
(一) LDA模型的假设
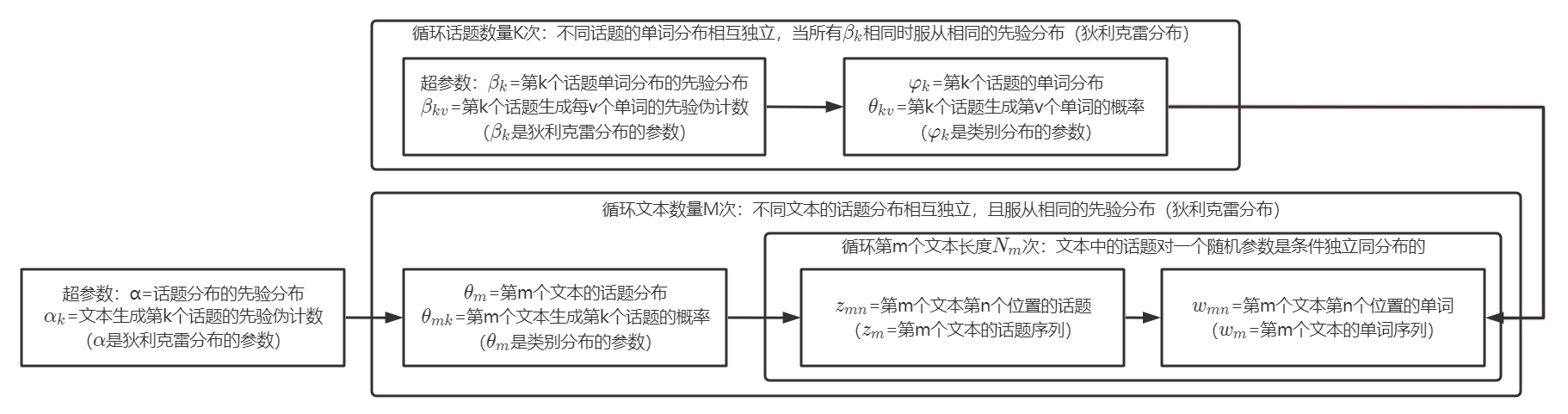
上图是LDA模型作为概率图模型的板块表示。从中可以看出LDA模型的基本假设:
- 文本中每个位置的话题相互独立;满足 P ( z m ∣ ψ ) = ∏ n = 1 N m P ( z m n ∣ ψ ) P(\textbf{z}_m|\psi) = \prod_{n=1}^{N_m} P(z_{mn}|\psi) P(zm∣ψ)=∏n=1NmP(zmn∣ψ),其中 ψ \psi ψ为所有影响 z m z_m zm的参数;也可以引入平均场理论,将其理解为参数以平均作用效果替代了单个作用效果的加和。
- 文本中每个位置的单词由该位置对应话题的单词分布决定;即 w m n = M u l t ( φ z m n ) w_{mn} = Mult(\varphi_{z_{mn}}) wmn=Mult(φzmn)。
- 文本中每个位置的单词相互独立,即经典的“词袋模型”;不考虑文本中单词的顺序,并假设文本中的每个单词同等重要;满足 P ( w m ∣ ψ ) = ∏ n = 1 N m P ( w m n ∣ ψ ) P(\textbf{w}_m|\psi) = \prod_{n=1}^{N_m} P(w_{mn}|\psi) P(wm∣ψ)=∏n=1NmP(wmn∣ψ),其中 ψ \psi ψ为所有影响 w m w_m wm的参数。
- 不同话题的单词分布相互独立;满足 P ( θ ∣ α ) = ∏ m = 1 M P ( θ m ∣ α ) P(\theta|\alpha) = \prod_{m=1}^M P(\theta_m|\alpha) P(θ∣α)=∏m=1MP(θm∣α);也满足 P ( z m n ∣ θ 1 , θ 2 , ⋯ , θ M ) = P ( z m n ∣ θ m ) P(z_{mn}|\theta_1,\theta_2,\cdots,\theta_M) = P(z_{mn}|\theta_m) P(zmn∣θ1,θ2,⋯,θM)=P(zmn∣θm), n = 1 , 2 , ⋯ , N m n=1,2,\cdots,N_m n=1,2,⋯,Nm。
- 不同文本的话题分布相互独立;满足 P ( φ ∣ β ) = ∏ k = 1 K P ( φ k ∣ β ) P(\varphi|\beta) = \prod_{k=1}^K P(\varphi_k|\beta) P(φ∣β)=∏k=1KP(φk∣β)。
(二) LDA模型的要素
LDA模型的随机变量:
所有文本的文本序列(文本序列的集合) W = { w 1 , w 2 , ⋯ , w M } \textbf{W} = \{\textbf{w}_1,\textbf{w}_2,\cdots,\textbf{w}_M\} W={ w1,w2,⋯,wM}是LDA模型的观测随机变量的数据。
所有文本的话题序列(话题序列的集合) Z = { z 1 , z 2 , ⋯ , z M } \textbf{Z} = \{ \textbf{z}_1,\textbf{z}_2,\cdots,\textbf{z}_M \} Z={ z1,z2,⋯,zM}是LDA模型的隐随机变量的数据。
LDA模型的随机变量的取值范围:
单词的取值范围,即所有文本中不同的单词的集合,称为单词集合,记作 W = { w 1 , w 2 , ⋯ , w V } W = \{ w_1,w_2,\cdots,w_V \} W={ w1,w2,⋯,wV},其中 V V V为文本中所有不同的单词的数量。
话题的取值范围,称为话题集合,记作 Z = { z 1 , z 2 , ⋯ , z K } Z = \{ z_1,z_2,\cdots,z_K \} Z={ z1,z2,⋯,zK},其中 K K K为话题数量。
LDA模型的超参数:
文本的话题分布的先验分布(狄利克雷分布)的参数 α \alpha α;实际上给出了话题序列的集合的先验分布 p ( Z ∣ α ) p(\textbf{Z}|\alpha) p(Z∣α)。
话题的单词分布的先验分布(狄利克雷分布)的参数 β \beta β;实际上给出了单词序列的集合的先验分布 p ( W ∣ Z , β ) p(\textbf{W}|\textbf{Z},\beta) p(W∣Z,β)。
LDA模型的参数:
话题数量 K K K。

LDA模型的需要求解的模型参数:
文本的话题分布 θ = { θ 1 , θ 2 , ⋯ , θ M } \theta = \{ \theta_1,\theta_2,\cdots,\theta_M \} θ={ θ1,θ2,⋯,θM}。
话题的单词分布 φ = { φ 1 , φ 2 , ⋯ , φ K } \varphi = \{ \varphi_1,\varphi_2,\cdots,\varphi_K \} φ={ φ1,φ2,⋯,φK}。
话题序列的集合的后验概率分布 p ( Z ∣ W , α , β ) p(\textbf{Z}|\textbf{W},\alpha,\beta) p(Z∣W,α,β)。
以上模型要素之间的关系,可以通过LDA模型训练的输入和输出体现:
- 输入:文本序列的集合 W \textbf{W} W;超参数 α \alpha α和 β \beta β;话题数量 K K K。
- 输出:话题序列的集合 Z \textbf{Z} Z;文本的话题分布 θ \theta θ;话题的单词分布 φ \varphi φ。
(三) LDA模型的学习
LDA模型的学习,有两种基本思路:
- 通过求解不完全数据的对数似然函数 l o g P ( W ∣ θ , φ ) log \ P(\textbf{W}|\theta,\varphi) log P(W∣θ,φ)的极大似然估计,得到参数 θ \theta θ和 φ \varphi φ的估计,进而得到话题序列的集合 Z \textbf{Z} Z的估计。
- 通过求解后验概率分布 p ( Z ∣ W , α , β ) p(\textbf{Z}|\textbf{W},\alpha,\beta) p(Z∣W,α,β)的极大后验概率估计,得到话题序列的集合 Z \textbf{Z} Z的估计,进而可以得到参数 θ \theta θ和 φ \varphi φ的估计。
【延伸阅读】极大似然估计与最大后验概率估计 - 张小磊的文章 - 知乎
LDA模型的不完全数据的似然函数是:
p ( W ∣ θ , φ ) = ∏ m = 1 M { ∏ n = 1 N m [ ∑ k = 1 K p ( z m n = k ∣ θ m ) p ( w m n ∣ z m n = k , φ ) ] } p(\textbf{W}|\theta,\varphi) = \prod_{m=1}^M \bigg\{ \prod_{n=1}^{N_m} \Big[ \sum_{k=1}^K p(z_{mn} = k|\theta_m) \ p(w_{mn}|z_{mn} = k,\varphi) \Big] \bigg\} p(W∣θ,φ)=m=1∏M{
n=1∏Nm[k=1∑Kp(zmn=k∣θm) p(wmn∣zmn=k,φ)]}
LDA模型的后验概率分布是:
p ( Z ∣ W , α , β ) = p ( W , Z ∣ α , β ) p ( W ∣ α , β ) = p ( W ∣ Z , β ) p ( Z ∣ α ) p ( W ∣ α , β ) p(\textbf{Z}|\textbf{W},\alpha,\beta) = \frac{p(\textbf{W},\textbf{Z}|\alpha,\beta)}{p(\textbf{W}|\alpha,\beta)} = \frac{p(\textbf{W}|\textbf{Z},\beta) \ p(\textbf{Z}|\alpha)}{p(\textbf{W}|\alpha,\beta)} p(Z∣W,α,β)=p(W∣α,β)p(W,Z∣α,β)=p(W∣α,β)p(W∣Z,β) p(Z∣α)
