
来源:SAMshare
为什么要学习Spark?作为数据从业者多年,个人觉得Spark已经越来越走进我们的日常工作了,无论是使用哪种编程语言,Python、Scala还是Java,都会或多或少接触到Spark,它可以让我们能够用到集群的力量,可以对BigData进行高效操作,实现很多之前由于计算资源而无法轻易实现的东西。网上有很多关于Spark的好处,这里就不做过多的赘述,我们直接进入这篇文章的正文!
关于PySpark,我们知道它是Python调用Spark的接口,我们可以通过调用Python API的方式来编写Spark程序,它支持了大多数的Spark功能,比如SparkDataFrame、Spark SQL、Streaming、MLlib等等。只要我们了解Python的基本语法,那么在Python里调用Spark的力量就显得十分easy了。下面我将会从相对宏观的层面介绍一下PySpark,让我们对于这个神器有一个框架性的认识,知道它能干什么,知道去哪里寻找问题解答,争取看完这篇文章可以让我们更加丝滑地入门PySpark。话不多说,马上开始!
???? 目录

???? 安装指引
安装这块本文就不展开具体的步骤了,毕竟大家的机子环境都不尽相同。不过可以简单说几点重要的步骤,然后节末放上一些安装示例供大家参考。
1)要使用PySpark,机子上要有Java开发环境
2)环境变量记得要配置完整
3)Mac下的/usr/local/ 路径一般是隐藏的,PyCharm配置py4j和pyspark的时候可以使用 shift+command+G 来使用路径访问。
4)Mac下如果修改了 ~/.bash_profile 的话,记得要重启下PyCharm才会生效的哈
5)版本记得要搞对,保险起见Java的jdk版本选择低版本(别问我为什么知道),我选择的是Java8.
下面是一些示例demo,可以参考下:
1)Mac下安装spark,并配置pycharm-pyspark完整教程
https://blog.csdn.net/shiyutianming/article/details/
2)virtualBox里安装开发环境
https://www.bilibili.com/video/BV1i4411i79a?p=3
3)快速搭建spark开发环境,云哥项目
https://github.com/lyhue1991/eat_pyspark_in_10_days
???? 基础概念
关于Spark的基础概念,我在先前的文章里也有写过,大家可以一起来回顾一下 《想学习Spark?先带你了解一些基础的知识》。作为补充,今天在这里也介绍一些在Spark中会经常遇见的专有名词。
????♀️ Q1: 什么是RDD
RDD的全称是 Resilient Distributed Datasets,这是Spark的一种数据抽象集合,它可以被执行在分布式的集群上进行各种操作,而且有较强的容错机制。RDD可以被分为若干个分区,每一个分区就是一个数据集片段,从而可以支持分布式计算。
????♀️ Q2: RDD运行时相关的关键名词
简单来说可以有 Client、Job、Master、Worker、Driver、Stage、Task以及Executor,这几个东西在调优的时候也会经常遇到的。
Client:指的是客户端进程,主要负责提交job到Master;
Job:Job来自于我们编写的程序,Application包含一个或者多个job,job包含各种RDD操作;
Master:指的是Standalone模式中的主控节点,负责接收来自Client的job,并管理着worker,可以给worker分配任务和资源(主要是driver和executor资源);
Worker:指的是Standalone模式中的slave节点,负责管理本节点的资源,同时受Master管理,需要定期给Master回报heartbeat(心跳),启动Driver和Executor;
Driver:指的是 job(作业)的主进程,一般每个Spark作业都会有一个Driver进程,负责整个作业的运行,包括了job的解析、Stage的生成、调度Task到Executor上去执行;
Stage:中文名 阶段,是job的基本调度单位,因为每个job会分成若干组Task,每组任务就被称为 Stage;
Task:任务,指的是直接运行在executor上的东西,是executor上的一个线程;
Executor:指的是 执行器,顾名思义就是真正执行任务的地方了,一个集群可以被配置若干个Executor,每个Executor接收来自Driver的Task,并执行它(可同时执行多个Task)。
????♀️ Q3: 什么是DAG
全称是 Directed Acyclic Graph,中文名是有向无环图。Spark就是借用了DAG对RDD之间的关系进行了建模,用来描述RDD之间的因果依赖关系。因为在一个Spark作业调度中,多个作业任务之间也是相互依赖的,有些任务需要在一些任务执行完成了才可以执行的。在Spark调度中就是有DAGscheduler,它负责将job分成若干组Task组成的Stage。
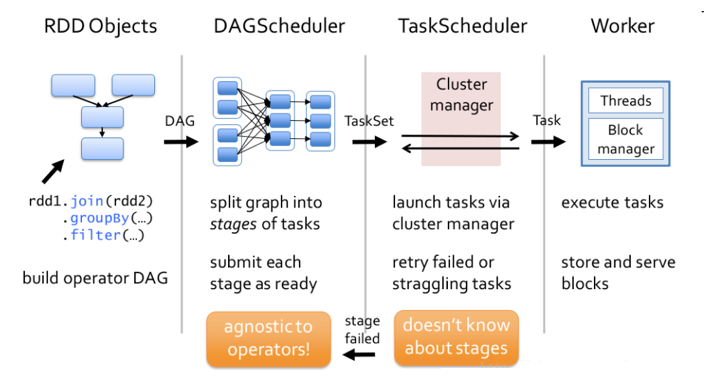
????♀️ Q4: Spark的部署模式有哪些
主要有local模式、Standalone模式、Mesos模式、YARN模式。
更多的解释可以参考这位老哥的解释。https://www.jianshu.com/p/3b8f
????♀️ Q5: Shuffle操作是什么
Shuffle指的是数据从Map端到Reduce端的数据传输过程,Shuffle性能的高低直接会影响程序的性能。因为Reduce task需要跨节点去拉在分布在不同节点上的Map task计算结果,这一个过程是需要有磁盘IO消耗以及数据网络传输的消耗的,所以需要根据实际数据情况进行适当调整。另外,Shuffle可以分为两部分,分别是Map阶段的数据准备与Reduce阶段的数据拷贝处理,在Map端我们叫Shuffle Write,在Reduce端我们叫Shuffle Read。
????♀️ Q6: 什么是惰性执行
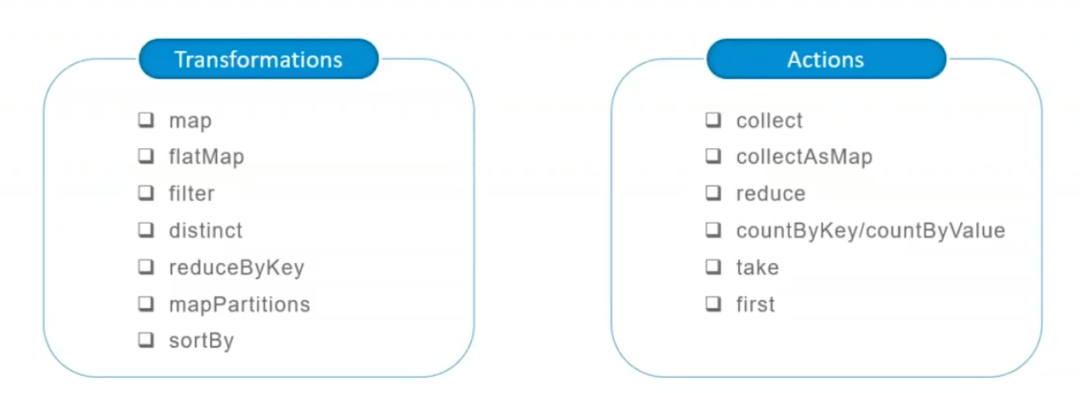
这是RDD的一个特性,在RDD中的算子可以分为Transform算子和Action算子,其中Transform算子的操作都不会真正执行,只会记录一下依赖关系,直到遇见了Action算子,在这之前的所有Transform操作才会被触发计算,这就是所谓的惰性执行。具体哪些是Transform和Action算子,可以看下一节。
???? 常用函数
从网友的总结来看比较常用的算子大概可以分为下面几种,所以就演示一下这些算子,如果需要看更多的算子或者解释,建议可以移步到官方API文档去Search一下哈。
pyspark.RDD:http://spark.apache.org/docs/latest/api/python/reference/api/pyspark.RDD.html#pyspark.RDD
下面我们用自己创建的RDD:sc.parallelize(range(1,11),4)
import os import pyspark from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName("test_SamShare").setMaster("local[4]") sc = SparkContext(conf=conf) # 使用 parallelize方法直接实例化一个RDD rdd = sc.parallelize(range(1,11),4) # 这里的 4 指的是分区数量 rdd.take(100) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] """ ---------------------------------------------- Transform算子解析 ---------------------------------------------- """ # 以下的操作由于是Transform操作,因为我们需要在最后加上一个collect算子用来触发计算。 # 1. map: 和python差不多,map转换就是对每一个元素进行一个映射 rdd = sc.parallelize(range(1, 11), 4) rdd_map = rdd.map(lambda x: x*2) print("原始数据:", rdd.collect()) print("扩大2倍:", rdd_map.collect()) # 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # 扩大2倍: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20] # 2. flatMap: 这个相比于map多一个flat(压平)操作,顾名思义就是要把高维的数组变成一维 rdd2 = sc.parallelize(["hello SamShare", "hello PySpark"]) print("原始数据:", rdd2.collect()) print("直接split之后的map结果:", rdd2.map(lambda x: x.split(" ")).collect()) print("直接split之后的flatMap结果:", rdd2.flatMap(lambda x: x.split(" ")).collect()) # 直接split之后的map结果: [['hello', 'SamShare'], ['hello', 'PySpark']] # 直接split之后的flatMap结果: ['hello', 'SamShare', 'hello', 'PySpark'] # 3. filter: 过滤数据 rdd = sc.parallelize(range(1, 11), 4) print("原始数据:", rdd.collect()) print("过滤奇数:", rdd.filter(lambda x: x % 2 == 0).collect()) # 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # 过滤奇数: [2, 4, 6, 8, 10] # 4. distinct: 去重元素 rdd = sc.parallelize([2, 2, 4, 8, 8, 8, 8, 16, 32, 32]) print("原始数据:", rdd.collect()) print("去重数据:", rdd.distinct().collect()) # 