
目录
1.僵尸进程java面试基础多线程框架和孤儿进程
1.1 孤儿进程定义
1.2 僵尸进程定义
1.2 怎样来清除僵尸进程:
1)kill杀死元凶父进程(一般不用)
2)父进程用wait或waitpid去回收资源(方案不好)
3)通过信号机制,在处理函数中调用wait,回收资源
2.线程池详解
2.1线程池的作用
2.2 常见线程池的创建方式
newFixedThreadPool()
newCachedThreadPool()
newSingleThreadExecutor()
newScheduledThreadPool()
总结:
2.3 工作队列
2.4 拒绝策略
2.5 基础、函数、复杂(Callable)创建线程池代码
3.线程池的几种状态:
4.线程池的底层实现原理?
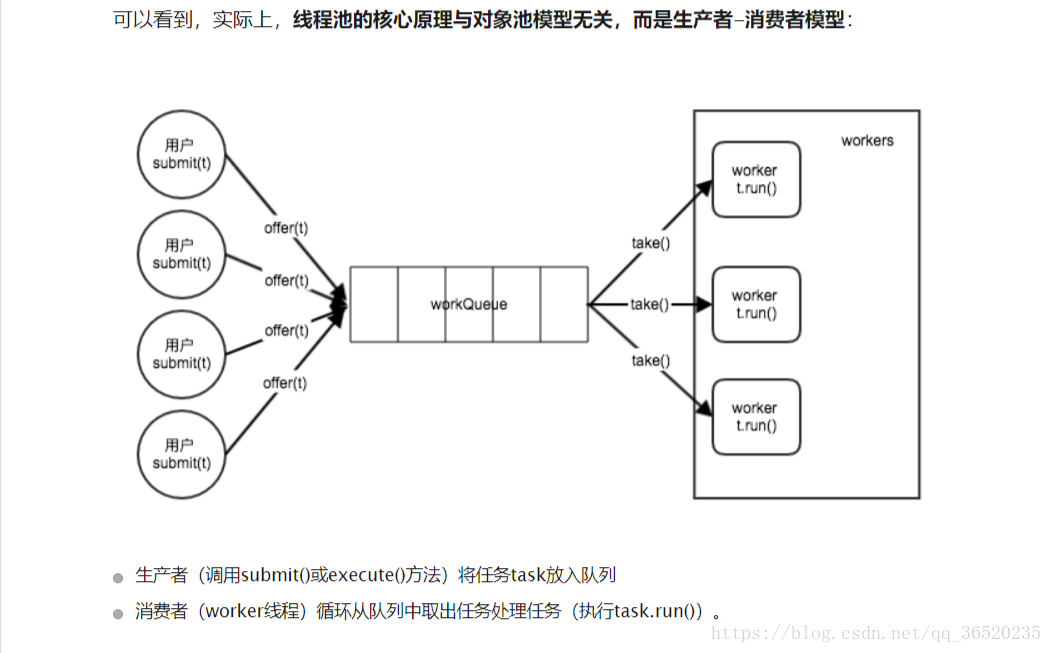
4.1 首先了解一下生产者消费者模型
4.2 线程池的核心
5.线程安全是什么意思?
