(根节点)构造分析树;将一个串w归约为文法开始符号S
最高效的自顶向下和自底向上方法智能处理某些文法子类,但是其中的某些子类,特别是LL和LR文法,其表达能力足以描述线代程序设计的大部分语法构造
4.1 自顶向下的分析
1、概述
可以看成是从文法开始符号S推导出词串w的过程

推导的每一步,都需要做两个选择:替换当前句型中的哪个非终结符;用该非终结符的哪个候选式进行替换
2、最右推导与最右推导
(1)最左推导
在最左推导中,总是选择每个句型的最左非终结符进行替换

如果S=>*lmα,则称α是当前文法的最左句型。
(2)最右推导
在最右推导中,总是选择每个句型的最右非终结符进行替换

在自底向上的分析中,总是采用最左规约方式,因此把最左规约成为规范规约,而最右推导相应地称为规范推导
(3)最左推导和最右推导的唯一性

3、自顶下的语法
(1)自顶向下的语法分析采用最左推导方式
总是选择每个句型的最左非终结符进行替换
根据输入流中的下一个终结符,选择最左非终结符的一个候选式

(2)自顶向下语法分析的通用形式
递归下降分析
由一组过程组成,每个过程对应一个非终结符
从文法开始符号S对应的过程开始,其中递归调用文法中其它非终结符对应的过程。如果S对应的过程体恰好扫描了整个输入串,则完成语法分析

(3)自顶向下分析过程中的问题
问题1:同一个非终结符的多个候选式存在共同前缀,将导致回溯现象

问题2:左递归文法会使递归下降分析器陷入无限循环

4、消除左递归
(1)消除直接左递归
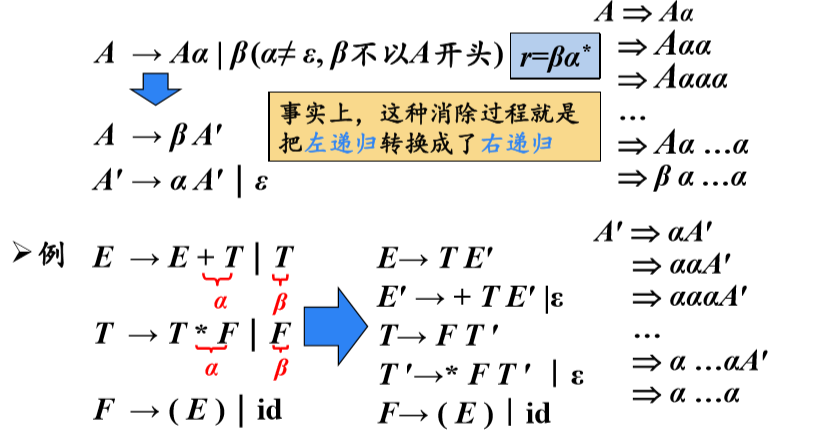
一般形式

(2)消除间接左递归

(3)消除左递归算法

5、提取左公因子


6、预测分析
4.2 预测分析法
1、LL(1)文法
- 每个产生式的右部都以终结符开始
- 同一非终结符的各个候选式的首终结符都不同
- S_文法不含ε产生式
例:


是么时候会用ε产生式
如果当前某非终结符A与当前输入符a不匹配时,则存在A→ε,可以通过检查a是否可以出现A的后面,来决定是否使用产生式A→ε(若文法中无A→ε,则应报错)
非终结符的后继符号集
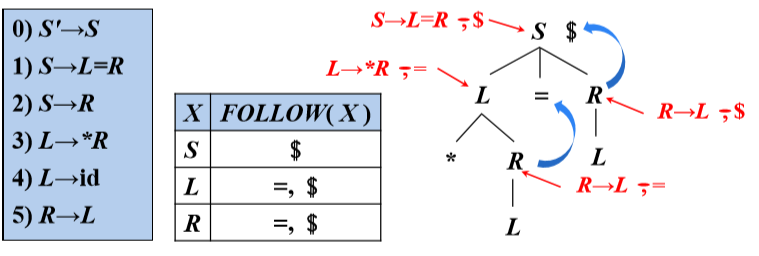
可能在某个句型中紧跟在A后边的终结符a的集合,记为FOLLOW(A)
FOLLOW(A)={a| S =>* αAaβ, a∈VT,α,β∈(VT∪VN) }
如果A是某个句型的最右符号,则将结束符“$”添加到FOLLOW(A)*中

产生式的可选集
产生式A→β的可选集是指可以选用该产生式进行推导时对应的输入符号的集合,记为SELECT( A→β )
SELECT( A→aβ ) = { a }
SELECT( A→ε )=FOLLOW( A )
q_文法
- 每个产生式的右部或为ε,或以汇终结符开始
- 具有相同左部的产生式有不相交的可选集
- q_文法不含右部以非终结符打头的产生式
串首终结符集
串首的第一个符号,并且是终结符。简称串首终结符
给定一个文法符号串α,α的串首终结符*FIRST(α)*被定义为可以从α推导出的所有串首终结符构成的集合。如果α=>*ε,那么ε也在FIRST(α)中

计算文法符号X的FIRST(X)
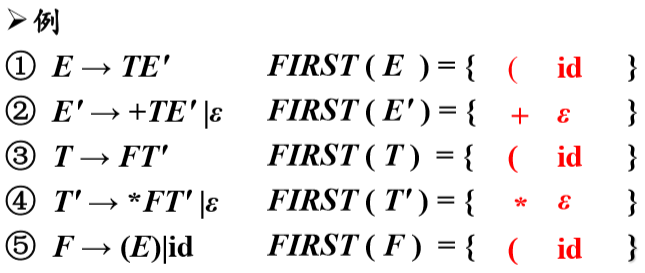
算法
不断应用下列规则,直到没有新的终结符或ε可以被加入到任何FIRST集合中为止
- 如果X是一个终结符,那么FIRST(X) = {X}
- 如果X是一个非终结符,且X→Y1…Yk ∈ P(k>=1),那么如果对于某个i,a在FIRST (Yi ) 中且ε 在所有的 FIRST(Y1) , … , FIRST(Yi-1)中(即Y1…Yi-1=>* ε ),就把a加入 到FIRST( X )中。如果对于所有的 j = 1,2, . . . , k,ε在 FIRST(Yj)中,那么将ε加入到FIRST( X )
- 如果X→ε∈P,那么将ε加入到FIRST( X )中
计算串X1X2 …Xn的FIRST 集合
- 向FIRST(X1X2…Xn)加入FIRST(X1)中所有的非ε符号
- 如果ε在FIRST(X1)中,再加入FIRST(X2)中的所有非ε符号;如果ε在FIRST(X1)和FIRST(X2)中,再加入FIRST(X3)中的所有非ε符号,以此类推
- 最后,如果对所有的i,ε都在FIRST(Xi)中,那么将ε加入到FIRST(X1X2…Xn) 中
产生式A→α的可选集
产生式A→α的可选集SELECT
- 如果 ε∉FIRST(α), 那么SELECT(A→α)= FIRST(α)
- 如果 ε∈FIRST(α), 那么SELECT(A→α)=( FIRST(α)-{ε} )∪FOLLOW(A)
LL(1)文法
文法G是LL(1)的,当且仅当G的任意两个具有相同左部的产生式A → α | β 满足下面的条件:

- 不存在终结符a使得α和β都能够推导出以a开头的串
- α和β至多有一个能推导出ε
- 如果β=>ε,则FIRST (α)∩FOLLOW(A) =Φ;如果 α=> ε,则FIRST (β)∩FOLLOW(A) =Φ;
同一个非终结符的各个产生式的可选集互不相交
可以为LL(1)文法构造预测分析器
第一个“L”表示从左向右扫描输入
第二个“L”表示产生最左推导
“1”表示在每一步中只需要向前看一个输入符号来决定语法分析动作
计算非终结符A的FOLLOW(A)

算法
不断应用下列规则,直到没有新的终结符可以被加 入到任何FOLLOW集合中为止
- 将 放 入 F O L L O W ( S ) 中 , 其 中 S 是 开 始 符 号 , 放入FOLLOW( S )中,其中S是开始符号, 放入FOLLOW(S)中,其中S是开始符号,是输入右端的结束标记
- 如果存在一个产生式A→αBβ,那么FIRST ( β )中除ε 之外的所有符号都在FOLLOW( B )中
- 如果存在一个产生式A→αB,或存在产生式A→αBβ且FIRST ( β ) 包含ε,那么 FOLLOW( A )中的所有符号都在FOLLOW( B )
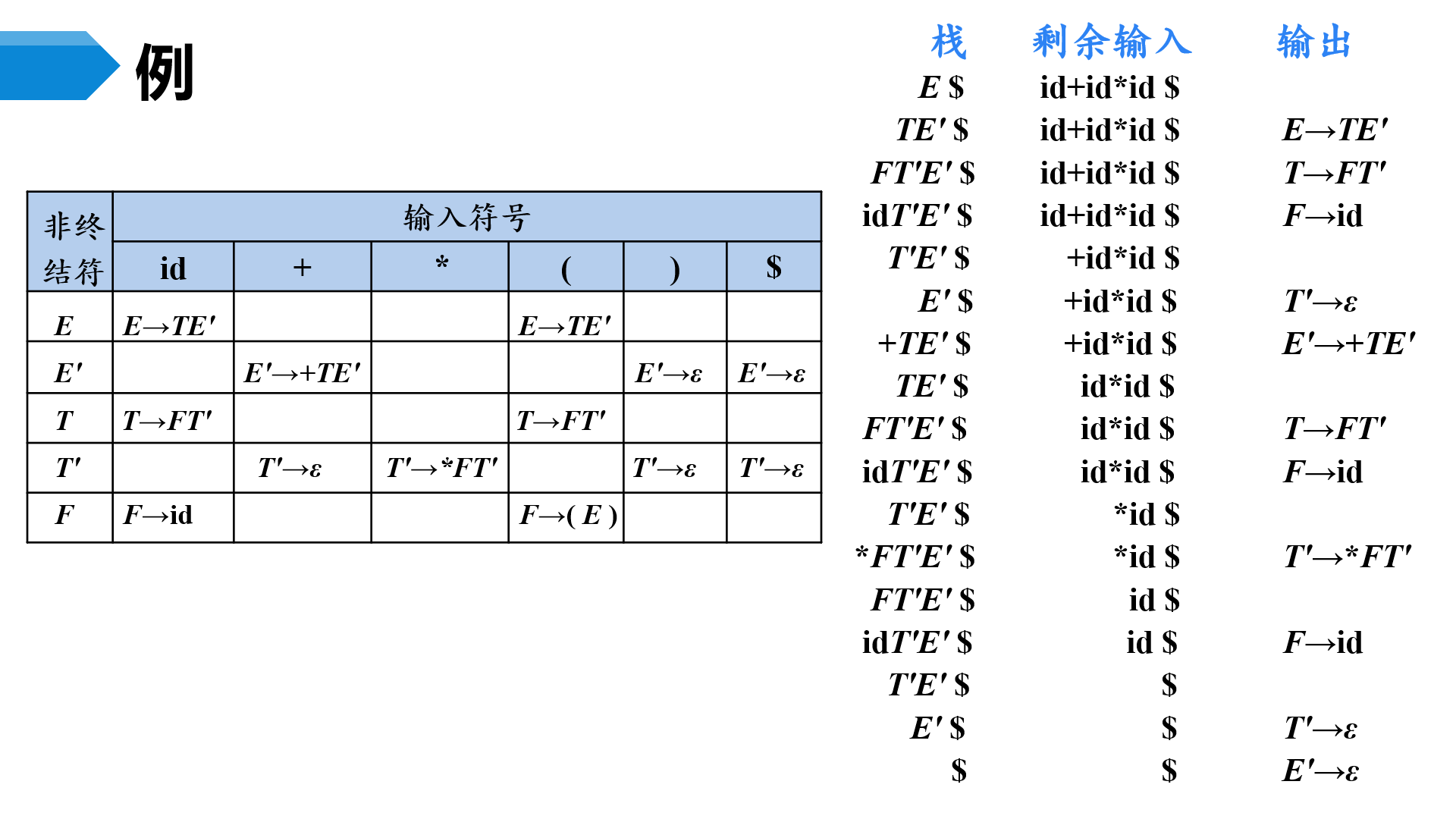
例:表达式文法各产生式的SELECT集

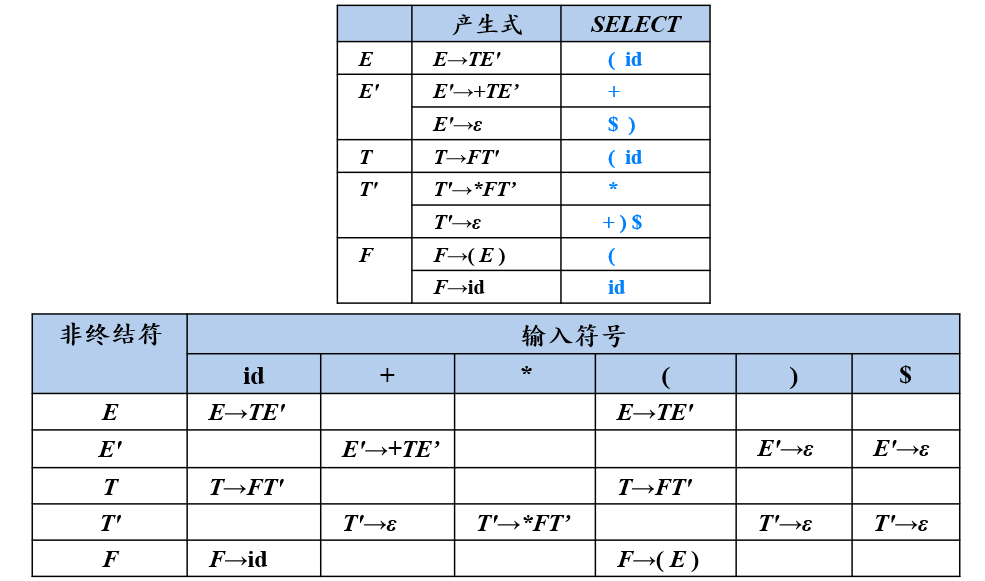
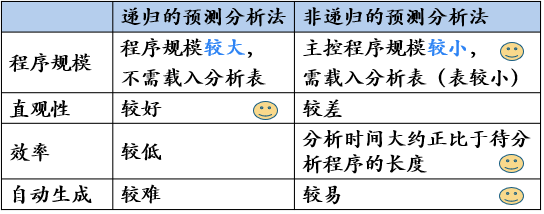
LL(1)文法的分析方法
- 递归的预测分析法
- 非递归的预测分析法
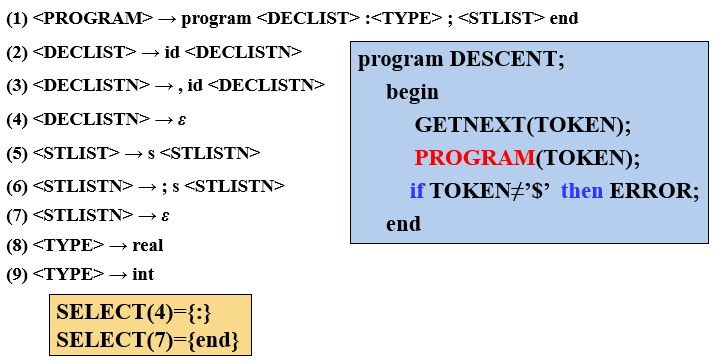
2、递归的预测分析法
递归的预测分析是指:在递归下降分析中,根据预测分析表进行产生式的选择。根据每个非终结符的产生式LL(1)文法的预测分析表,为每个非终结符编写对应的过程。