原始数据: [2, 2, 4, 8, 8, 8, 8, 16, 32, 32] # 去重数据: [4, 8, 16, 32, 2] # 5. reduceByKey: 根据key来映射数据 from operator import add rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)]) print("原始数据:", rdd.collect()) print("原始数据:", rdd.reduceByKey(add).collect()) # 原始数据: [('a', 1), ('b', 1), ('a', 1)] # 原始数据: [('b', 1), ('a', 2)] # 6. mapPartitions: 根据分区内的数据进行映射操作 rdd = sc.parallelize([1, 2, 3, 4], 2) def f(iterator): yield sum(iterator) print(rdd.collect()) print(rdd.mapPartitions(f).collect()) # [1, 2, 3, 4] # [3, 7] # 7. sortBy: 根据规则进行排序 tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)] print(sc.parallelize(tmp).sortBy(lambda x: x[0]).collect()) print(sc.parallelize(tmp).sortBy(lambda x: x[1]).collect()) # [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)] # [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)] # 8. subtract: 数据集相减, Return each value in self that is not contained in other. x = sc.parallelize([("a", 1), ("b", 4), ("b", 5), ("a", 3)]) y = sc.parallelize([("a", 3), ("c", None)]) print(sorted(x.subtract(y).collect())) # [('a', 1), ('b', 4), ('b', 5)] # 9. union: 合并两个RDD rdd = sc.parallelize([1, 1, 2, 3]) print(rdd.union(rdd).collect()) # [1, 1, 2, 3, 1, 1, 2, 3] # 10. interp: 取两个RDD的交集,同时有去重的功效 rdd1 = sc.parallelize([1, 10, 2, 3, 4, 5, 2, 3]) rdd2 = sc.parallelize([1, 6, 2, 3, 7, 8]) print(rdd1.interp(rdd2).collect()) # [1, 2, 3] # 11. cartesian: 生成笛卡尔积 rdd = sc.parallelize([1, 2]) print(sorted(rdd.cartesian(rdd).collect())) # [(1, 1), (1, 2), (2, 1), (2, 2)] # 12. zip: 拉链合并,需要两个RDD具有相同的长度以及分区数量 x = sc.parallelize(range(0, 5)) y = sc.parallelize(range(1000, 1005)) print(x.collect()) print(y.collect()) print(x.zip(y).collect()) # [0, 1, 2, 3, 4] # [1000, 1001, 1002, 1003, 1004] # [(0, 1000), (1, 1001), (2, 1002), (3, 1003), (4, 1004)] # 13. zipWithIndex: 将RDD和一个从0开始的递增序列按照拉链方式连接。 rdd_name = sc.parallelize(["LiLei", "Hanmeimei", "Lily", "Lucy", "Ann", "Dachui", "RuHua"]) rdd_index = rdd_name.zipWithIndex() print(rdd_index.collect()) # [('LiLei', 0), ('Hanmeimei', 1), ('Lily', 2), ('Lucy', 3), ('Ann', 4), ('Dachui', 5), ('RuHua', 6)] # 14. groupByKey: 按照key来聚合数据 rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)]) print(rdd.collect()) print(sorted(rdd.groupByKey().mapValues(len).collect())) print(sorted(rdd.groupByKey().mapValues(list).collect())) # [('a', 1), ('b', 1), ('a', 1)] # [('a', 2), ('b', 1)] # [('a', [1, 1]), ('b', [1])] # 15. sortByKey: tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)] print(sc.parallelize(tmp).sortByKey(True, 1).collect()) # [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)] # 16. join: x = sc.parallelize([("a", 1), ("b", 4)]) y = sc.parallelize([("a", 2), ("a", 3)]) print(sorted(x.join(y).collect())) # [('a', (1, 2)), ('a', (1, 3))] # 17. leftOuterJoin/rightOuterJoin x = sc.parallelize([("a", 1), ("b", 4)]) y = sc.parallelize([("a", 2)]) print(sorted(x.leftOuterJoin(y).collect())) # [('a', (1, 2)), ('b', (4, None))] """ ---------------------------------------------- Action算子解析 ---------------------------------------------- """ # 1. collect: 指的是把数据都汇集到driver端,便于后续的操作 rdd = sc.parallelize(range(0, 5)) rdd_collect = rdd.collect() print(rdd_collect) # [0, 1, 2, 3, 4] # 2. first: 取第一个元素 sc.parallelize([2, 3, 4]).first() # 2 # 3. collectAsMap: 转换为dict,使用这个要注意了,不要对大数据用,不然全部载入到driver端会爆内存 m = sc.parallelize([(1, 2), (3, 4)]).collectAsMap() m # {1: 2, 3: 4} # 4. reduce: 逐步对两个元素进行操作 rdd = sc.parallelize(range(10),5) print(rdd.reduce(lambda x,y:x+y)) # 45 # 5. countByKey/countByValue: rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)]) print(sorted(rdd.countByKey().items())) print(sorted(rdd.countByValue().items())) # [('a', 2), ('b', 1)] # [(('a', 1), 2), (('b', 1), 1)] # 6. take: 相当于取几个数据到driver端 rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)]) print(rdd.take(5)) # [('a', 1), ('b', 1), ('a', 1)] # 7. saveAsTextFile: 保存rdd成text文件到本地 text_file = "./data/rdd.txt" rdd = sc.parallelize(range(5)) rdd.saveAsTextFile(text_file) # 8. takeSample: 随机取数 rdd = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量 rdd_sample = rdd.takeSample(True, 2, 0) # withReplacement 参数1:代表是否是有放回抽样 rdd_sample # 9. foreach: 对每一个元素执行某种操作,不生成新的RDD rdd = sc.parallelize(range(10), 5) accum = sc.accumulator(0) rdd.foreach(lambda x: accum.add(x)) print(accum.value) # 45 讯享网
???? Spark SQL使用
在讲Spark SQL前,先解释下这个模块。这个模块是Spark中用来处理结构化数据的,提供一个叫SparkDataFrame的东西并且自动解析为分布式SQL查询数据。我们之前用过Python的Pandas库,也大致了解了DataFrame,这个其实和它没有太大的区别,只是调用的API可能有些不同罢了。
我们通过使用Spark SQL来处理数据,会让我们更加地熟悉,比如可以用SQL语句、用SparkDataFrame的API或者Datasets API,我们可以按照需求随心转换,通过SparkDataFrame API 和 SQL 写的逻辑,会被Spark优化器Catalyst自动优化成RDD,即便写得不好也可能运行得很快(如果是直接写RDD可能就挂了哈哈)。
