
ID3算法
信息熵:
熵是度量样本集合纯度最常用的一种指标,代表一个系统中蕴含着多少信息量,信息量越大表面一个系统不确定性就越大,就存在跟多的可能性,即信息熵越大
假定当前样本集合D中第k类样本所占的比例为 P k P_k Pk(k=1,2,……,|y|),则D的信息熵为:
E n t = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent = -\sum_{k=1}^{|y|} p_k log_2p_k Ent=−∑k=1∣y∣pklog2pk
其中,|y|表示样本类被种数, p k p_k pk表示第k类样本所占比例,且 0 ≤ p k ≤ 1 , ∑ k = 1 n p k = 1 0\leq p_k \leq1,\sum_{k=1}^{n}p_k=1 0≤pk≤1,∑k=1npk=1
信息熵满足以下不等式:
0 ≤ E n t ( D ) ≤ l o g 2 ∣ y ∣ 0\leq Ent(D) \leq log_2|y| 0≤Ent(D)≤log2∣y∣ y表示样本D中的个数
若令|y|=n, p k = x k p_k=x_k pk=xk,那么信息熵 E n t ( D ) Ent(D) Ent(D)就可以看作一个n元的实值函数,即
E n t ( D ) = f ( x 1 , … … , x n ) = − ∑ k = 1 n x k l o g 2 x k Ent(D) = f(x_1,……,x_n)=-\sum_{k=1}^nx_klog_2x_k Ent(D)=f(x1,……,xn)=−∑k=1nxklog2xk,其中: 0 ≤ x q ≤ 1 , ∑ k = 1 n x k = 1 0\leq x_q \leq1,\sum_{k=1}^nx_k=1 0≤xq≤1,∑k=1nxk=1
引入拉格朗日乘子法 λ \lambda λ
L ( x 1 , … … x n , λ ) = − ∑ k = 1 n x k l o g 2 x k + λ ( ∑ k = 1 n x k − 1 ) L(x_1,……x_n,\lambda)=-\sum_{k=1}^nx_klog_2x_k+\lambda(\sum_{k=1}^nx_k-1) L(x1,……xn,λ)=−∑k=1nxklog2xk+λ(∑k=1nxk−1)
对L分别关于 x , λ x,\lambda x,λ求一阶偏导,并令偏导等于0:
∂ ( x 1 , … … , x n , λ ) ∂ x 1 = ∂ ∂ x 1 [ − ∑ k = 1 n x k l o g 2 x k + λ ( ∑ k = 1 n x k − 1 ) ] = 0 \frac{\partial(x_1,……,x_n,\lambda)}{\partial x_1}=\frac{\partial }{\partial x_1}[-\sum_{k=1}^{n}x_klog_2x_k+\lambda (\sum _{k=1}^{n}x_k-1)] = 0 ∂x1∂(x1,……,xn,λ)=∂x1∂[−∑k=1nxklog2xk+λ(∑k=1nxk−1)]=0
= − l o g 2 x 1 − x 1 ⋅ 1 x 1 l n 2 + λ = 0 = -log_2 x_1-x_1 \cdot\frac{1}{x_1ln2}+\lambda=0 =−log2x1−x1⋅x1ln21+λ=0
= − l o g 2 x 1 − 1 l n 2 + λ = 0 =-log_2x_1-\frac{1}{ln2}+\lambda=0 =−log2x1−ln21+λ=0
⇒ λ = l o g 2 x 1 + 1 l n 2 \Rightarrow\lambda=log_2x_1+\frac{1}{ln2} ⇒λ=log2x1+ln21
同理可推:
