
复盘第一次NLP算法比赛 Top2

DECEM
(本科在读)NLP | Time Series
关注他
薛定谔的猫lxx
、
苏格兰折耳喵
、
阴天快乐
、
阿水
、
TniL
等 162 人赞同了该文章
大家好,我是DECEM,一名大二学生。本次比赛是笔者入门NLP后的第一场比赛,是在公众号上偶然间看到的,属于偏基础的文本匹配任务,适合新人作为NLP实战入门项目。
经过组队两个月的努力,在近300支提交队伍中取得了还不错的成绩:初赛第一,复赛第二,决赛第二。

比赛链接:
2021 Sohu Campus Document Matching AIgorithm Competitionwww.biendata.xyz/competition/sohu_2021/正在上传…重新上传取消
开源代码:
Decem-Y/sohu_text_matching_Rank2github.com/Decem-Y/sohu_text_matching_Rank2正在上传…重新上传取消
01 任务分析
本次比赛的赛题可以概括为“长短不一的文本对在不同粒度下的匹配问题”。
具体而言,任务数据中包含A类(话题)与B类(事件)两种评判标准,同时有三项细分任务,分别是:短文本-短文本匹配,短文本-长文本匹配,长文本-长文本匹配。
比赛同时对资源进行了限制,要求模型大小低于2G且单个句对推理时间不超过500ms。
