
一、什么是广义表
1、定义
广义表又称列表,也是一种线性存储结构,通数组类似,广义表中即可存储不可再分的元素也能存储可在分元素。
例如:数组中可以存储‘a’、3这样的字符或数字,也能存储数组,比如二维数组、三维数组,数组都是可在分成子元素的。广义表也是如此,但与数组不同的是,在广义表中存储的数据是既可以再分也可以不再分的,形如:{1,{1,2,3}}。
如果创建一个二维数组来存储{1,{1,2,3}}。在存储上确实可以实现,但无疑会造成存储空间的浪费。
广义表记作:
LS = (a1,a2,…,an)
其中,LS 代表广义表的名称,an 表示广义表存储的数据。广义表中每个 ai 既可以代表单个元素,也可以代表另一个广义表。
2、原子和子表
广义表中存储的单个元素称为 "原子",而存储的广义表称为 "子表"。
例如创建一个广义表 LS = {1,{1,2,3}},我们可以这样解释此广义表的构成:广义表 LS 存储了一个原子 1 和子表 {1,2,3}。
以下是广义表存储数据的一些常用形式:
- A = ():A 表示一个广义表,只不过表是空的。
- B = (e):广义表 B 中只有一个原子 e。
- C = (a,(b,c,d)) :广义表 C 中有两个元素,原子 a 和子表 (b,c,d)。
- D = (A,B,C):广义表 D 中存有 3 个子表,分别是A、B和C。这种表示方式等同于 D = ((),(e),(b,c,d)) 。
- E = (a,E):广义表 E 中有两个元素,原子 a 和它本身。这是一个递归广义表,等同于:E = (a,(a,(a,…)))。
3、表头和表尾
当广义表不是空表时,称第一个数据(原子或子表)为"表头",剩下的数据构成的新广义表为"表尾"。
强调一下,除非广义表为空表,否则广义表一定具有表头和表尾,且广义表的表尾一定是一个广义表。
例如在广义表中 LS={1,{1,2,3},5} 中,表头为原子 1,表尾为子表 {1,2,3} 和原子 5 构成的广义表,即 { {1,2,3},5}。
再比如,在广义表 LS = {1} 中,表头为原子 1 ,但由于广义表中无表尾元素,因此该表的表尾是一个空表,用 {} 表示。
二、广义表的存储结构
由于中既可存储原子(不可再分的数据元素),也可以存储子表,因此很难使用顺序存储结构表示,通常情况下广义表结构采用链表实现。
使用顺序表实现广义表结构,不仅需要操作 n 维数组(例如 {1,{2,{3,4}}} 就需要使用三维数组存储),还会造成存储空间的浪费。
使用链表存储广义表,首先需要确定链表中节点的结构。由于广义表中可同时存储原子和子表两种形式的数据,因此链表节点的结构也有两种,如图 1 所示:

图 1 广义表节点的两种类型
如图 1 所示,表示原子的节点由两部分构成,分别是 tag 标记位和原子的值,表示子表的节点由三部分构成,分别是 tag 标记位、hp 指针和 tp 指针。
tag 标记位用于区分此节点是原子还是子表,通常原子的 tag 值为 0,子表的 tag 值为 1。子表节点中的 hp 指针用于连接本子表中存储的原子或子表,tp 指针用于连接广义表中下一个原子或子表。
因此,广义表中两种节点的 C 语言表示代码为:
typedef struct GLNode{ int tag;//标志域 union{ char atom;//原子结点的值域 struct{ struct GLNode * hp,*tp; }ptr;//子表结点的指针域,hp指向表头;tp指向表尾 }subNode; }*Glist;讯享网
这里用到了 union 共用体,因为同一时间此节点不是原子节点就是子表节点,当表示原子节点时,就使用 atom 变量;反之则使用 ptr 结构体。
例如,广义表 {a,{b,c,d}} 是由一个原子 a 和子表 {b,c,d} 构成,而子表 {b,c,d} 又是由原子 b、c 和 d 构成,用链表存储该广义表如图 2 所示:
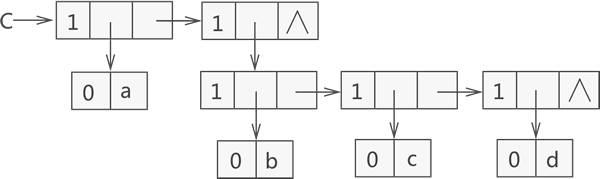
图 2 可以看到,存储原子 a、b、c、d 时都是用子表包裹着表示的,因为原子 a 和子表 {b,c,d} 在广义表中同属一级,而原子 b、c、d 也同属一级。
图 2 中链表存储的广义表用 C 语言代码表示为:
讯享网Glist creatGlist(Glist C) { //广义表C C = (Glist)malloc(sizeof(Glist)); C->tag = 1; //表头原子‘a’ C->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.hp->tag = 0; C->subNode.ptr.hp->subNode.atom = 'a'; //表尾子表(b,c,d),是一个整体 C->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.tp = NULL; //开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d) C->subNode.ptr.tp->subNode.ptr.hp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->subNode.atom = 'b'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); //存放子表(c,d),表头为c,表尾为d C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'c'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); //存放表尾d C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'd'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.tp = NULL; return C; }