λ = l o g 2 x 1 + 1 l n 2 = l o g 2 x 2 + 1 l n 2 = … … = l o g 2 x n + 1 l n 2 \lambda = log_2x_1+\frac{1}{ln2}=log_2x_2+\frac{1}{ln2}=……=log_2x_n+\frac{1}{ln2} λ=log2x1+ln21=log2x2+ln21=……=log2xn+ln21
对于任意的x,满足约束条件:
∑ k = 1 n x k = 1 \sum_{k=1}^{n}x_k=1 ∑k=1nxk=1
因此:
x 1 = x 2 = x 3 … … = x n = 1 n x_1 = x_2 = x_3……=x_n=\frac{1}{n} x1=x2=x3……=xn=n1
最大值点还是最小值点需要做个简单的检验:
当 x 1 = x 2 = x 3 … … = x n = 1 n x_1 = x_2 = x_3……=x_n=\frac{1}{n} x1=x2=x3……=xn=n1时:
f ( 1 n , … … 1 n ) = − ∑ k = 1 n 1 n l o g 2 1 n = − n ⋅ l o g 2 1 n = l o g 2 n f(\frac{1}{n},……\frac{1}{n})=-\sum^{n}_{k=1}\frac{1}{n}log_2\frac{1}{n}=-n\cdot log_2\frac{1}{n}=log_2n f(n1,……n1)=−∑k=1nn1log2n1=−n⋅log2n1=log2n
将 x 1 = 1 , x 2 = x 3 = … … = x n = 0 时 x_1=1,x_2=x_3=……=x_n=0时 x1=1,x2=x3=……=xn=0时:
f ( 1 , 0 , … … , 0 ) = − 1 ⋅ l o g 2 1 − 0 ⋅ l o g 2 0 … … − 0 ⋅ l o g 2 0 = 0 f(1,0,……,0)=-1\cdot log_21-0\cdot log_20……-0\cdot log_20=0 f(1,0,……,0)=−1⋅log21−0⋅log20……−0⋅log20=0
显然 l o g 2 n ≥ 0 log_2n\geq 0 log2n≥0,所以 x 1 = x 2 … … = x n = 1 n x_1=x_2……=x_n=\frac{1}{n} x1=x2……=xn=n1为最大值点,最大值为 l o g 2 n log_2n log2n
下面考虑求 f ( x 1 , … … , x n ) f(x_1,……,x_n) f(x1,……,xn)的最小值,仅考虑 0 ≤ x k ≤ 1 , f ( x 1 , … … , x n ) 0\leq x_k\leq 1,f(x_1,……,x_n) 0≤xk≤1,f(x1,……,xn)可以看作是n个互不相关一元函数的加和,即:
f ( x 1 , … … , x n ) = ∑ k = 1 n g ( x k ) f(x_1,……,x_n) = \sum_{k=1}^{n}g(x_k) f(x1,……,xn)=∑k=1ng(xk)
g ( x k ) = − x k l o g 2 x k , 0 ≤ x k ≤ 1 g(x_k)=-x_klog_2x_k,0\leq x_k\leq 1 g(xk)=−xklog2xk,0≤xk≤1
求 g ( x i ) g(x_i) g(xi)的最小值,但因为其表达式相同。所以只求出一个就可。
求 g ( x 1 ) g(x_1) g(x1)的最小值,首先对 g ( x 1 ) g(x_1) g(x1)关于 x 1 x_1 x1求一阶、二阶导数:
g ( x 1 ) ′ = d ( − x 1 l o g 2 x 1 ) d x 1 = − l o g 2 x 1 − x 1 ⋅ 1 x 1 l n 2 = − l o g 2 x 1 − l n 2 g(x_1)' = \frac{d(-x_1log_2x_1)}{dx_1}=-log_2x_1-x_1\cdot \frac{1}{x_1ln2}=-log_2x_1-ln2 g(x1)′=dx1d(−x1log2x1)=−log2x1−x1⋅x1ln21=−log2x1−ln2