例如:






3、非递归的预测分析法
非递归的预测分析不需要为每个非终结符编写递归下降过程,而是根据预测分析表构造一个自动机,也叫做表驱动的预测分析。
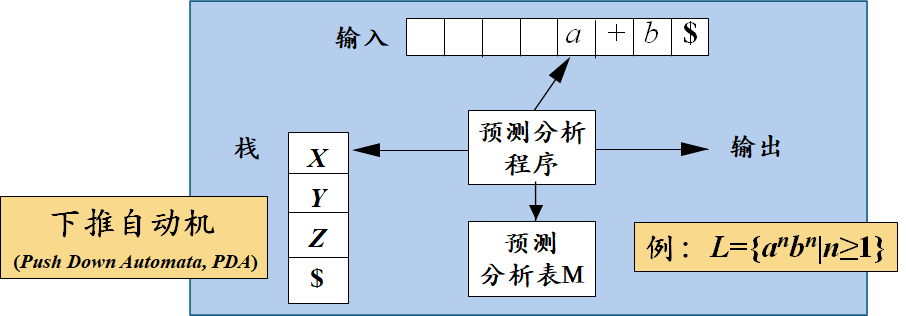
输入:一个串w和文法G的分析表M
输出:如果w在L(G)中,输出w的最左推导;否则给出错误指示
方法:最初,语法分析器的格局如下:输入缓冲区中是w$,G的开始符号位于栈顶,其下面是 $。下面的程序使用预测分析表M生成了处理这个输入的预测分析过程。