综上,我们认为比赛的难点包括:
- 不同评判颗粒度和多个子任务
- 需处理大量超长文本
- 正负样例存在类别不平衡问题
02 数据分析
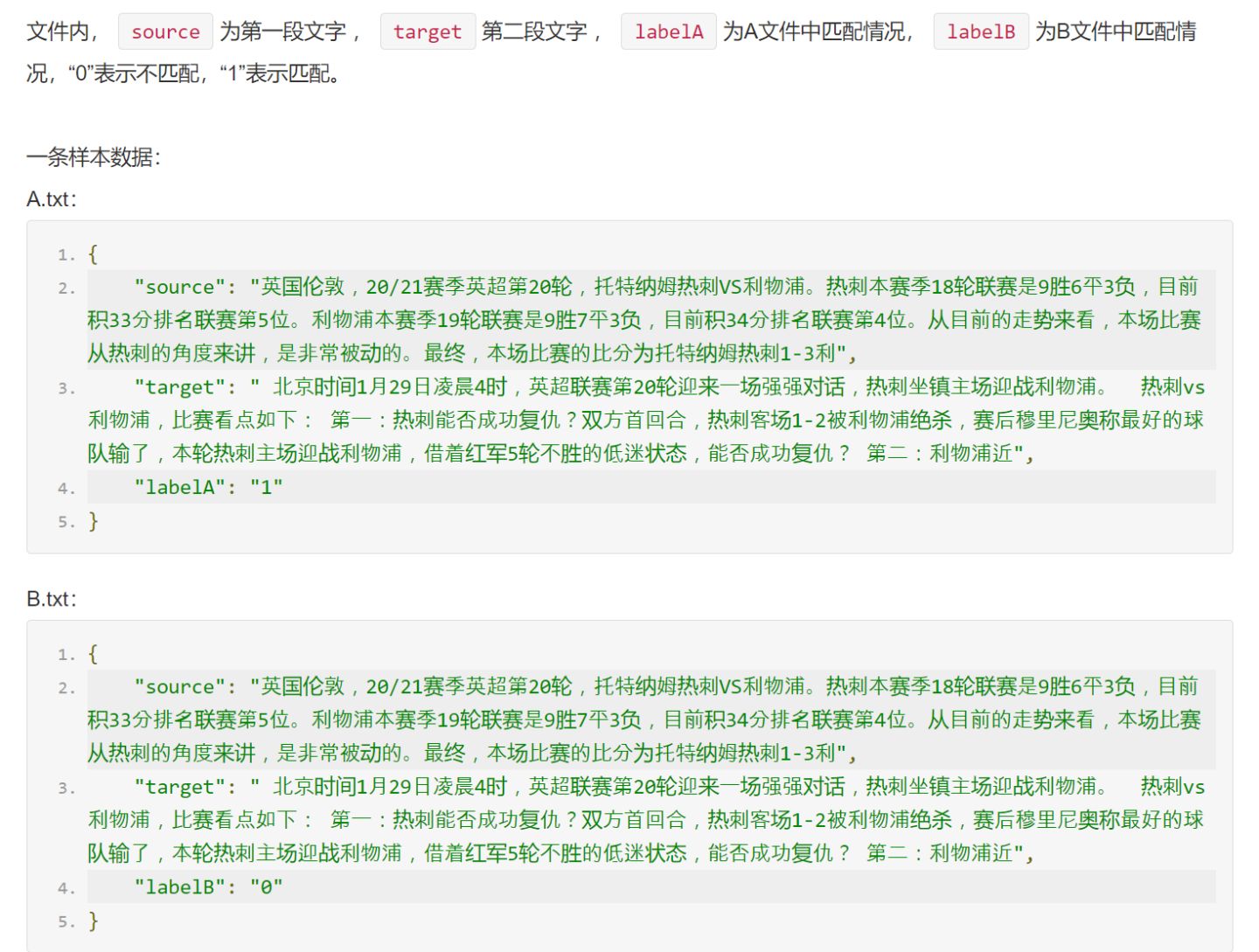
各类任务的样本数目
短短匹配任务样本数量略少,训练集、验证集与测试集的样本数目比例基本一致。
在复赛环节中,我们采用了初赛与复赛的训练集(共计241,726条)和复赛的验证集(共计13,825条),并在复赛测试集(共计41,480条)上推理结果。
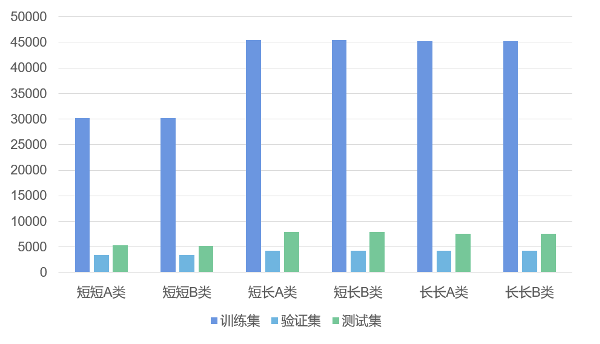
各类任务的正负样本比例
B类类别不平衡现象明显,训练集与评估集分布不一致。
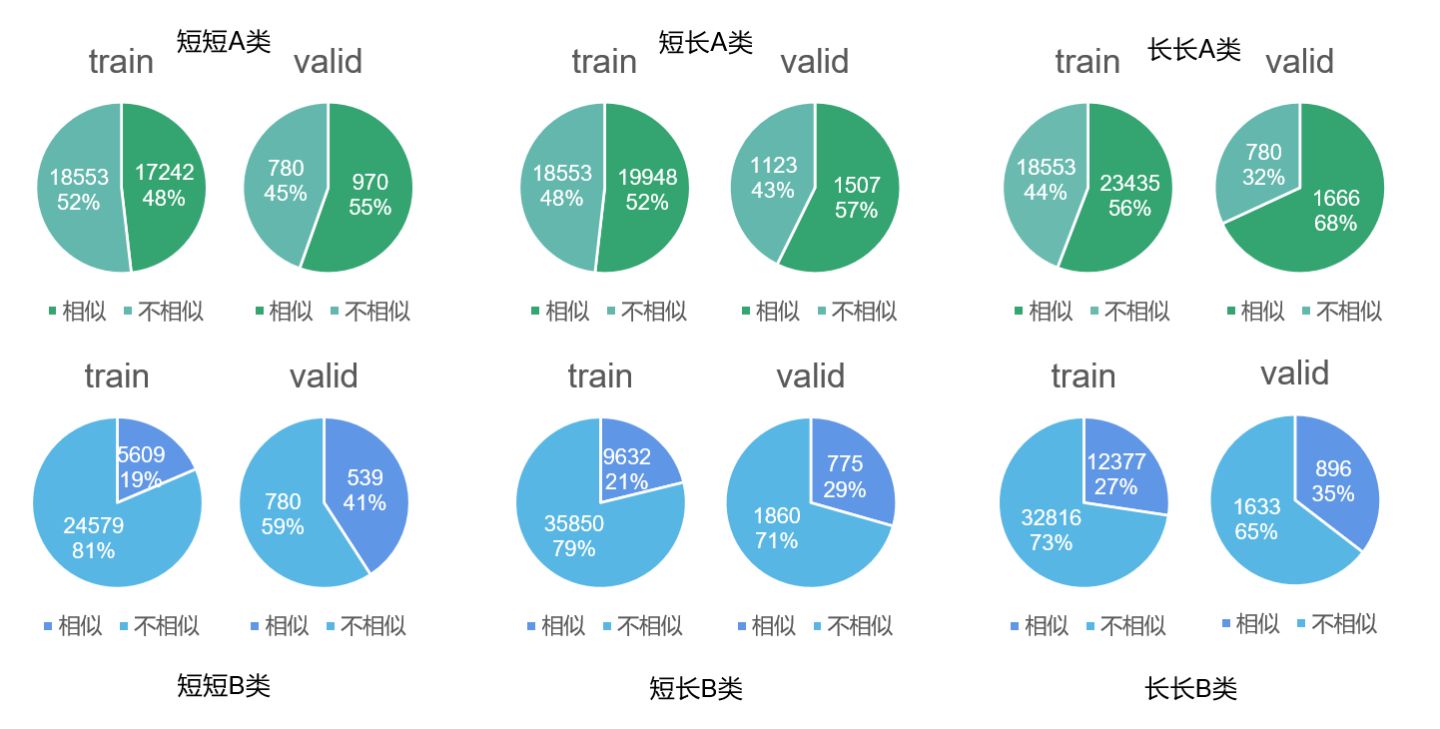
各类任务文本长度
短文本均值μ≈60,长文本μ≈1000;部分文本超长,达数千字。
03 匹配方法实现
我们的技术方案主要包含以下几个流程。
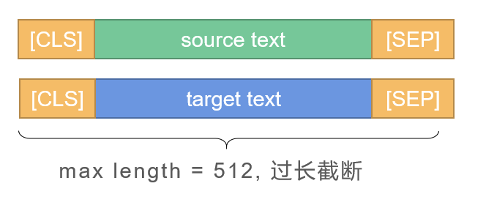
匹配任务数据预处理
cross-encoder类:拼接source与target,返回token_ids, token_types,label/id与任务编号(AB大类0-1,或子任务0-5)


