
参考书目:贾俊平. 统计学——Python实现. 北京: 高等教育出版社,2021.
无论是什么数据,在清洗整理完后第一步肯定是描述性统计。上一章介绍了这么画图,这一章介绍怎么计算各种简单的统计量,均值方差,偏度,峰度这些....
导入包,读取案例数据。
(最近很多同学找我要这个数据,可以参考:贾俊平统计学,整本书的实验数据都在里面)
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文 plt.rcParams ['axes.unicode_minus']=False #显示负号 #sns.set_style("darkgrid",{"font.sans-serif":['KaiTi', 'Arial']})讯享网df=pd.read_csv('example3_1.csv',encoding='gbk') df.head()
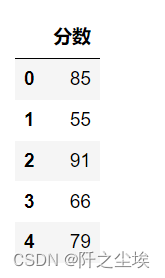 数据前五行
数据前五行
计算均值
df.mean() 
如果是分组数据,则计算加权平均数
讯享网df2=pd.read_csv('example3_2.csv',encoding='gbk') df2.head()
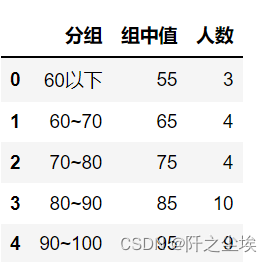
m=df2['组中值'] f=df2['人数'] print("加权平均:",np.average(a=m,weights=f))![]()
中位数
df['分数'].median() 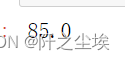
四分位数
pd.DataFrame.quantile(df,q=[0.25,0.75],interpolation='linear')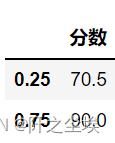
各种位置的分位数
pd.DataFrame.quantile(df,q=[0.1,0.25,0.5,0.75,0.9],interpolation='linear') 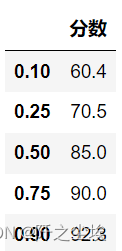
众数
mode=df['分数'].mode() mode极差
#极差 df['分数'].max()-df['分数'].min()四分位差
#四分位差 np.quantile(df['分数'],q=0.75)-np.quantile(df['分数'],q=0.25)方差
#方差 df['分数'].var(ddof=1)标准差
#标准差 df['分数'].std()变异系数
#变异系数 df['分数'].std()/df['分数'].mean()标准化分位数

