
一、python爬虫程序requests采用get和post方式
#! python# -*- coding: utf-8 -*-from urllib.request import urlopenurl = "https://www.hao123.com/"if __name__ == '__main__':resp = urlopen(url)# 把读取到网页的页面源代码写入myGetFile.html文件with open("myGetFile.html", mode="w", encoding='utf-8') as f:f.write(resp.read().decode('utf-8'))f.close() # 关闭文件resp.close() # 关闭resp响应print("结束")
讯享网
讯享网# -*- coding: utf-8 -*-import requestsif __name__ == '__main__':query = input("请输入一个你喜欢的明星:")url = f"https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&srcqid=0&tn=_hao_pg&wd={query}"dic = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47"}resp = requests.get(url, headers=dic) # 处理一个小小的反爬# print(resp)# print(resp.text) # 打印读取到的网页的页面源代码# 把读取到网页的页面源代码写入myGetFile.html文件with open("myGetFile.html", mode="w", encoding='utf-8') as f:f.write(resp.text) # 读取到网页的页面源代码f.close() # 关闭文件resp.close() # 关闭resp响应连接print("结束")
# -*- coding: utf-8 -*-import requestsif __name__ == '__main__':url = "https://fanyi.baidu.com/sug"s = input("请输入你要翻译的英文单词:")# 要翻译的英文单词dat = {"kw": s}# 用户代理dicHeaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47"}# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递resp = requests.post(url, headers=dicHeaders, data=dat)# print(resp.text)# 将服务器返回的内容直接处理成json(),就是字典格式print(resp.json())resp.close() # 关闭resp响应连接print("结束")
讯享网# -*- coding: utf-8 -*-import requestsif __name__ == '__main__':url = "https://movie.douban.com/j/chart/top_list"# 参数dicParam = {"type": "24","interval_id": "100:90","action": "","start": "0","limit": "20"}# 用户代理dicHeaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47"}# 发送get请求,发送的数据必须放在字典中,通过params参数进行传递resp = requests.get(url=url, params=dicParam, headers=dicHeaders) # 处理小小的反爬# print(resp.text)# 将服务器返回的内容直接处理成json(),就是字典格式# print(resp.json())objData = resp.json()# 打印信息for i in range(0, len(objData)):print(objData[i])resp.close() # 关闭resp响应连接print("结束")
