
一般读写分离,主库做增删改等操作,从库做查询操作。如果查询多的话,可以配置一主多从。SHARDINGJDBC 最开始是由当当网开始的一个开源项目。由于反响好,直接进入 apache 的孵化项目,更名为 shareingsphere。
github 项目地址: https://github.com/apache/incubator-shardingsphere
一、准备工作
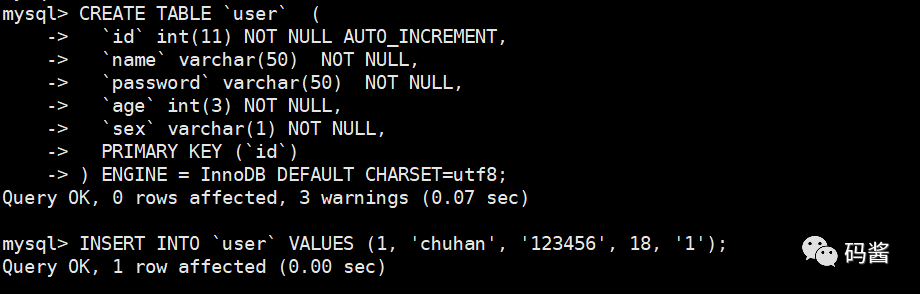
1,我们先在主库创建一个 user 表,插入一条记录
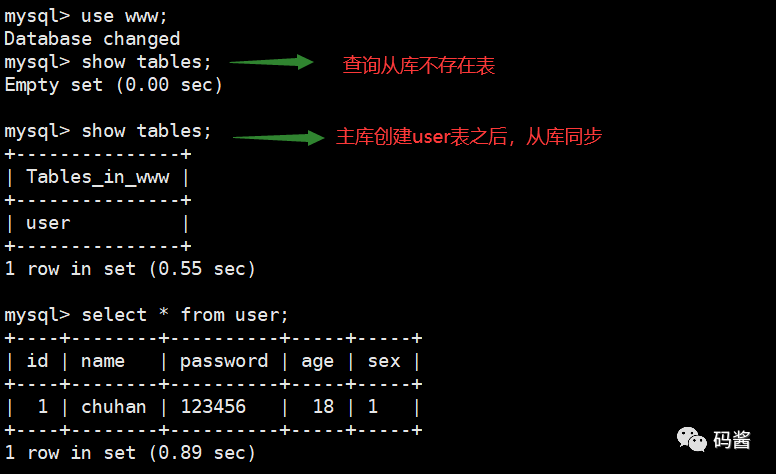
2,查询从库
3,为了方便操作,我们直接在客户端 navicat 上连接主从库
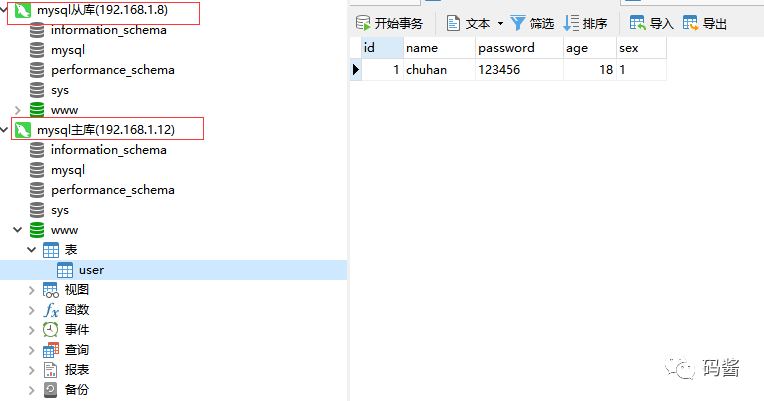
准备工作已经大致 ok 了…
进入正题
二、使用 spring boot 整合 shardingjdbc
1,pom 文件引入 shardingjdbc 的 jar
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency> 讯享网
2,配置 application.yml 文件
讯享网spring: shardingsphere: props: sql: show: true datasource: names: master,slave #对应下面主从库 master: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.1.12:3306/www?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai username: root password: slave: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.1.8:3306/www?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai username: root password: masterslave: load-balance-algorithm-type: round_robin #负载 轮询,当你有多个从库或者主库时 name: ms master-data-source-name: master #设置主库 slave-data-source-names: slave #设置从库
