
强化学习: A3C算法原理
深度强化学习框架使用异步梯度下降来优化深度神经网络控制器。提出了四种标准强化学习算法的异步变体,并证明并行actor-learners在训练中具有稳定作用,使得四种方法都能成功地训练神经网络控制器。 讯享网

讯享网
首先明确什么是A3C?全称Asynchronous advantage actor-critic(异步优势动作评估 ) 我们先来看经典的A3C架构图:
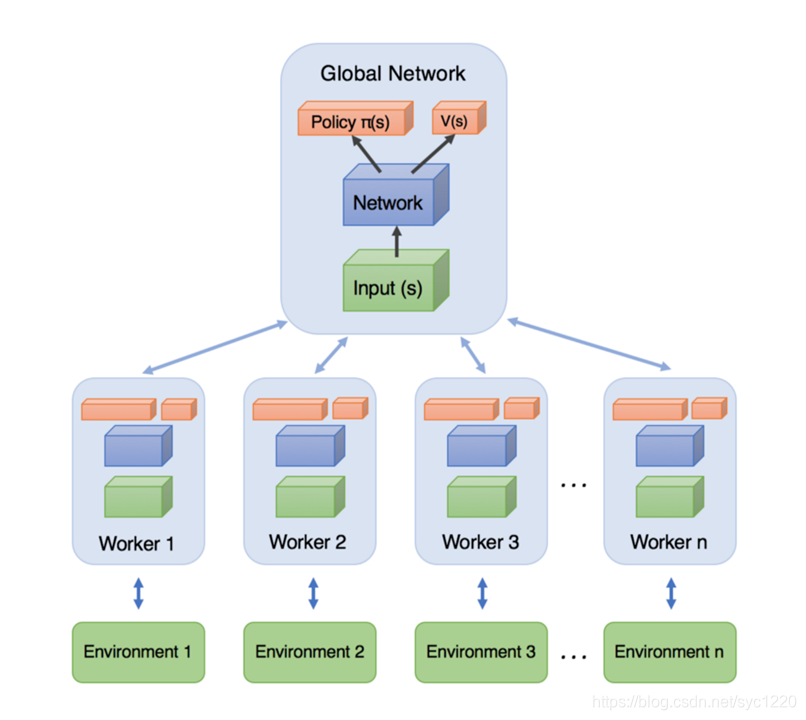
简单理解: 训练的时候,同时为多个线程上分配task,学习一遍后,每个线程将自己学习到的参数更新(这里就是异步的思想)到全局Global Network上,下一次学习的时候拉取全局参数,继续学习。
1. RL背景知识
略
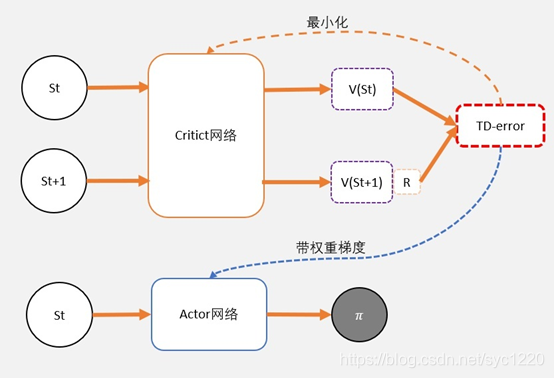
2.Actor-Critic框架
Actor-Critic,其实是用了两个网络:
两个网络有一个共同点,输入状态S: 一个输出策略,负责选择动作,我们把这个网络成为Actor; 一个负责计算每个动作的分数,我们把这个网络成为Critic。
大家可以形象地想象为,Actor是青你里的小姐姐,Critic是台下的青春制作人。所以AC也称“行动器-评判器”方法。
AC是PG(策略梯度) 的算法框架,通常采用TD-error方法作为Critic,即来评估Actor的好坏!

