
导读
唇语识别有着极长的历史。古代的唇语师通过长期的训练,具备了“观察别人的嘴型,解读其表达语句”的能力。在现代社会里,一些听力障碍者们也会使用这种技巧与他人交谈,补充听力器官的不足。
讯享网


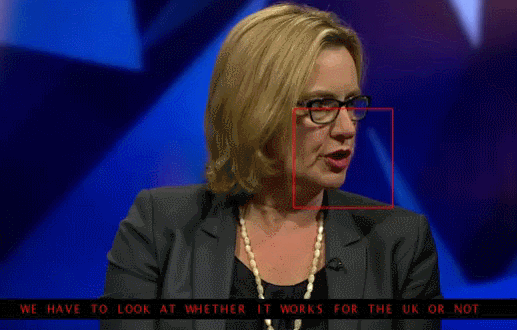
本期将将以Amirsina Torfi 等人实现的使用 3D 卷积神经网络的交叉视听识别技术为引,介绍唇语识别技术。
唇语识别
唇语识别/Lip ReadingGithub:github.com/astorfi/lip-reading-deeplearning
软件地址:暂无项目基于用于交叉视听匹配识别的3D卷积神经网络实现。模型结构如下图。模型具有以下四个特点:

- 输入是音频和视频,输出是他们是否匹配
- 标签是音频视频是否是一样的
- 衡量音频视频3D卷积后的低维映射之间的欧氏距离
- 两个重要的手段去掉多余数据
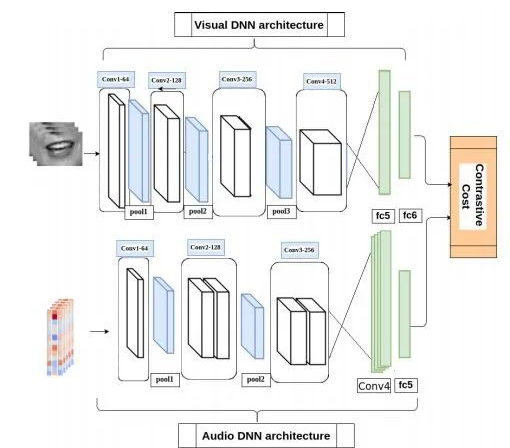
AVR 系统的方法是利用从某种模态中提取的信息,通过填补缺失的信息来提高另一种模态的识别能力。
这篇文章提出了利用耦合的三维卷积神经网络(CNN)架构,该架构可以将两种模态映射到表示空间,以使用学习到的多模态特征来评估音频 - 视频流的对应关系。
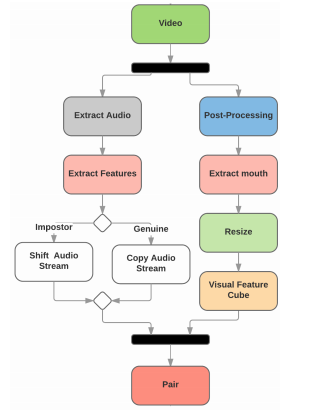
代码实现
输入管道必须由用户提供。其余实现将考虑包含基于话语的提取特征的数据集。 ▌唇语识别对于嘴唇跟踪,必须将所需的视频作为输入。首先,将cd转到相应的目录:cd code/lip_tracking讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/57305.html