很简单吧,就加了些配置信息,SHARDINGSPHERE 会帮你自动切库,当你做增删改时,会直接操作主库,当你做查询操作时,会直接查询从库,这里数据库压力就可以平摊出来了而我们一般的系统都是增删改少,查询多,就可以多设置几个从库。

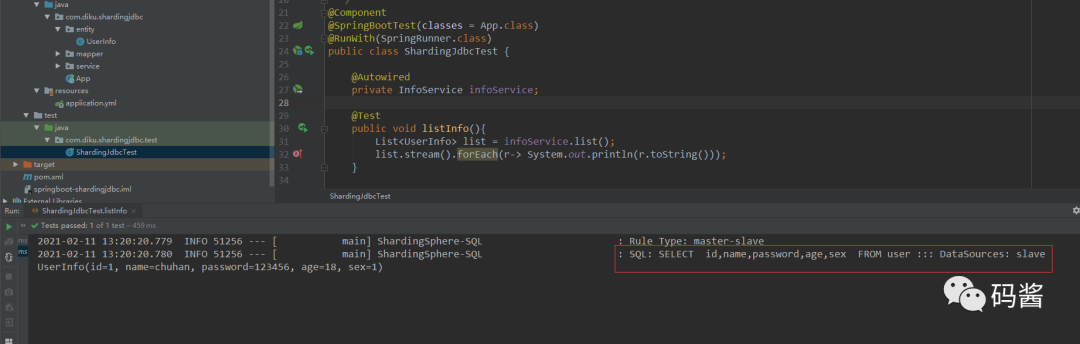
- 查询所有
@Component @SpringBootTest(classes = App.class) @RunWith(SpringRunner.class) public class ShardingJdbcTest { @Autowired private InfoService infoService; @Test public void listInfo(){ List<UserInfo> list = infoService.list(); list.stream().forEach(r-> System.out.println(r.toString())); } } 可以从日志看出,查询操作的是从库 slave
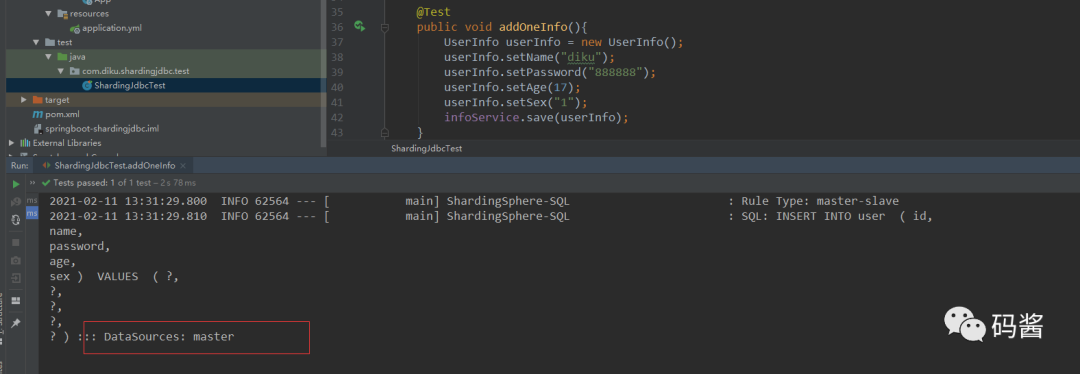
- 插入一条数据
讯享网@Test public void addOneInfo(){ UserInfo userInfo = new UserInfo(); userInfo.setName("diku"); userInfo.setPassword(""); userInfo.setAge(17); userInfo.setSex("1"); infoService.save(userInfo); }
可以从日志看出,新增操作的是主库 master
- 查询刚刚插入的数据
@Test public void getOneInfoByName(){ QueryWrapper<UserInfo> query = new QueryWrapper<>(); query.eq("name","diku"); UserInfo u = infoService.getOne(query); System.out.println(u); } 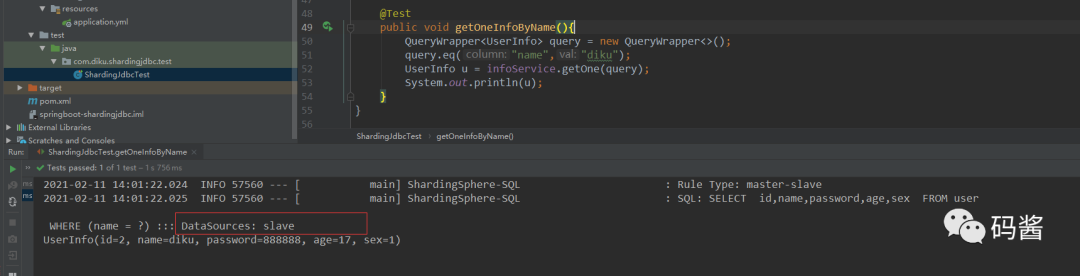
到这里,我们就基本实现了 spring boot 整合 shardingjdbc 的读写分离操作了。
原文 来自“码酱”公众号
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/64042.html