
目录
第一周
Welcome
Machine Learning Honor Code
Introduction
Supervised Learning(监督学习)
Unsupervised Learning(无监督学习)
Who are Mentors?
Get to Know Your Classmates
Frequently Asked Questions
Model and Cost Function
Model Representation
Cost Function
Parameter Learning
梯度下降(Gradient Descent)
Linear Algebra Review
第二周
Environment Setup Instructions
Multivariate Linear Regression
Multiple Features
Gradient Descent For Multiple Variables
Gradient Descent in Practice I - Feature Scaling
Gradient Descent in Practice II - Learning Rate
Features and Polynomial Regression
Computing Parameters Analytically
Normal Equation
Normal Equation Noninvertibility
Submiting Programing Assignments
Working on and Submitting Programming Assignments
Programming tips from Mentors
Octave Tutorial
Basic Operations 命令行操作
Moving Data Around 数据和矩阵操作
Computing on Data
Plotting Data 一般画图工具
Control Statements: for, while, if statement
其他
ex-1
Coursera-机器学习![]()
讯享网https://www.coursera.org/learn/machine-learning/
第一周
Welcome
Machine Learning Honor Code
介绍了在课程和提交作业中,欢迎讨论,拒绝对代码的剪切粘贴。
介绍了哪些问题是合适的,哪些是不合适的。示例如下:
不合适的:我代码跑不了了,怎么改?代码如下:……;用英文theta代替希腊字母θ的数学问题
合适的:如何在矩阵中取子集来消除截距(eliminate the intercept)?
Introduction
Supervised Learning(监督学习)
首先介绍了一个房价预测例子,你可以选择用直线或者一元二次方程(a quadratic function, or a second-order polynomial)来预测一栋房子大概能卖出多少钱。
然后定义了有监督学习,即用于训练算法的数据集有标签or标准答案(The term Supervised Learning refers to the fact that we gave the algorithm a data set in which the, called, "right answers" were given. )
对于现实生活中出现的监督学习术语(terminology)定义如下:
- 回归问题(regression problems):预测的输出值可以被认为是连续的实数
- 分类问题(classification problems):预测的输出值为离散值
当数据量过大时可以用支持向量机(Support Vector Machine)来解决电脑内存告急的状况
Unsupervised Learning(无监督学习)
无监督学习指的是给出具有许多特征的数据,但单个数据体并无特定结果or标签,在并不清楚每个特征的作用下,通过机器学习来对数据进行有结构的组织。
聚类问题(Clustering problems): 将数据集划分到具体的类别里
非聚类问题(Non-clustering problems): 知名算法 "Cocktail Party Algorithm",可以在有干扰项的情况下找出想要的数据
Who are Mentors?
用于课程内容交流的论坛,由已结课的志愿者维护![]() https://www.coursera.org/learn/machine-learning/discussions
https://www.coursera.org/learn/machine-learning/discussions
Get to Know Your Classmates
线上交友活动,新人报道thread,但是当前社区内容已不可见
Frequently Asked Questions
常见问题解答,挑一些我感兴趣的记录一下:
- 课程所需基础:编程、基本概率论、基本线性代数
- 推荐使用语言:Matlab or Octave
- 课程帮助中心
- 一些提交在线问题的格式:分数化简成两位小数;一个元素的矩阵不需要带括号;
Model and Cost Function
Model Representation
给出了监督学习和符号的定义,如下图,有监督式学习其目的为给出训练集,得到一个预测函数(hypothesis)能够很好的根据输入的X预测出Y。根据Y是离散的还是连续的,又可以分为回归问题和分类问题。

![]() 指代第i个输入值和预测值。
指代第i个输入值和预测值。
Cost Function
我们可以评判一个预测函数的好坏,通过成本函数值。对于回归问题,均方误差函数(square error function/Mean squared error)是比较适用的,课程中的定义如下:

它也可以写作 ,其中表示预测函数与实际值之差()的平方的平均值
,其中表示预测函数与实际值之差()的平方的平均值
等高线图(contour plot):
一个等高线图由许多条等高线组成,每个同样颜色的等高线代表其线上的θ0,θ1对应的成本函数值相等。
Parameter Learning
梯度下降(Gradient Descent)