5.1 Servlet的线程安全性
5.2 SpringMVC的Controller是线程安全的吗?
6.乐观锁和悲观锁
7.volatile实现原理
7.1 volatile作用
7.2 volatile对应底层实现原理
7.3 相关代码
8.synchronized的底层原理
8.1 对代码块同步monitor表象原理;
8.2 Synchronized的使用
8.2.1 同步与异步
8.2.2 阻塞与非阻塞
8.2.3 补充
8.3 Synchronized的优化
8.3.1 普通对象内存结构
编辑
8.3.2 锁升级
编辑
8.3.3 锁粗化和锁消除
8.4 volatile和synchronized的区别:
9.ReentrantLock相关
9.1 底层原理
9.2 相关代码
9.3 ReentrantLock 和 Synchronized 区别
10.死锁的形成条件和避免方法:
10.1 形成条件:
10.2 避免方法:
11.红黑树和平衡二叉树的区别:
12.进程和线程的区别:
13.创建线程的方法
14.线程状态
15.集合相关内容
15.1 HashMap的底层实现原理
15.1.1 概述
15.1.2 HashMap和HashashTable的区别
两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全;
15.1.3 HashMap的底层存储
15.2 CocurrentHashMap的底层实现原理
15.2.1 JDK 1.7
15.2.2 JDK 1.8
16.进程通信方式
17.Scheduler.from
附录代码
1.ThreadLocal测试
2.invoke测试
3.ForkJoinPool测试
1.僵尸进程和孤儿进程
1.1 孤儿进程定义
孤儿进程:父进程结束了,而它的一个或多个子进程还在运行,那么这些子进程就成为孤儿进程(father died)。子进程的资源由init进程(进程号PID = 1)回收。
1.2 僵尸进程定义
子进程退出了,但是父进程没有用wait或waitpid去获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中,此时子进程将成为 一个僵尸进程。
1.2 怎样来清除僵尸进程:
1)kill杀死元凶父进程(一般不用)
严格的说,僵尸进程并不是问题的根源,罪魁祸首是产生大量僵死进程的父进程。因此,我们可以直接除掉元凶,通过kill发送SIGTERM或者SIGKILL信号。元凶死后,僵尸进程进程变成孤儿进程,由init充当父进程,并回收资源。
或者运行:kill -9 父进程的pid值、
2)父进程用wait或waitpid去回收资源(方案不好)
父进程通过wait或waitpid等函数去等待子进程结束,但是不好,会导致父进程一直等待被挂起,相当于一个进程在干活,没有起到多进程的作用。
3)通过信号机制,在处理函数中调用wait,回收资源
通过信号机制,子进程退出时向父进程发送SIGCHLD信号,父进程调用signal(SIGCHLD,sig_child)去处理SIGCHLD信号,在信号处理函数sig_child()中调用wait进行处理僵尸进程。什么时候得到子进程信号,什么时候进行信号处理,父进程可以继续干其他活,不用去阻塞等待。
讯享网显示:(状态Z代表僵尸进程)
S PID PPID CMD
S 3213 2529 https://blog.csdn.net/chengxuya/article/details/pid1
Z 3214 3213 [pid1]
2.线程池详解
2.1线程池的作用
- 降低资源消耗,减少线程池的创建销毁开销;
- 提高系统的响应速率,任务到达时,不需等待线程就能立即执行。
- 提高线程可管理性;
- 防止服务器过载。是针对内存溢出,CPU耗尽的一个比较好的解决方式,但是不能用newCachedThreadPool()。
2.2 常见线程池的创建方式
有4种类型的创建线程池的简单函数:
-
newFixedThreadPool()
- 说明:初始化一个指定线程数的线程池,其中 corePoolSize == maxiPoolSize,使用 LinkedBlockingQuene 作为阻塞队列
- 特点:即使当线程池没有可执行任务时,也不会释放线程。
-
newCachedThreadPool()
- 说明:初始化一个可以缓存线程的线程池,核心线程数是0,默认缓存 60s,线程池的线程数可达到 Integer.MAX_VA LUE,即 ,内部使用 SynchronousQueue 作为阻塞队列;
- 特点:在没有任务执行时,当线程的空闲时间超过 keepAliveTime,会自动释放线程资源;当提交新任务时,如果没有空闲线程,则创建新线程执行任务,会导致一定的系统开销; 因此,使用时要注意控制并发的任务数,防止因创建大量的线程导致而降低性能。适合执行耗时小的异步连续任务;
-
newSingleThreadExecutor()
- 说明:初始化只有一个线程的线程池,最大线程数也是1,内部使用 LinkedBlockingQueue 作为阻塞队列。
- 特点:如果该线程异常结束,会重新创建一个新的线程继续执行任务,唯一的线程可以保证所提交任务的顺序执行。
- 与newFixedThreadPool(1)的区别在于,单一线程池大小在newSingleThreadExecutor方法中硬编码,不能再改变。
-
newScheduledThreadPool()
- 特定:初始化的线程池可以在指定的时间内周期性的执行所提交的任务,在实际的业务场景中可以使 用该线程池定期的同步数据。
总结:
除了 newScheduledThreadPool 的内部实现特殊一点之外,其它线程池内部都是基于 ThreadPoolExecutor 类(Executor 的子类)实现的。
2.3 工作队列
workQueue
- ArrayBlockingQueue:基于数组结构的有界阻塞队列,按 FIFO 排序任务;
- LinkedBlockingQuene:基于链表结构的阻塞队列,按 FIFO 排序任务,吞吐量通常要高于 Array BlockingQuene;
- SynchronousQuene:一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除 操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于 LinkedBlockingQuene;
- priorityBlockingQuene:具有优先级的无界阻塞队列; threadFactory 创建线程的工厂,通过自定义的线程工厂可以给每个新建的线程设置一个具有识别度的线程名。
2.4 拒绝策略
handler
线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了 4 种策略:
- AbortPolicy:丢弃任务并抛出RejectedExecutionException异常,默认策略;
- CallerRunsPolicy:用调用者所在的线程来执行任务;
- DiscardOldestPolicy:丢弃阻塞队列中最靠前的任务,并重新提交当前业务;
- DiscardPolicy:直接丢弃新来的任务不发出异常;
当然也可以根据应用场景实现 RejectedExecutionHandler 接口,自定义饱和策略,如记录日志或持久化存储不能处理的任务。
2.5 基础、函数、复杂(Callable)创建线程池代码

讯享网
3.线程池的几种状态:
- RUNNING 自然是运行状态,指可以接受任务且可以执行队列里的任务;
- SHUTDOWN 指调用了 shutdown() 方法,不再接受新任务了,但是队列里的任务得执行完毕。
- STOP 指调用了 shutdownNow() 方法,不再接受新任务,同时抛弃阻塞队列里的所有任务并中断所有正在执行任务(中断这个不一定能彻底中断)。
- TIDYING 所有任务都执行完毕,在调用 shutdown()/shutdownNow() 中都会尝试更新为这个状态。
- TERMINATED 终止状态,当TIDYING 时执行 terminated() 后会更新为这个状态,表示回调函数已经完成。
4.线程池的底层实现原理?
