
简介
图像分割(Image Segmentation)是一种计算机视觉领域的技术,旨在将图像分成若干个特定的、具有语义意义性质的区域。图像分割可以用于许多领域,包括目标检测、图像编辑、医学图像分析等。它是由图像处理到图像分析的关键步骤。
发展史
- 传统方法:在早期计算机时代我们对图像分割采用的是传统方法,它基于灰度值的不连续和相似的性质对图像进行超像素分割。简单来说就是将不同的物体区域分开。
基于深度学习的方法:利用卷积神经网络,把每个像素都标注上与其对应的类别。
图像分割的三个任务等级有:语义分割(Semantic Aegmentation)、实例分割(Instance Segmentation)、全景分割(Panoptic Segmentation)。【当前讨论的图像分割一般泛指基于深度学习的分割方法,也称之为语义分割】
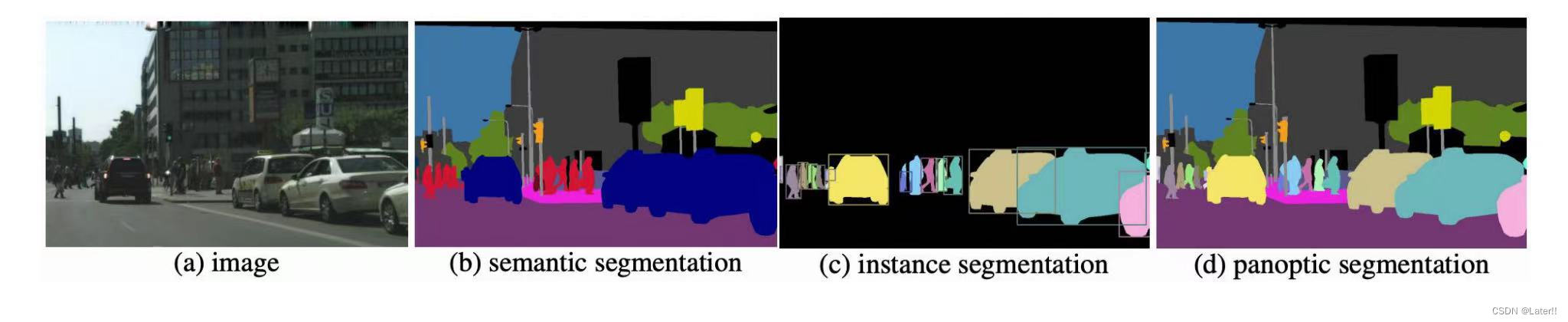
- (1)语义分割:语义分割的目的是把图像中的每个像素分为特定的语义类别,属于特定类别的像素仅被分类到该类别,而不考虑其他信息,例如:人、车、树、狗等这就是不同的类别。它与普通的图像分割任务不同,语义分割要求对图像中的每个像素进行细粒分类,以便我们能够准确的理解图像中的内容。语义分割在自动驾驶、医学图像分析、图像理解等领域具有重要的应用价值。
语义分割的方法:基于全卷积网络(FCN)、深度解码网络(DeepLab)、U-Net、图像分割神经网络(SegNet)、Mask R-CNN等。
(2)实例分割:实例分割根据“实例”而不是类别将像素分类,实例分割的目的是将图像中的目标检测出来,它不仅要对图像中的每个像素进行语义类别的分类,还要将同一类别的不同实例进行区分,并且对目标的每个像素分配类别标签以区分它们。实例分割能够对前景语义类别相同的不同实例进行区分。这种技术在物体检测、图像分析和医学图像处理等领域具有重要的应用,实现更精细的图像分析和理解。实例分割模型一般由三部分组成:图像输入、实例分割处理、分割结果输出。
实例分割的方法:Mask R-CNN、ShapeMask、全卷积实例分割(Fully Convolutional Instance Segmentation,FCIS)、PANet、YOLACT等。
(3)全景分割:全景分割是最新开发的分割任务,可以表示为语义分割和实例分割的组合,其中图像中对象的每个实例都被分离,并预测对象的身份。和实例分割的区别在于,将整个图像都进行分割。与实例分割不同,全景分割不需要将像素分配给特定的实例,而是将其分为不同的语义类别。全景分割在自动驾驶、机器人导航、视觉增强现实、医学影像分析、地球观测和遥感、图像编辑和艺术创造等领域都有应用,随着深度学习和计算机视觉的发展,全景分割在更多领域中的应用也会不断增加。
全景分割的方法:Fully Convolutional Network (FCN)、U-Net、DeepLab、Mask R-CNN、PANet等。
图像分割必要准备
图像分割常用数据集
PASCAL VOC数据集:该数据集包含了来自20个不同类别的物体的图片和对应的标注信息,如人、车、猫、狗等,同时还包含了大量的难以识别的背景图片。每张图像都包含一个 .xml 格式的标注文件,记录了图像中的目标类别、位置、大小等信息。同时,每个目标都有一个唯一的ID标识,可以方便地在多个图像中进行跟踪。Train + validation = 2913张。

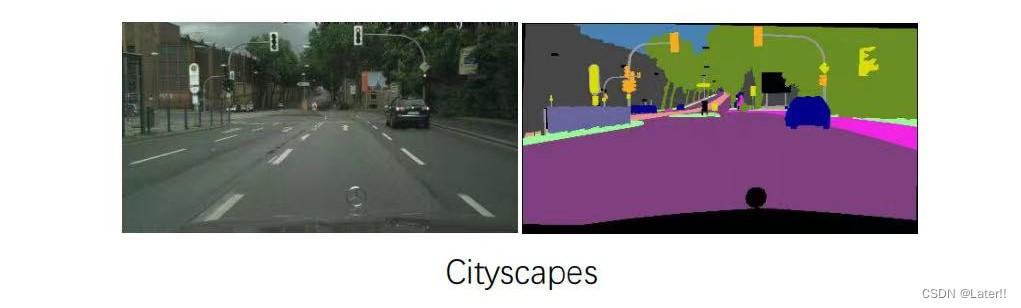
Cityscapes数据集:一个用于城市场景理解的大规模数据,该数据集主要用于场景分析、车辆自主驾驶等方向的研究。每个图像都标注了精细的像素级别的分割标签,包含了19个不同的类别,如道路、人行道、建筑物、车辆、行人等。它还提供了一个真实的场景理解挑战,因为城市场景通常包含复杂的背景、遮挡、多样化的物体和不同的光照条件。Train + validation = 3475张。