需要了解过微积分中的偏导数(partial derivatives)和导数(derivatives)的知识。梯度下降法给出当前每个θ的下一步迭代结果,从而使J(θ)的计算结果最小。
1. 当前讨论的是简单的成本函数,包括θ0和θ1,所以是j=0和j=1的两种情况。

2. a:=b代表b赋值给a,对应的a=b代表判断a和b是否相等
3. α是学习步长,当步长初始设置的过大时下降可能会震荡,当过小时下降速率太慢。课程视频展示了为什么不需要随着时间推移调整步长也能收敛到代价函数区间最小值(因为越接近该点斜率的绝对值越小,所以步长和导数的乘积自己就慢慢变小),很生动。
4. 是偏导数,代表该点切线的斜率,也是下降速度最快的方向
Linear Algebra Review
一些矩阵的基础知识和一份简单的Octave示例代码。包括矩阵相加、常数乘法、矩阵乘向量、矩阵乘矩阵、矩阵的性质、矩阵的转置和矩阵的逆
这里吐槽一下csdn竟然没有matlab的高亮……
%% Matrix and Vector % The ; denotes we are going back to a new row. A = [1, 2, 3; 4, 5, 6; 7, 8, 9; 10, 11, 12] % Initialize a vector v = [1;2;3] % Get the dimension of the matrix A where m = rows and n = columns [m,n] = size(A) % You could also store it this way dim_A = size(A) % Get the dimension of the vector v dim_v = size(v) % Now let's index into the 2nd row 3rd column of matrix A A_23 = A(2,3) %% Addition and Scalar Multiplication % Initialize matrix A and B A = [1, 2, 4; 5, 3, 2] B = [1, 3, 4; 1, 1, 1] % Initialize constant s s = 2 % See how element-wise addition works add_AB = A + B % See how element-wise subtraction works sub_AB = A - B % See how scalar multiplication works mult_As = A * s % Divide A by s div_As = A / s % What happens if we have a Matrix + scalar? add_As = A + s %% Matrix Vector Multiplication % Initialize matrix A A = [1, 2, 3; 4, 5, 6;7, 8, 9] % Initialize vector v v = [1; 1; 1] % Multiply A * v Av = A * v % Matrix Matrix Multiplication % Initialize a 3 by 2 matrix A = [1, 2; 3, 4;5, 6] % Initialize a 2 by 1 matrix B = [1; 2] % We expect a resulting matrix of (3 by 2)*(2 by 1) = (3 by 1) mult_AB = A*B % Make sure you understand why we got that result %% Matrix Multiplication Properties % Initialize random matrices A and B A = [1,2;4,5] B = [1,1;0,2] % Initialize a 2 by 2 identity matrix I = eye(2) % The above notation is the same as I = [1,0;0,1] % What happens when we multiply I*A ? IA = I*A % How about A*I ? AI = A*I % Compute A*B AB = A*B % Is it equal to B*A? BA = B*A % Note that IA = AI but AB != BA %% Inverse and Transpose % Initialize matrix A A = [1,2,0;0,5,6;7,0,9] % Transpose A A_trans = A' % Take the inverse of A A_inv = inv(A) % What is A^(-1)*A? A_invA = inv(A)*A讯享网
第二周
Environment Setup Instructions
可以选择Octave或者Matlab,Octave官网
Octave提交遇到问题可以看参考网址
Multivariate Linear Regression
Multiple Features
多变量线性拟合![]() 可以被简写为:
可以被简写为:

Gradient Descent For Multiple Variables
梯度下降公式结构如下:

等价于以下的格式:

Gradient Descent in Practice I - Feature Scaling
在每个变量数值差异过大时,梯度下降会震荡从而降低表现性能。处理数据时的小技巧:
1. feature scaling 数据规模标准化,参考范围为[-1, 1],在这个基础上扩大或缩小三倍都是可接受的。
2. mean normalization,使数据的中位数接近0
公式可以总结为:
其中,μi是平均值,si是{max-min}的x范围或标准差。
Gradient Descent in Practice II - Learning Rate
1. Debugging gradient descent. 通过作图的方式,每一批次的下降后画出当前的Cost Function值,来判断α的大小是否合适。α过大时,图像会震荡或上升,α过小时,图像会下降的非常缓慢,正确的α可以通过多次测试来得出,如尝试:0.001/0.003/0.01/0.03/0.1/.....