PG更新公式:
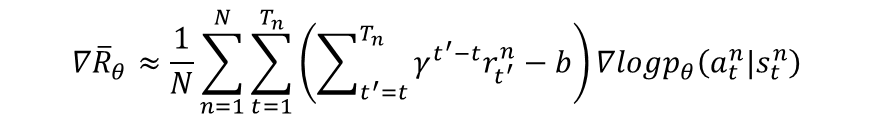
AC更新公式:
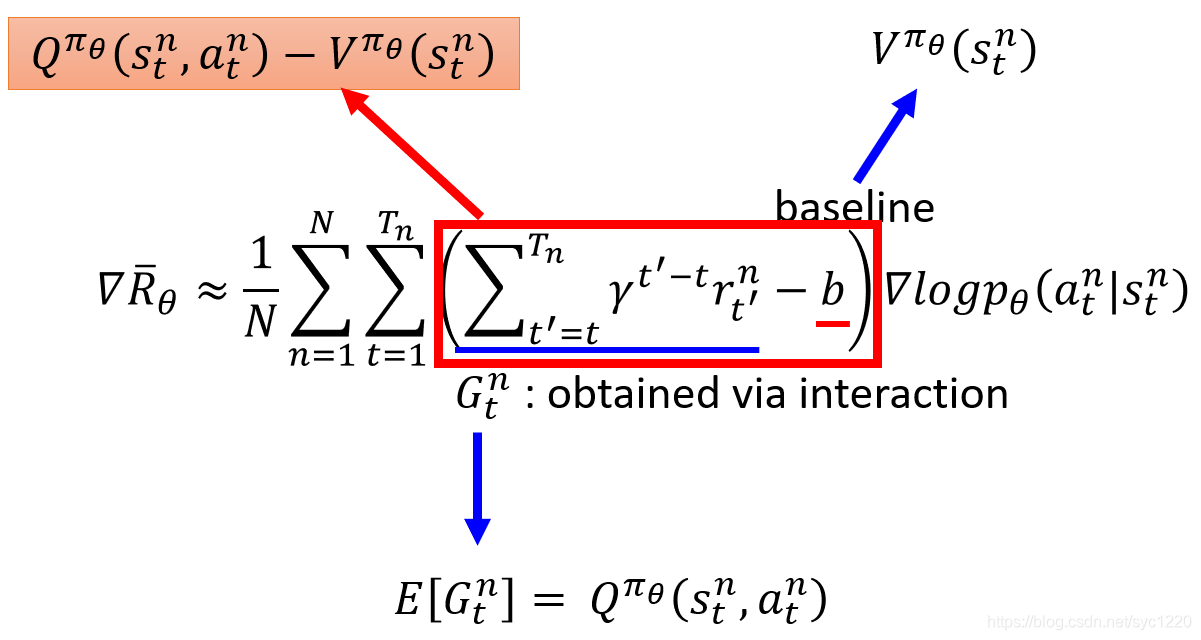
我们可以得到更新的权重:Q(s,a)-V(s)
为了避免需要预估V值和Q值,我们希望把Q和V统一。
由于Q(s,a) = gamma * V(s’) + r 。所以我们得到TD-error公式:
TD-error = gamma * V(s’) + r - V(s)
可得:
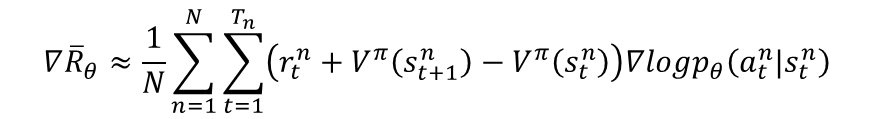 TD-error就是Critic网络需要的loss,也就是说,Critic函数需要最小化TD-error
TD-error就是Critic网络需要的loss,也就是说,Critic函数需要最小化TD-error
3. A3C算法
我们称之为异步优势actor-critic (A3C),保持策略π(a_t |s_t;θ)和估计的价值函数V(s_t; θ_v)。就像我们的n-step Q-learning变量一样,我们的actor-critic变量也在前视图中运行,并使用相同的n步返回组合来更新策略和值函数。策略和值函数在每次t_max操作之后或达到终端状态时更新。算法执行的更新可视为:
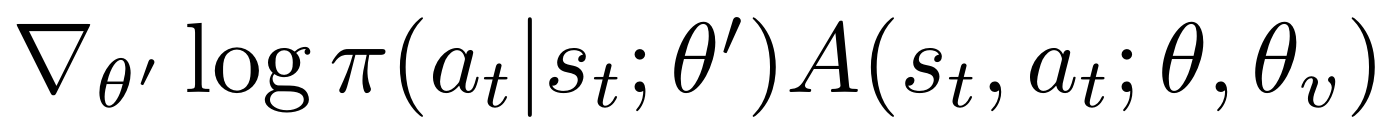
其中A(s,a)为优势函数,值为:

其中k可以随着状态的变化而变化并且最大值是t_max
完整的目标函数的梯度包括熵正则化项的策略参数:
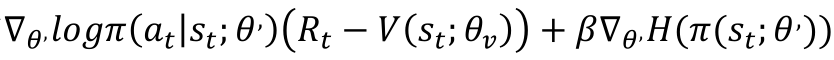
其中H是熵,超参数β控制的强度熵正则化项。增加政策π的熵目标函数改进令人沮丧的过早收敛到不确定的策略。
具体的算法伪代码如下:

算法流程图:

关于A3C算法Tensorflow实现,详见我另一篇
讯享网""" Asynchronous Advantage Actor Critic (A3C) with continuous action space, Reinforcement Learning. The Pendulum example. View more on my tutorial page: https://morvanzhou.github.io/tutorials/ Using: tensorflow 1.8.0 gym 0.10.5 """ import multiprocessing # 多线程模块 import threading # 线程模块 import tensorflow as tf import numpy as np import gym import os import shutil # 拷贝文件用 import matplotlib.pyplot as plt GAME = 'Pendulum-v0' OUTPUT_GRAPH = True LOG_DIR = './log' N_WORKERS = multiprocessing.cpu_count() # 独立玩家个体数为cpu数 MAX_EP_STEP = 200 MAX_GLOBAL_EP = 2000 # 中央大脑最大回合数 GLOBAL_NET_SCOPE = 'Global_Net' # 中央大脑的名字 UPDATE_GLOBAL_ITER = 10 # 中央大脑每N次更新一次 GAMMA = 0.9 # 衰减度 ENTROPY_BETA = 0.01 # β项熵 LR_A = 0.0001 # learning rate for actor LR_C = 0.001 # learning rate for critic GLOBAL_RUNNING_R = [] # 存储总的reward GLOBAL_EP = 0 # 中央大脑步数 env = gym.make(GAME) # 定义游戏环境 N_S = env.observation_space.shape[0] # 观测值个数 N_A = env.action_space.shape[0] # 动作值个数 A_BOUND = [env.action_space.low, env.action_space.high] # 动作界限 # 这个 class 可以被调用生成一个 global net. # 也能被调用生成一个 worker 的 net, 因为他们的结构是一样的, # 所以这个 class 可以被重复利用. class ACNet(object): def __init__(self, scope, globalAC=None): if scope == GLOBAL_NET_SCOPE: # get global network with tf.variable_scope(scope): self.s = tf.placeholder(tf.float32, [None, N_S], 'S') # [None, N_S]数据形状,None代表batch,N_S是每个state的观测值个数 self.a_params, self.c_params = self._build_net(scope)[-2:] # 定义中央大脑actor和critic的参数 else: # local net, calculate losses with tf.variable_scope(scope): self.s = tf.placeholder(tf.float32, [None, N_S], 'S') self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A') self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget') mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope) # 均值μ,方差σ, td = tf.subtract(self.v_target, self.v, name='TD_error') # TD_error=v_target-v with tf.name_scope('c_loss'): self.c_loss = tf.reduce_mean(tf.square(td)) # TD加平方避免负数 with tf.name_scope('wrap_a_out'): mu, sigma = mu * A_BOUND[1], sigma + 1e-4 normal_dist = tf.distributions.Normal(mu, sigma) # tf.distributions.normal可以生成一个均值为μ,方差为σ的正态分布。 