g ( x 1 ) ′ ′ = d ( − l o g 2 x 1 − 1 l n 2 ) d x 1 = − 1 x 1 l n 2 g(x_1)''=\frac{d(-log_2x_1-\frac{1}{ln2})}{dx_1}=-\frac{1}{x_1ln2} g(x1)′′=dx1d(−log2x1−ln21)=−x1ln21
在定义域 0 ≤ x k ≤ 1 0\leq x_k \leq 1 0≤xk≤1上,始终有 g ′ ′ ( x 1 ) = − 1 x 1 l n 2 < 0 g''(x_1)=-\frac{1}{x_1ln2}<0 g′′(x1)=−x1ln21<0,即 g ( x i ) g(x_i) g(xi)为开口向下的凹函数,最小值在边界 x 1 = 0 x_1=0 x1=0或 x 1 = 1 x_1=1 x1=1处取得:
g ( 0 ) = − 0 l o g 2 0 = 0 g(0) = -0log_20=0 g(0)=−0log20=0
g ( 1 ) = − 1 l o g 2 1 = 0 g(1)=-1log_21=0 g(1)=−1log21=0
g ( x 1 ) g(x_1) g(x1)的最小值即为0,同理可得 g ( x 2 ) … … g ( x n ) g(x_2)……g(x_n) g(x2)……g(xn)的最小值也0,那么 f ( x 1 , … … , x n ) f(x_1,……,x_n) f(x1,……,xn)的最小值此时为0
如果令某个 x k = 1 x_k = 1 xk=1,那么根据约束条件 ∑ k = 1 n = 1 \sum_{k=1}^{n}=1 ∑k=1n=1可知:
x 1 = x 2 = … … = x k + 1 = … … = x n = 0 x_1=x_2=……=x_{k+1}=……=x_n=0 x1=x2=……=xk+1=……=xn=0
带入 f ( x 1 , … … , x n ) f(x_1,……,x_n) f(x1,……,xn)得:
f ( 0 , 0 … … 0 , 1 , 0 … … 0 ) = 0 f(0,0……0,1,0……0)=0 f(0,0……0,1,0……0)=0
所以 x k = 1 , x 1 = x 2 = … … = x k − 1 = x k + 1 = … … = x n = 0 x_k=1,x_1=x_2=……=x_{k-1}=x_{k+1}=……=x_n=0 xk=1,x1=x2=……=xk−1=xk+1=……=xn=0,一定是 f ( x 1 , … … , x n ) f(x_1,……,x_n) f(x1,……,xn)在满足约束条件下的最小值点,其最小值和为0。
所以说: 0 ≤ E n t ( D ) ≤ l o g 2 n 0\leq Ent(D)\leq log_2n 0≤Ent(D)≤log2n
信息增益
假定离散属性 α \alpha α有 V V V个可能的取值 α 1 , α 2 … … α V {\alpha ^1,\alpha^2……\alpha^V} α1,α2……αV,如果使用特征a来对数据集 D D D进行划分,则会产生 V V V个分支结点,其中第 v v v个结点包含了数据集 D D D中所有在特征 α \alpha α上取值为 α V \alpha^V αV的样本总数,记住 D v D^v Dv。再考虑到不同的分支结点所包含的样本数量不同,给分支结点赋予不同的权重,这样对样本数越多的分支点的影响就会越大,因此,就能够计算出特征对样本集 D D D进行划分所获得的“信息增益”:
G a i n ( D , α ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,\alpha) = Ent(D)-\sum_{v=1}^{V}\frac{|D^v|}{|D|}Ent(D^v) Gain(D,α)=Ent(D)−∑v=1V∣D∣∣Dv∣Ent(Dv)