2. Automatic convergence test. 当这次迭代J(θ)下降不超过在某个数值区间,如10-3,则认为已收敛到**位置,但在实际应用中,这个数字范围的选择是很难把握的。
Features and Polynomial Regression
我们可以通过变换特征值和预测函数来更好的做预测工作,如可以合并两个特征值为1个,或使用平方、立方、开方等作为预测函数。此时的回归仍为线性回归,可以把平方or开方后的特征值视为一个新的x。如:可以把视为
Computing Parameters Analytically
Normal Equation
对于一些特征值较少的情况,可以通过叫Normal Equation的方法来直接计算出最适合的θ值,给出公式如右,这里并不进行证明:,具体X和y的定义见下图:

对于normal equation还是gradient decent的选择,一般以特征数量的多少作为参考,梯度下降的复杂度为n^2,而正规方程则是n^3,一般以10,000作为考虑用梯度下降的分界点。
ps:此时不需要考虑feature scaling
Normal Equation Noninvertibility
注意到上个式子存在逆运算,所以如果不可逆怎么办?
1. 当X内部存在线性关系(此时X矩阵的秩不满),可以删掉线性相关的特征
2. 特征数大于样本数,可以删掉部分特征
不过在Octave中我们使用的是pinv来求解逆运算,所以即使不可逆也会求得矩阵的伪逆,所以一般不用处理上述问题。
补充阅读:矩阵秩的性质 ,pinv和inv
Submiting Programing Assignments
Working on and Submitting Programming Assignments
视频演练了如何提交homework,我在windows下试了一遍:
1. 通过windows菜单直接打开Octave-cli(或者在gui界面下的命令窗口也行)
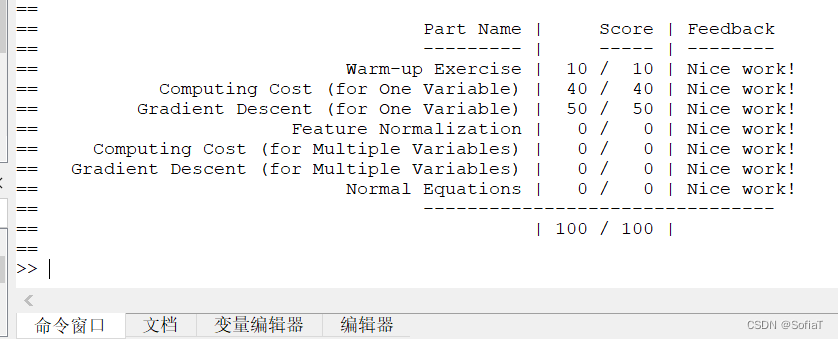
2. 做好作业后,cd到作业目录,键入submit,输入账号和token,一键提交本周作业
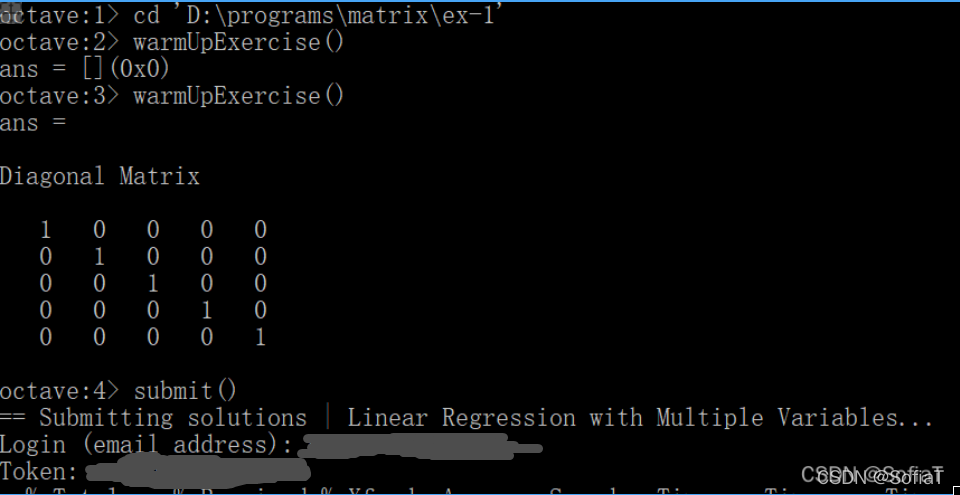
ps:账号和密码在week2的作业页面可见
Programming tips from Mentors
1. 关于标量和矩阵的不同写法 Confused about "h(x) = theta' * x" vs. "h(x) = X * theta?"
在pdf和课程中,小写字母代表向量,大写字母代表矩阵,所以前一种表示是参数向量的转置(1*m)乘上一个样本(m*1)的预测值(一个标量数值),后一个写法是全部样本(n*m)乘上参数向量(m*1)的预测值(y向量,n*1)
2. 常用提示
a. 提问前搜索论坛,我觉得很有用,我就是在论坛中搜到token所在页面的。
b. octave命令行操作调用文件不需要加上后缀.m,无参数函数也不需要加括号(我试了一下,加不加括号都能运行)
c. submit分数测试集的大小可能和pdf不一致,所以不要写死数组下标和矩阵规模,防止不能通过所有样例
d. 可以通过unit tests来debug自己的代码,或者去论坛问
Octave Tutorial
介绍了Octave的使用方式
Basic Operations 命令行操作