创建SparkDataFrame
开始讲SparkDataFrame,我们先学习下几种创建的方法,分别是使用RDD来创建、使用python的DataFrame来创建、使用List来创建、读取数据文件来创建、通过读取数据库来创建。
1. 使用RDD来创建
主要使用RDD的toDF方法。
讯享网rdd = sc.parallelize([("Sam", 28, 88), ("Flora", 28, 90), ("Run", 1, 60)]) df = rdd.toDF(["name", "age", "score"]) df.show() df.printSchema() # +-----+---+-----+ # | name|age|score| # +-----+---+-----+ # | Sam| 28| 88| # |Flora| 28| 90| # | Run| 1| 60| # +-----+---+-----+ # root # |-- name: string (nullable = true) # |-- age: long (nullable = true) # |-- score: long (nullable = true)
2. 使用python的DataFrame来创建
df = pd.DataFrame([['Sam', 28, 88], ['Flora', 28, 90], ['Run', 1, 60]], columns=['name', 'age', 'score']) print(">> 打印DataFrame:") print(df) print("\n") Spark_df = spark.createDataFrame(df) print(">> 打印SparkDataFrame:") Spark_df.show() # >> 打印DataFrame: # name age score # 0 Sam 28 88 # 1 Flora 28 90 # 2 Run 1 60 # >> 打印SparkDataFrame: # +-----+---+-----+ # | name|age|score| # +-----+---+-----+ # | Sam| 28| 88| # |Flora| 28| 90| # | Run| 1| 60| # +-----+---+-----+ 3. 使用List来创建
讯享网list_values = [['Sam', 28, 88], ['Flora', 28, 90], ['Run', 1, 60]] Spark_df = spark.createDataFrame(list_values, ['name', 'age', 'score']) Spark_df.show() # +-----+---+-----+ # | name|age|score| # +-----+---+-----+ # | Sam| 28| 88| # |Flora| 28| 90| # | Run| 1| 60| # +-----+---+-----+
4. 读取数据文件来创建
# 4.1 CSV文件 df = spark.read.option("header", "true")\ .option("inferSchema", "true")\ .option("delimiter", ",")\ .csv("./test/data/titanic/train.csv") df.show(5) df.printSchema() # 4.2 json文件 df = spark.read.json("./test/data/hello_samshare.json") df.show(5) df.printSchema() 5. 通过读取数据库来创建
讯享网# 5.1 读取hive数据 spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive") spark.sql("LOAD DATA LOCAL INPATH 'data/kv1.txt' INTO TABLE src") df = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key") df.show(5) # 5.2 读取mysql数据 url = "jdbc:mysql://localhost:3306/test" df = spark.read.format("jdbc") \ .option("url", url) \ .option("dbtable", "runoob_tbl") \ .option("user", "root") \ .option("password", "8888") \ .load()\ df.show()
常用的SparkDataFrame API
这里我大概是分成了几部分来看这些APIs,分别是查看DataFrame的APIs、简单处理DataFrame的APIs、DataFrame的列操作APIs、DataFrame的一些思路变换操作APIs、DataFrame的一些统计操作APIs,这样子也有助于我们了解这些API的功能,以后遇见实际问题的时候可以解决。
首先我们这小节全局用到的数据集如下:
from pyspark.sql import functions as F from pyspark.sql import SparkSession # SparkSQL的许多功能封装在SparkSession的方法接口中, SparkContext则不行的。 spark = SparkSession.builder \ .appName("sam_SamShare") \ .config("master", "local[4]") \ .enableHiveSupport() \ .getOrCreate() sc = spark.sparkContext # 创建一个SparkDataFrame rdd = sc.parallelize([("Sam", 28, 88, "M"), ("Flora", 28, 90, "F"), ("Run", 1, 60, None), ("Peter", 55, 100, "M"), ("Mei", 54, 95, "F")]) df = rdd.toDF(["name", "age", "score", "sex"]) df.show() df.printSchema() # +-----+---+-----+----+ # | name|age|score| sex| # +-----+---+-----+----+ # | Sam| 28| 88| M| # |Flora| 28| 90| F| # | Run| 1| 60|null| # |Peter| 55| 100| M| # | Mei| 54| 95| F| # +-----+---+-----+----+ # root # |-- name: string (nullable = true) # |-- age: long (nullable = true) # |-- score: long (nullable = true) # |-- sex: string (nullable = true) 1. 查看DataFrame的APIs
讯享网# DataFrame.collect # 以列表形式返回行 df.collect() # [Row(name='Sam', age=28, score=88, sex='M'), # Row(name='Flora', age=28, score=90, sex='F'), # Row(name='Run', age=1, score=60, sex=None), # Row(name='Peter', age=55, score=100, sex='M'), # Row(name='Mei', age=54, score=95, sex='F')] # DataFrame.count df.count() # 5 # DataFrame.columns df.columns # ['name', 'age', 'score', 'sex'] # DataFrame.dtypes df.dtypes # [('name', 'string'), ('age', 'bigint'), ('score', 'bigint'), ('sex', 'string')] # DataFrame.describe # 返回列的基础统计信息 df.describe(['age']).show() # +-------+------------------+ # |summary| age| # +-------+------------------+ # | count| 5| # | mean| 33.2| # | stddev|22.2826| # | min| 1| # | max| 55| # +-------+------------------+ df.describe().show() # +-------+-----+------------------+------------------+----+ # |summary| name| age| score| sex| # +-------+-----+------------------+------------------+----+ # | count| 5| 5| 5| 4| # | mean| null| 33.2| 86.6|null| # | stddev| null|22.2826|15.5966|null| # | min|Flora| 1| 60| F| # | max| Sam| 55| 100| M| # +-------+-----+------------------+------------------+----+ # DataFrame.select # 选定指定列并按照一定顺序呈现 df.select("sex", "score").show() # DataFrame.first # DataFrame.head # 查看第1条数据 df.first() # Row(name='Sam', age=28, score=88, sex='M') df.head(1) # [Row(name='Sam', age=28, score=88, sex='M')] # DataFrame.freqItems # 查看指定列的枚举值 