#标准化分数 from scipy import stats z=stats.zscore(df['分数'],ddof=1) z=np.round(z,4) print('标准分数:',z) 
偏度
#偏度 skew=df['分数'].skew() skew峰度
#峰度 kurt=df['分数'].kurt() kurt一个综合的例子
读取案例数据
df=pd.read_csv('example3_12.csv',encoding='gbk') df.head()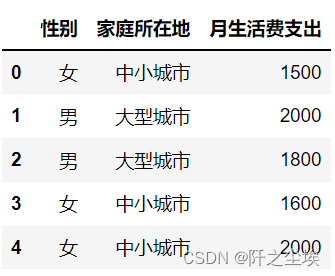
可以看到是两个分类变量和一个数值型变量。先把数值型变量画个图,直方图加箱线图
#直方图和箱线图 x=df['月生活费支出'] fig=plt.figure(figsize=(6,5)) spec=fig.add_gridspec(nrows=2,ncols=1,height_ratios=[1,3]) ax1=fig.add_subplot(spec[0,:]) x.plot(kind="box",vert=False) ax1.spines['right'].set_color('none') ax1.spines['top'].set_color('none') ax1.spines['left'].set_color('none') ax1.spines['bottom'].set_color('none') ax1.set_xticks([]) ax2=fig.add_subplot(spec[1,:]) x.plot(bins=10,kind='hist',ax=ax2,density=True,legend=False) x.plot(kind='density',ax=ax2,lw=3) ax2.set_xlabel('月生活费支出') ax2.set_ylabel('频率') ax2.set_xlim(x.min(),x.max()) ax2.spines['right'].set_color('none') ax2.spines['top'].set_color('none') plt.tight_layout() plt.show()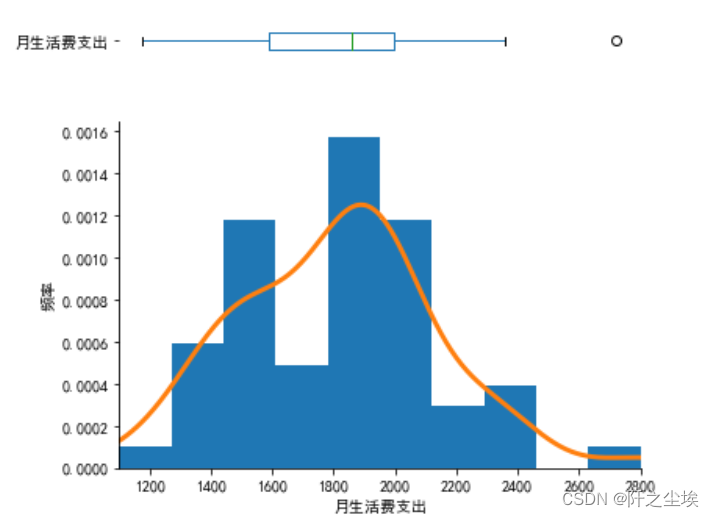
分组画核密度图
#分组核密度图 plt.figure(figsize=(12,4)) plt.subplot(1,2,1) sns.kdeplot('月生活费支出',hue='性别',shade=True,data=df) plt.title('(a)性别分组') plt.subplot(1,2,2) sns.kdeplot('月生活费支出',hue='家庭所在地',shade=True,data=df) plt.title('(b)家庭所在地分组') 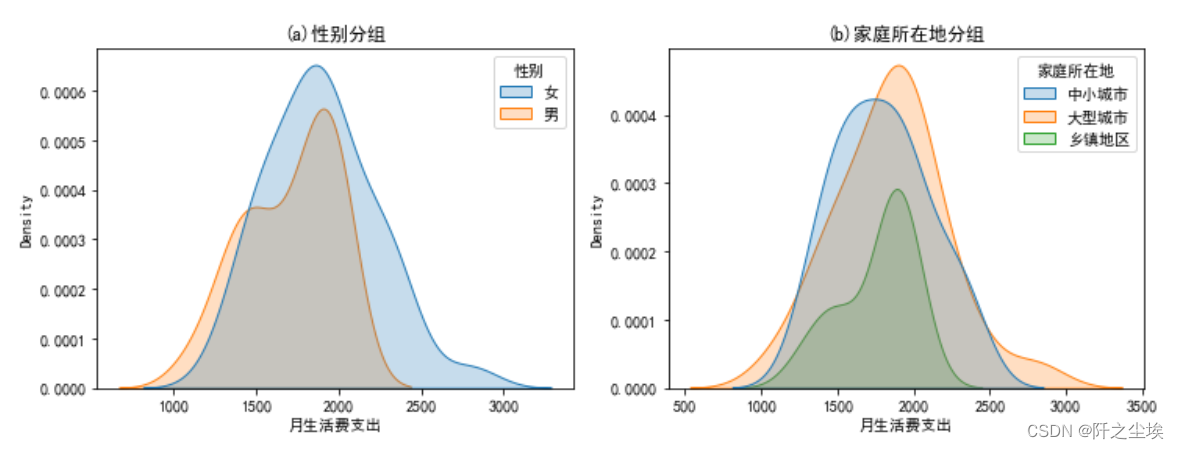