讯享网1 ~= 2 % 与cpp等语言的!=不同,这里~=是不等于号 % 输出:1 PS1('>>') % 替换命令行默认前缀octave:n> % 之后所有输出前缀为 >> a = pi format long % 显示精度上升 disp(a) % 输出:3.9793 format short % 显示精度下降 disp(a) % 输出:3.1416 disp(sprintf('2 digits:%0.2f', a)) % 与cpp的字符串输出类似 % 输出:2 digits:3.14 w = -6 + sqrt(10)*(randn(1,10000)); % randn是符合正态分布的[-4,4]范围数据 % 加上分号;表示不在命令行里显示w(数据量太大) hist(w) % 输出:w的直方图统计 v = 1:0.1:1.5 % 按照步长0.1 % 输出:是一个1*6的数组 v = 1.0000 1.1000 1.2000 1.3000 1.4000 1.5000 v = 1:10 % 输出:是一个1*10的数组 v = 1 2 3 4 5 6 7 8 9 10 ones(2, 3) ans = 1 1 1 1 1 1 eye(5) ans = Diagonal Matrix 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 zoros(3) ans = 0 0 0 0 0 0 whos % 查看所有变量与详细 % 输出: Variables visible from the current scope: variables in scope: top scope Attr Name Size Bytes Class ==== ==== ==== ===== ===== A 7x7 56 double X 7x7 392 double a 1x1 8 double ans 3x2 48 double tempFile 3x2 48 double v 1x10 24 double w 1x10000 80000 double x 7x1 56 double y 7x1 56 double Total is 10135 elements using 80688 bytes who % 查看变量名 clear v % 删除变量v, 单纯的clear就是clear all help [操作名] % 操作名的readme帮助手册
以及cd/ls等类似linux的命令
Moving Data Around 数据和矩阵操作
Computing on Data
>>A = [1 2;3 4;5 6] A = 1 2 3 4 5 6 >>B = [11 12; 13 14; 15 16] B = 11 12 13 14 15 16 >>C = [1 1; 2 2] C = 1 1 2 2 % 对每个像素进行运算,在操作符前加上. >>A .* B ans = 11 24 39 56 75 96 >>A .^ 2 ans = 1 4 9 16 25 36 >>A' % A的转置 ans = 1 3 5 2 4 6 >>a = [1 15 2 0.5] a = 1.0000 15.0000 2.0000 0.5000 >>sum(a) % 所有元素相加 ans = 18.500 >>prod(a) % 所有元素相乘 ans = 15 >>floor(a) % 向下取整 ans = 1 15 2 0 >>ceil(a) % 向上取整 ans = 1 15 2 1 >>A = magic(3) A = 8 1 6 3 5 7 4 9 2 >>[r, c] = find(A >= 7) % 找到A中大于等于7的元素的r 行坐标、 c 列坐标 r = 1 3 2 c = 1 2 3 >>A(3, 2) ans = 9 % find(A<4) 是找到A中所有小于元素的值,find函数非常灵活 >>max(A, [], 1) % 查找每列的最大值,也是默认max(A)的结果 ans = 8 9 7 >>max(A, [], 2) % 查找每行的最大值 ans = 8 7 9 >>sum(A, 1) % 每列相加 >>sum(A, 2) % 每行相加 >>sum(sum(A.*eye(3))) % 每对角线相加Plotting Data 一般画图工具
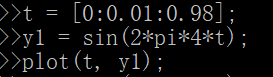