对比
预测分析法实现步骤
- 构造文法
- 改造文法:消除二义性、消除左递归、消除回溯
- 求每个变量的FIRST集和FOLLOW集,从而求得每个候选式的SELECT集
- 检查是不是LL(1)文法。若是,构造预测分析表
- 对于递归的预测分析,根据预测分析表为每一个非终结符编写一个过程;对于非递归的预测分析,实现表驱动的预测分析算法
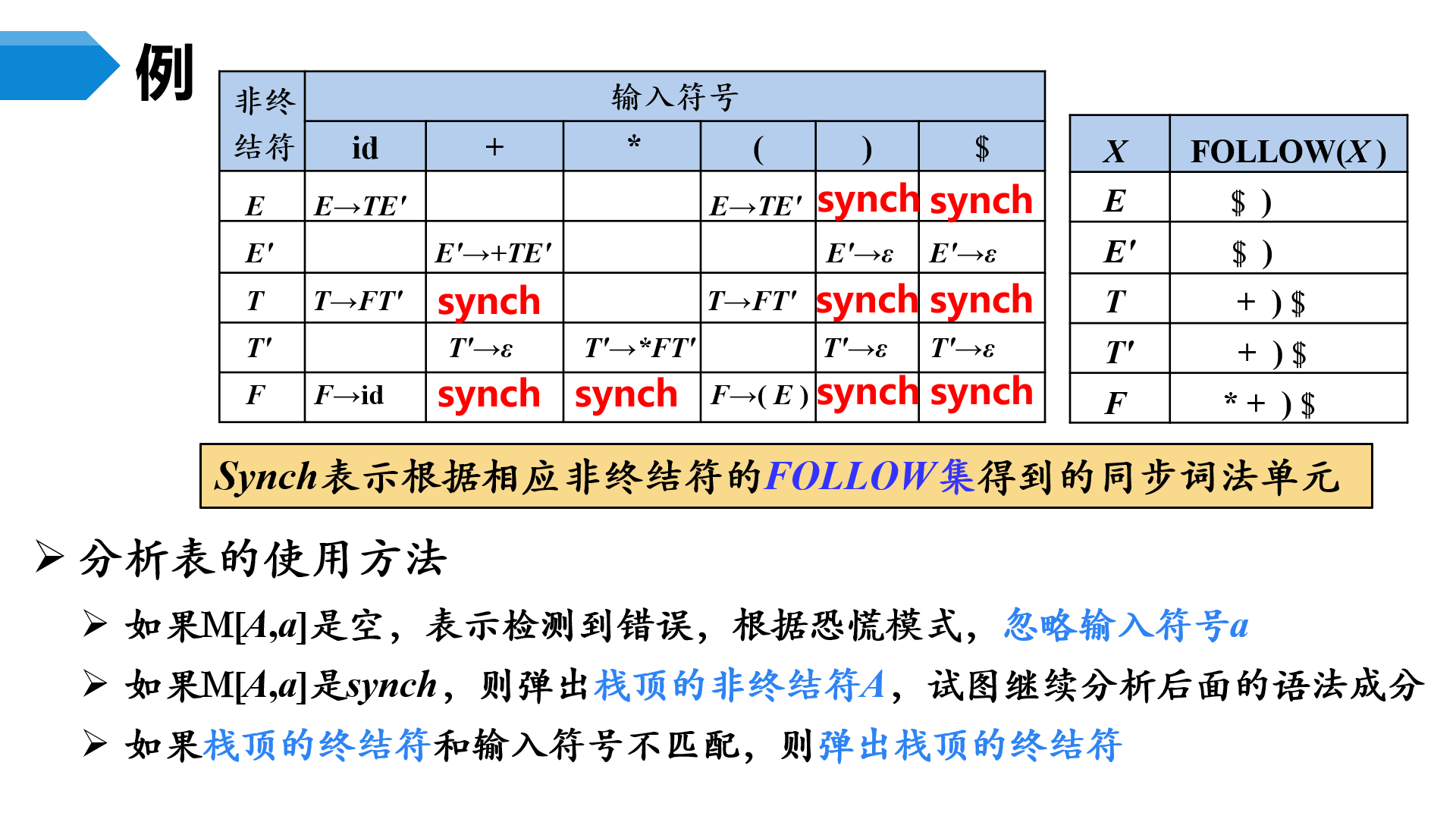
4、预测分析中的错误恢复
(1)错误检查
- 栈顶的终结符和当前输入符号不匹配
- 栈顶非终结符与当前输入符号在预测分析表对应的项中的信息为空
(2)错误恢复
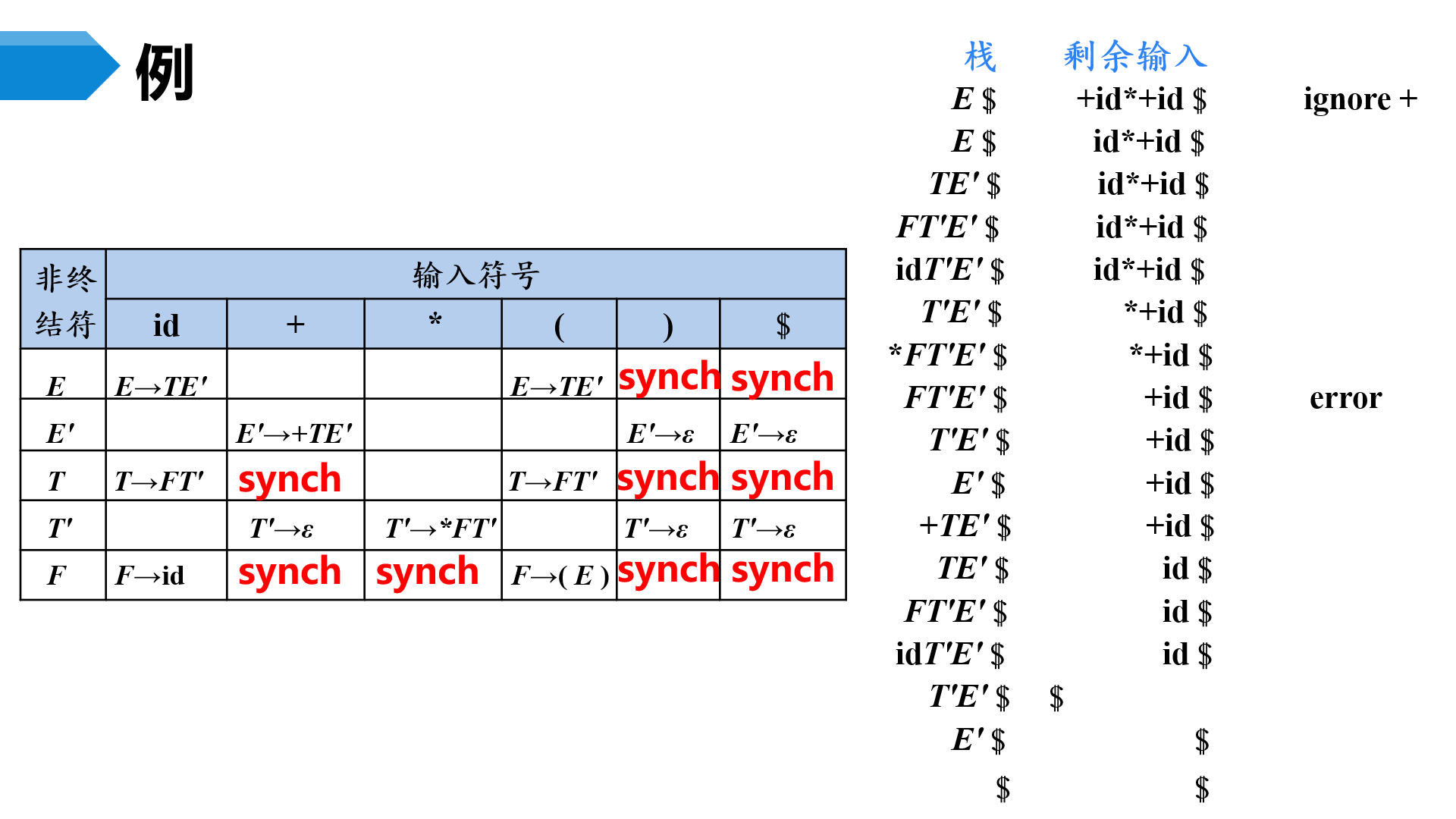
恐慌模式
忽略输入中的一些符号,知道输入中出现由设计者选定的同步词法单元集合中的某个词法单元。其效果依赖于同步集合的选取。集合的选取应该使得语法分析器能从实际遇到的错误中快速恢复。例如可以把FOLLOW(A)中的所有终结符放入非终结符A的同步记号集合
如果终结符在栈顶而不能匹配,一个简单的办法就是弹出此终结符
4.3 自底向上的分析
1、移入规约分析的概念
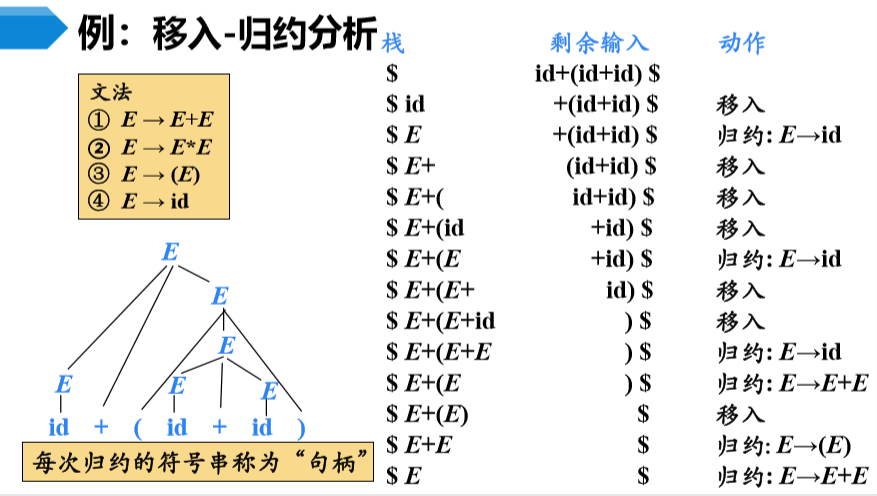
从分析树底部(叶节点)向顶部(根节点)方向构造分析树
可以看成是将输入串w归约为文法开始符号S的过程
自顶向下的书法分析采用最左推导方式,自底向上的语法分析财通最左规约方式(反向构造最右推导)
自底向上语法分析的通用框架:移入-规约分析
2、移入-规约分析的工作过程
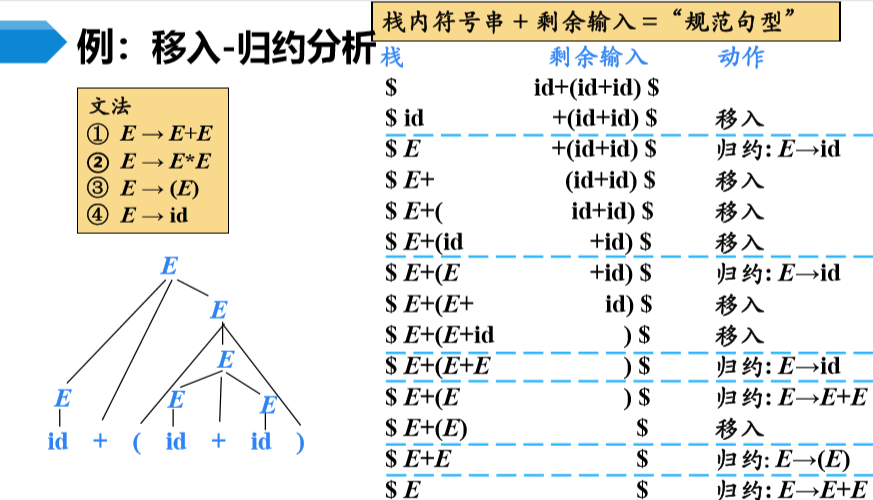
在对输入串的依次从左到右扫描过程中,语法分析器将零个或多个输入符号移入到栈的顶端,直到它可以对栈顶的一个文法符号串β进行归约为止
然后,它将β归约为某个产生式的左部
语法分析器不断地重复这个循环,直到它检测到一个语法错误,或者栈中包含了开始符号且输入缓冲区为空(当进入这样的格局时,语法分析器停止运行,并宣称完成了语法分析)为止
3、移入-归约分析器可采取的四种动作
移入:将下一个输入符号移到栈的顶端
归约:被归约的符号串的右端必然处于栈顶。语法分析器在栈中确定这个串的左端,并决定用哪个非终结符来替换这个串
接收:宣布语法分析过程成功完成
报错:发现一个语法错误,并调用错误恢复子例程
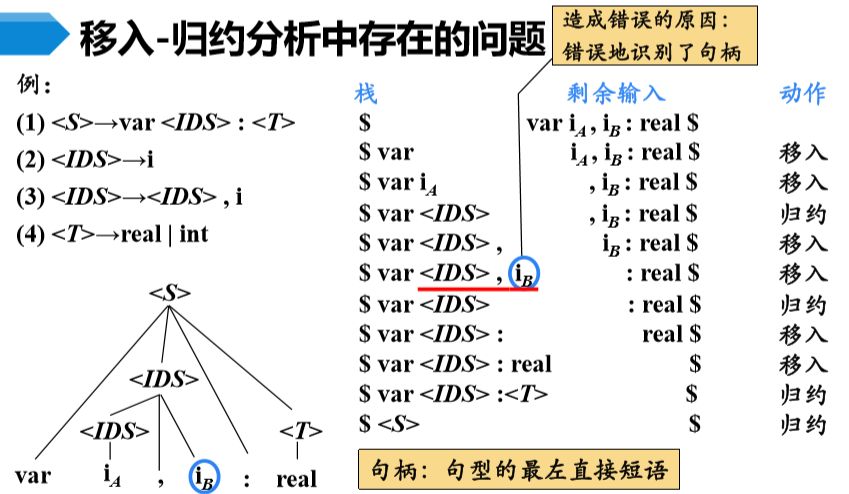
4、移入-归约分析中存在的问题
4.4 LR分析法
1、概述
LR文法是最大的、可以构造出相应移入-归约语法分析器的文法类
- L:对输入进行从左到右的扫描
- R:反向构造出一个最右推导序列
LR(k)分析:需要向前查看k个输入符号的LR分析,其中k = 0和k = 1这两种情况具有实践意义,当省略(k)时,表示k = 1
2、LR分析法的基本原理
自底向上分析的关键问题是如何正确地识别句柄
句柄是逐步形成的,用“状态”表示句柄识别的进展程度