with tf.name_scope('a_loss'): log_prob = normal_dist.log_prob(self.a_his) # 正态分布中概率的log值 exp_v = log_prob * tf.stop_gradient(td) entropy = normal_dist.entropy() # 最大熵 self.exp_v = ENTROPY_BETA * entropy + exp_v # 完整的目标函数 self.a_loss = tf.reduce_mean(-self.exp_v) with tf.name_scope('choose_a'): # use local params to choose action self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=[0, 1]), A_BOUND[0], A_BOUND[1]) # tf.clip_by_value将正态分布输出值压缩在min~max之间得到action输出 with tf.name_scope('local_grad'): self.a_grads = tf.gradients(self.a_loss, self.a_params) # 实现a_loss对a_params每一个参数的求导,返回一个list self.c_grads = tf.gradients(self.c_loss, self.c_params) # 实现c_loss对c_params每一个参数的求导,返回一个list with tf.name_scope('sync'): # worker和global的同步过程 with tf.name_scope('pull'): # 获取global参数,复制到local—net self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)] self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)] with tf.name_scope('push'): # 将参数传送到gloabl中去 self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params)) self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params)) # 其中传送的是local—net的actor和critic的参数梯度grads,具体计算在上面定义 # apply_gradients是tf.train.Optimizer中自带的功能函数,将求得的梯度参数更新到global中 def _build_net(self, scope): w_init = tf.random_normal_initializer(0., .1) # 返回一个生成具有正态分布的张量的初始化器 with tf.variable_scope('actor'): l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la') mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu') sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma') # actor 输出动作的均值和方差 with tf.variable_scope('critic'): l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc') v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # critic 输出state value用于计算td a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor') c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic') return mu, sigma, v, a_params, c_params # return 均值, 方差, state_value def update_global(self, feed_dict): # push SESS.run([self.update_a_op, self.update_c_op], feed_dict) # 进行 push 操作 def pull_global(self): SESS.run([self.pull_a_params_op, self.pull_c_params_op]) # 进行 pull 操作 def choose_action(self, s): s = s[np.newaxis, :] return SESS.run(self.A, {
self.s: s}) # 根据 s 选动作 class Worker(object): def __init__(self, name, globalAC): self.env = gym.make(GAME).unwrapped # 创建自己的环境 self.name = name # 自己的名字 self.AC = ACNet(name, globalAC) # 自己的 local net, 并绑定上 globalAC def work(self): global GLOBAL_RUNNING_R, GLOBAL_EP # R是所有worker的总reward,ep是所有worker的总episode total_step = 1 # 本worker的总步数 buffer_s, buffer_a, buffer_r = [], [], [] # s, a, r 的缓存, 用于 n_steps 更新 while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP: # worker运行的条件 s = self.env.reset() # 重置环境 ep_r = 0 # 统计ep的总reward for ep_t in range(MAX_EP_STEP): # if self.name == 'W_0': # 只有worker0才将动画图像显示 # self.env.render() a = self.AC.choose_action(s) # 将当前状态state传入AC网络选择动作action s_, r, done, info = self.env.step(a) # 行动并获得s_和r等信息 done = True if ep_t == MAX_EP_STEP - 1 else False # ep_r += r # 记录本回合总体reward buffer_s.append(s) # 将当前s,a和r加入缓存 buffer_a.append(a) buffer_r.append((r+8)/8) # normalize # TD(n)的架构 if total_step % UPDATE_GLOBAL_ITER == 0 or done: # 每 UPDATE_GLOBAL_ITER 步 或者回合完了, 进行 sync 操作 # 获得用于计算 TD error 的 下一 state 的 value if done: v_s_ = 0 # terminal else: v_s_ = SESS.run(self.AC.v, {