CamVid数据集:一个广泛用于图像分割领域的数据集,包含了701个图像序列,每个图像序列都是由视频中连续帧截取得到的。这些序列涵盖了多种交通场景,如城市道路、人行道、建筑物、车辆、行人等。每个图像都标注了精细的像素级别的分割标签,包含了32个不同的类别,如道路、人行道、建筑物、车辆、行人等。Train + validation = 701张。

COCO数据集:包含了各种真实世界场景中的图像,涵盖了多个类别的常见物体和复杂场景。目前,COCO数据集涵盖了80个不同的类别,如人、动物、车辆、家具等。除了图像本身,COCO数据集还提供了对图像中物体的详细标注信息。这些标注信息包括物体的边界框(bounding box)、物体实例分割的掩码(mask)以及对图像中物体的关键点的标注。这些标注信息使得COCO数据集成为目标检测、分割和姿态估计等任务的理想数据集。Train + validation = 330k张。

图像分割评价指标
MPA(Mean Pixel Accuracy):均像素精度
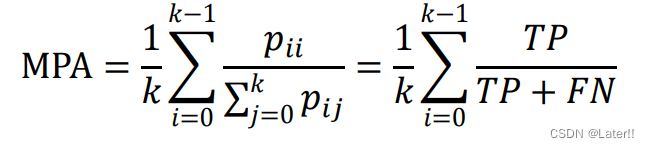
MIOU(Mean Intersection Over Nion):均交并比
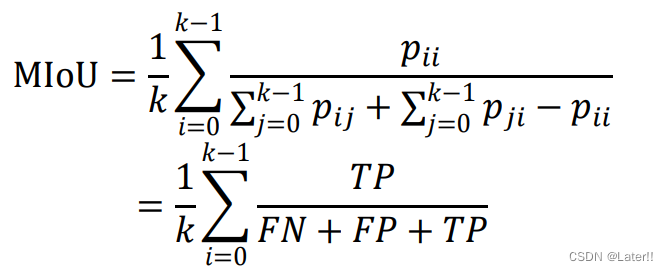
i表示真实值,j表示预测值,k表示类别数,pij表示将i预测为j;对于i类,pij为TP, pij为FN,pji为FP。
图像分割图标的工具
Labelme:Labelme是一个基于Web的开源图像标注工具,它可以让用户轻松地标注2D和3D图像,并且支持各种类型的标注,如矩形、多边形、点、线条等,提供了一个直观界面,为图像中的对象绘制准确的分割边界。Labelme也提供了一些高级的功能,如语义分割、实例分割、关键点检测等。
VGG Image Annotator (VIA):VIA是一个开源的图像注释工具,可以用于不同类型的图像标注任务,包括图像分割。它具有灵活的标注界面和多种标注工具,可以绘制精确的分割边界,同时支持导入和导出多种标注格式。
LabelImg:LabelImg是一个开源的图像标注工具,用于创建图像分类和目标检测数据集。它支持常见的标注类型,如矩形框、多边形、点等,并提供了一些高级功能,如标注分组、标注多个类别、标注困难样本等。
RectLabel:RectLabel是一款图像标注工具,适用于Mac和iOS平台。它支持目标检测、语义分割和图像分类等任务的标注,并提供了各种标注工具,如矩形、椭圆形、多边形、标签、线条等。此外,RectLabel还提供了自动标注、批量标注、图像预览等高级功能,使标注更加高效和便捷。
COCO Annotator:COCO Annotator是一个基于Web的开源图像标注工具,专门用于处理COCO数据集的标注任务。它支持图像分割和边界框标注,并提供了丰富的交互功能和导入/导出选项。
图像分割常用的损失函数
交叉熵损失函数(Cross-Entropy Loss):交叉熵损失函数是常用的分类任务损失函数,但在图像分割中也可应用,它是最常用的损失函数。它通过计算预测分割与真实分割之间的差异来衡量损失。交叉熵损失函数在像素级别进行计算,对每个像素的预测进行评估。代码实现如下:

import torch import torch.nn.functional as F def cross_entropy_loss(predicted, target): # 将预测值和目标值转为一维张量 predicted_flat = predicted.view(-1) target_flat = target.view(-1) # 使用PyTorch的交叉熵损失函数计算损失 loss = F.cross_entropy(predicted_flat, target_flat) return loss讯享网