3、LR分析器(自动机)的总体结构
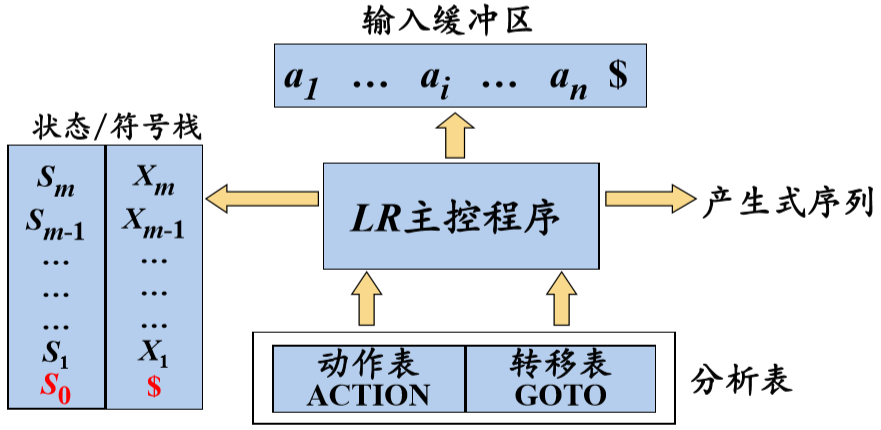
4、LR分析表的结构
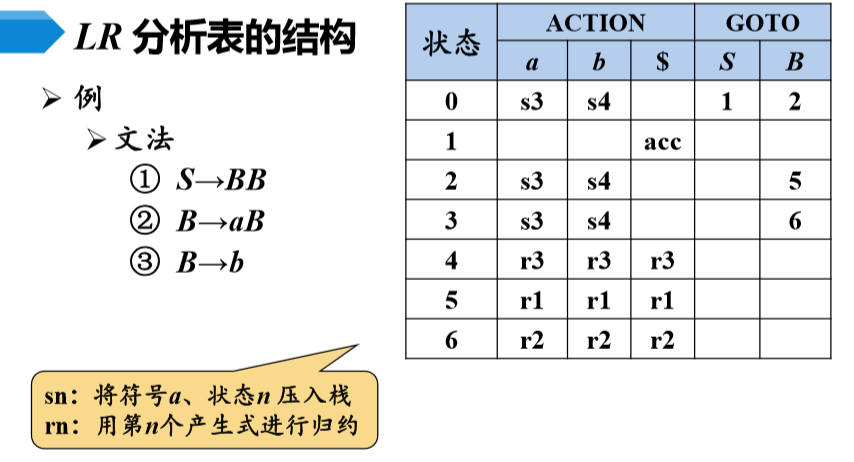
4、LR分析器的工作过程


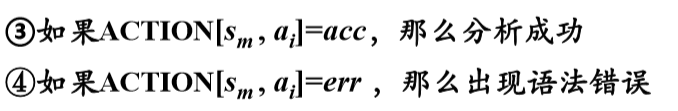
5、LR分析算法
输入:串w和LR语法分析表,该表描述了文法G的ACTION函数和GOTO函数。
输出:如果w在L(G)中,则输出w的自底向上语法分析过程中的归约步骤;否则给出一个错误指示。
方法:初始时,语法分析器栈中的内容为初始状态s0,输入缓冲区中的内容为w$。然后语法分析器执行下面的程序:

6、构造给定文法的LR分析表
(1)LR(0)分析
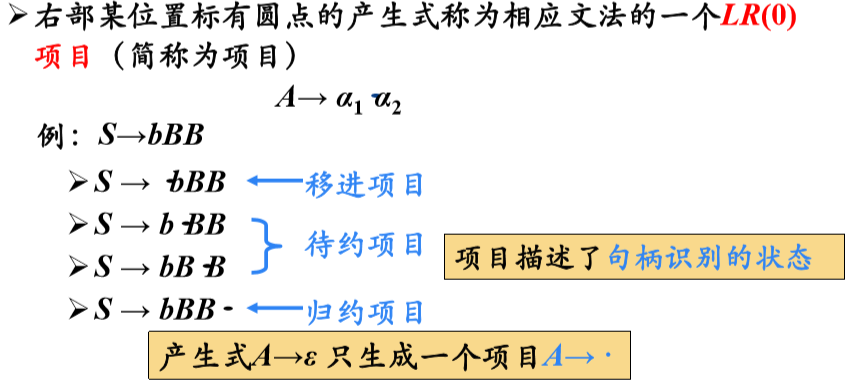
增广文法
如果G是一个以S为开始符号的文法,则G的增广文法G’就是在G中加上新开始符号S’和产生式S’→S得到的文法。引入这个新的开始产生式的目的是使得文法开始符号仅出现在一个产生式的左边,从而使得分析器只有一个接受状态