self.AC.s: s_[np.newaxis, :]})[0, 0] # reduce dim from 2 to 0 buffer_v_target = [] # 下 state value 的缓存, 用于算 TD for r in buffer_r[::-1]: # 进行 n_steps forward view v_s_ = r + GAMMA * v_s_ buffer_v_target.append(v_s_) # 将每一步的v现实都加入缓存中 buffer_v_target.reverse() buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target) feed_dict = {
self.AC.s: buffer_s, # 本次走过的所有状态,用于计算v估计 self.AC.a_his: buffer_a, # 本次进行过的所有操作,用于计算a—loss self.AC.v_target: buffer_v_target, # 走过的每一个state的v现实值,用于计算td } # 更新全局网络的参数 self.AC.update_global(feed_dict) # update gradients on global network buffer_s, buffer_a, buffer_r = [], [], [] # 清空缓存 self.AC.pull_global() # update local network from global network s = s_ total_step += 1 # 本回合总步数加1 if done: if len(GLOBAL_RUNNING_R) == 0: # record running episode reward GLOBAL_RUNNING_R.append(ep_r) else: GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r) print( self.name, "Ep:", GLOBAL_EP, "| Ep_r: %i" % GLOBAL_RUNNING_R[-1], ) GLOBAL_EP += 1 # 加一回合 break # 结束这回合 if __name__ == "__main__": SESS = tf.Session() with tf.device("/cpu:0"): # 指定在cpu:0进行以下代码(CPU不区分设备号,统一使用 /cpu:0) OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA') # 创建Actor的优化器 OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC') # 创建Critic的优化器 GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # 创建全局网络GLOBAL_AC workers = [] # workers列表 # 创建 worker for i in range(N_WORKERS): # 创建n个worker,worker的数量最好和cpu的核一致,因为每个线程都是在一个单独的cpu进行 i_name = 'W_%i' % i # worker name workers.append(Worker(i_name, GLOBAL_AC)) # 创建worker,并放在workers列表中,方便统一管理 # 把每个worker对象都存放在一个workers列表中,方便使用 COORD = tf.train.Coordinator() # Tensorflow 用于并行的工具 SESS.run(tf.global_variables_initializer()) # global变量初始化 if OUTPUT_GRAPH: if os.path.exists(LOG_DIR): shutil.rmtree(LOG_DIR) tf.summary.FileWriter(LOG_DIR, SESS.graph) worker_threads = [] for worker in workers: # 执行每一个worker # t = threading.Thread(target=worker.work) job = lambda: worker.work() # worker要执行的工作 t = threading.Thread(target=job) # threading.Thread(target=job)创建线程,其中target要执行的函数 t.start() # 开始线程,并执行 worker_threads.append(t) # 把线程加入worker_threads中 COORD.join(worker_threads) # 线程由COORD统一管理即可 plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R) plt.xlabel('step') plt.ylabel('Total moving reward') plt.show()
注:框图取自李宏毅课程PPT, 算法流程图找不到来源了(侵删)
参考文献:
Asynchronous Methods for Deep Reinforcement Learning
http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
https://zhuanlan.zhihu.com/p/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/59316.html