4.1 首先了解一下生产者消费者模型
讯享网
4.2 线程池的核心
简单看了一下源码,线程池的状态是通过Atomic Integer实现的,所谓线程池就是一个HashSet,HashSet里面存储了一堆Worker对象,Worker是一个实现了Runnbale接口的类,每次来一个任务,如果需要增加线程,就要调用ReentrantLock的对象mainlock进行该线程池ThreadPoolExecutor对象的加锁和解锁,来向hashset对象里面添加这个对应的工作线程worker。具体原理待补充。
execute –> addWorker –>runworker (getTask)
线程池的工作线程通过Woker类实现,在ReentrantLock锁的保证下,把Woker实例插入到HashSet后,并启动Woker中的线程。
从Woker类的构造方法实现可以发现:线程工厂在创建线程thread时,将Woker实例本身this作为参数传入,当执行start方法启动线程thread时,本质是执行了Worker的runWorker方法。
firstTask执行完成之后,通过getTask方法从阻塞队列中获取等待的任务,如果队列中没有任务,getTask方法会被阻塞并挂起,不会占用cpu资源;
Java线程池实现原理与源码解析(jdk1.8)_猪杂汤饭的博客-CSDN博客_java线程池源码
四种线程池拒绝策略_onEars的博客-CSDN博客_线程池拒绝策略
5.线程安全是什么意思?
线程安全是指某个函数函数库在多线程环境中被调用时,可以正确的处理多个线程之间的共享变量,让程序功能正确完成。
5.1 Servlet的线程安全性
Servlet不是线程安全的,它是单实例多线程的,当多个线程同时访问一个方法时,是不能保证共享变量的线程安全性的。

5.2 SpringMVC的Controller是线程安全的吗?
同样不是,和Servlet类似,但是和前者一样都可以用ThreadLocal来处理问题。
6.乐观锁和悲观锁
乐观锁:对于并发间操作产生的线程安全状态抱有乐观态度。乐观锁认为竞争不总是会发生,因此它不需要持有锁,一般是通过CAS操作解决并发出现的问题。
悲观锁:假设并发操作会出现线程安全问题,即总是有多个线程竞争资源,所以会有一个独占的锁,像synchronized。
7.volatile实现原理
7.1 volatile作用
- 保证线程的可见性;
- 禁止指令重排序;
7.2 volatile对应底层实现原理
- 通过lock前缀指令在多核处理器实现以下两点:
(1)将当前处理器缓存的数据写回到系统内存;
对volatile变量进行写操作,JVM会向处理器发送一条lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存;
(2)这个写回操作会引起其他CPU里缓存了该内存地址的数据无效;
通过缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是否过期了。当处理器发现自己缓存行对应的内存地址内容被修改,就会将当前处理器的缓存行设置为无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
- volatile通过内存屏障防止指令重排
主要是借助JMM在编译期和处理器层面限制指令重排序,java的内存屏障插入策略是保守策略,策略如下:
普通写-storestore-volatile写-storeload-volatile读-loadload-普通读-loadstore-普通读-普通写。。。
7.3 相关代码
8.synchronized的底层原理
8.1 对代码块同步monitor表象原理;
synchronized每个对象都有一个监视器锁monitor,当monitor被占用时就会处于锁定状态。
线程所谓的加锁其实就是执行monitorenter指令尝试获取monitor的使用权,过程如下:
如果monitor进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
如果线程已经占有monitor,则重新进入,则进入monitor的数量加一。
如果其他线程已经占用了该monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
所谓对象其实就是括号里的对象。上述描述可以推断出:
synchronized是可重入锁;
8.2 Synchronized的使用
调用指令将会检查方法的ACC_SYNCHRONIZED访问标识是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。
- 修饰实例方法,对当前实例对象加锁;
- 修饰静态方法,对当前类的Class对象加锁;
- 修饰代码块,对synchronized括号内的对象加锁,里面如果是类.class或者类的静态对象,则对当前类加锁,若是普通对象(包括字符串)就是对实例对象加锁。
- 个人猜测这个对象的内存结构有关。
- 相关代码:
synchronized和lock属于同步阻塞。
使用CAS属于同步非阻塞;
8.2.1 同步与异步
同步就是不停的查询等待结果;
异步就是等服务端通知就好,不用主动查询获取结果。
8.2.2 阻塞与非阻塞
阻塞式方法是指程序会一直等待该方法完成期间不做其他事情,ServerSocket 的 accept()方法就是一直等待客户端连接。这里的阻塞是指调用结果返回之前,当前 线程会被挂起,直到得到结果之后才会返回。
非阻塞就是可以继续去做别的事情;
8.2.3 补充
网络中获取数据的读操作步骤:
等待数据准备。
数据从内核空间拷贝到用户空间。
同步过程中进程触发IO操作并等待或者轮询的去查看IO操作是否完成。
异步过程中进程触发IO操作以后,直接返回,做自己的事情,IO操作交给内核来处理,完成后内核通知进程IO完成。
同步和异步是相对于操作结果来说,会不会等待结果返回。
阻塞与非阻塞:
应用进程请求IO操作时,如果数据未准备好,如果请求立即返回就是非阻塞,不立即返回就是阻塞。简单来说,就是做一件事如果不能立即获得返回,需要等待,就是阻塞,否则可以理解为非阻塞。
阻塞和非阻塞是相对于线程是否被阻塞。
异步/同步和阻塞/非阻塞的区别:
其实,这两者存在本质区别,他们的修饰对象是不同的。 阻塞和非阻塞是指进程访问的数据如果尚未准备就绪,进程是否需要等待,简单来说这相当于函数内部的实现区别 ,也就是未就绪时是直接返回还是等待就绪。
而同步和异步是指访问数据的机制 ,同步一般指主动请求并等待IO操作完毕的方式 ,当数据就绪后再读写的时候必须阻塞,异步则指主动请求数据后便可以继续处理其它任务,随后等待IO操作完毕的通知,这可以使进程再数据读写时也不阻塞。
同步/异步 与 阻塞/非阻塞的组合方式
故事:老王烧开水
出场人物:老王,两把水壶(水壶,响水壶)
同步阻塞: 效率是最低的,实际程序中,就是fd未设置O_NONBLOCK 标志位的read/write操作。
老王用水壶烧水,并且站在那里(阻塞),不管水开没开,每隔一定时间看看水开了没(同步->轮询)。
同步非阻塞: 实际上效率是低下的,注意对fd设置O_NONBLOCK 标志位。
老王用水壶烧水,不再傻傻的站在那里,跑去做别的事情(非阻塞),但是还是会每个一段时间过来看看水开了没,没开就继续去做的事情(同步->轮询)。
异步阻塞: 异步操作是可以被阻塞住的,只不过它不是在处理消息时阻塞,而是在等待消息时被阻塞。比如select函数,假如传入的最后一个timeout函数为NULL,那么如果所关注的事件没有一个被触发,程序就会一直阻塞在select调用处。
老王用响水壶烧水,站在那里(阻塞),但是不再去看水开了没,而是等水开了,水壶会自动通知它(异步,内核通知进程)。
异步非阻塞: 效率更高,注册一个回调函数,就可以去做别的事情。
老王用响水壶烧水。跑去做别的事情(非阻塞),等待响水壶烧开水自动通知它(异步,内核通知进程)
socket的fd是什么?