df.freqItems(["age","sex"]).show() # +---------------+-------------+ # | age_freqItems|sex_freqItems| # +---------------+-------------+ # |[55, 1, 28, 54]| [M, F,]| # +---------------+-------------+ # DataFrame.summary df.summary().show() # +-------+-----+------------------+------------------+----+ # |summary| name| age| score| sex| # +-------+-----+------------------+------------------+----+ # | count| 5| 5| 5| 4| # | mean| null| 33.2| 86.6|null| # | stddev| null|22.2826|15.5966|null| # | min|Flora| 1| 60| F| # | 25%| null| 28| 88|null| # | 50%| null| 28| 90|null| # | 75%| null| 54| 95|null| # | max| Sam| 55| 100| M| # +-------+-----+------------------+------------------+----+ # DataFrame.sample # 按照一定规则从df随机抽样数据 df.sample(0.5).show() # +-----+---+-----+----+ # | name|age|score| sex| # +-----+---+-----+----+ # | Sam| 28| 88| M| # | Run| 1| 60|null| # |Peter| 55| 100| M| # +-----+---+-----+----+
2. 简单处理DataFrame的APIs
# DataFrame.distinct # 对数据集进行去重 df.distinct().show() # DataFrame.dropDuplicates # 对指定列去重 df.dropDuplicates(["sex"]).show() # +-----+---+-----+----+ # | name|age|score| sex| # +-----+---+-----+----+ # |Flora| 28| 90| F| # | Run| 1| 60|null| # | Sam| 28| 88| M| # +-----+---+-----+----+ # DataFrame.exceptAll # DataFrame.subtract # 根据指定的df对df进行去重 df1 = spark.createDataFrame( [("a", 1), ("a", 1), ("b", 3), ("c", 4)], ["C1", "C2"]) df2 = spark.createDataFrame([("a", 1), ("b", 3)], ["C1", "C2"]) df3 = df1.exceptAll(df2) # 没有去重的功效 df4 = df1.subtract(df2) # 有去重的奇效 df1.show() df2.show() df3.show() df4.show() # +---+---+ # | C1| C2| # +---+---+ # | a| 1| # | a| 1| # | b| 3| # | c| 4| # +---+---+ # +---+---+ # | C1| C2| # +---+---+ # | a| 1| # | b| 3| # +---+---+ # +---+---+ # | C1| C2| # +---+---+ # | a| 1| # | c| 4| # +---+---+ # +---+---+ # | C1| C2| # +---+---+ # | c| 4| # +---+---+ # DataFrame.intersectAll # 返回两个DataFrame的交集 df1 = spark.createDataFrame( [("a", 1), ("a", 1), ("b", 3), ("c", 4)], ["C1", "C2"]) df2 = spark.createDataFrame([("a", 1), ("b", 4)], ["C1", "C2"]) df1.intersectAll(df2).show() # +---+---+ # | C1| C2| # +---+---+ # | a| 1| # +---+---+ # DataFrame.drop # 丢弃指定列 df.drop('age').show() # DataFrame.withColumn # 新增列 df1 = df.withColumn("birth_year", 2021 - df.age) df1.show() # +-----+---+-----+----+----------+ # | name|age|score| sex|birth_year| # +-----+---+-----+----+----------+ # | Sam| 28| 88| M| 1993| # |Flora| 28| 90| F| 1993| # | Run| 1| 60|null| 2020| # |Peter| 55| 100| M| 1966| # | Mei| 54| 95| F| 1967| # +-----+---+-----+----+----------+ # DataFrame.withColumnRenamed # 重命名列名 df1 = df.withColumnRenamed("sex", "gender") df1.show() # +-----+---+-----+------+ # | name|age|score|gender| # +-----+---+-----+------+ # | Sam| 28| 88| M| # |Flora| 28| 90| F| # | Run| 1| 60| null| # |Peter| 55| 100| M| # | Mei| 54| 95| F| # +-----+---+-----+------+ # DataFrame.dropna # 丢弃空值,DataFrame.dropna(how='any', thresh=None, subset=None) df.dropna(how='all', subset=['sex']).show() # +-----+---+-----+---+ # | name|age|score|sex| # +-----+---+-----+---+ # | Sam| 28| 88| M| # |Flora| 28| 90| F| # |Peter| 55| 100| M| # | Mei| 54| 95| F| # +-----+---+-----+---+ # DataFrame.fillna # 空值填充操作 df1 = spark.createDataFrame( [("a", None), ("a", 1), (None, 3), ("c", 4)], ["C1", "C2"]) # df2 = df1.na.fill({"C1": "d", "C2": 99}) df2 = df1.fillna({"C1": "d", "C2": 99}) df1.show() df2.show() # DataFrame.filter # 根据条件过滤 df.filter(df.age>50).show() # +-----+---+-----+---+ # | name|age|score|sex| # +-----+---+-----+---+ # |Peter| 55| 100| M| # | Mei| 54| 95| F| # +-----+---+-----+---+ df.where(df.age==28).show() # +-----+---+-----+---+ # | name|age|score|sex| # +-----+---+-----+---+ # | Sam| 28| 88| M| # |Flora| 28| 90| F| # +-----+---+-----+---+ df.filter("age<18").show() # +----+---+-----+----+ # |name|age|score| sex| # +----+---+-----+----+ # | Run| 1| 60|null| # +----+---+-----+----+ # DataFrame.join # 这个不用多解释了,直接上案例来看看具体的语法即可,DataFrame.join(other, on=None, how=None) df1 = spark.createDataFrame( [("a", 1), ("d", 1), ("b", 3), ("c", 4)], ["id", "num1"]) df2 = spark.createDataFrame([("a", 1), ("b", 3)], ["id", "num2"]) df1.join(df2, df1.id == df2.id, 'left').select(df1.id.alias("df1_id"), df1.num1.alias("df1_num"), df2.num2.alias("df2_num") ).sort(["df1_id"], ascending=False)\ .show() # DataFrame.agg(*exprs) # 聚合数据,可以写多个聚合方法,如果不写groupBy的话就是对整个DF进行聚合 # DataFrame.alias # 设置列或者DataFrame别名 # DataFrame.groupBy # 根据某几列进行聚合,如有多列用列表写在一起,如 df.groupBy(["sex", "age"]) df.groupBy("sex").agg(F.min(df.age).alias("最小年龄"), F.expr("avg(age)").alias("平均年龄"), F.expr("collect_list(name)").alias("姓名集合") ).show() # +----+--------+--------+------------+ # | sex|最小年龄|平均年龄| 姓名集合| # +----+--------+--------+------------+ # | F| 28| 41.0|[Flora, Mei]| # |null| 1| 1.0| [Run]| # | M| 28| 41.5|[Sam, Peter]| # +----+--------+--------+------------+ # DataFrame.foreach # 对每一行进行函数方法的应用 def f(person): print(person.name) df.foreach(f) # Peter # Run # Sam # Flora # Mei # DataFrame.replace # 修改df里的某些值 df1 = df.na.replace({"M": "Male", "F": "Female"}) df1.show() # DataFrame.union # 相当于SQL里的union all操作 df1 = spark.createDataFrame( [("a", 1), ("d", 1), ("b", 3), ("c", 4)], ["id", "num"]) df2 = spark.createDataFrame([("a", 1), ("b", 3)], ["id", "num"]) df1.union(df2).show() df1.unionAll(df2).show() # 这里union没有去重,不知道为啥,有知道的朋友麻烦解释下,谢谢了。 # +---+---+ # | id|num| # +---+---+ # | a| 1| # | d| 1| # | b| 3| # | c| 4| # | a| 1| # | b| 3| # +---+---+ # DataFrame.unionByName # 根据列名来进行合并数据集 df1 = spark.createDataFrame([[1, 2, 3]], ["col0", "col1", "col2"]) df2 = spark.createDataFrame([[4, 5, 6]], ["col1", "col2", "col0"]) df1.unionByName(df2).show() # +----+----+----+ # |col0|col1|col2| # +----+----+----+ # | 1| 2| 3| # | 6| 4| 5| # +----+----+----+ 3. DataFrame的列操作APIs
这里主要针对的是列进行操作,比如说重命名、排序、空值判断、类型判断等,这里就不展开写demo了,看看语法应该大家都懂了。
讯享网Column.alias(*alias, kwargs) # 重命名列名 Column.asc() # 按照列进行升序排序 Column.desc() # 按照列进行降序排序 Column.astype(dataType) # 类型转换 Column.cast(dataType) # 强制转换类型 Column.between(lowerBound, upperBound) # 返回布尔值,是否在指定区间范围内 Column.contains(other) # 是否包含某个关键词 Column.endswith(other) # 以什么结束的值,如 df.filter(df.name.endswith('ice')).collect() Column.isNotNull() # 筛选非空的行 Column.isNull() Column.isin(*cols) # 返回包含某些值的行 df[df.name.isin("Bob", "Mike")].collect() Column.like(other) # 返回含有关键词的行 Column.when(condition, value) # 给True的赋值 Column.otherwise(value) # 与when搭配使用,df.select(df.name, F.when(df.age > 3, 1).otherwise(0)).show() Column.rlike(other) # 可以使用正则的匹配 df.filter(df.name.rlike('ice$')).collect() Column.startswith(other) # df.filter(df.name.startswith('Al')).collect() Column.substr(startPos, length) # df.select(df.name.substr(1, 3).alias("col")).collect()
4. DataFrame的一些思路变换操作APIs
# DataFrame.createOrReplaceGlobalTempView # DataFrame.dropGlobalTempView # 创建全局的试图,注册后可以使用sql语句来进行操作,生命周期取决于Spark application本身 df.createOrReplaceGlobalTempView("people") spark.sql("select * from global_temp.people where sex = 'M' ").show() # +-----+---+-----+---+ # | name|age|score|sex| # +-----+---+-----+---+ # | Sam| 28| 88| M| # |Peter| 55| 100| M| # +-----+---+-----+---+ # DataFrame.createOrReplaceTempView # DataFrame.dropTempView # 创建本地临时试图,生命周期取决于用来创建此数据集的SparkSession df.createOrReplaceTempView("tmp_people") spark.sql("select * from tmp_people where sex = 'F' ").show() # +-----+---+-----+---+ # | name|age|score|sex| # +-----+---+-----+---+ # |Flora| 28| 90| F| # | Mei| 54| 95| F| # +-----+---+-----+---+ # DataFrame.cache\DataFrame.persist # 可以把一些数据放入缓存中,default storage level (MEMORY_AND_DISK). df.cache() df.persist() df.unpersist() # DataFrame.crossJoin # 返回两个DataFrame的笛卡尔积关联的DataFrame df1 = df.select("name", "sex") df2 = df.select("name", "sex") df3 = df1.crossJoin(df2) print("表1的记录数", df1.count()) print("表2的记录数", df2.count()) print("笛卡尔积后的记录数", df3.count()) # 表1的记录数 5 # 表2的记录数 5 # 笛卡尔积后的记录数 25 # DataFrame.toPandas # 把SparkDataFrame转为 Pandas的DataFrame df.toPandas() # DataFrame.rdd # 把SparkDataFrame转为rdd,这样子可以用rdd的语法来操作数据 df.rdd 5. DataFrame的一些统计操作APIs
讯享网# DataFrame.cov # 计算指定两列的样本协方差 df.cov("age", "score") # 324.997 # DataFrame.corr # 计算指定两列的相关系数,DataFrame.corr(col1, col2, method=None),目前method只支持Pearson相关系数 df.corr("age", "score", method="pearson") # 0.98815 # DataFrame.cube # 创建多维度聚合的结果,通常用于分析数据,比如我们指定两个列进行聚合,比如name和age,那么这个函数返回的聚合结果会 # groupby("name", "age") # groupby("name") # groupby("age") # groupby(all) # 四个聚合结果的union all 的结果 df1 = df.filter(df.name != "Run") print(df1.show()) df1.cube("name", "sex").count().show() # +-----+---+-----+---+ # | name|age|score|sex| # +-----+---+-----+---+ # | Sam| 28| 88| M| # |Flora| 28| 90| F| # |Peter| 55| 100| M| # | Mei| 54| 95| F| # +-----+---+-----+---+ # cube 聚合之后的结果 # +-----+----+-----+ # | name| sex|count| # +-----+----+-----+ # | null| F| 2| # | null|null| 4| # |Flora|null| 1| # |Peter|null| 1| # | null| M| 2| # |Peter| M| 1| # | Sam| M| 1| # | Sam|null| 1| # | Mei| F| 1| # | Mei|null| 1| # |Flora| F| 1| # +-----+----+-----+
保存数据/写入数据库
这里的保存数据主要是保存到Hive中的栗子,主要包括了overwrite、append等方式。
1. 当结果集为SparkDataFrame的时候