后继项目:同属于一个产生式的项目,但圆点的位置只差一个符号,则称后者是前者的后继项目
可以把等价的项目组成一个项目集(I),称为项目集闭包,每个项目集闭包对应着自动机的一个状态
LR(0)自动机
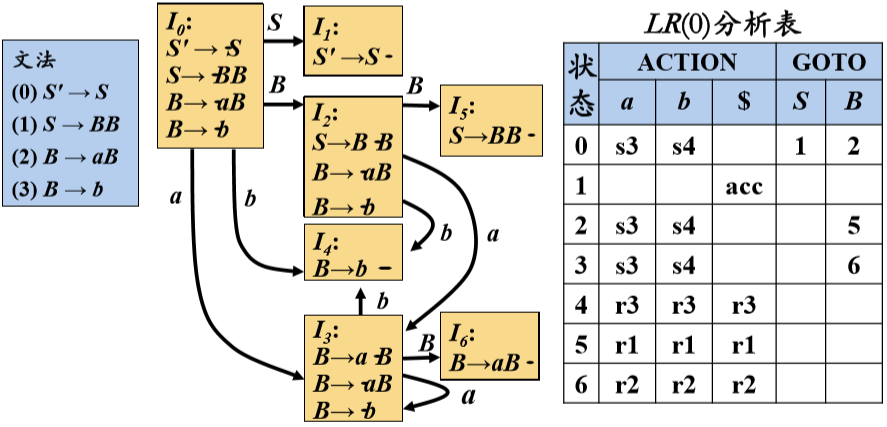
CLOSURE()函数
计算给定项目集I的闭包
CLOSURE(I) = I∪{B→ ·γ | A→α·Bβ∈CLOSURE(I), B→γ∈P}

GOTO()函数
返回项目集I对应于文法X的后继项目集闭包GOTO( I, X )=CLOSURE({A→αX· β | A→α·Xβ∈I })

构造LR(0)自动机的状态集
规范LR(0) 项集族(Canonical LR(0) Collection)
C={I0}∪{I | ∃J∈C, X∈VN∪VT, I=GOTO(J , X) }