其中
p ( W ∣ Z , β ) = ∫ p ( W ∣ Z , φ ) p ( φ ∣ β ) d φ p ( Z ∣ α ) = ∫ p ( Z ∣ θ ) p ( θ ∣ α ) d θ p ( W ∣ α , β ) = ∫ [ ∏ k = 1 K p ( φ k ∣ β ) ] [ ∏ m = 1 M ∫ p ( θ m ∣ α ) ∏ n = 1 N m [ ∑ z m n ∈ Z p ( z m n ∣ θ m ) p ( w m n ∣ z m n , φ ) ] d θ m ] d φ \begin{aligned} p(\textbf{W}|\textbf{Z},\beta) & = \int p(\textbf{W}|\textbf{Z},\varphi) \ p(\varphi|\beta) \ d \varphi \\ p(\textbf{Z}|\alpha) & = \int p(\textbf{Z}|\theta) \ p(\theta|\alpha) \ d \theta \\ p(\textbf{W}|\alpha,\beta) & = \int \Bigg[ \prod_{k=1}^K p(\varphi_k|\beta) \Bigg] \Bigg[ \prod_{m=1}^M \int p(\theta_m|\alpha) \prod_{n=1}^{N_m} \bigg[ \sum_{z_{mn} \in Z} p(z_{mn}|\theta_m) p(w_{mn}|z_{mn},\varphi) \bigg] \ d \theta_m \Bigg] \ d \varphi \\ \end{aligned} p(W∣Z,β)p(Z∣α)p(W∣α,β)=∫p(W∣Z,φ) p(φ∣β) dφ=∫p(Z∣θ) p(θ∣α) dθ=∫[k=1∏Kp(φk∣β)][m=1∏M∫p(θm∣α)n=1∏Nm[zmn∈Z∑p(zmn∣θm)p(wmn∣zmn,φ)] dθm] dφ
显然,无论是哪一种思路,直接估计都是很困难的。
吉布斯抽样的思路
基于第二种思路,我们使用吉布斯抽样,获得后验概率分布后验概率分布 P ( Z ∣ W , α , β ) P(\textbf{Z}|\textbf{W},\alpha,\beta) P(Z∣W,α,β)的样本集合,也就得到了话题序列的集合 Z \textbf{Z} Z的估计,进而可以得到参数 θ \theta θ和 φ \varphi φ的估计。
变分EM推理的思路
基于第一种思路,我们引入变分分布 q ∗ ( Z , θ ∣ γ , η ) ≈ p ( Z , θ ∣ W , α , β ) q^*(\textbf{Z},\theta|\gamma,\eta) \approx p(\textbf{Z},\theta|\textbf{W},\alpha,\beta) q∗(Z,θ∣γ,η)≈p(Z,θ∣W,α,β),通过KL散度大于等于零的性质,得到 l o g P ( W ∣ θ , φ ) log \ P(\textbf{W}|\theta,\varphi) log P(W∣θ,φ)的证据下界。然后,使用变分EM算法对证据下界进行最大化;得到证据下界取得最大值时,参数 α \alpha α和 β \beta β的后验参数,以及已知参数 γ \gamma γ和 η \eta η的变分分布。通过 β \beta β的后验参数可以得到模型参数 φ \varphi φ的估计,通过参数 α \alpha α和 β \beta β以及变分分布,可以得到模型参数 θ \theta θ的估计和话题序列的集合 Z \textbf{Z} Z的估计。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/61450.html