
ResNeXt就是一种典型的混合模型,由基础的Inception+ResNet组合而成,本质在gruops分组卷积,核心创新点就是用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
关于论文更详细的解读可以看我上一篇笔记:经典神经网络论文超详细解读(八)——ResNeXt学习笔记(翻译+精读+代码复现)
接下来我们进行代码的复现
一、ResNeXt Block 结构
1.1 基础结构
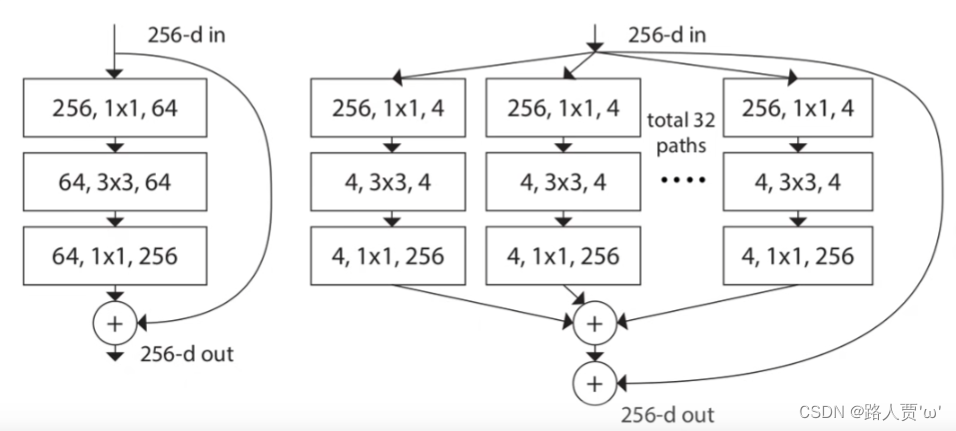
ResNeXt是ResNet基础上的改进版本,改进的部分不多,主要将之前的残差结构换成了另外的一个Block结构,并且使用了组卷积的概念。下图是ResNeXt的一个基础Block。
左图是其基础结构,灵感来自于ResNet的BottleNeck(关于ResNet代码的详细讲解,大家可以看我之前的文章:ResNet代码复现+超详细注释(PyTorch))。受Inception启发论文将Residual部分分成若干个支路,这个支路的数量就是cardinality的含义(Inception代码详细讲解可参考:GoogLeNet InceptionV1代码复现+超详细注释(PyTorch))。
右图是ResNeXt提出的一个组卷积的概念:将输入通道为256的数据通过1*1卷积压缩成大小为4的32组,合起来也就是128通道,然后进行卷积操作后,再用1*1卷积扩充回32组256通道,将32组数据按对应位置相加合成一个256通道的输出。
1.2 三种等效的优化结构
(a)表示先划分,单独卷积并计算输出,最后输出相加。split-transform-merge三阶段形式
(b)表示先划分,单独卷积,然后拼接再计算输出。将各分支的最后一个1×1卷积聚合成一个卷积。
(c)就是分组卷积。将各分支的第一个1×1卷积融合成一个卷积,3×3卷积采用group(分组)卷积的形式,分组数=cardinality(基数) 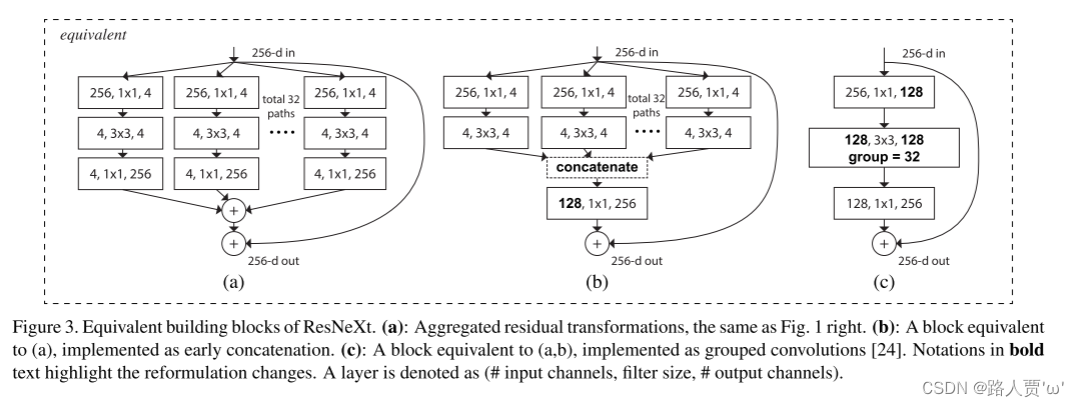

以上三个Block模块在数学计算上是完全等价的。
以(c)为例:通过1×1的卷积层将输入channel从256降为128,然后利用组卷积进行处理,卷积核大小为3×3组数为32,再利用1×1的卷积层进行升维,将输出与输入相加,得到最终输出。
再看(b)模块,就是将第一层和第二层的卷积分组,将第一层卷积(卷积核大小为1×1,每个卷积核有256层)分为32组,每组4个卷积核,这样每一组输出的channel为4;将第二层卷积也分为32组对应第一层,每一组输入的channel为4,每一组4个卷积核输出channel也为4,再将输出拼接为channel为128的输出,再经过一个256个卷积核的卷积层得到最终输出。
