
目录
1.安装
1.下载
2.解压
3.配置
4.切换zeppelin用户并启动Zeppelin
5.访问
2.集成spark
1.进入拦截器
2.搜索spark相关配置
3.修改spark相关配置
4. 重启
3.集成trino
1.新增拦截器
2.设置属性
3.添加jdbc包
4.重启
4.用户管理
1.添加管理员用户和普通用户
2.使用jdbc控制用户登录
1.配置shiro.ini
2.导入驱动包
3.新建库表
3.重启
5.迁移note
6.构建
1.安装
1.下载
进入到官网http://zeppelin.apache.org/,手动下载或者通过命令方式下载
如果下载慢,可以通过迅雷下载
wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.0/zeppelin-0.10.0-bin-all.tgz 讯享网
2.解压
讯享网tar -xzvf zeppelin-0.10.0-bin-all.tgz -C /usr/local
3.配置
进入到conf目录
cp zeppelin-env.sh.template zeppelin-env.sh cp zeppelin-site.xml.template zeppelin-site.xml vim zeppelin-env.sh //配置JAVA_HOME地址,如果JAVA_HOME已经在系统变量中设置过了则不用再设置 vim zeppelin-site.xml //改zeppelin.server.addr中的value为0.0.0.0和zeppelin端口号为8999(避免和其他端口冲突) //创建zeppelin并将用户的组改为hadoop useradd zeppelin -g hadoop //将zeppelin安装目录拥有者改为zeppelin,组的改为hadoop chown zeppelin -R zeppelin-0.10.0-bin-all chgrp hadoop -R zeppelin-0.10.0-bin-all4.切换zeppelin用户并启动Zeppelin
讯享网su zeppelin bin/zeppelin-daemon.sh start
此时可以通过jps命令看到ZeppelinServer进程
5.访问
http://ip:8999
2.集成spark
1.进入拦截器
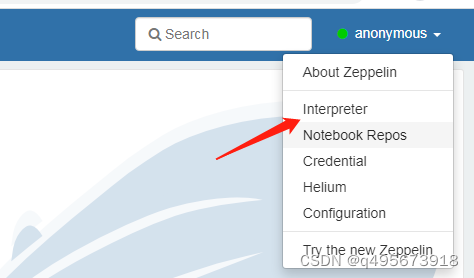
2.搜索spark相关配置

3.修改spark相关配置
指定spark_home,模式,启动用户等
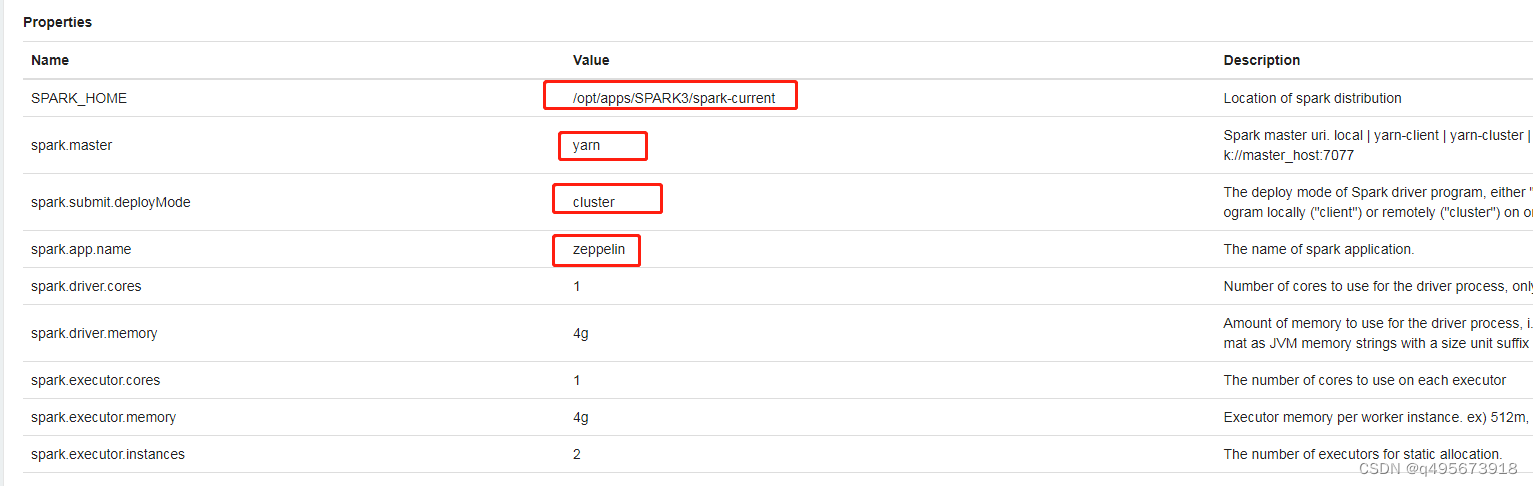
也可以添加属性spark.yarn.queue,设置使用队列