fd是(file descriptor/文件描述符) ,这种一般是BSD Socket的用法,用在Unix/linux系统上。在Unix/linux系统下,一个Socket句柄,可以看做是一个文件,在socket上收发数据,相当于读一个文件进行读写,所以一个socket句柄,通常也用表示文件句柄的fd来表示。
8.3 Synchronized的优化
8.3.1 普通对象内存结构
- 对象头(markword[关于synchronized的所有信息都在这部分,8个字节];
- 类型指针class pointer[属于哪个类,存储大小4个字节]) ;
- 实例数据instance data[成员变量所在的存储,存储初始化为0字节] ;
- 对齐padding[补足八个字节的倍数]
可以通过
查看对象的内存结构。
输出结果为:
锁的信息记录在对象里,其实就是在对象的Markword里;内含指向栈中所记录的指针或者指向重量级锁的指针。对象头的MarkWord中的LockRecord指向monitor的起始地址。下图为markword内部关于锁的信息的存储:
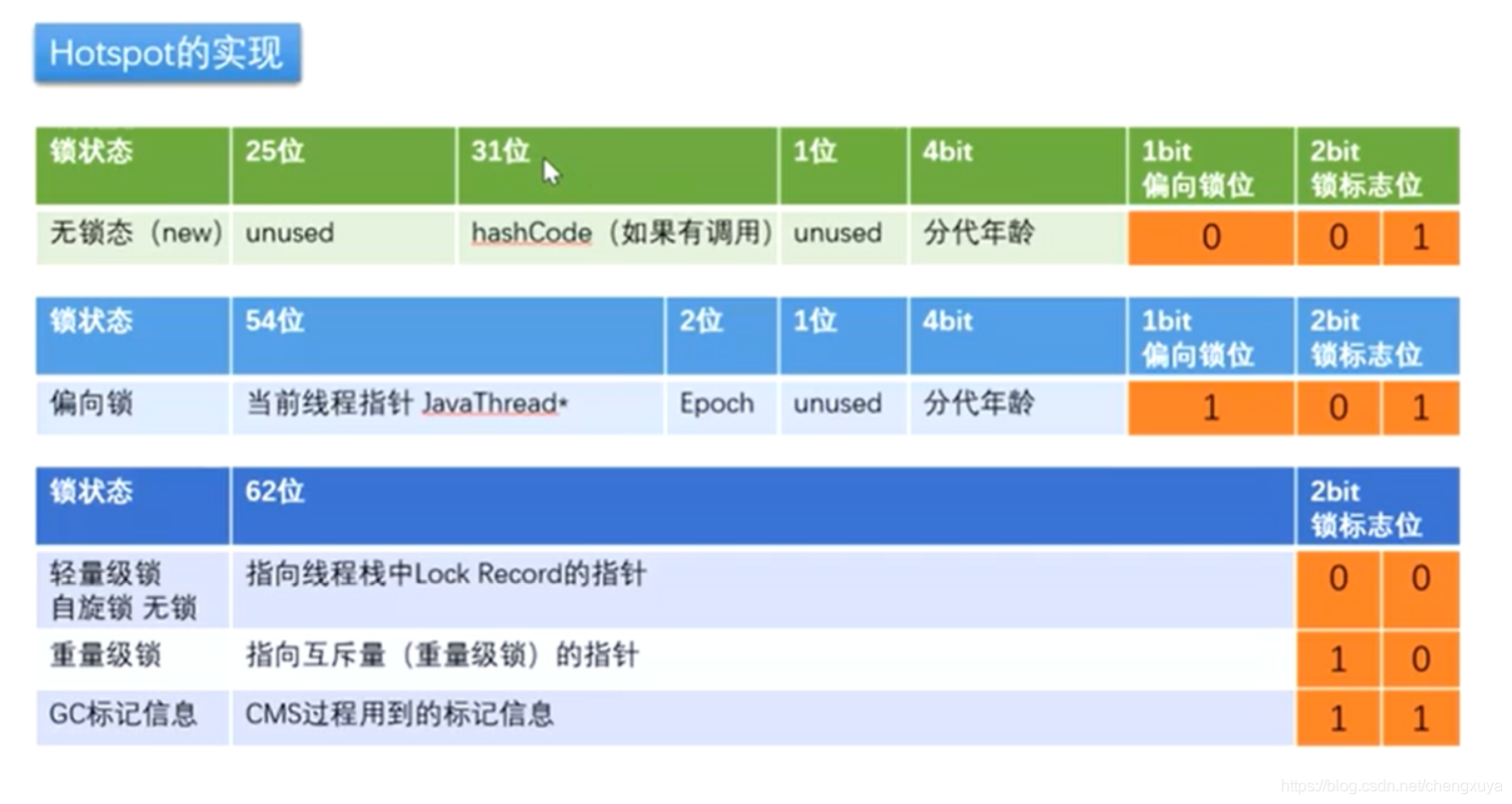
8.3.2 锁升级
锁升级其实就是锁的优化。
锁升级包括无锁-偏向锁-轻量锁-重量级锁几步。
偏向锁:当前没有线程争抢的情况,没有线程争抢,所以本线程就将当前线程指针指向占有该对象的线程。
轻量级锁、自旋锁:有线程争抢情况。
如果有线程要争抢这个对象的锁,偏向锁升级为这种锁。线程释放偏向锁,每个线程都有自己的线程栈,每个线程栈都可以生成自己的Lock Record,线程争抢看哪个线程能让指针指向自己线程栈中的Lock Record。因为自旋锁很占CPU,所以当有线程自旋超过10次或者自旋线程数超过CPU核数的一半的时候, java高版本中加入自适应自选adaptive self spinning,JVM自己控制是否升级为重量级锁;
重量级锁:指向互斥量(重量级锁)的指针; 升级为重量级锁,向操作系统申请资源,linux mutex,CPU从3级到0级系统调用, 线程挂起,进入等待队列,阻塞等待操作系统的调度,此时不占用CPU,然后再映射回用户空间;GC标记信息(CMS过程用到的标记信息)。
8.3.3 锁粗化和锁消除
- 锁粗化:遇到不停加锁减锁的情况,就把锁的代码范围扩大,这样就不用频繁加锁解锁了。
- 锁消除:如果操作的stringbuffer对象没被其他线程争抢引用,所以锁就不需要了,所以系统自动进行锁消除;stringbuffer之所以是线程安全的,是因为它的关键方法都是被synchronized修饰过的。
8.4 volatile和synchronized的区别:
锁具有两种特性:互斥性和可见性;
- volatile不加锁,synchronized加锁;
- volatile仅能作用于变量级别,synchronized则可以作用于变量、代码段、方法级别。
- volatile仅能保证变量的可见性,synchronized则可以同时保证变量的可见性和原子性。例如volatile变量的自增操作就没有原子性。
- volatile不会造成线程的阻塞,synchronized可能会。
9.ReentrantLock相关
9.1 底层原理
以ReentrantLock为例理解AQS原理_weixin_的博客-CSDN博客_cas和aqs
如何理解Condition:Java技术——ReentrantLock的Condition的作用以及使用_reentrantlock newcondition-CSDN博客
9.2 相关代码
9.3 ReentrantLock 和 Synchronized 区别
- ReentrantLock可以实现公平锁、锁中断、锁超时;
- ReentrantLock可以通过condition变量实现明确唤醒某个线程,而不是只能全部唤醒然后通过其他方法限制争抢。