LR(0)分析表构造算法

LR(0)自动机的形式化定义
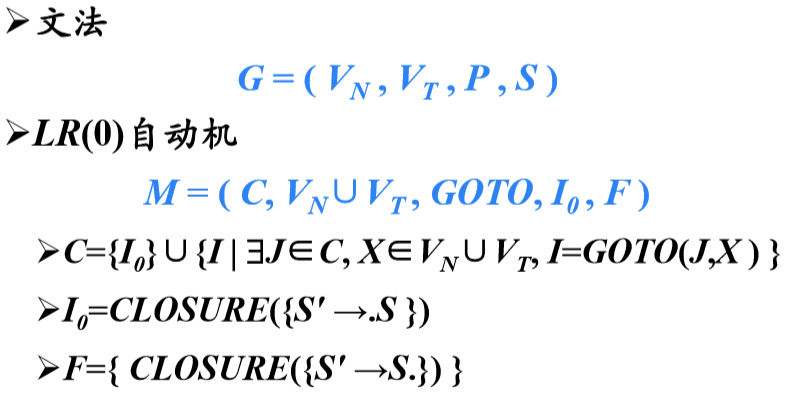
LR(0)分析过程中的冲突
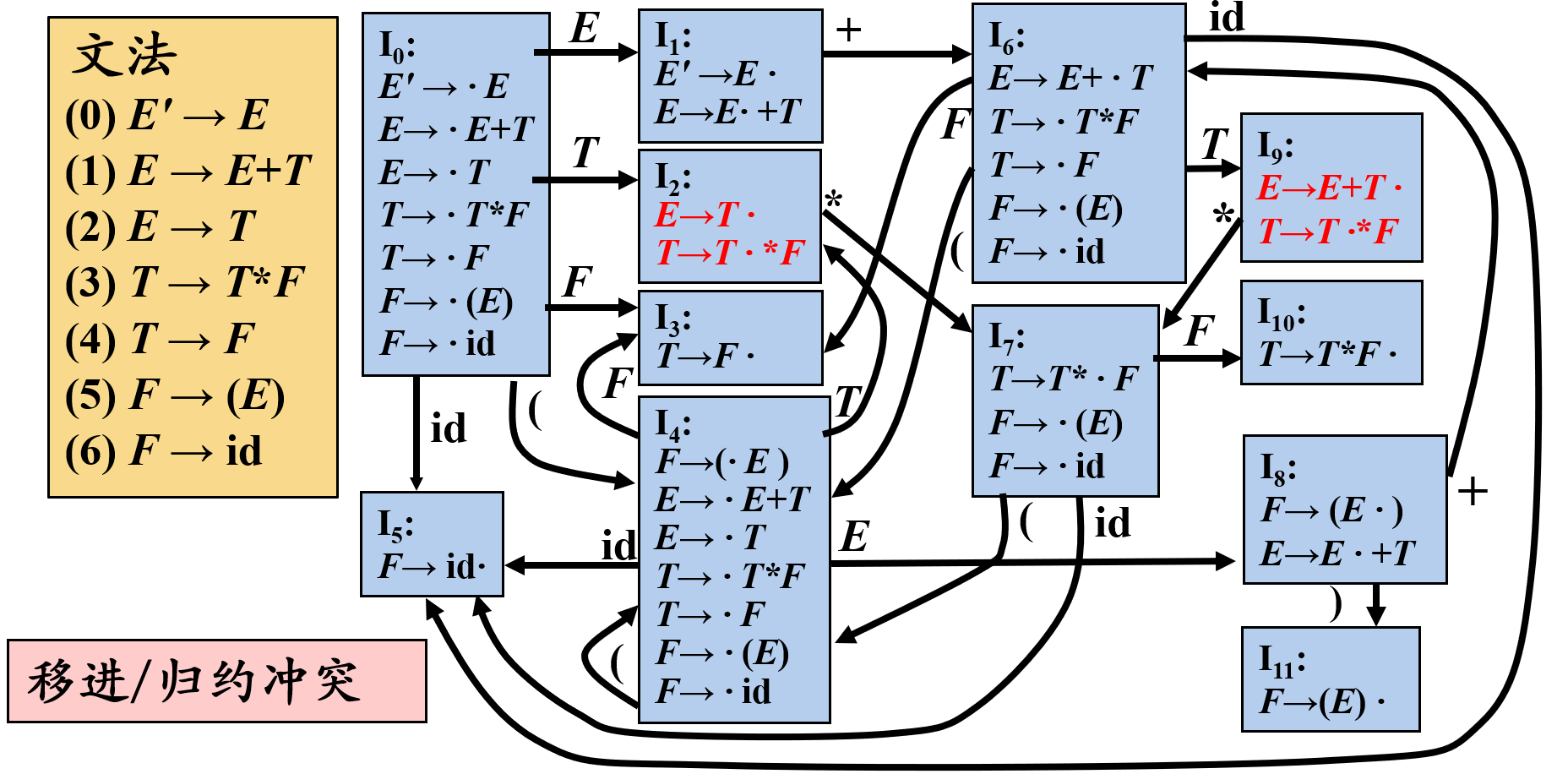
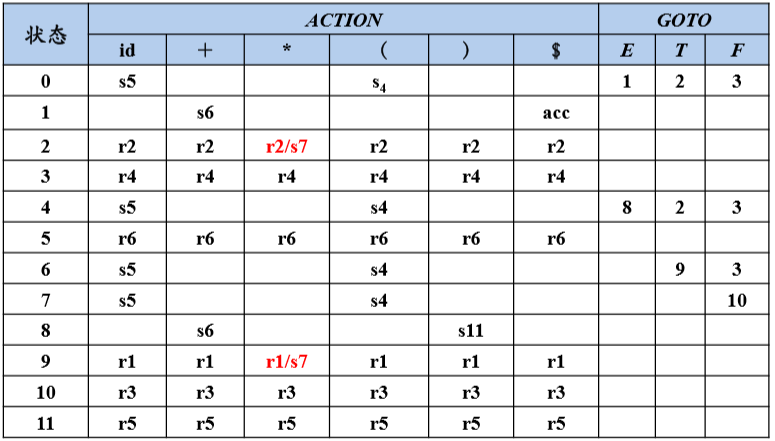
表达式文法的LR(0)分析表含有移进/归约冲突
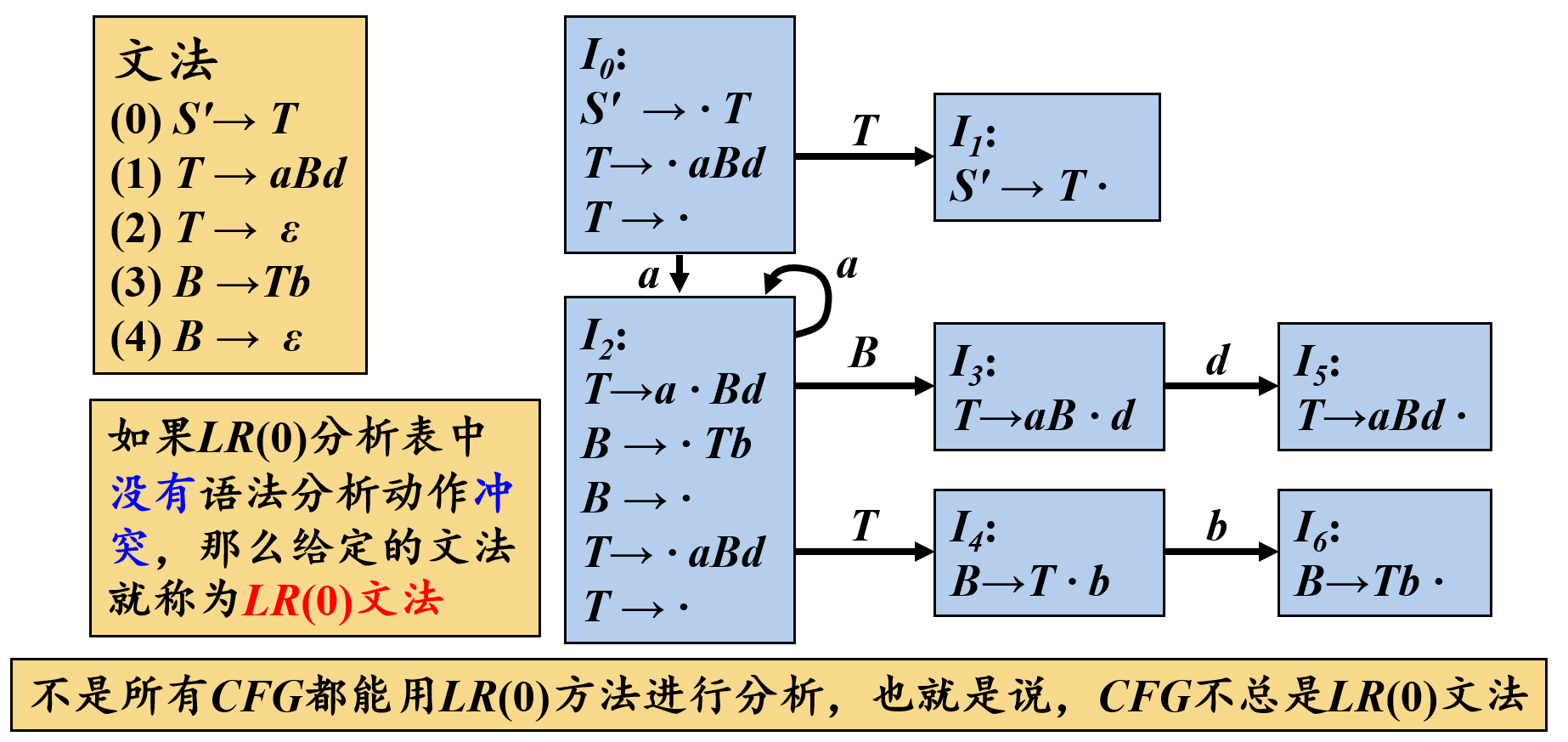
(2)SLR分析
SLR分析的基本思想
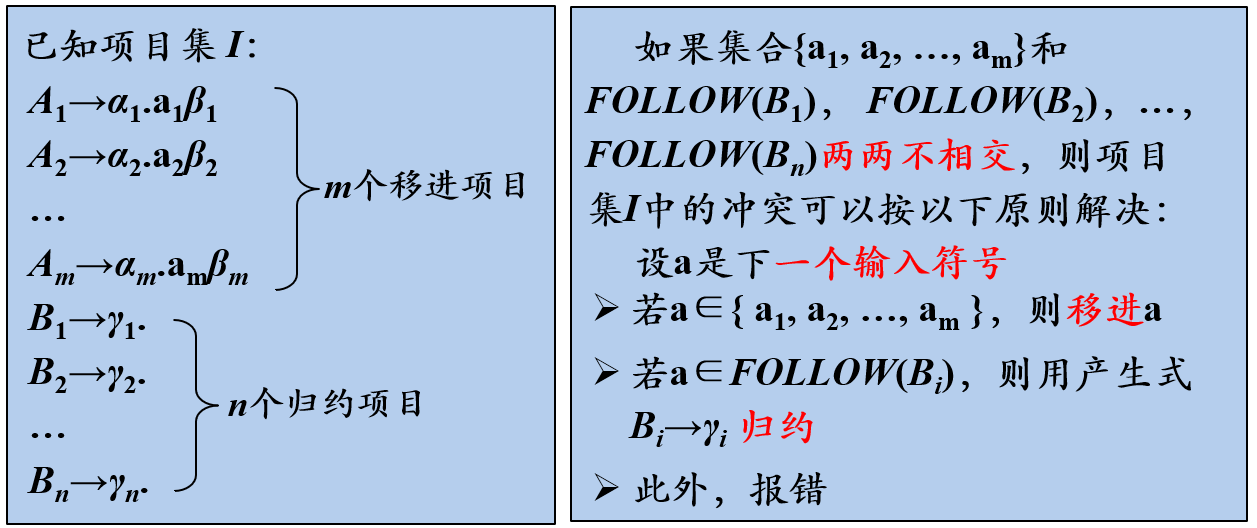
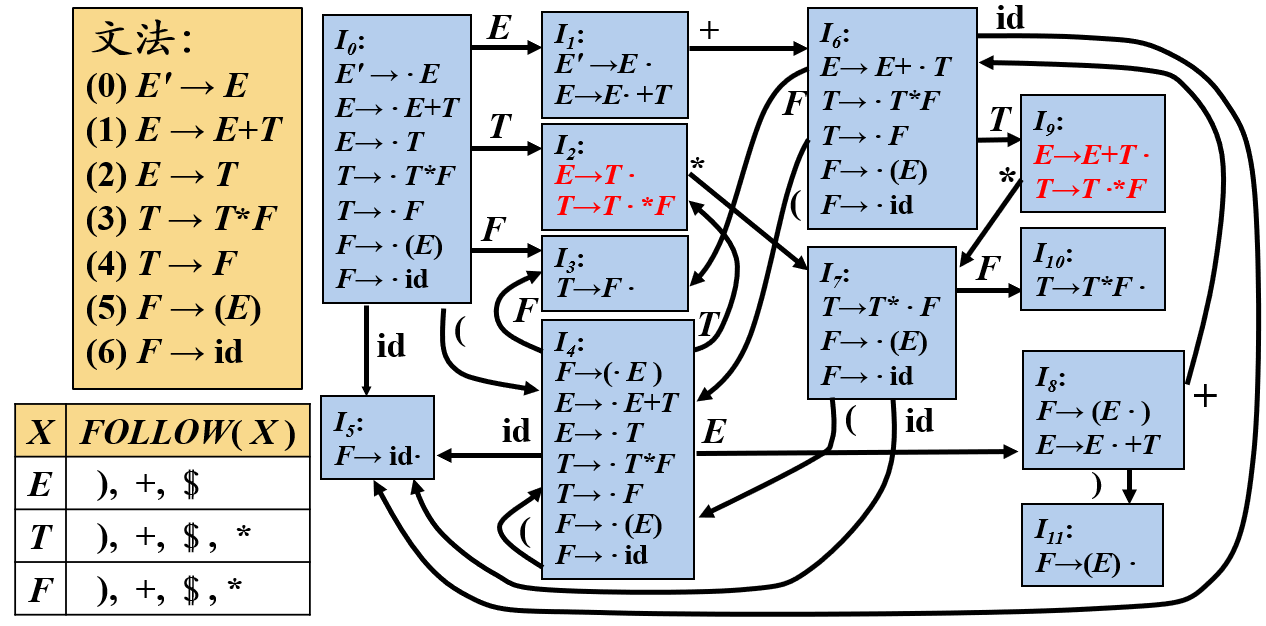