#按照性别和家庭分组箱线图
#按照性别和家庭分组箱线图 plt.figure(figsize=(8,5)) sns.boxplot(x='性别',y='月生活费支出',hue='家庭所在地',width=0.6,saturation=0.9, #饱和度 fliersize=2,linewidth=0.8,notch=False,palette='Set2',orient='v',data=df) #plt.xticks(fontsize=15,rotation=10) plt.show()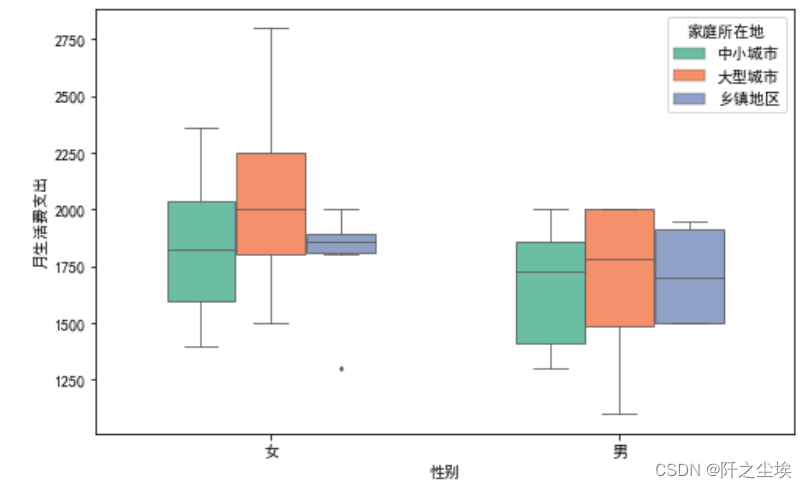
按照性别和家庭分组点图
#按照性别和家庭分组点图 plt.subplots(1,2,figsize=(8,4)) plt.subplot(121) sns.stripplot(x='性别',y="月生活费支出",jitter=True,size=5,data=df) plt.title('(a)安性别分组') plt.subplot(122) sns.stripplot(x='家庭所在地',y="月生活费支出",size=5,data=df) plt.title('(b)家庭分组')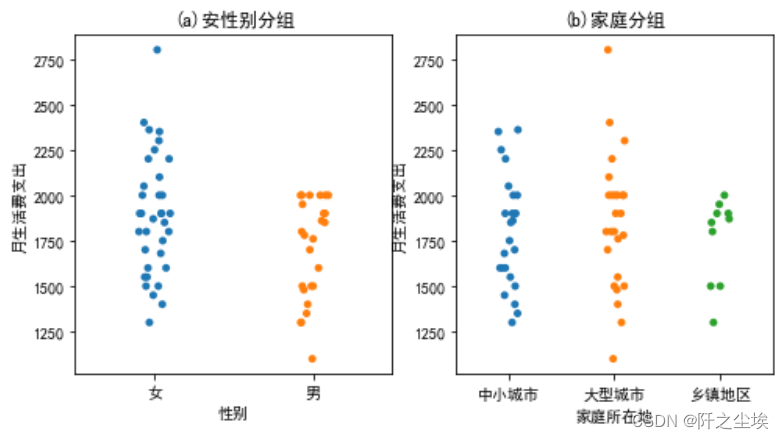
性别家庭频数分析,分析不同性别和不同家庭的样本个数
#性别家庭频数分析 tab=pd.pivot_table(df,index=['性别'],columns=['家庭所在地'],margins=True,margins_name="合计",aggfunc=len) tab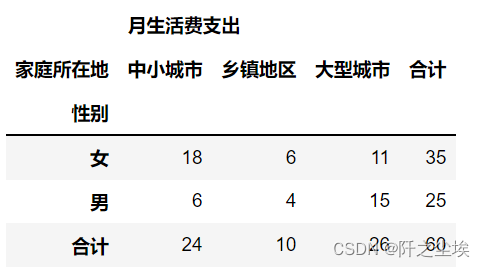
性别家庭生活费分析统计量,这里采用很多聚合函数,所以得到很多统计量的值
#性别家庭频数分析统计量 tab=pd.pivot_table(df,index=['性别','家庭所在地'],values=['月生活费支出'],margins=True,margins_name="合计",aggfunc=[sum,min,max,np.mean,np.std]) tab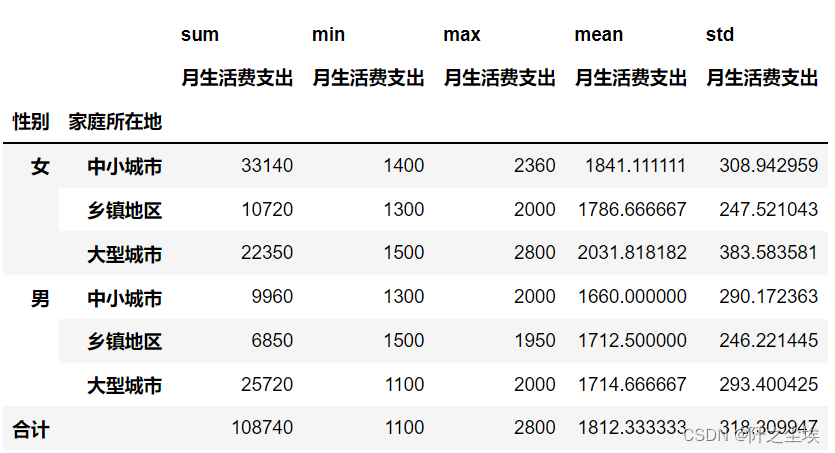
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/49542.html