import pandas as pd from datetime import datetime from pyspark import SparkConf from pyspark import SparkContext from pyspark.sql import HiveContext conf = SparkConf()\ .setAppName("test")\ .set("hive.exec.dynamic.partition.mode", "nonstrict") # 动态写入hive分区表 sc = SparkContext(conf=conf) hc = HiveContext(sc) sc.setLogLevel("ERROR") list_values = [['Sam', 28, 88], ['Flora', 28, 90], ['Run', 1, 60]] Spark_df = spark.createDataFrame(list_values, ['name', 'age', 'score']) print(Spark_df.show()) save_table = "tmp.samshare_pyspark_savedata" # 方式1:直接写入到Hive Spark_df.write.format("hive").mode("overwrite").saveAsTable(save_table) # 或者改成append模式 print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table) # 方式2:注册为临时表,使用SparkSQL来写入分区表 Spark_df.createOrReplaceTempView("tmp_table") write_sql = """ insert overwrite table {0} partitions (pt_date='{1}') select * from tmp_table """.format(save_table, "") hc.sql(write_sql) print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table) 2. 当结果集为Python的DataFrame的时候
如果是Python的DataFrame,我们就需要多做一步把它转换为SparkDataFrame,其余操作就一样了。
讯享网import pandas as pd from datetime import datetime from pyspark import SparkConf from pyspark import SparkContext from pyspark.sql import HiveContext conf = SparkConf()\ .setAppName("test")\ .set("hive.exec.dynamic.partition.mode", "nonstrict") # 动态写入hive分区表 sc = SparkContext(conf=conf) hc = HiveContext(sc) sc.setLogLevel("ERROR") result_df = pd.DataFrame([1,2,3], columns=['a']) save_table = "tmp.samshare_pyspark_savedata" # 获取DataFrame的schema c1 = list(result_df.columns) # 转为SparkDataFrame result = hc.createDataFrame(result_df.astype(str), c1) result.write.format("hive").mode("overwrite").saveAsTable(save_table) # 或者改成append模式 print(datetime.now().strftime("%y/%m/%d %H:%M:%S"), "测试数据写入到表" + save_table)
???? Spark调优思路
这一小节的内容算是对pyspark入门的一个ending了,全文主要是参考学习了美团Spark性能优化指南的基础篇和高级篇内容,主体脉络和这两篇文章是一样的,只不过是基于自己学习后的理解进行了一次总结复盘,而原文中主要是用Java来举例的,我这边主要用pyspark来举例。文章主要会从4个方面(或者说4个思路)来优化我们的Spark任务,主要就是下面的图片所示:
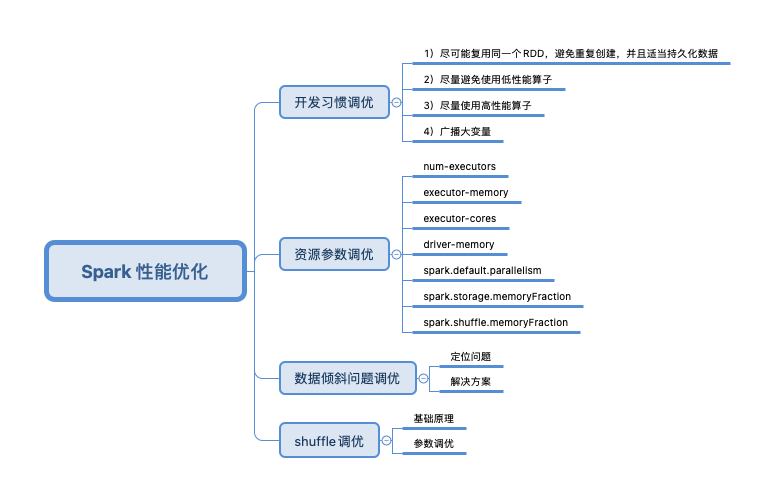
开发习惯调优
1. 尽可能复用同一个RDD,避免重复创建,并且适当持久化数据
这种开发习惯是需要我们对于即将要开发的应用逻辑有比较深刻的思考,并且可以通过code review来发现的,讲白了就是要记得我们创建过啥数据集,可以复用的尽量广播(broadcast)下,能很好提升性能。
# 最低级写法,相同数据集重复创建。 rdd1 = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量 rdd2 = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量 print(rdd1.take(10)) print(rdd2.map(lambda x:x[0:1]).take(10)) # 稍微进阶一些,复用相同数据集,但因中间结果没有缓存,数据会重复计算 rdd1 = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量 print(rdd1.take(10)) print(rdd1.map(lambda x:x[0:1]).take(10)) # 相对比较高效,使用缓存来持久化数据 rdd = sc.parallelize(range(1, 11), 4).cache() # 或者persist() rdd_map = rdd.map(lambda x: x*2) rdd_reduce = rdd.reduce(lambda x, y: x+y) print(rdd_map.take(10)) print(rdd_reduce) 下面我们就来对比一下使用缓存能给我们的Spark程序带来多大的效率提升吧,我们先构造一个程序运行时长测量器。
讯享网import time # 统计程序运行时间 def time_me(info="used"): def _time_me(fn): @functools.wraps(fn) def _wrapper(*args, kwargs): start = time.time() fn(*args, kwargs) print("%s %s %s" % (fn.__name__, info, time.time() - start), "second") return _wrapper return _time_me
下面我们运行下面的代码,看下使用了cache带来的效率提升:
@time_me() def test(types=0): if types == 1: print("使用持久化缓存") rdd = sc.parallelize(range(1, ), 4) rdd1 = rdd.map(lambda x: x*x + 2*x + 1).cache() # 或者 persist(StorageLevel.MEMORY_AND_DISK_SER) print(rdd1.take(10)) rdd2 = rdd1.reduce(lambda x, y: x+y) rdd3 = rdd1.reduce(lambda x, y: x + y) rdd4 = rdd1.reduce(lambda x, y: x + y) rdd5 = rdd1.reduce(lambda x, y: x + y) print(rdd5) else: print("不使用持久化缓存") rdd = sc.parallelize(range(1, ), 4) rdd1 = rdd.map(lambda x: x * x + 2 * x + 1) print(rdd1.take(10)) rdd2 = rdd1.reduce(lambda x, y: x + y) rdd3 = rdd1.reduce(lambda x, y: x + y) rdd4 = rdd1.reduce(lambda x, y: x + y) rdd5 = rdd1.reduce(lambda x, y: x + y) print(rdd5) test() # 不使用持久化缓存 time.sleep(10) test(1) # 使用持久化缓存 # output: # 使用持久化缓存 # [4, 9, 16, 25, 36, 49, 64, 81, 100, 121] # # test used 26.188 second # 使用持久化缓存 # [4, 9, 16, 25, 36, 49, 64, 81, 100, 121] # # test used 17.666 second 同时我们打开YARN日志来看看:http://localhost:4040/jobs/
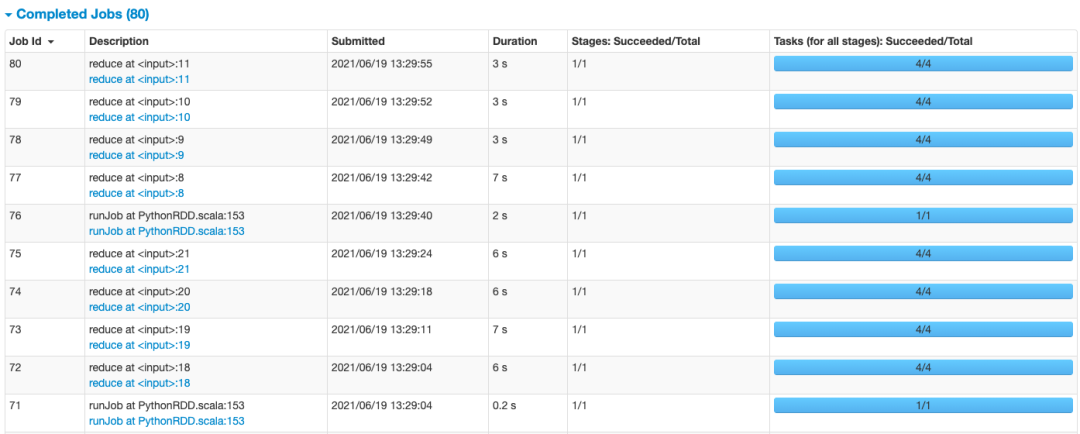

因为我们的代码是需要重复调用RDD1的,当没有对RDD1进行持久化的时候,每次当它被action算子消费了之后,就释放了,等下一个算子计算的时候要用,就从头开始计算一下RDD1。代码中需要重复调用RDD1 五次,所以没有缓存的话,差不多每次都要6秒,总共需要耗时26秒左右,但是,做了缓存,每次就只需要3s不到,总共需要耗时17秒左右。
另外,这里需要提及一下一个知识点,那就是持久化的级别,一般cache的话就是放入内存中,就没有什么好说的,需要讲一下的就是另外一个 persist(),它的持久化级别是可以被我们所配置的:
| 持久化级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。使用cache()方法时,实际就是使用的这种持久化策略,性能也是最高的。 |
| MEMORY_AND_DISK | 优先尝试将数据保存在内存中,如果内存不够存放所有的数据,会将数据写入磁盘文件中。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是会先序列化,节约内存。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。一般不推荐使用。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等. | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。一般也不推荐使用。 |
2. 尽量避免使用低性能算子
shuffle类算子算是低性能算子的一种代表,所谓的shuffle类算子,指的是会产生shuffle过程的操作,就是需要把各个节点上的相同key写入到本地磁盘文件中,然后其他的节点通过网络传输拉取自己需要的key,把相同key拉到同一个节点上进行聚合计算,这种操作必然就是有大量的数据网络传输与磁盘读写操作,性能往往不是很好的。
那么,Spark中有哪些算子会产生shuffle过程呢?