讯享网>>t = [0:0.01:0.98]; >>y1 = sin(2*pi*4*t); >>y2 = cos(2*pi*4*t); >>plot(t,y2); >>hold on; % 在上一个plot的基础上添加新图像 >>plot(t, y1, 'r'), >>xlabel('time') % x坐标轴名称 >>ylabel('value') % y坐标轴名称 >>legend('sin', 'cos') % 不同线代表的含义(右上角的角标) >>title('my plot') % 图标题 >>print -dpng 'myPlot.png' % 将图片保存到当前文件夹
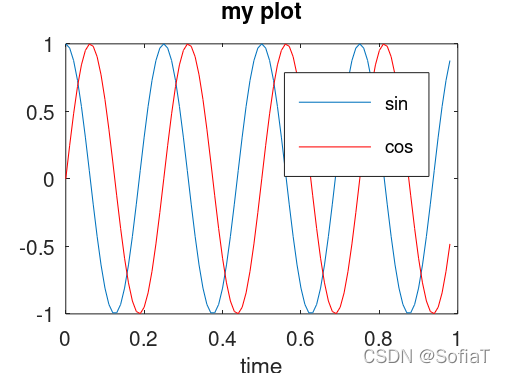
>>close % 关闭上个绘图 >>figure(1); plot(t,y1); % 加上figure相当于新声明了一个图像窗口 >>figure(2); plot(t,y2); % 新弹出一个图像窗口,有点类似于一个新的windows GUI讯享网>>subplot(1, 2, 1); plot(t, y1); >>subplot(1, 2, 2); plot(t, y2);

>>A = magic(5) A = 17 24 1 8 15 23 5 7 14 16 4 6 13 20 22 10 12 19 21 3 11 18 25 2 9 >>imagesc(A) % 用颜色来表示数值 >>imagesc(A), colorbar, colormap gray; % 灰度图,感觉可以用于图像处理 
Control Statements: for, while, if statement
写法类似python和matlab
其他
1. 可以添加路径方便启动函数