# -*- coding: utf-8 -*-import requestsif __name__ == '__main__':url = "https://movie.douban.com/j/chart/top_list"# 进行连续2轮获取数据,每轮20个数据for n in range(0, 2):# 参数dicParam = {"type": "24","interval_id": "100:90","action": "","start": f"{20*n}","limit": "20"}# 用户代理dicHeaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47"}# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递resp = requests.get(url=url, params=dicParam, headers=dicHeaders) # 处理小小的反爬# print(resp.text)# 将服务器返回的内容直接处理成json(),就是字典格式# print(resp.json())objData = resp.json()print(f"第{n+1}轮20个数据:")# 打印信息for i in range(0, len(objData)):print(objData[i])resp.close() # 关闭resp响应连接print("结束")
二、python爬虫 正则表达式 re.finditer 元字符 贪婪匹配 惰性匹配
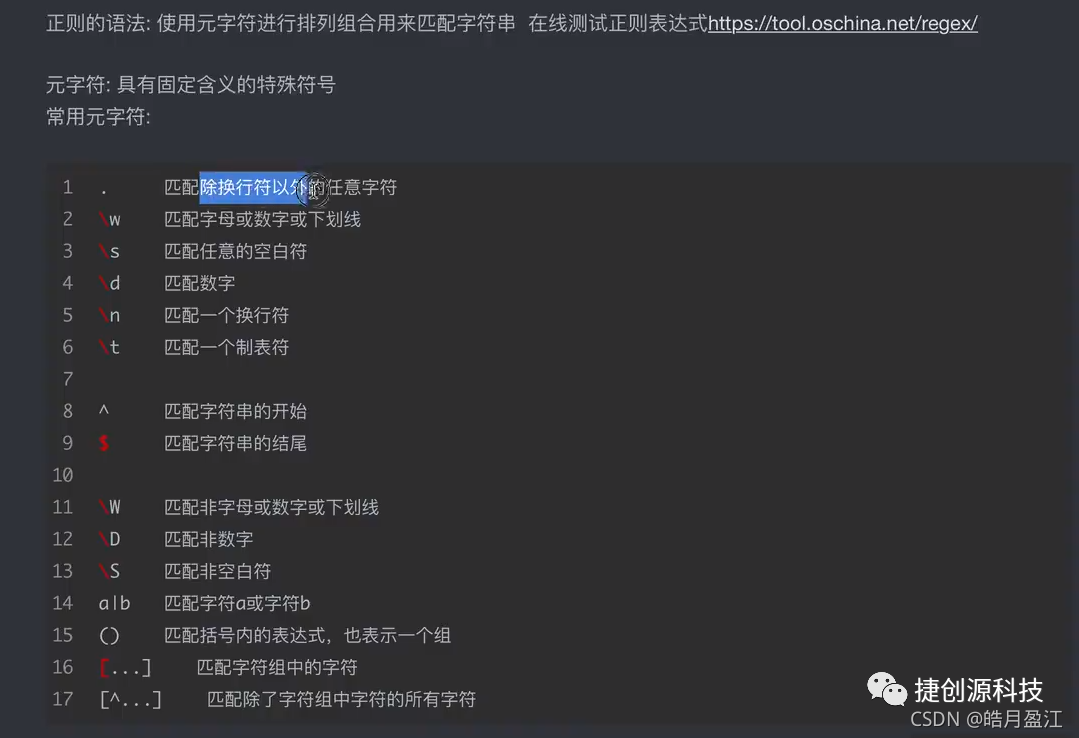
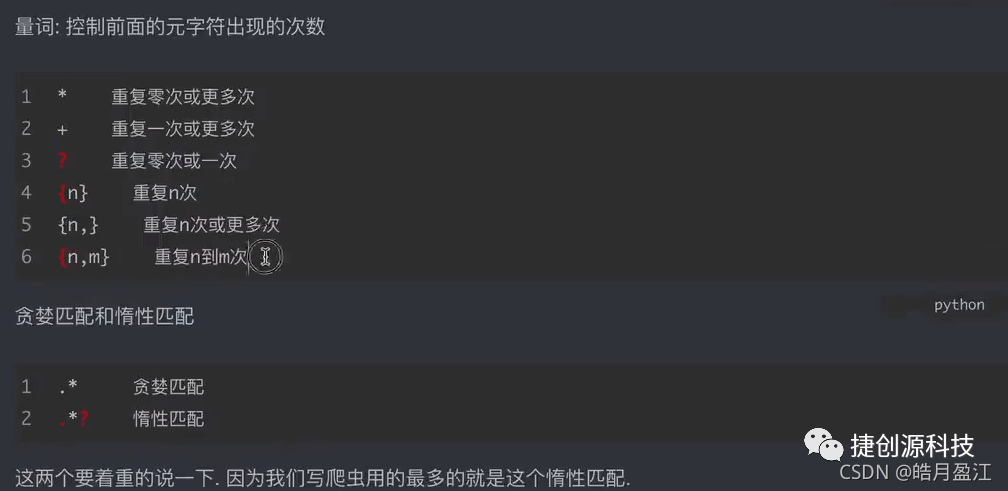


讯享网# -*- coding: utf-8 -*-import reif __name__ == '__main__':# findall匹配字符串中所有的符合正则的内容lst = re.findall(r"\d+", "濮阳电话区号:0393,郑州电话区号:0371")print(lst)# 【推荐】finditer匹配字符串中所有的内容[返回的是迭代器],从迭代器中拿到内容需要.group()it = re.finditer(r"\d+", "濮阳电话区号:0393,郑州电话区号:0371")for i in it:print(i.group())# search,找到一个结果就返回,返回的结果是match对象,拿到数据需要.group()s = re.search(r"\d+", "濮阳电话区号:0393,郑州电话区号:0371")print(s.group())# match,从头开始匹配s = re.match(r"\d+", "0393,郑州电话区号:0371")print(s.group())# 【推荐】finditer匹配字符串中所有的内容[返回的是迭代器],从迭代器中拿到内容需要.group()# 预加载正则表达式obj = re.compile(r"\d+")it = obj.finditer("濮阳电话区号:0393,郑州电话区号:0371")for i in it:print(i.group())测试代码2:python爬虫很常用的从网页提取数据例子 main7.py
# -*- coding: utf-8 -*-import reif __name__ == '__main__':s = """<div class= 'tom'><span id= '1'>汤姆</span></div><div class= 'kali'><span id= '2'>凯丽</span></div><div class= 'lnr'><span id= '3'>罗恩</span></div>"""# 【推荐】finditer匹配字符串中所有的内容[返回的是迭代器],从迭代器中拿到内容需要.group()# 预加载正则表达式,(?P<分组名称>正则表达式)可以单独从正则匹配的内容中进一步提取内容,标志处添加re.S是让.匹配换行符,即匹配任意字符。obj = re.compile(r"<div class= '(?P<class>.*?)'><span id= '(?P<id>\d)'>(?P<name>.*?)</span></div>", re.S)result = obj.finditer(s)for i in result:print(i.group("class")+" "+i.group("id")+" "+i.group("name"))
效果:
讯享网tom 1 汤姆kali 2 凯丽lnr 3 罗恩
Python经验分享
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
Python学习路线
这里把Python常用的技术点做了整理,有各个领域的知识点汇总,可以按照上面的知识点找对应的学习资源。
学习软件
Python常用的开发软件,会给大家节省很多时间。
学习视频
编程学习一定要多多看视频,书籍和视频结合起来学习才能事半功倍。
100道练习题

实战案例
光学理论是没用的,学习编程切忌纸上谈兵,一定要动手实操,将自己学到的知识运用到实际当中。
最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/49977.html