| 操作类别 | shuffle类算子 | 备注 |
|---|---|---|
| 分区操作 | repartition()、repartitionAndSortWithinPartitions()、coalesce(shuffle=true) | 重分区操作一般都会shuffle,因为需要对所有的分区数据进行打乱。 |
| 聚合操作 | reduceByKey、groupByKey、sortByKey | 需要对相同key进行操作,所以需要拉到同一个节点上。 |
| 关联操作 | join类操作 | 需要把相同key的数据shuffle到同一个节点然后进行笛卡尔积 |
| 去重操作 | distinct等 | 需要对相同key进行操作,所以需要shuffle到同一个节点上。 |
| 排序操作 | sortByKey等 | 需要对相同key进行操作,所以需要shuffle到同一个节点上。 |
这里进一步介绍一个替代join的方案,因为join其实在业务中还是蛮常见的。
讯享网# 原则2:尽量避免使用低性能算子 rdd1 = sc.parallelize([('A1', 211), ('A1', 212), ('A2', 22), ('A4', 24), ('A5', 25)]) rdd2 = sc.parallelize([('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)]) # 低效的写法,也是传统的写法,直接join rdd_join = rdd1.join(rdd2) print(rdd_join.collect()) # [('A4', (24, 14)), ('A2', (22, 12)), ('A1', (211, 11)), ('A1', (212, 11))] rdd_left_join = rdd1.leftOuterJoin(rdd2) print(rdd_left_join.collect()) # [('A4', (24, 14)), ('A2', (22, 12)), ('A5', (25, None)), ('A1', (211, 11)), ('A1', (212, 11))] rdd_full_join = rdd1.fullOuterJoin(rdd2) print(rdd_full_join.collect()) # [('A4', (24, 14)), ('A3', (None, 13)), ('A2', (22, 12)), ('A5', (25, None)), ('A1', (211, 11)), ('A1', (212, 11))] # 高效的写法,使用广播+map来实现相同效果 # tips1: 这里需要注意的是,用来broadcast的RDD不可以太大,最好不要超过1G # tips2: 这里需要注意的是,用来broadcast的RDD不可以有重复的key的 rdd1 = sc.parallelize([('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)]) rdd2 = sc.parallelize([('A1', 211), ('A1', 212), ('A2', 22), ('A4', 24), ('A5', 25)]) # step1: 先将小表进行广播,也就是collect到driver端,然后广播到每个Executor中去。 rdd_small_bc = sc.broadcast(rdd1.collect()) # step2:从Executor中获取存入字典便于后续map操作 rdd_small_dict = dict(rdd_small_bc.value) # step3:定义join方法 def broadcast_join(line, rdd_small_dict, join_type): k = line[0] v = line[1] small_table_v = rdd_small_dict[k] if k in rdd_small_dict else None if join_type == 'join': return (k, (v, small_table_v)) if k in rdd_small_dict else None elif join_type == 'left_join': return (k, (v, small_table_v if small_table_v is not None else None)) else: print("not support join type!") # step4:使用 map 实现 两个表join的功能 rdd_join = rdd2.map(lambda line: broadcast_join(line, rdd_small_dict, "join")).filter(lambda line: line is not None) rdd_left_join = rdd2.map(lambda line: broadcast_join(line, rdd_small_dict, "left_join")).filter(lambda line: line is not None) print(rdd_join.collect()) print(rdd_left_join.collect()) # [('A1', (211, 11)), ('A1', (212, 11)), ('A2', (22, 12)), ('A4', (24, 14))] # [('A1', (211, 11)), ('A1', (212, 11)), ('A2', (22, 12)), ('A4', (24, 14)), ('A5', (25, None))]
上面的RDD join被改写为 broadcast+map的PySpark版本实现,不过里面有两个点需要注意:
- tips1: 用来broadcast的RDD不可以太大,最好不要超过1G
- tips2: 用来broadcast的RDD不可以有重复的key的
3. 尽量使用高性能算子
上一节讲到了低效算法,自然地就会有一些高效的算子。
| 原算子 | 高效算子(替换算子) | 说明 |
|---|---|---|
| map | mapPartitions | 直接map的话,每次只会处理一条数据,而mapPartitions则是每次处理一个分区的数据,在某些场景下相对比较高效。(分区数据量不大的情况下使用,如果有数据倾斜的话容易发生OOM) |
| groupByKey | reduceByKey/aggregateByKey | 这类算子会在原节点先map-side预聚合,相对高效些。 |
| foreach | foreachPartitions | 同第一条记录一样。 |
| filter | filter+coalesce | 当我们对数据进行filter之后,有很多partition的数据会剧减,然后直接进行下一步操作的话,可能就partition数量很多但处理的数据又很少,task数量没有减少,反而整体速度很慢;但如果执行了coalesce算子,就会减少一些partition数量,把数据都相对压缩到一起,用更少的task处理完全部数据,一定场景下还是可以达到整体性能的提升。 |
| repartition+sort | repartitionAndSortWithinPartitions | 直接用就是了。 |
4. 广播大变量
如果我们有一个数据集很大,并且在后续的算子执行中会被反复调用,那么就建议直接把它广播(broadcast)一下。当变量被广播后,会保证每个executor的内存中只会保留一份副本,同个executor内的task都可以共享这个副本数据。如果没有广播,常规过程就是把大变量进行网络传输到每一个相关task中去,这样子做,一来频繁的网络数据传输,效率极其低下;二来executor下的task不断存储同一份大数据,很有可能就造成了内存溢出或者频繁GC,效率也是极其低下的。
# 原则4:广播大变量 rdd1 = sc.parallelize([('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)]) rdd1_broadcast = sc.broadcast(rdd1.collect()) print(rdd1.collect()) print(rdd1_broadcast.value) # [('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)] # [('A1', 11), ('A2', 12), ('A3', 13), ('A4', 14)] 资源参数调优
如果要进行资源调优,我们就必须先知道Spark运行的机制与流程。
下面我们就来讲解一些常用的Spark资源配置的参数吧,了解其参数原理便于我们依据实际的数据情况进行配置。
1)num-executors
指的是执行器的数量,数量的多少代表了并行的stage数量(假如executor是单核的话),但也并不是越多越快,受你集群资源的限制,所以一般设置50-100左右吧。
2)executor-memory
这里指的是每一个执行器的内存大小,内存越大当然对于程序运行是很好的了,但是也不是无节制地大下去,同样受我们集群资源的限制。假设我们集群资源为500core,一般1core配置4G内存,所以集群最大的内存资源只有2000G左右。num-executors x executor-memory 是不能超过2000G的,但是也不要太接近这个值,不然的话集群其他同事就没法正常跑数据了,一般我们设置4G-8G。
3)executor-cores
这里设置的是executor的CPU core数量,决定了executor进程并行处理task的能力。
4)driver-memory
设置driver的内存,一般设置2G就好了。但如果想要做一些Python的DataFrame操作可以适当地把这个值设大一些。
5)driver-cores
与executor-cores类似的功能。
6)spark.default.parallelism
设置每个stage的task数量。一般Spark任务我们设置task数量在500-1000左右比较合适,如果不去设置的话,Spark会根据底层HDFS的block数量来自行设置task数量。有的时候会设置得偏少,这样子程序就会跑得很慢,即便你设置了很多的executor,但也没有用。
下面说一个基本的参数设置的shell脚本,一般我们都是通过一个shell脚本来设置资源参数配置,接着就去调用我们的主函数。