另一种储存结构:
如果你觉得图 2 这种存储广义表的方式不合理,可以使用另一套表示广义表中原子和子表结构的节点,如图 3 所示:
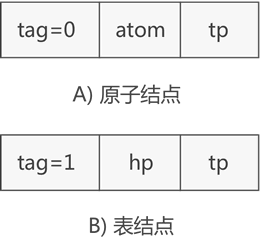
图 3 广义表的另一套节点结构
如图 3 所示,表示原子的节点构成由 tag 标记位、原子值和 tp 指针构成,表示子表的节点还是由 tag 标记位、hp 指针和 tp 指针构成。
图 3 的节点结构用 C 语言代码表示为:
typedef struct GNode { int tag;//标志域 union { int atom;//原子结点的值域 struct GNode* hp;//子表结点的指针域,hp指向表头 }subNode; struct GNode* tp;//这里的tp相当于链表的next指针,用于指向下一个数据元素 }GLNode, *Glist;采用图 3 中的节点结构存储广义表 {a,{b,c,d}} 的示意图如图 4 所示:


图 4 广义表 {a,{b,c,d}} 的存储结构示意图
图 4 存储广义表对应的 C 语言代码为:
讯享网Glist creatGlist(Glist C) { C = (Glist)malloc(sizeof(GLNode)); C->tag = 1; C->subNode.hp = (Glist)malloc(sizeof(GLNode)); C->tp = NULL; //表头原子a C->subNode.hp->tag = 0; C->subNode.hp->subNode.atom = 'a'; C->subNode.hp->tp = (Glist)malloc(sizeof(GLNode)); C->subNode.hp->tp->tag = 1; C->subNode.hp->tp->subNode.hp = (Glist)malloc(sizeof(GLNode)); C->subNode.hp->tp->tp = NULL; //原子b C->subNode.hp->tp->subNode.hp->tag = 0; C->subNode.hp->tp->subNode.hp->subNode.atom = 'b'; C->subNode.hp->tp->subNode.hp->tp = (Glist)malloc(sizeof(GLNode)); //原子c C->subNode.hp->tp->subNode.hp->tp->tag = 0; C->subNode.hp->tp->subNode.hp->tp->subNode.atom = 'c'; C->subNode.hp->tp->subNode.hp->tp->tp = (Glist)malloc(sizeof(GLNode)); //原子d C->subNode.hp->tp->subNode.hp->tp->tp->tag = 0; C->subNode.hp->tp->subNode.hp->tp->tp->subNode.atom = 'd'; C->subNode.hp->tp->subNode.hp->tp->tp->tp = NULL; return C; }
需要注意的是,无论采用以上哪一种节点结构存储广义表,都不要破坏广义表中各数据元素之间的并列关系。拿 {a,{b,c,d}} 来说,原子 a 和子表 {b,c,d} 是并列的,而在子表 {b,c,d} 中原子 b、c、d 是并列的。
三、广义表的长度和深度
1、广义表的长度
广义表的长度,指的是广义表中所包含的数据元素的个数。
由于广义表中可以同时存储原子和子表两种类型的数据,因此在计算广义表的长度时规定,广义表中存储的每个原子算作一个数据,同样每个子表也只算作是一个数据。
例如,在广义表 {a,{b,c,d}} 中,它包含一个原子和一个子表,因此该广义表的长度为 2。
再比如,广义表 { {a,b,c}} 中只有一个子表 {a,b,c},因此它的长度为 1。
前面我们用 LS={a1,a2,...,an} 来表示一个广义表,其中每个 ai 都可用来表示一个原子或子表,其实它还可以表示广义表 LS 的长度为 n。广义表规定,空表 {} 的长度为 0。
在编程实现求广义表长度时,由于广义表的存储使用的是链表结构,且有以下两种方式(如图 1 所示):
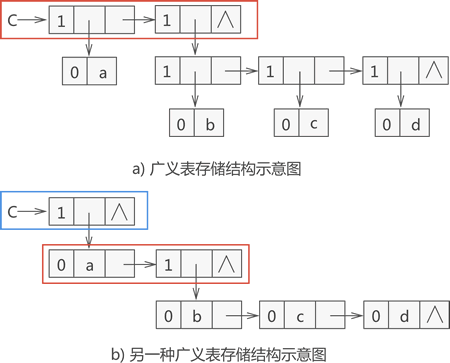
图 1 存储 {a,{b,c,d}} 的两种方式
对于图 1a) 来说,只需计算最顶层(红色标注)含有的节点数量,即可求的广义表的长度。
同理,对于图 1b) 来说,由于其最顶层(蓝色标注)表示的此广义表,而第二层(红色标注)表示的才是该广义表中包含的数据元素,因此可以通过计算第二层中包含的节点数量,即可求得广义表的长度。
由于两种算法的实现非常简单,这里只给出计算图 1a) 中广义表长度的 C 语言实现代码:
#include<stdio.h> #include<stdlib.h> typedef struct GLNode { int tag;//标志域 union { char atom;//原子结点的值域 struct { struct GLNode* hp, * tp; }ptr;//子表结点的指针域,hp指向表头;tp指向表尾 }subNode; }*Glist; Glist creatGlist(Glist C) { //广义表C C = (Glist)malloc(sizeof(Glist)); C->tag = 1; //表头原子‘a’ C->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.hp->tag = 0; C->subNode.ptr.hp->subNode.atom = 'a'; //表尾子表(b,c,d),是一个整体 C->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.tp = NULL; //开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d) C->subNode.ptr.tp->subNode.ptr.hp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->subNode.atom = 'b'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); //存放子表(c,d),表头为c,表尾为d C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'c'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); //存放表尾d C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'd'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.tp = NULL; return C; } int GlistLength(Glist C) { int Number = 0; Glist P = C; while (P) { Number++; P = P->subNode.ptr.tp; } return Number; } int main() { Glist C = NULL; C = creatGlist(C); printf("广义表的长度为:%d", GlistLength(C)); }2、广义表的深度
广义表的深度,可以通过观察该表中所包含括号的层数间接得到。
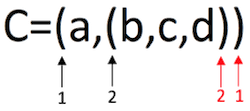
从图 2 中可以看到,此广义表从左往右数有两层左括号(从右往左数也是如此),因此该广义表的深度为 2。
再比如,广义表 {
{1,2},{3,{4,5}}} 中,子表 {1,2} 和 {3,{4,5}} 位于同层,此广义表中包含 3 层括号,因此深度为 3。以上观察括号的方法需将广义表当做字符串看待,并借助栈存储结构实现,这里不做重点介绍。
编写程序计算广义表的深度时,以图 1a) 中的广义表为例,可以采用递归的方式:
- 依次遍历广义表 C 的每个节点,若当前节点为原子(tag 值为 0),则返回 0;若为空表,则返回 1;反之,则继续遍历该子表中的数据元素。
- 设置一个初始值为 0 的整形变量 max,每次递归过程返回时,令 max 与返回值进行比较,并取较大值。这样,当整个广义表递归结束时,max+1 就是广义表的深度。
其实,每次递归返回的值都是当前所在的子表的深度,原子默认深度为 0,空表默认深度为 1。
C 语言实现代码如下:
讯享网#include <stdio.h> #include <stdlib.h> typedef struct GLNode { int tag;//标志域 union { char atom;//原子结点的值域 struct { struct GLNode* hp, * tp; }ptr;//子表结点的指针域,hp指向表头;tp指向表尾 }subNode; }*Glist, GNode; Glist creatGlist(Glist C) { //广义表C C = (Glist)malloc(sizeof(Glist)); C->tag = 1; //表头原子‘a’ C->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.hp->tag = 0; C->subNode.ptr.hp->subNode.atom = 'a'; //表尾子表(b,c,d),是一个整体 C->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.tp = NULL; //开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d) C->subNode.ptr.tp->subNode.ptr.hp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->subNode.atom = 'b'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); //存放子表(c,d),表头为c,表尾为d C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'c'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist)); //存放表尾d C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->tag = 1; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist)); C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->tag = 0; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'd'; C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.tp = NULL; return C; } int GlistDepth(Glist C) { //如果表C为空表时,直接返回长度1; if (!C) { return 1; } //如果表C为原子时,直接返回0; if (C->tag == 0) { return 0; } int max = 0;//设置表C的初始长度为0; for (Glist pp = C; pp; pp = pp->subNode.ptr.tp) { int dep = GlistDepth(pp->subNode.ptr.hp); if (dep > max) { max = dep;//每次找到表中遍历到深度最大的表,并用max记录 } } //程序运行至此处,表明广义表不是空表,由于原子返回的是0,而实际长度是1,所以,此处要+1; return max + 1; } int main(int argc, const char* argv[]) { Glist C = NULL; C = creatGlist(C); printf("广义表的深度为:%d", GlistDepth(C)); return 0; }