- ReentrantLock和Synchronized的底层实现原理不一样。
10.死锁的形成条件和避免方法:
10.1 形成条件:
进程对资源的独占性,不可抢占性,请求与等待性,循环等待;这将导致不同进程竞争资源时出现僵持状态。
10.2 避免方法:
(1)控制死锁的加锁顺序,银行家算法,银行家算法需要事先知道自己需要多少资源和系统可以给多少资源,这是问题;
(2)设置获取锁的超时时间;
(3)强制中断线程,interrupt(java),(有对应sql命令)数据库;
11.红黑树和平衡二叉树的区别:
红黑树和AVL树(平衡二叉树)区别_Charles_yy的博客-CSDN博客_红黑树和平衡二叉树区别
一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
12.进程和线程的区别:
进程时操作系统分配资源的最小单位,线程是CPU进行调度的最小单位。
线程是进程的一部分,线程的资源来自于进程,因此进程切换的开销(程序上下文)要远比线程(程序计数器+虚拟机栈+本地方法栈)大。
系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
13.创建线程的方法
有 以下几种方式可以用来创建线程:
- 继承 Thread 类
- 实现 Runnable 接口
- 应用程序可以使用 Executor 框架来创建线程池
- 实现 Callable 接口
实现 Runnable 接口比继承 Thread 类所具有的优势:
- 适合多个相同的程序代码的线程去处理同一个资源
- 可以避免 java 中的单继承的限制
- 增加程序的健壮性,代码可以被多个线程共享,代码和数据独立
- 线程池只能放入实现 Runable 或 callable 类线程,不能直接放入继承 Thread 的类
- runnable 实现线程可以对线程进行复用,因为 runnable 是轻量级的对象,重复 new 不会耗费太大资源,而 Thread 则不然,它是重量级对象,而且线程执行完就结束了,无法再次利用。
不可以通过调用Thread的run()方法启动线程,原因:
如果我们调用了 Thread 的 run()方法,它的行为就会和普通的方 法一样,会在当前线程中执行。为了在新的线程中执行我们的代码,必须使用 Thread.start()方法。
14.线程状态
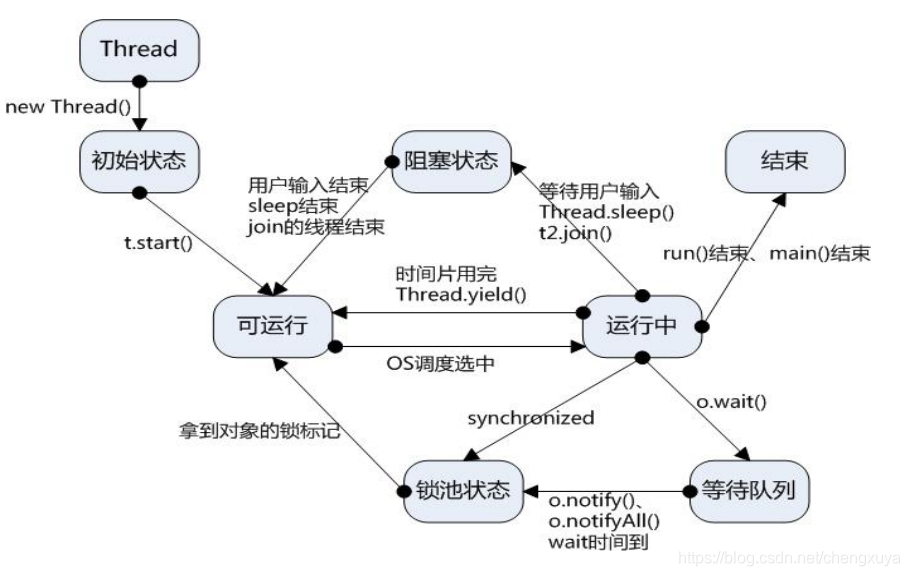
1、新建状态(New):新创建了一个线程对象。
2、就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的 start()方法。 该状态的线程位于可运行线程池中,变得可运行,等待获取 CPU 的使用权。
3、运行状态(Running):就绪状态的线程获取了 CPU,调用了run方法,执行程序代码。
4、阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃 CPU 使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
(一)、等待阻塞:运行的线程执行 wait()方法,JVM 会把该线程放入等待池中。(wait会释放持有的锁)
(二)、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则 JVM 会把该线程放入锁池中。
(三)、其他阻塞:运行的线程执行 sleep()或 join()方法,或者发出了 I/O 请求时,JVM 会把该线程置为阻塞状态。当 sleep()状态超时、join()等待线程终止或者超时、或者 I/O 处理完毕时,线程重新转入就绪状态。(注意,sleep 是不会释放持有的锁,sleep 必须捕获异常,而 wait,notify 和 notifyAll 不需要捕获异常)