对于(a)模块,就是对b模块的最后一层进行拆分,就是将第二层的32组的输出再经过一层(卷积核大小为1×1,每个卷积核有4层,一共有256个卷积核)卷积,再把这32组输出相加得到最终输出。
二、ResNeXt 网络结构
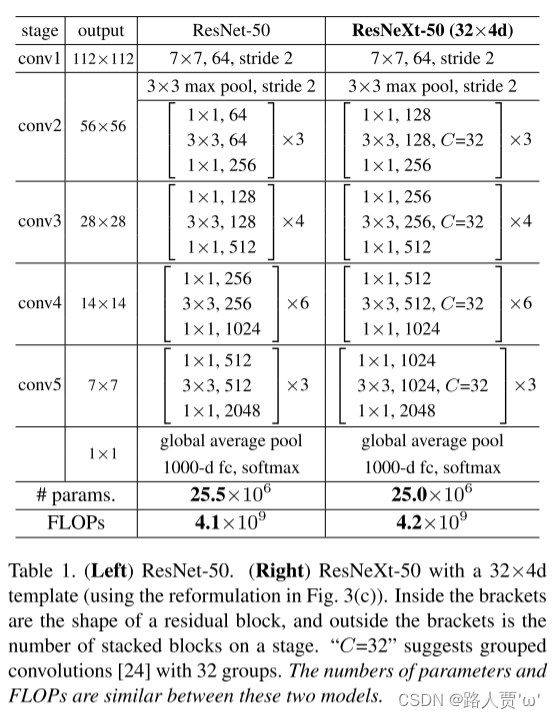
下图是ResNet-50和ResNeXt-50(32x4d)的对比,可以发现二者网络整体结构一致,ResNeXt替换了基本的block。32 指进入网络的第一个ResNeXt基本结构的分组数量C(即基数)为32。4d 表示depth即每一个分组的通道数为4(所以第一个基本结构输入通道数为128)
模型设计两个原则:
(1)如果输出的空间尺寸一样,那么模块的超参数(宽度和卷积核尺寸)也是一样的。
(2)每当空间分辨率/2(降采样),则卷积核的宽度*2。这样保持模块计算复杂度。
三、ResNeXt的PyTorch实现
3.1BasicBlock模块
基础Block模块,也就是对应18/34层的BasicBlock。这里实现和ResNet一样,就不再过多论述。
代码
'''-------------一、BasicBlock模块-----------------------------''' # 用于ResNet18和ResNet34基本残差结构块 class BasicBlock(nn.Module): def __init__(self, in_channel, out_channel, stride=1, downsample=None): super(BasicBlock, self).__init__() self.left = nn.Sequential( nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(out_channel), nn.ReLU(), nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(out_channel), nn.downsample(downsample) ) def forward(self, x): identity = x if self.downsample is not None: identity = self.downsample(x) out = self.left(x) # 这是由于残差块需要保留原始输入 out += identity # 这是ResNet的核心,在输出上叠加了输入x out = F.relu(out) return out讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/56527.html