设置不以登录用户提交任务用户,这样就是已启动zeppelin的用户提交任务

设置spark使用的udf函数

如果spark版本不一致,需要将版本校验去掉zeppelin.spark.enableSupportedVersionCheck设为false,例如使用的spark3.3.1但是zeppelin版本是0.10.1的版本,虽然从zeppelin0.10.1开始默认使用的是spark3的版本,但是默认使用的版本还是低于3.3.1,如果要想匹配spark版本也可以自己下源码编译打包
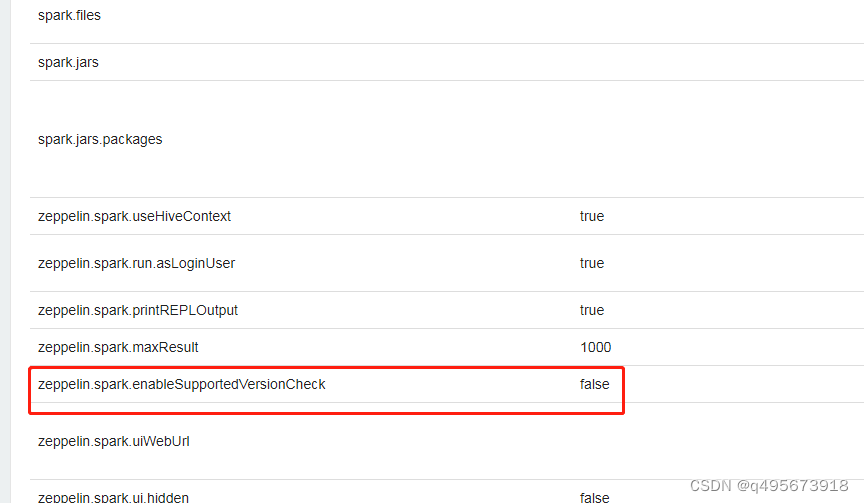
4. 重启

并重启zeppelin
su zeppelin bin/zeppelin-daemon.sh start 3.集成trino
1.新增拦截器
拦截器名字为trino,group设置为jdbc

2.设置属性
添加url和driver,用户名可以随便填,trino默认没有启动用户校验

3.添加jdbc包
进入interpreter/jdbc目录
上传trino-jdbc-359.jar包,版本可以自己选
4.重启

讯享网su zeppelin bin/zeppelin-daemon.sh start
如果再查询未找到url错误,则可以自己编译trino-jdbc-359.jar包,删除url相关的校验再上传试试
4.用户管理
1.添加管理员用户和普通用户
cd conf cp shiro.ini.template shiro.ini vim shiro.ini 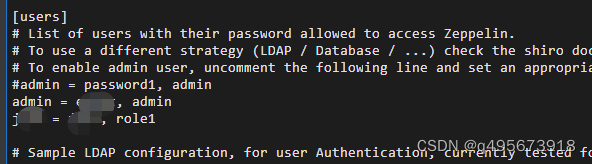
2.使用jdbc控制用户登录
可以通过jdbc控制用户登录,但是不可以控制权限,修改密码和新增用户立即生效,不用重启zeppelin
1.配置shiro.ini
讯享网[main] jdbcRealm= org.apache.shiro.realm.jdbc.JdbcRealm dataSource= com.alibaba.druid.pool.DruidDataSource #配置数据库url dataSource.url=jdbc:mysql://ip:port/database?serverTimezone=UTC dataSource.driverClassName=com.mysql.cj.jdbc.Driver #配置数据库用户 dataSource.username=username #配置数据密码 dataSource.password=password jdbcRealm.dataSource=$dataSource #配置登录访问的表 jdbcRealm.authenticationQuery=SELECT password FROM t_user WHERE username = ? #用户的角色,配置之后发现不起作用,此功能不是很重要,暂时未深入研究 #jdbcRealm.userRolesQuery=SELECT role_name FROM t_user_roles WHERE username = ? securityManager.realms=$jdbcRealm
2.导入驱动包
在lib目录下导入mysql-connector-java-8.0.28.jar和druid-1.2.8.jar包
3.新建库表

3.重启
su zeppelin bin/zeppelin-daemon.sh start 5.迁移note
直接迁移安装目录下的notebook文件夹,然后重启就好
6.构建
因zeppelin最新版本没有集成spark3,所以我们从git上下载源码,自己构建
构建过程当中遇到错误
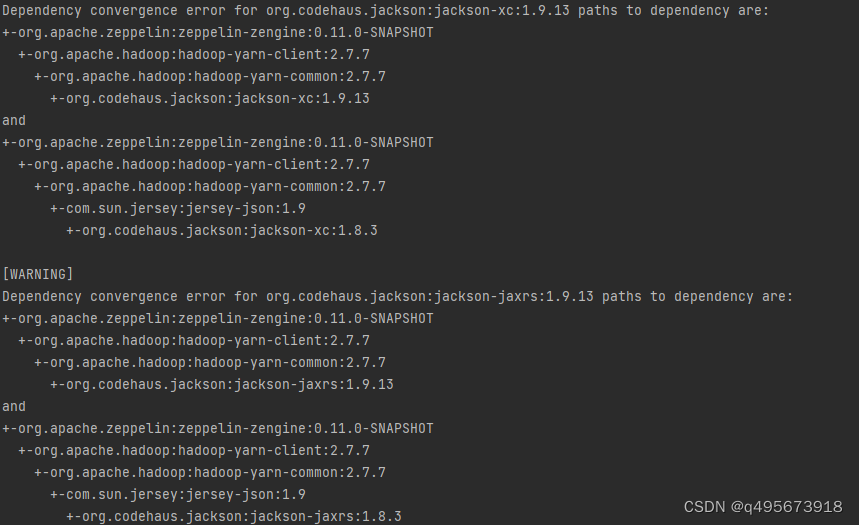

解决方法:jar包冲突,我们把低版本的jar包排除,进入到zengine的pom文件 ,找到
讯享网hadoop-yarn-client,然后排除低版本的jar包
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-client</artifactId> <exclusions> <exclusion> <groupId>org.codehaus.jackson</groupId> <artifactId>jackson-xc</artifactId> </exclusion> <exclusion> <groupId>org.codehaus.jackson</groupId> <artifactId>jackson-jaxrs</artifactId> </exclusion> </exclusions> </dependency>
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/49813.html