bi-encoder类:为source和target分别处理,返回source_token_ids, target_token_ids,label/id与任务编号
模型定义与预训练
针对匹配任务的3类模型思路:
(1) cross-encoder类:对一组句对进行编码,编码过程中可以进行句内及句间的信息交互。
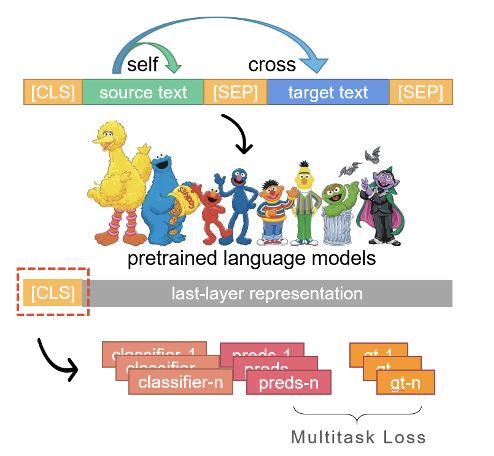
优点:cross-encoder比bi-encoder实现更好的性能
缺点:文本长度受限,实际应用场景应用并不实用
(2) bi-encoder类:分别对source文本和target文本进行编码,再通过网络结构进行表示间的交互和计算,得到最终分类结果
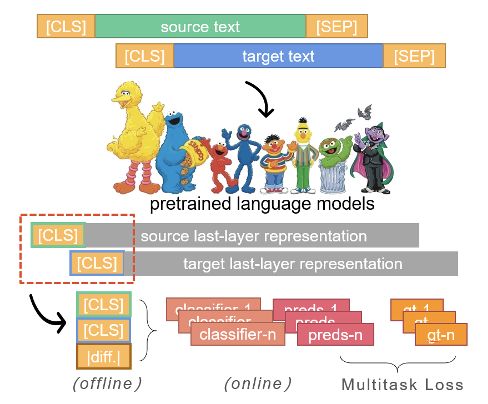
优点:更大的文本长度上限,推理速度较cross-encoder类更快
缺点:文本之间的信息交互不充分,训练时对算力的要求更高
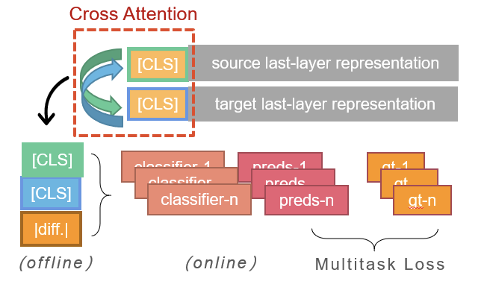
(3) Cross Attention:对bi-encoder类的改进,加入跨句子表示的注意力模块,显式促进文本之间的信息交互 与原方案相比得分略微增长(较SBERT提升2%~3%)
模型训练
使用到的预训练模型:
NEZHA_base_wwm(单模最优):完全函数式的相对位置编码,加入Span预测任务