四、广义表的复制
对于任意一个非空广义表来说,都是由两部分组成:表头和表尾。反之,只要确定的一个广义表的表头和表尾,那么这个广义表就可以唯一确定下来。
复制一个广义表,也是不断的复制表头和表尾的过程。如果表头或者表尾同样是一个广义表,依旧复制其表头和表尾。
所以,复制广义表的过程,其实就是不断的递归,复制广义表中表头和表尾的过程。
递归的出口有两个:
- 如果当前遍历的数据元素为空表,则直接返回空表。
- 如果当前遍历的数据元素为该表的一个原子,那么直接复制,返回即可。
还拿广义表 C 为例:
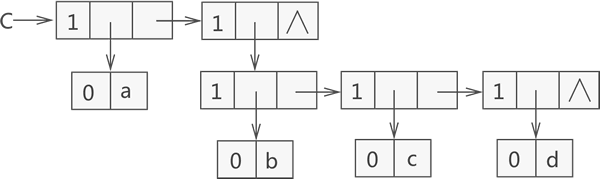
图1 广义表 C 的结构示意图
代码实现:
#include <stdio.h> #include <stdlib.h> typedef struct GLNode{ int tag;//标志域 union{ char atom;//原子结点的值域 struct{ struct GLNode * hp,*tp; }ptr;//子表结点的指针域,hp指向表头;tp指向表尾 }; }*Glist,GNode; Glist creatGlist(Glist C){ //广义表C C=(Glist)malloc(sizeof(GNode)); C->tag=1; //表头原子‘a’ C->ptr.hp=(Glist)malloc(sizeof(GNode)); C->ptr.hp->tag=0; C->ptr.hp->atom='a'; //表尾子表(b,c,d),是一个整体 C->ptr.tp=(Glist)malloc(sizeof(GNode)); C->ptr.tp->tag=1; C->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode)); C->ptr.tp->ptr.tp=NULL; //开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d) C->ptr.tp->ptr.hp->tag=1; C->ptr.tp->ptr.hp->ptr.hp=(Glist)malloc(sizeof(GNode)); C->ptr.tp->ptr.hp->ptr.hp->tag=0; C->ptr.tp->ptr.hp->ptr.hp->atom='b'; C->ptr.tp->ptr.hp->ptr.tp=(Glist)malloc(sizeof(GNode)); //存放子表(c,d),表头为c,表尾为d C->ptr.tp->ptr.hp->ptr.tp->tag=1; C->ptr.tp->ptr.hp->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode)); C->ptr.tp->ptr.hp->ptr.tp->ptr.hp->tag=0; C->ptr.tp->ptr.hp->ptr.tp->ptr.hp->atom='c'; C->ptr.tp->ptr.hp->ptr.tp->ptr.tp=(Glist)malloc(sizeof(GNode)); //存放表尾d C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->tag=1; C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode)); C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp->tag=0; C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp->atom='d'; C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.tp=NULL; return C; } void copyGlist(Glist C, Glist *T){ //如果C为空表,那么复制表直接为空表 if (!C) { *T=NULL; } else{ *T=(Glist)malloc(sizeof(GNode));//C不是空表,给T申请内存空间 //申请失败,程序停止 if (!*T) { exit(0); } (*T)->tag=C->tag;//复制表C的tag值 //判断当前表元素是否为原子,如果是,直接复制 if (C->tag==0) { (*T)->atom=C->atom; }else{//运行到这,说明复制的是子表 copyGlist(C->ptr.hp, &((*T)->ptr.hp));//复制表头 copyGlist(C->ptr.tp, &((*T)->ptr.tp));//复制表尾 } } } int main(int argc, const char * argv[]) { Glist C=NULL; C=creatGlist(C); Glist T=NULL; copyGlist(C,&T); printf("%c",T->ptr.hp->atom); return 0; }在实现复制广义表的过程中,实现函数为:
void copyGlist(Glist C, Glist *T);
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/58051.html