ex-1
ex1_multi
ex1.pdf里面的指引很详细,能理解课程ppt的话做作业没问题。主要讲一下ex1_multi,分为以下几个处理步骤:
- Scaling:作业要求写的scaling具有普适性,除了对当前训练集生效,对其他规模的数据也要能使用。scaling需要返回μ和std,以便处理测试集数据,θ是在scaling后的训练集上得到的,如果不处理肯定预测结果是不对的。
- gradient descent:重点是如何把公式向量化、矩阵化,这样在Octave中能大大减少代码量,不用写循环语句。我推的过程是:写出X矩阵和y向量的具体表达形式 → 写出J(θ)和新θ的数值表达式 → 通过观察形式、观察矩阵的大小(m*n矩阵乘上 n*1矩阵,大小会变为m*1)作为辅助推的依据。
- α的选择:除了下降慢和非收敛的情况,当α巨大的时候,甚至可能会导致数据NAN,运行错误。
- θ0:因为我是学了week3再来写的这一部分,在week3中为了使图像更平滑,在J(θ)的计算中把每个θ的平方和也加了进来,但是θ0不包括在内。所以对θ0这里是否也应该出现产生了混淆。其实只要把公式矩阵化的过程推导一遍就不会有这种疑惑了,这里θ0的处理和其他的θ是一致的,不需要单独考虑。
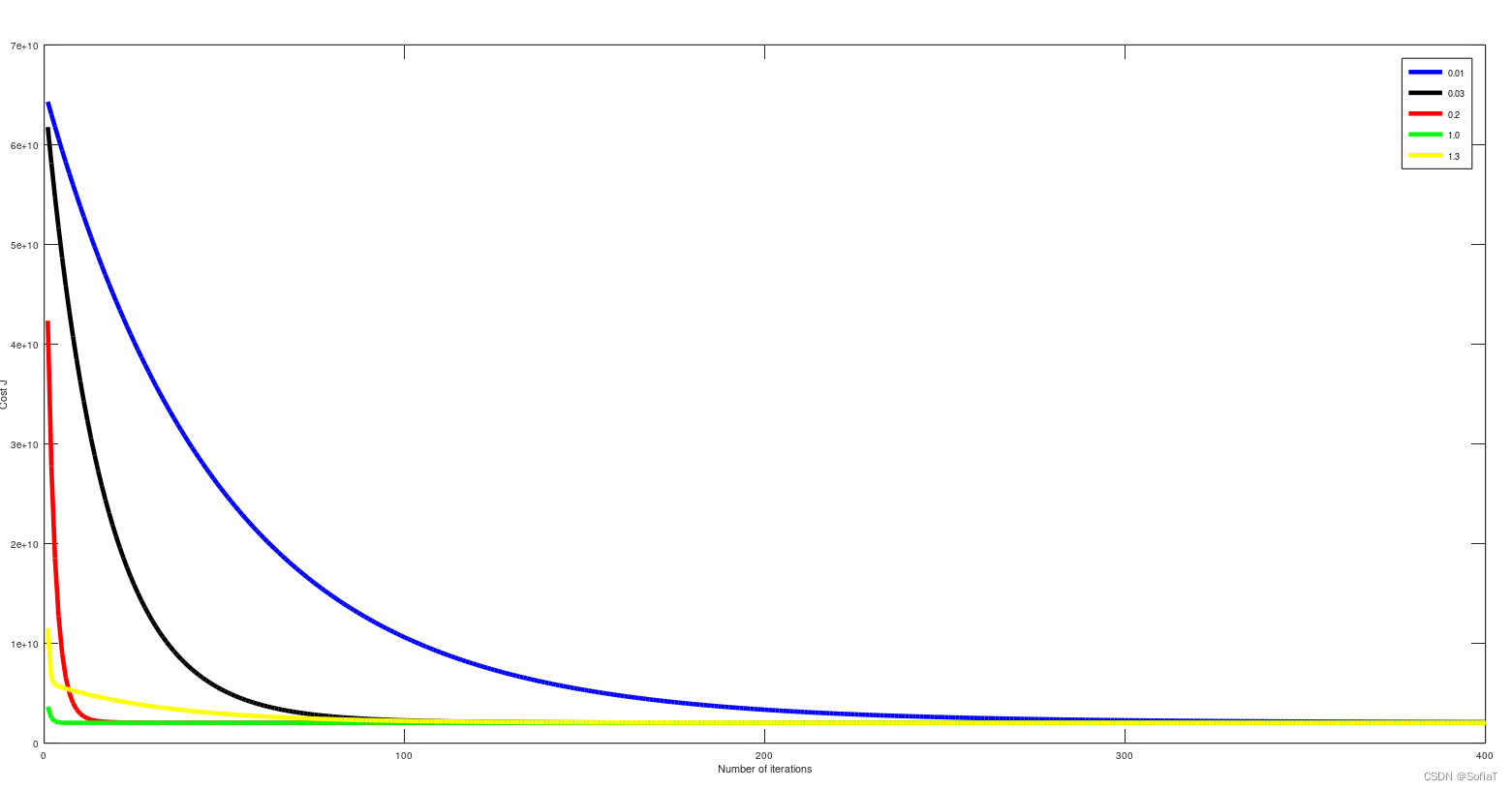
不同α下的Cost Function迭代值,0.03比较适合这个问题,在1.3处出现了震荡:
To be continued:
- scaling时,除数选择xmax-xmin还是std?二者有什么不同?
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/63053.html