Dice损失函数(Dice Loss):Dice损失函数衡量预测分割和真实分割图之间的重叠度。它通过计算预测分割和真实分割的重叠系数(Dice系数)来衡量损失。Dice损失函数对于不平衡数据集和边缘细节的分割任务效果较好。算法实现如下:
讯享网import torch def dice_loss(predicted, target): smooth = 1e-5 # 用于避免除以零的平滑项 # 将预测值和目标值转为一维张量 predicted_flat = predicted.view(-1) target_flat = target.view(-1) # 计算预测值和目标值的交集和并集 intersection = torch.sum(predicted_flat * target_flat) union = torch.sum(predicted_flat) + torch.sum(target_flat) # 计算Dice系数 dice_coeff = (2 * intersection + smooth) / (union + smooth) # 计算Dice损失 loss = 1 - dice_coeff return loss
Jaccard损失函数(Jaccard Loss):Jaccard损失函数也被称为IoU(Intersection over Union)损失函数,用于衡量预测分割和真实分割之间的相似度。它通过计算预测分割和真实分割的IoU来衡量损失。Jaccard损失函数对于边缘细节和不平衡数据集的分割任务效果较好。
Focal损失函数(Focal Loss):Focal损失函数是一种用于解决类别不平衡问题的损失函数,在图像分割任务中也可应用。它通过为困难样本分配更高的权重来减轻类别不平衡的影响,提高模型对边界细节的分割能力。
像素交叉熵损失函数(Pixel-wise Cross-Entropy Loss):像素交叉熵损失函数是像素级别的损失函数,用于图像分割任务。它将像素分类损失聚合到整个图像上,衡量预测分割图和真实分割图之间的差异。
基于深度学习的图像分割详解
新旧区别
原始图像分割想法:(1)滑动窗口(sliding window)
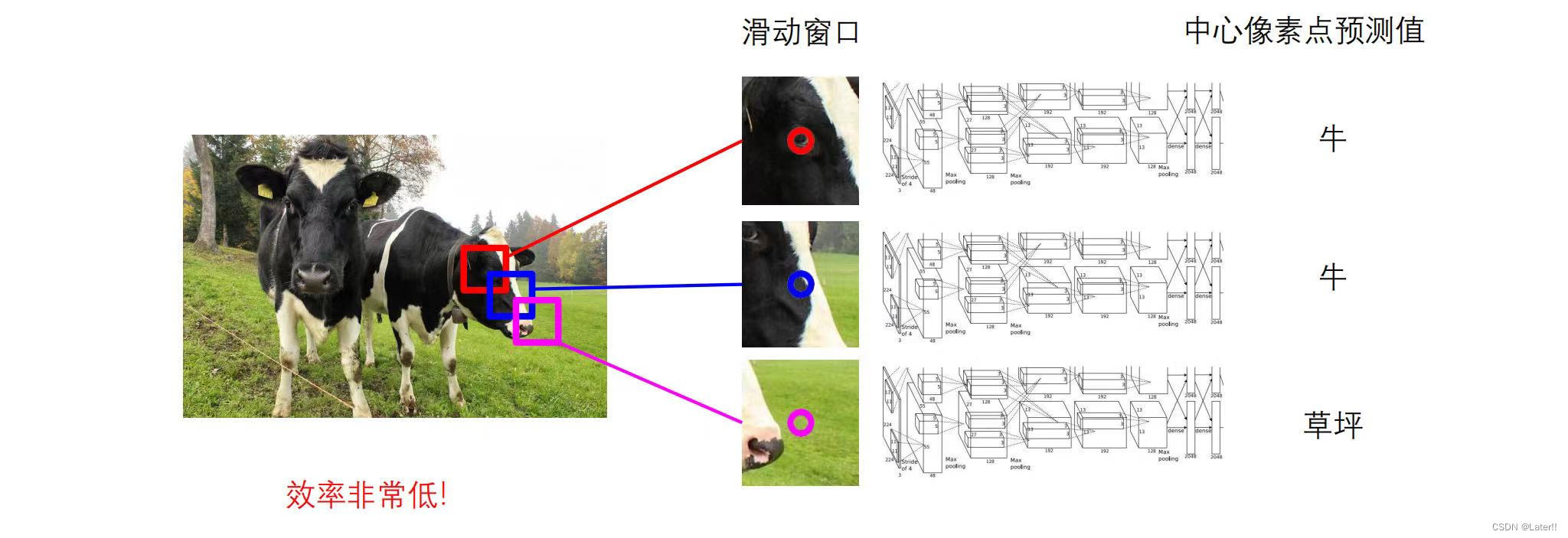
(2)直筒状卷积神经网络(CNN)
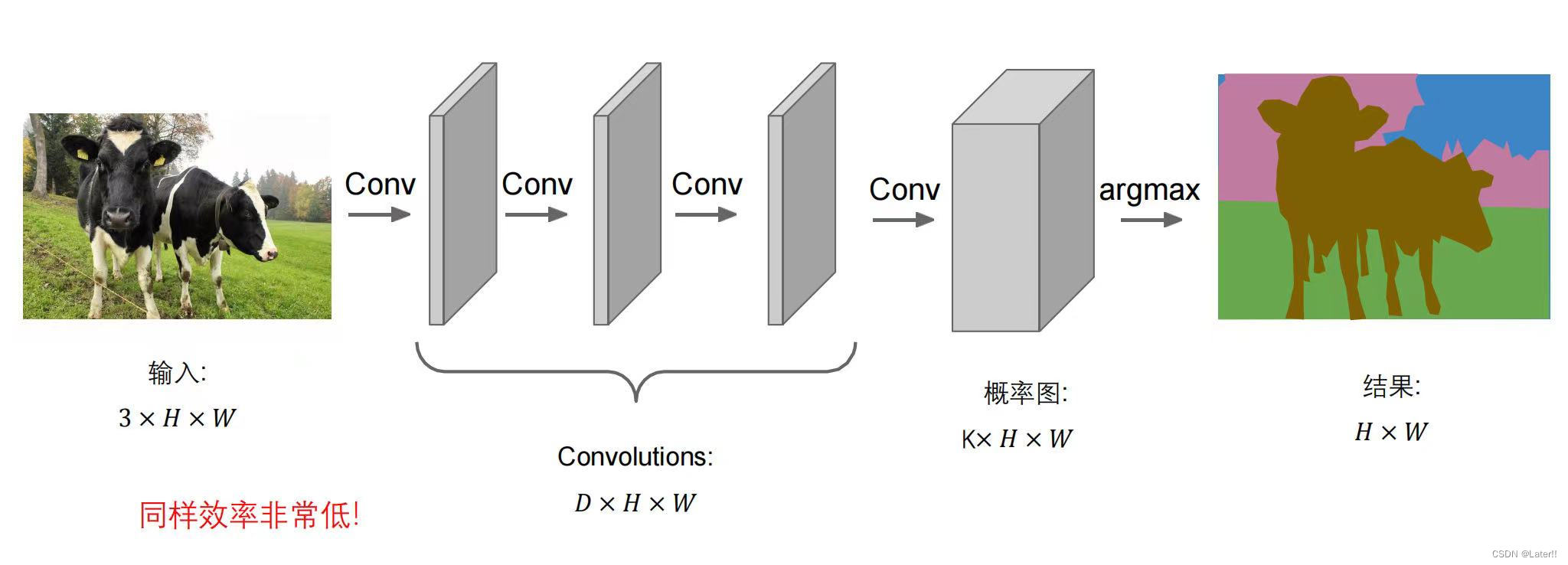
基于深度学习的图像分割:主要思想是基于encoder + decoder(大多使用UNet网络实现)
Encoder:复用图像分类网络,通过下采样获取低分辨率高层语义信息。
Decoder:逐层上采样,逐步恢复高分辨率细节预测。
上采样和下采样概述:上采样(upsampling)和下采样(downsampling)是数字图像处理中常用的两种操作。
上采样:将输入图像中的像素点增加,从而提高图像的分辨率。常见的上采样方法包括插值法(包括线性插值、双线性插值、最近邻插值、双三次插值等)、反池化、反卷积等。插值法将输入图像中的像素点之间插入新的像素点,从而使图像的分辨率增加。反卷积则是一种将低分辨率特征图转换为高分辨率图像的方法,它通过使用反卷积滤波器将特征图转换为与输入图像大小相同的输出图像。上采样可以使得图像变得更加清晰和细致,同时也可以帮助模型恢复更多的细节信息。关于插值方法更多细节这个博主讲的很详细 http://t.csdnimg.cn/94bx4
下采样:下采样是将输入图像中的像素点减少,从而降低图像的分辨率。常见的下采样方法包括平均池化和最大池化等。平均池化将输入图像中的像素点分成若干个区域,然后取每个区域内像素点的平均值作为输出像素点的值。最大池化则是取每个区域内像素点的最大值作为输出像素点的值。下采样可以使得图像变得更加简单和快速,同时也可以避免图像中的噪声和细节干扰。