5、死亡状态(Dead):线程执行完了或者因异常退出了 run()方法,该线程结束生命周期。、
14.5 start方法和run方法的区别
在Java中,和是类中的两个重要方法,它们之间的主要区别体现在线程的创建和执行方式上。
- 方法种类和执行方式:
- 方法是类中的一个普通方法,它定义了线程要执行的代码。当直接调用方法时,它会在当前线程的上下文中执行,不会创建新的线程。因此,代码会在当前线程中同步执行,而不是并发执行。
- 方法是类中的一个启动方法,它会创建一个新的线程,并在新线程的上下文中执行方法中的代码。调用方法后,新线程会异步执行方法中的代码,使得线程能够并发执行。
- 线程状态和行为:
- 调用方法启动一个新线程时,该线程会进入就绪状态,等待JVM调度它和其他线程的执行顺序。一旦得到CPU时间片,就开始执行方法中的代码。
- 直接调用方法,则会在当前线程中同步执行其内容,这并不会启动一个新的线程。因此,如果直接调用方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,要等待方法体执行完毕后才可继续执行下面的代码,这样就没有达到多线程的目的。
- 调用次数和线程终止:
- 方法可以被执行无数次,因为它是一个普通方法,可以在程序中多次调用。
- 方法只能被执行一次,因为线程不能被重复启动。一旦一个线程启动后,它的生命周期就由JVM管理,包括创建、运行和终止。
总结来说,使用方法启动线程是实现多线程运行的关键,因为它真正实现了多线程运行,无需等待方法体代码执行完毕而直接继续执行下面的代码。而直接调用方法则在当前线程中同步执行其内容,不会创建新的线程。
15.集合相关内容
15.1 HashMap的底层实现原理
15.1.1 概述
HashMap基于Map接口实现,元素以键值对的方式存储,并且允许使用null 键和null值,因为key不允许重复,因此只能有一个键为null。另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。HashMap是线程不安全的。HashMap的扩容操作是一项很耗时的任务,所以如果能估算Map的容量,最好给它一个默认初始值,避免进行多次扩容。HashMap的线程是不安全的,多线程环境中推荐是ConcurrentHashMap。
15.1.2 HashMap和HashashTable的区别
-
两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全;
- 两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全。虽说HashMap支持null值作为key,不过建议还是尽量避免这样使用,因为一旦不小心使用了,若因此引发一些问题,排查起来很麻烦。注意HashMap以null作为key时,总是存储在table数组的第一个节点上;
- HashMap是对Map接口的实现,HashTable实现了Map接口和Dictionary抽象类;
- Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模;HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取模;
15.1.3 HashMap的底层存储
1)JDK1.7 版本
HashMap采用Entry数组来存储key-value对,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Entry实体,以此来解决Hash冲突的问题。
数组存储区间是连续的,占用内存严重,故空间复杂度较大。但数组的查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表存储区间离散,占用内存比较宽松,故空间复杂度较小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