讯享网
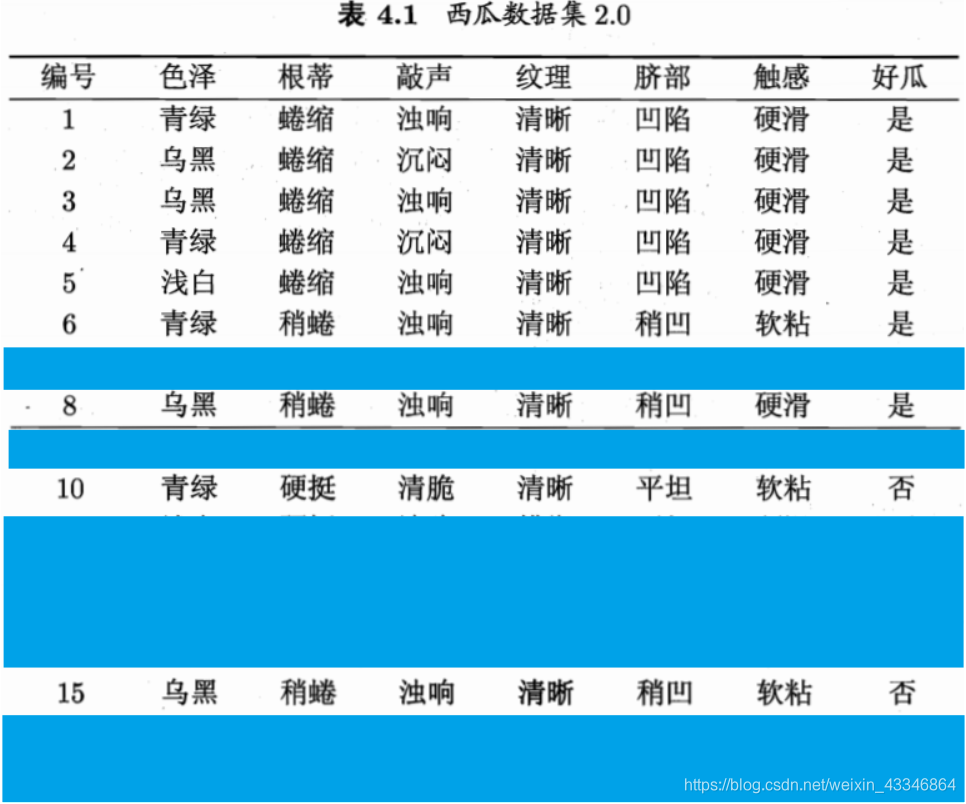
该数据集包含十七个样本、有五个属性。类别为好瓜(8/17)、坏瓜(9/17)
E n t ( D ) = − 8 17 ∗ l o g 2 8 17 − 9 17 ∗ l o g 2 9 17 = 0.9975 Ent(D)=-\frac{8}{17}*log_2\frac{8}{17}-\frac{9}{17}*log_2\frac{9}{17}=0.9975 Ent(D)=−178∗log2178−179∗log2179=0.9975
下面计算每个信息的信息增益
属性 a 1 a_1 a1:色泽
G a i n ( D , a 1 ) = E n t ( D ) − ∑ v = 1 3 E n t ( D v ) Gain(D,a_1) = Ent(D)-\sum_{v=1}^{3}Ent(D^v) Gain(D,a1)=Ent(D)−∑v=13Ent(Dv)
= E n t ( D ) − ( D 1 D × E n t ( D 1 ) + D 2 D × E n t ( D 2 ) + D 3 D × E n t ( D 3 ) ) =Ent(D)-(\frac{D^1}{D}\times Ent(D^1)+\frac{D^2}{D}\times Ent(D^2)+\frac{D^3}{D}\times Ent(D^3)) =Ent(D)−(DD1×Ent(D1)+DD2×Ent(D2)+DD3×Ent(D3))
对数据集进行色泽划分:D1青绿(包含6个样本)、D2乌黑(6个样本)、D3浅白(5个样本)

= 0.9975 − ( 6 17 ( − 3 6 l o g 2 3 6 − 3 6 l o g 2 3 6 ) + 6 17 ( − 4 6 l o g 2 4 6 − 2 6 l o g 2 2 6 + 5 17 ( − 1 5 l o g 2 1 5 − 4 5 l o g 2 4 5 ) ) =0.9975-(\frac{6}{17}(-\frac{3}{6}log_2\frac{3}{6}-\frac{3}{6}log_2\frac{3}{6})+\frac{6}{17}(-\frac{4}{6}log_2\frac{4}{6}-\frac{2}{6}log_2\frac{2}{6}+\frac{5}{17}(-\frac{1}{5}log_2\frac{1}{5}-\frac{4}{5}log_2\frac{4}{5})) =0.9975−(176(−63log263−63log263)+176(−64log264−62log262+175(−51log251−54log254))
= 0.1091 =0.1091 =0.1091
同理可求属性 a 2 a_2 a2:根蒂
G a i n ( D , a 2 ) = 0.1427 Gain(D,a_2) = 0.1427 Gain(D,a2)=0.1427
属性 a 3 a_3 a3:敲声
G a i n ( D , a 3 ) = 0.1408 Gain(D,a_3) = 0.1408 Gain(D,a3)=0.1408
属性 a 4 a_4 a4:纹理
G a i n ( D , a 4 ) = 0.3808 Gain(D,a_4)=0.3808 Gain(D,a4)=0.3808
属性 a 5 a_5 a5:脐部
G a i n ( D , a 5 ) = 0.2892 Gain(D,a_5) = 0.2892 Gain(D,a5)=0.2892
比较所得纹理属性的信息增益最大
然后对每一个分支节点做进一步划分,以下图中分支节点(“纹理=清晰”)为例,该结点包含的样本集合中有编号{1、2、3、4、5、6、8、10、15}的九个样例,可用属性集合为{色泽、根蒂、敲声、脐部、触感},基于样本集合(“纹理=清晰”)
样本集合(“纹理=清晰”)的信息熵为:
E n t ( D 2 ) = − 7 9 l o g 2 7 9 − 2 9 l o g 2 2 9 = 0.7642 Ent(D_2)=-\frac{7}{9}log_2\frac{7}{9}-\frac{2}{9}log_2\frac{2}{9}=0.7642 Ent(D2)=−97log297−92log292=0.7642
我们接下来选择色泽属性 α 1 \alpha_1 α1
G a i n ( D 2 , α 1 ) = E n t ( D 2 ) − ∑ v = 1 3 ∣ D 2 v ∣ D 2 E n t ( D 2 v ) Gain(D_2,\alpha_1)=Ent(D_2)-\sum_{v=1}^{3}\frac{|D_2^v|}{D_2}Ent(D_2^v) Gain(D2,α1)=Ent(D2)−∑v=13D2∣D2v∣Ent(D2v)
= E n t ( D 2 ) − ( D 2 1 D 2 × E n t ( D 2 1 ) + D 2 2 D 2 × E n t ( D 2 3 ) D 2 3 D 2 × E n t ( D 2 3 ) ) =Ent(D_2)-(\frac{D_2^1}{D_2}\times Ent(D_2^1)+\frac{D_2^2}{D_2}\times Ent(D_2^3)\frac{D_2^3}{D_2}\times Ent(D_2^3)) =Ent(D2)−(D2D21×Ent(D21)+D2D22×Ent(D23)D2D23×Ent(D23))
= 0.0431 =0.0431 =0.0431
根蒂属性, α 2 \alpha_2 α2:
G a i n ( D 2 , α 2 ) = 0.4581 Gain(D_2,\alpha_2)=0.4581 Gain(D2,α2)=0.4581
敲声属性 α 3 \alpha_3 α3:
G a i n ( D 2 , α 3 ) = 0.3308 Gain(D_2,\alpha_3)=0.3308 Gain(D2,α3)=0.3308
脐部属性 α 4 \alpha_4 α4:
G a i n ( D 2 , α 4 ) = 0.4581 Gain(D_2,\alpha_4)=0.4581 Gain(D2,α4)=0.4581
触感属性 α 5 \alpha_5 α5:
G a i n ( D 2 , α 5 ) = 0.4581 Gain(D_2,\alpha_5)=0.4581 Gain(D2,α5)=0.4581
| 属性 | 信息增益 |
|---|---|
| 色泽 | 0.0431 |
| 根蒂 | 0.4581 |
| 敲声 | 0.3308 |
| 脐部 | 0.4581 |
| 触感 | 0.4581 |
随机选择最大的其中之一作为划分属性,这里选择“根蒂”作为划分属性。

继续对上图中的每个分支结点递归进行划分,以上图中的结点{
“根蒂=蜷缩”}为例,设该样本集为{1,2,3,4,5},共五个样本,但这五个样本的label均为好瓜。因此均为正样本。得到的分支节点图为:

接下来对上图中结点(“根蒂=稍蜷”)进行划分,该点的样本集为{6,8,15},共3个样本。可用特征集为色泽、敲声、肚脐、触感进行计算信息增益、得到下表
| 属性 | 信息增益 |
|---|---|
| 色泽 | 0.251 |
| 敲声 | 0 |
| 脐部 | 0 |
| 触感 | 0.251 |
色泽触感作为最大,这里我们选择色泽。
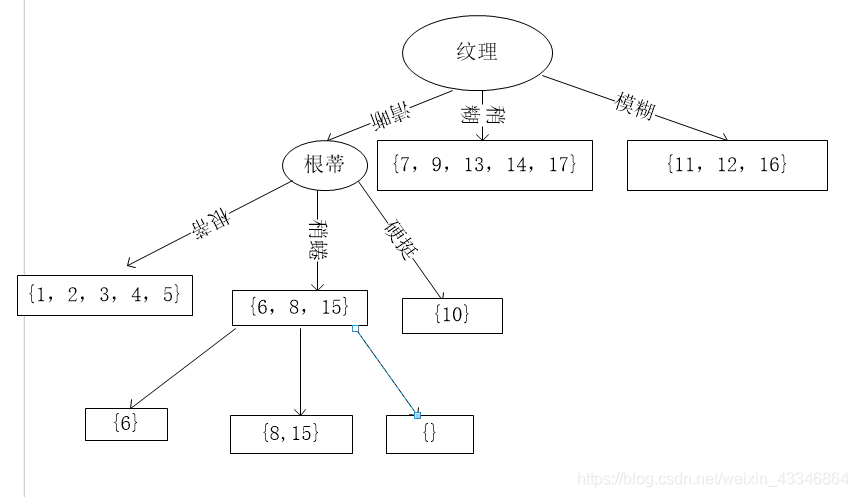
青绿为好瓜,递归返回对乌黑进行划分。色泽等于浅白此点为空,类别按照父节点中类别最高的样本所以色泽为浅白的类别为好瓜。
最终决策树如下图所示

ID3算法的不足:
- ID3没有考虑连续性
- ID3采用信息熵大的特征优先建立决策树的节点,取值比较多的特征比取值少的特征信息增益大。
- 未对缺失值做考虑
- 没有考虑过拟合的情况
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/61783.html