基于深度学习的图像分割常用算法:
完整的实践过程一般分为:数据准备、网络设计、设计损失函数、参数更新、训练模型、评估模型、预测模型。图像分割任务往往需要大量的标注数据和计算资源,因此在实际应用中需要谨慎设计训练数据和网络结构,以提高训练效率和预测准确率。
FCN(Fully Convolutional Networks)全卷积层是基于CNN的图像分割的奠基之作,它服用图像分类网络框架,将分类训练得到的模型作为初始化权重。其次,分类网络的全连接层转为卷积层,可以结合上采样+融合中间特征,输出下采样8倍、16倍效果。

以下是一个简单的FCN实现:
class FCN(nn.Module): def __init__(self, num_classes): super(FCN, self).__init__() # 加载预训练的VGG模型 vgg = models.vgg16(pretrained=True) # 获取VGG的前面几个卷积层 features = list(vgg.features.children()) # 替换最后一个最大池化层为步长为1的卷积层 features[-1] = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1) # 添加一个额外的卷积层 features.append(nn.ReLU(inplace=True)) features.append(nn.Conv2d(512, num_classes, kernel_size=1)) # 将特征提取层和分类层组合成FCN模型 self.features = nn.Sequential(*features) def forward(self, x): x = self.features(x) x = torch.nn.functional.interpolate(x, scale_factor=32, mode='bilinear', align_corners=False) return x SegNet:它的结构与FCN类似,但更为对称;其上采样采用反池化操作。
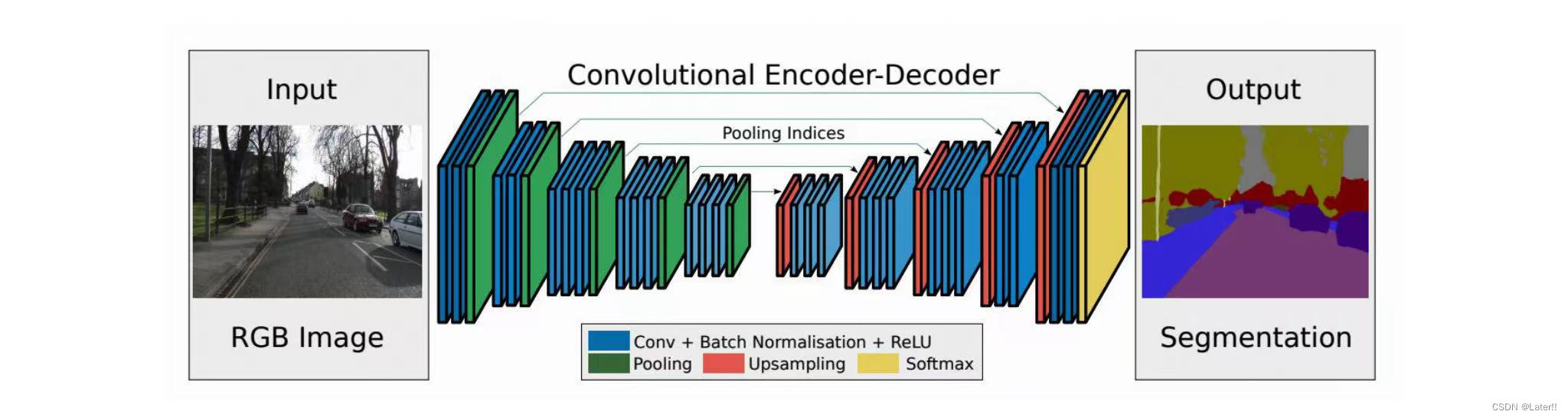
讯享网class SegNet(nn.Module): def __init__(self, num_classes): super(SegNet, self).__init__() self.MaxEn = nn.MaxPool2d(2, stride=2, return_indices=True) self.ConvEn11 = nn.Conv2d(3, 64, kernel_size=3, padding=1) self.BNEn11 = nn.BatchNorm2d(64) self.ConvEn12 = nn.Conv2d(64, 64, kernel_size=3, padding=1) self.BNEn12 = nn.BatchNorm2d(64) self.ConvEn21 = nn.Conv2d(64, 128, kernel_size=3, padding=1) self.BNEn21 = nn.BatchNorm2d(128) self.ConvEn22 = nn.Conv2d(128, 128, kernel_size=3, padding=1) self.BNEn22 = nn.BatchNorm2d(128) self.ConvEn31 = nn.Conv2d(128, 256, kernel_size=3, padding=1) self.BNEn31 = nn.BatchNorm2d(256) self.ConvEn32 = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.BNEn32 = nn.BatchNorm2d(256) self.ConvEn33 = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.BNEn33 = nn.BatchNorm2d(256) self.ConvEn41 = nn.Conv2d(256, 512, kernel_size=3, padding=1) self.BNEn41 = nn.BatchNorm2d(512) self.ConvEn42 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNEn42 = nn.BatchNorm2d(512) self.ConvEn43 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNEn43 = nn.BatchNorm2d(512) self.ConvEn51 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNEn51 = nn.BatchNorm2d(512) self.ConvEn52 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNEn52 = nn.BatchNorm2d(512) self.ConvEn53 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNEn53 = nn.BatchNorm2d(512) self.MaxDe = nn.MaxUnpool2d(2, stride=2) self.ConvDe53 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNDe53 = nn.BatchNorm2d(512) self.ConvDe52 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNDe52 = nn.BatchNorm2d(512) self.ConvDe51 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNDe51 = nn.BatchNorm2d(512) self.ConvDe43 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNDe43 = nn.BatchNorm2d(512) self.ConvDe42 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.BNDe42 = nn.BatchNorm2d(512) self.ConvDe41 = nn.Conv2d(512, 256, kernel_size=3, padding=1) self.BNDe41 = nn.BatchNorm2d(256) self.ConvDe33 = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.BNDe33 = nn.BatchNorm2d(256) self.ConvDe32 = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.BNDe32 = nn.BatchNorm2d(256) self.ConvDe31 = nn.Conv2d(256, 128, kernel_size=3, padding=1) self.BNDe31 = nn.BatchNorm2d(128) self.ConvDe22 = nn.Conv2d(128, 128, kernel_size=3, padding=1) self.BNDe22 = nn.BatchNorm2d(128) self.ConvDe21 = nn.Conv2d(128, 64, kernel_size=3, padding=1) self.BNDe21 = nn.BatchNorm2d(64) self.ConvDe12 = nn.Conv2d(64, 64, kernel_size=3, padding=1) self.BNDe12 = nn.BatchNorm2d(64) self.ConvDe11 = nn.Conv2d(64, num_classes, kernel_size=3, padding=1) self.BNDe11 = nn.BatchNorm2d(num_classes)
UNet:结构与SegNet类似,在decoder中引入encoder的输出,提升网络精度,能够处理小目标以及具有良好的泛化性能。它在encoder和decoder之间加入跳跃连接,使得decoder可以访问不同层次的特征信息,有效提高了模型对于不同尺度和不同语义的特征的利用效率。此外,U-Net采用了结合二元交叉熵和Dice系数的损失函数,使得模型在预测分割图时既能考虑像素级别的准确度,也能考虑不同类别之间的IoU,从而进一步提高了分割精度。
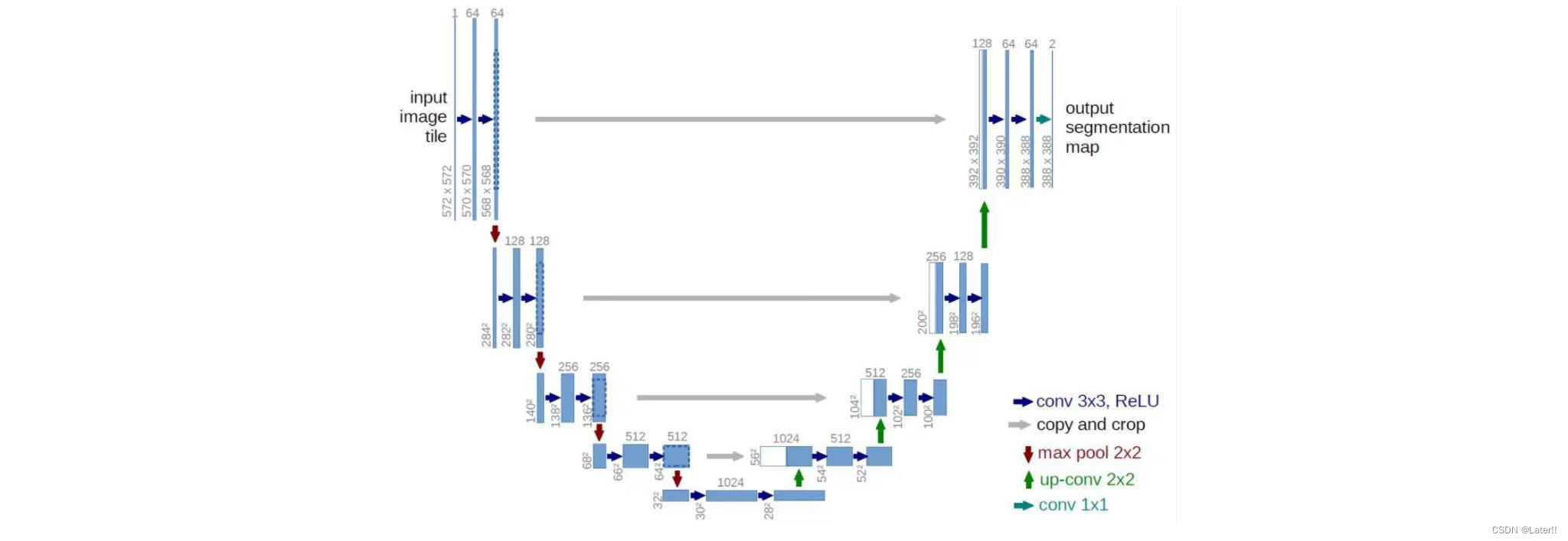
""" paddlepaddle-gpu==2.2.1 author:CP backbone:U-net """ import paddle from paddle import nn class Encoder(nn.Layer):#下采样:两层卷积,两层归一化,最后池化。 def __init__(self, num_channels, num_filters): super(Encoder,self).__init__()#继承父类的初始化 self.conv1 = nn.Conv2D(in_channels=num_channels, out_channels=num_filters, kernel_size=3,#3x3卷积核,步长为1,填充为1,不改变图片尺寸[H W] stride=1, padding=1) self.bn1 = nn.BatchNorm(num_filters,act="relu")#归一化,并使用了激活函数 self.conv2 = nn.Conv2D(in_channels=num_filters, out_channels=num_filters, kernel_size=3, stride=1, padding=1) self.bn2 = nn.BatchNorm(num_filters,act="relu") self.pool = nn.MaxPool2D(kernel_size=2,stride=2,padding="SAME")#池化层,图片尺寸减半[H/2 W/2] def forward(self,inputs): x = self.conv1(inputs) x = self.bn1(x) x = self.conv2(x) x = self.bn2(x) x_conv = x #两个输出,灰色 -> x_pool = self.pool(x)#两个输出,红色 | return x_conv, x_pool class Decoder(nn.Layer):#上采样:一层反卷积,两层卷积层,两层归一化 def __init__(self, num_channels, num_filters): super(Decoder,self).