RoFormer:通过绝对位置编码的方式实现相对位置编码,能处理较长序列
Roberta-wwm-ext:采用WWM策略,取消NSP任务,更大规模的中文训练数据
Macbert_base:替换[MASK]为近义词,由模型“纠正”,使用SOP任务,预测上下句顺序
Ernie_1.0:融入实体概念等先验语义知识,基于贴吧提问-回帖的DLM任务
模型推理与融合
测试集推理前,在验证集上搜索AB两类任务最优的正例阈值,以最大化F1指标。
由于正负样例类别不平衡,最后阈值在0.4左右,B类小于A类 如果验证集与测试集分布一致,可考虑按子任务进行阈值优化(未尝试)。
模型以优化后的阈值进行推理,各模型推理后的标签输出通过投票进行融合,在验证集上搜索**的模型组合,融合模型输出作为最终提交。
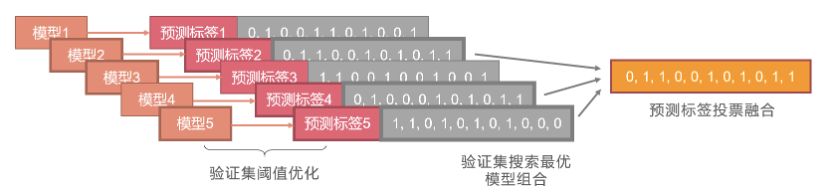
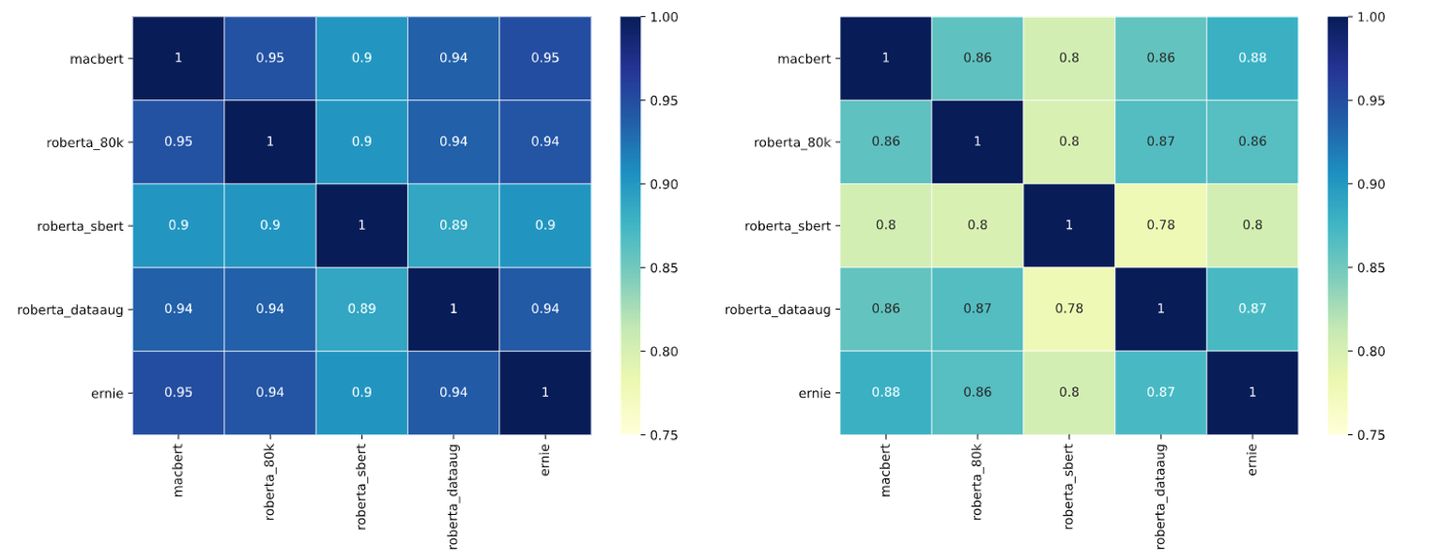
“和而不同”:不同模型方案、预训练模型、训练技巧的模型融合可提升1%+;相比于取概率分布,取0-1标签放大了模型之间的差异,输出的相关系数明显降低。
04 涨分trick
做一个深度学习主导的算法比赛,除了分析数据与模型,一些trick也是获得高分的重要因素。这里罗列了一些常用策略。
- 优化器与学习率:尝试Lookahead + Radam 加入权重衰减,线性规划学习率
- 数据增强:互换source文本与target文本的位置,A类负例是B类负例,B类正例是A类正例
- Multi-Sample Dropout:对encoder的输出进行多次dropout,得到多组样本,以更好地训练classifier
- Focal Loss:针对类别不平衡问题,降低负样本的权重(0.2%)
- Task-adaptive Pretraining:在比赛提供的文本语料上继续MLM任务,使语言模型更贴近任务领域的语料分布 效果:新闻领域与预训练文本领域较为接近,提升有限(0.5%)
- 文本对抗训练(由于比赛数据较多,复赛时间和算力有限,未尝试FGM与PGD)(初赛提升0.5%)
- 伪标签:模型在测试集上标注得到伪标签,将伪标签与真实标签一起训练模型(噪声较大,降低模型鲁棒性,最终未采取)
- 标签平滑(提升效果不明显)
05 总结
在这里感谢搜狐对比赛的支持,通过这次比赛,很大程度的增长了自己在NLP方面的知识和coding能力,取得这样的成绩,也算是对自己的一次勉励。
如文中有不对的地方,也欢迎大家在评论区或者私信
@DECEM
指正交流,谢谢!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/49323.html