
SELECT a.managecom, a.subtype, count(*) loadsucc, sum(case when a.state in ('4', '5', '6', '7', '8', '9') then 1 else 0 end) recogsucc, sum(case when a.state in ('3', '12', '13') then 1 else 0 end) recogfail, sum(case when a.state in ('1', '2') then 1 else 0 end) waitrecog FROM ocr_docdetail a, ocr_loaddetail c WHERE 1 = 1 and a.managecom like '86%' and a.managecom = c.managecom and a.bussno = c.bussno and a.subtype = c.subtype and c.loadstate = 0 and c.scandate >= date '2012-07-29' and c.scandate <= date '2013-01-07' group by a.managecom, a.subtype order by a.managecom, a.subtype;讯享网
case具有两种格式。简单case函数和case搜索函数。
--简单case函数
case sex
when '1' then '男'
when '2' then '女'
else '其他' end
--case搜索函数
case when sex = '1' then '男'
when sex = '2' then '女'
else '其他' end
--比如说,下面这段sql,你永远无法得到“第二类”这个结果
case when col_1 in ( 'a', 'b') then'第一类'
when col_1 in ('a') then '第二类'
else '其他' end
下面我们来看一下,使用case函数都能做些什么事情。
一,已知数据按照另外一种方式进行分组,分析。
有如下数据:(为了看得更清楚,我并没有使用国家代码,而是直接用国家名作为primary key)
| 国家(country) |
人口(population) |
| 中国 |
600 |
| 美国 |
100 |
| 加拿大 |
100 |
| 英国 |
200 |
| 法国 |
300 |
| 日本 |
250 |
| 德国 |
200 |
| 墨西哥 |
50 |
| 印度 |
250 |
| 洲 |
人口 |
| 亚洲 |
1100 |
| 北美洲 |
250 |
| 其他 |
700 |
想要解决这个问题,你会怎么做?生成一个带有洲code的view,是一个解决方法,但是这样很难动态的改变统计的方式。
假如使用case函数,sql代码如下:
select sum(population),
case country
when '中国' then'亚洲'
when '印度' then'亚洲'
when '日本' then'亚洲'
when '美国' then'北美洲'
when '加拿大' then'北美洲'
when '墨西哥' then'北美洲'
else '其他' end
from table_a
group by case country
when '中国' then'亚洲'
when '印度' then'亚洲'
when '日本' then'亚洲'
when '美国' then'北美洲'
when '加拿大' then'北美洲'
when '墨西哥' then'北美洲'
else '其他' end;
注:
在上面这个例子中,其实select 了两个字段:sum(population), case country;
country 字段里面原来有很多值,有“中国,美国,日本,加拿大...”等等,select后的case when then else end其实就是相当于把country的值分为三类:"亚洲,北美洲,其他";
其实没有from后面的case when语句,其结果集是这样的,sum得到的是人口population的总数,所以需要将population分组,就有了后面的group by:
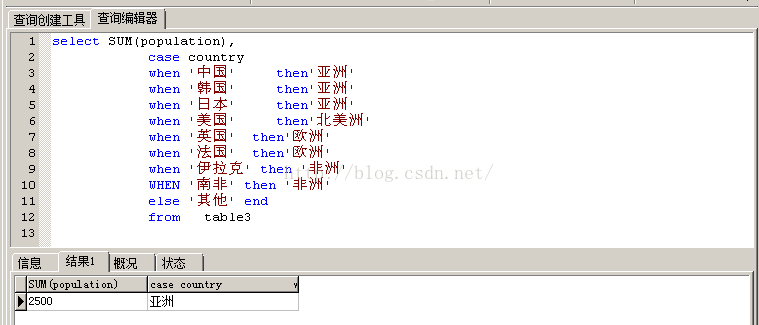
后面的case when语句,其实是将前面查询的字段case country进行分组,分成三组:"亚洲,北美洲,其他",然后就能得出结果来

select
case when salary <= 500 then '1'
when salary > 500 and salary <= 600 then '2'
when salary > 600 and salary <= 800 then '3'
when salary > 800 and salary <= 1000 then '4'
else null end salary_class,
count(*)
from table_a
group by
case when salary <= 500 then '1'
when salary > 500 and salary <= 600 then '2'
when salary > 600 and salary <= 800 then '3'
when salary > 800 and salary <= 1000 then '4'
else null end;
二,用一个sql语句完成不同条件的分组。
有如下数据
| 国家(country) |
性别(sex) |
人口(population) |
| 中国 |
1 |
340 |
| 中国 |
2 |
260 |
| 美国 |
1 |
45 |
| 美国 |
2 |
55 |
| 加拿大 |
1 |
51 |
| 加拿大 |
2 |
49 |
| 英国 |
1 |
40 |
| 英国 |
2 |
60 |
| 国家 |
男 |
女 |
| 中国 |
340 |
260 |
| 美国 |
45 |
55 |
| 加拿大 |
51 |
49 |
| 英国 |
40 |
60 |
普通情况下,用union也可以实现用一条语句进行查询。但是那样增加消耗(两个select部分),而且sql语句会比较长。
下面是一个是用case函数来完成这个功能的例子
select country,
sum( case when sex = '1' then
population else 0 end), --男性人口
sum( case when sex = '2' then
population else 0 end) --女性人口
from table_a
group by country;
这样我们使用select,完成对二维表的输出形式,充分显示了case函数的强大。
三,在check中使用case函数。
在check中使用case函数在很多情况下都是非常不错的解决方法。可能有很多人根本就不用check,那么我建议你在看过下面的例子之后也尝试一下在sql中使用check。
下面我们来举个例子
公司a,这个公司有个规定,女职员的工资必须高于1000块。假如用check和case来表现的话,如下所示
constraint check_salary check
( case when sex = '2'
then case when salary > 1000
then 1 else 0 end
else 1 end = 1 )
constraint check_salary check
( sex = '2' and salary > 1000 )
转自:http://blog.csdn.net/xuxurui007/article/details/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/64412.html