__init__() self.up = nn.Conv2DTranspose(in_channels=num_channels, out_channels=num_filters, kernel_size=2, stride=2, padding=0)#图片尺寸变大一倍[2*H 2*W] self.conv1 = nn.Conv2D(in_channels=num_filters*2, out_channels=num_filters, kernel_size=3, stride=1, padding=1) self.bn1 = nn.BatchNorm(num_filters,act="relu") self.conv2 = nn.Conv2D(in_channels=num_filters, out_channels=num_filters, kernel_size=3, stride=1, padding=1) self.bn2 = nn.BatchNorm(num_filters,act="relu") def forward(self,input_conv,input_pool): x = self.up(input_pool) h_diff = (input_conv.shape[2]-x.shape[2]) w_diff = (input_conv.shape[3]-x.shape[3]) pad = nn.Pad2D(padding=[h_diff//2, h_diff-h_diff//2, w_diff//2, w_diff-w_diff//2]) x = pad(x) #以下采样保存的feature map为基准,填充上采样的feature map尺寸 x = paddle.concat(x=[input_conv,x],axis=1)#考虑上下文信息,in_channels扩大两倍 x = self.conv1(x) x = self.bn1(x) x = self.conv2(x) x = self.bn2(x) return x class UNet(nn.Layer): def __init__(self,num_classes=59): super(UNet,self).__init__() self.down1 = Encoder(num_channels= 3, num_filters=64) #下采样 self.down2 = Encoder(num_channels= 64, num_filters=128) self.down3 = Encoder(num_channels=128, num_filters=256) self.down4 = Encoder(num_channels=256, num_filters=512) self.mid_conv1 = nn.Conv2D(512,1024,1) #中间层 self.mid_bn1 = nn.BatchNorm(1024,act="relu") self.mid_conv2 = nn.Conv2D(1024,1024,1) self.mid_bn2 = nn.BatchNorm(1024,act="relu") self.up4 = Decoder(1024,512) #上采样 self.up3 = Decoder(512,256) self.up2 = Decoder(256,128) self.up1 = Decoder(128,64) self.last_conv = nn.Conv2D(64,num_classes,1) #1x1卷积,softmax做分类 def forward(self,inputs): x1, x = self.down1(inputs) x2, x = self.down2(x) x3, x = self.down3(x) x4, x = self.down4(x) x = self.mid_conv1(x) x = self.mid_bn1(x) x = self.mid_conv2(x) x = self.mid_bn2(x) x = self.up4(x4, x) x = self.up3(x3, x) x = self.up2(x2, x) x = self.up1(x1, x) x = self.last_conv(x) return x model = UNet(num_classes=59) paddle.summary(model,(1,3,250,250)) http://t.csdnimg.cn/nZT3o
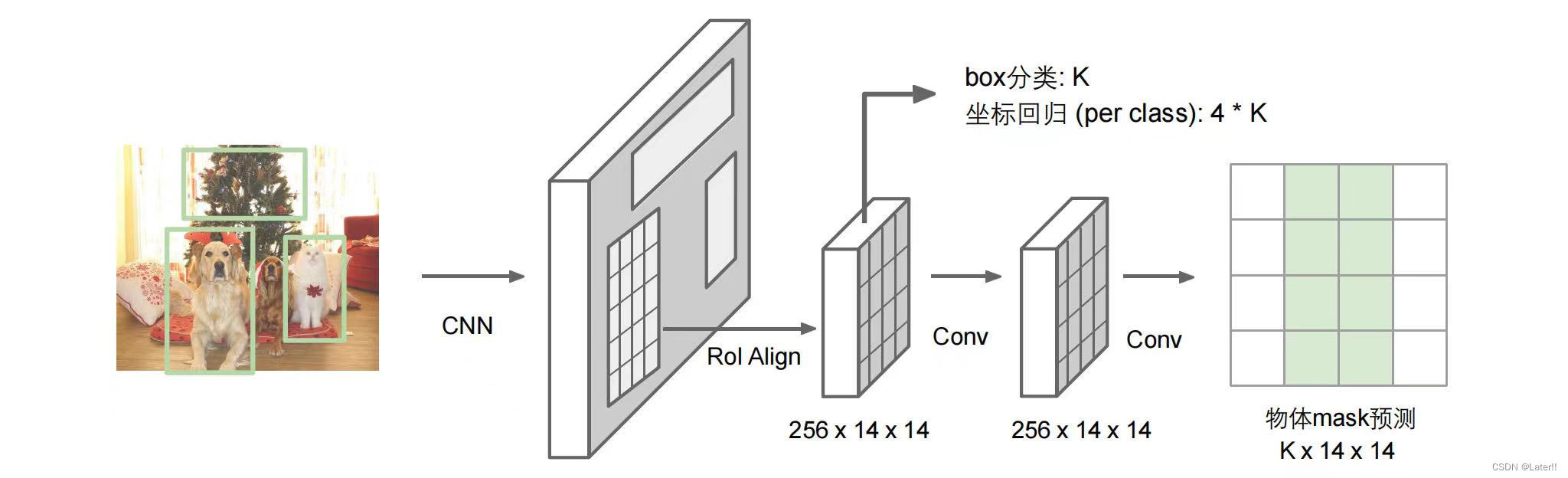
MaskRCNN:这个网络的主体结构与FasterRCNN类似,它加入了分割head,预测每个RoI内部物体的mask(0/1分类)。Fast R-CNN对每个候选对象有2个输出: 一个类标签和一个边界框偏移,而Mask R-CNN设计了第三个分支输出对象掩码。额外的掩码输出不同于类和框输出,需要提取更精细的对象空间布局。下面是一个使用PyTorch实现Mask R-CNN的示例代码。
讯享网import torch import torchvision from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor # 加载预训练的COCO数据集上训练的Mask R-CNN模型 model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True) # 替换模型的分类器,因为COCO数据集有91个类别(包括背景) num_classes = 91 # 91个类别 + 1个背景 in_features = model.roi_heads.box_predictor.cls_score.in_features model.roi_heads.box_predictor = MaskRCNNPredictor(in_features, num_classes) # 加载测试图片 image = Image.open('test_image.jpg') # 对图片进行预处理 transform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor() ]) image = transform(image) # 将图片放入模型中进行推理 model.eval() with torch.no_grad(): prediction = model([image]) # 获取预测结果 masks = prediction[0]['masks'].detach().cpu().numpy() scores = prediction[0]['scores'].detach().cpu().numpy() # 可视化预测结果 import matplotlib.pyplot as plt plt.imshow(image.permute(1, 2, 0)) # 设置阈值,只显示置信度高于阈值的实例 threshold = 0.5 for mask, score in zip(masks, scores): if score > threshold: plt.contour(mask.squeeze(), colors='r', linewidths=2) plt.axis('off') plt.show()
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/59609.html