Entry数组初始容量为16,扩容的容量是2的次幂;


2)JDK 1.8的改变
HashMap变化为数组+链表+红黑树的存储方式,当链表长度超过阈值8时,将链表转换为红黑树,加上其他一些优化让HashMap在性能上进一步得到提升。

红黑树:平衡二叉查找树。当链表超过8时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。
一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
3)HashMap的判断键值是否相等的原理
containsKey方法是先计算hash然后使用hash和table.length取摸得到index值,遍历table[index]元素查找是否包含key相同的值。即先通过hashcode()确定在数组中的下标,再通过equals确定链表中的key值是否相等。有就覆盖,没有就创建新的链表节点,1.8以后好像是Node节点,不是Entry节点了。
equals判断的默认实现函数是:
所以对于基本数据类型判断值是否相等,对于包装类Integer有特殊情况,其他对象类里String也有特殊情况,因为String重写了hashcode函数和equals函数,对于自定义的类对象,也要自定义一下hashcode函数和equals函数。
4)扩容机制的对比
Java 1.7中是hashmap达到阈值(容量*负载因子0.75)便进行扩容,扩容总是二倍容量扩容。扩容方法是用一个容量更大的数组代替已有的容量小的数组,transfer()方法将原有的Entry数组中的元素拷贝到新的Entry数组中,然后重新计算每个元素在数组中的位置。
Java 8中扩容前提条件一样,但是扩容机制出现变化,因为容量是二倍扩展,所以只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变为“原索引+oldCap”,就是原位置再移动二次幂的位置。
15.2 CocurrentHashMap的底层实现原理
15.2.1 JDK 1.7
采用锁分段技术,有一个segment数组,容量默认设置为16。Segment 继承了 ReentrantLock,表明每个 segment 都可以当做一个锁。这样对每个 segment 中的数据需要同步操作的话都是使用每个 segment 容器对象自身的锁来实现。只有对全局需要改变时锁定的是所有的 segment。HashTable之所以效率低,是因为所有访问HashTable的线程都必须竞争一把锁,而这里有16把锁。
15.2.2 JDK 1.8
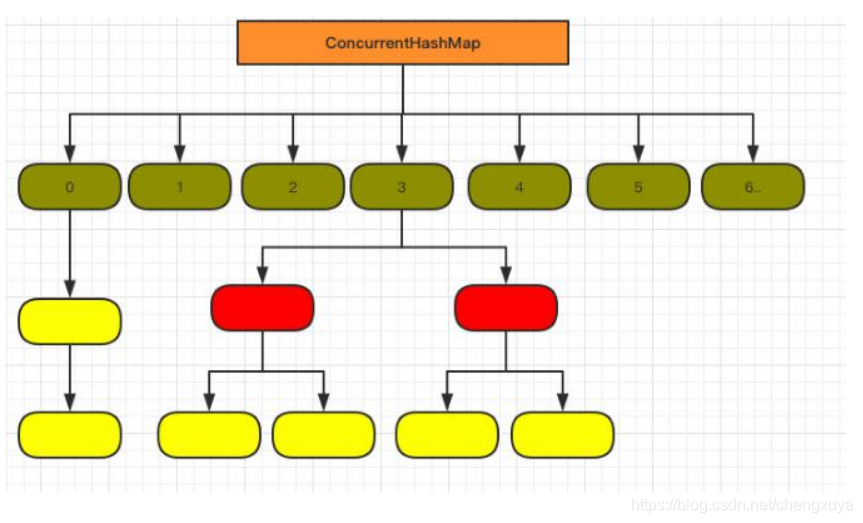
- 抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
- 当 table[i]下面的链表长度大于8时就转化为红黑树结构。
16.进程通信方式
管道、有名管道、信号量、消息队列、共享内存、套接字。
共享内存:共享内存可以说是最有用的进程间通信方式,也是最快的 IPC 形式。两个不同进程 A、B共享内存的意思是,同一块物理内存被映射到进程 A、B 各自的进程地址空间。进程 A 可以即时看到进程 B 对共享内存中数据的更新,反之亦然。由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以。
17.Scheduler.from
RxJava学习笔记(三)--- 线程调度Scheduler_编程的小蚂蚁的博客-CSDN博客
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/6623.html