简单来说,I2读到星号后既可以归约为E也可以移入,但是E的FOLLOW集没有星号,所以这种情况忽略。SLR即SLR(1),S是Simple的意思,向前查看一个符号,而1可以省略,所以称为SLR。但真实情况应该是FOLLOW集的子集,所以SLR还会产生冲突。
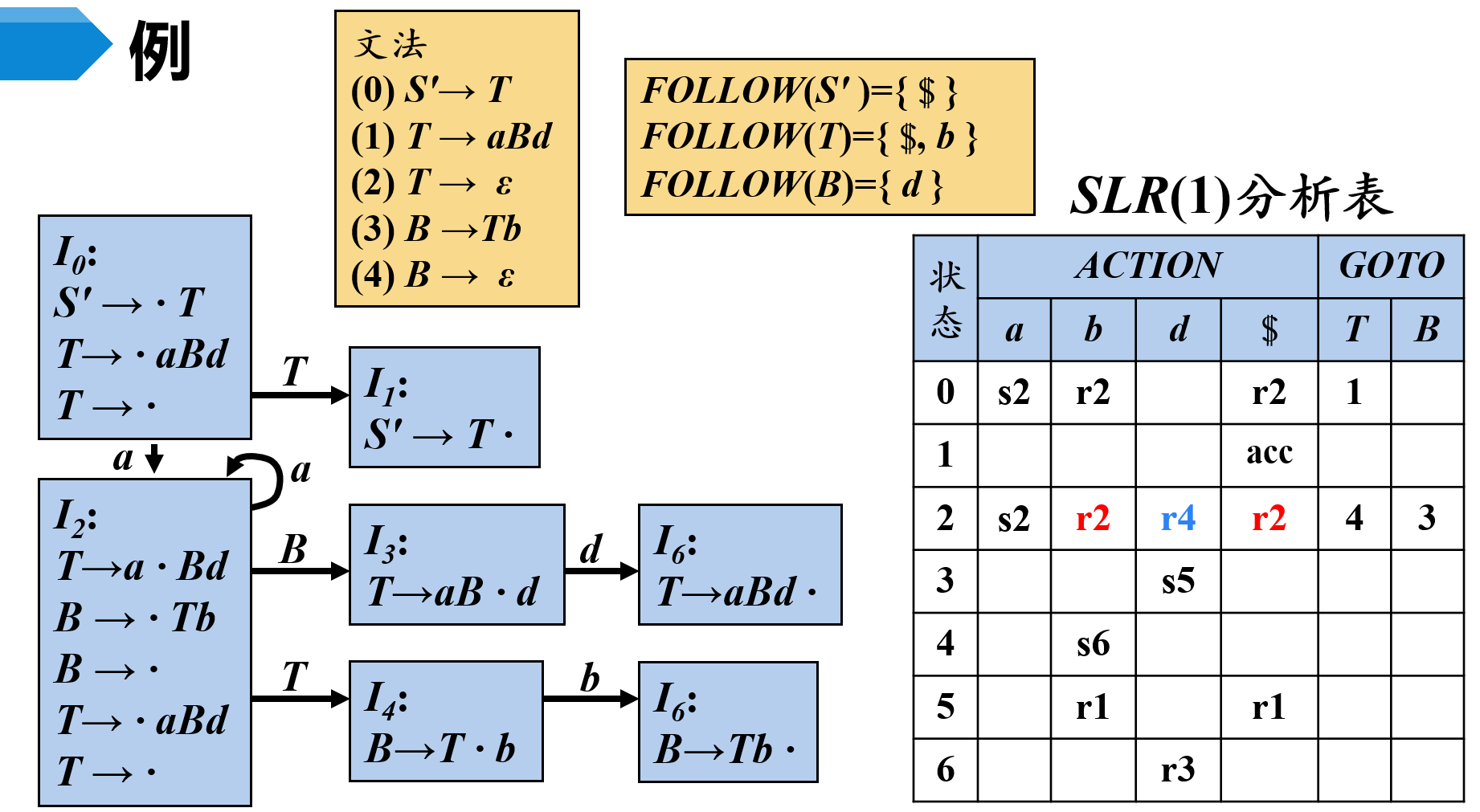
SLR分析表构造算法

(3)LR(1)分析
SLR的问题在于只是简单地考察下一个输入符号b是否属于与归约项目A→α相关联的FOLLOW(A),但b∈FOLLOW(A)只是归约α的一个必要条件,而非充分条件
对于产生式A→α的归约,在不同的使用位置,A会要求不同的后继符号,在特定位置,A的后继符集合是FOLLOW(A)的子集
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/68113.html