讯享网#!/bin/bash basePath=$(cd "$(dirname )"$(cd "$(dirname "$0"): pwd)")": pwd) spark-submit \ --master yarn \ --queue samshare \ --deploy-mode client \ --num-executors 100 \ --executor-memory 4G \ --executor-cores 4 \ --driver-memory 2G \ --driver-cores 2 \ --conf spark.default.parallelism=1000 \ --conf spark.yarn.executor.memoryOverhead=8G \ --conf spark.sql.shuffle.partitions=1000 \ --conf spark.network.timeout=1200 \ --conf spark.python.worker.memory=64m \ --conf spark.sql.catalogImplementation=hive \ --conf spark.sql.crossJoin.enabled=True \ --conf spark.dynamicAllocation.enabled=True \ --conf spark.shuffle.service.enabled=True \ --conf spark.scheduler.listenerbus.eventqueue.size= \ --conf spark.pyspark.driver.python=python3 \ --conf spark.pyspark.python=python3 \ --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=python3 \ --conf spark.sql.pivotMaxValues= \ --conf spark.hadoop.hive.exec.dynamic.partition=True \ --conf spark.hadoop.hive.exec.dynamic.partition.mode=nonstrict \ --conf spark.hadoop.hive.exec.max.dynamic.partitions.pernode= \ --conf spark.hadoop.hive.exec.max.dynamic.partitions= \ --conf spark.hadoop.hive.exec.max.created.files= \ ${bashPath}/project_name/main.py $v_var1 $v_var2
数据倾斜调优
相信我们对于数据倾斜并不陌生了,很多时间数据跑不出来有很大的概率就是出现了数据倾斜,在Spark开发中无法避免的也会遇到这类问题,而这不是一个崭新的问题,成熟的解决方案也是有蛮多的,今天来简单介绍一些比较常用并且有效的方案。
首先我们要知道,在Spark中比较容易出现倾斜的操作,主要集中在distinct、groupByKey、reduceByKey、aggregateByKey、join、repartition等,可以优先看这些操作的前后代码。而为什么使用了这些操作就容易导致数据倾斜呢?大多数情况就是进行操作的key分布不均,然后使得大量的数据集中在同一个处理节点上,从而发生了数据倾斜。
查看Key 分布
# 针对Spark SQL hc.sql("select key, count(0) nums from table_name group by key") # 针对RDD RDD.countByKey() Plan A: 过滤掉导致倾斜的key
这个方案并不是所有场景都可以使用的,需要结合业务逻辑来分析这个key到底还需要不需要,大多数情况可能就是一些异常值或者空串,这种就直接进行过滤就好了。
Plan B: 提前处理聚合
如果有些Spark应用场景需要频繁聚合数据,而数据key又少的,那么我们可以把这些存量数据先用hive算好(每天算一次),然后落到中间表,后续Spark应用直接用聚合好的表+新的数据进行二度聚合,效率会有很高的提升。
Plan C: 调高shuffle并行度
讯享网# 针对Spark SQL --conf spark.sql.shuffle.partitions=1000 # 在配置信息中设置参数 # 针对RDD rdd.reduceByKey(1000) # 默认是200
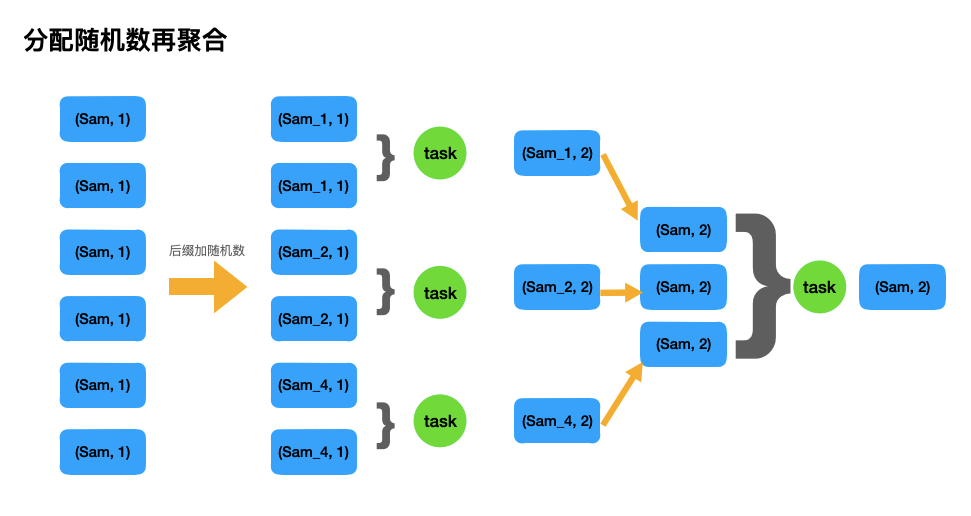
Plan D: 分配随机数再聚合
大概的思路就是对一些大量出现的key,人工打散,从而可以利用多个task来增加任务并行度,以达到效率提升的目的,下面是代码demo,分别从RDD 和 SparkSQL来实现。
# Way1: PySpark RDD实现 import pyspark from pyspark import SparkContext, SparkConf, HiveContext from random import randint import pandas as pd # SparkSQL的许多功能封装在SparkSession的方法接口中, SparkContext则不行的。 from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName("sam_SamShare") \ .config("master", "local[4]") \ .enableHiveSupport() \ .getOrCreate() conf = SparkConf().setAppName("test_SamShare").setMaster("local[4]") sc = SparkContext(conf=conf) hc = HiveContext(sc) # 分配随机数再聚合 rdd1 = sc.parallelize([('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1), ('sam', 1)]) # 给key分配随机数后缀 rdd2 = rdd1.map(lambda x: (x[0] + "_" + str(randint(1,5)), x[1])) print(rdd.take(10)) # [('sam_5', 1), ('sam_5', 1), ('sam_3', 1), ('sam_5', 1), ('sam_5', 1), ('sam_3', 1)] # 局部聚合 rdd3 = rdd2.reduceByKey(lambda x,y : (x+y)) print(rdd3.take(10)) # [('sam_5', 4), ('sam_3', 2)] # 去除后缀 rdd4 = rdd3.map(lambda x: (x[0][:-2], x[1])) print(rdd4.take(10)) # [('sam', 4), ('sam', 2)] # 全局聚合 rdd5 = rdd4.reduceByKey(lambda x,y : (x+y)) print(rdd5.take(10)) # [('sam', 6)] # Way2: PySpark SparkSQL实现 df = pd.DataFrame(5*[['Sam', 1],['Flora', 1]], columns=['name', 'nums']) Spark_df = spark.createDataFrame(df) print(Spark_df.show(10)) Spark_df.createOrReplaceTempView("tmp_table") # 注册为视图供SparkSQl使用 sql = """ with t1 as ( select concat(name,"_",int(10*rand())) as new_name, name, nums from tmp_table ), t2 as ( select new_name, sum(nums) as n from t1 group by new_name ), t3 as ( select substr(new_name,0,length(new_name) -2) as name, sum(n) as nums_sum from t2 group by substr(new_name,0,length(new_name) -2) ) select * from t3 """ tt = hc.sql(sql).toPandas() tt 下面是原理图。
全文终!
????学习资源推荐
1)edureka about PySpark Tutorial
印度老哥的课程,B站可直接看,不过口音略难听懂不过还好有字幕。
https://www.bilibili.com/video/BV1i4411i79a?p=1
2)eat_pyspark_in_10_days
梁云大哥的课程,讲得超级清晰,建议精读。
https://github.com/lyhue1991/eat_pyspark_in_10_days
3)官方文档
http://spark.apache.org/docs/latest/api/python/reference/index.html
4)《Spark性能优化指南——基础篇》
https://tech.meituan.com/2016/04/29/spark-tuning-basic.html
5)《Spark性能优化指南——高级篇》
https://tech.meituan.com/2016/05/12/spark-tuning-pro.html
---------End---------

精选资料
回复关键词,获取对应的资料:
| 关键词 | 资料名称 |
|---|---|
| 600 | 《Python知识手册》 |
| md | 《Markdown速查表》 |
| time | 《Python时间使用指南》 |
| str | 《Python字符串速查表》 |
| pip | 《Python:Pip速查表》 |
| style | 《Pandas表格样式配置指南》 |
| mat | 《Matplotlib入门100个案例》 |
| px | 《Plotly Express可视化指南》 |
精选内容
- 神器 VS Code,超详细Python配置使用指南
- 神器Tushare,财经数据必备工具!
- Matplotlib 可视化最有价值的 50 个图表
- 视频:Plotly 和 Dash 在投资领域的应用

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/58053.html