
https://github.com/guyulongcs/CIKM2020_DMT
1、Motivation

讯享网
2、Method
Deep Multifaceted Transformers(DMT)算法,使用多个Transformers同时建模用户多种行为序列,利用MMoE优化多个目标。另外,探索了消偏学习来减轻训练数据的选择偏差。
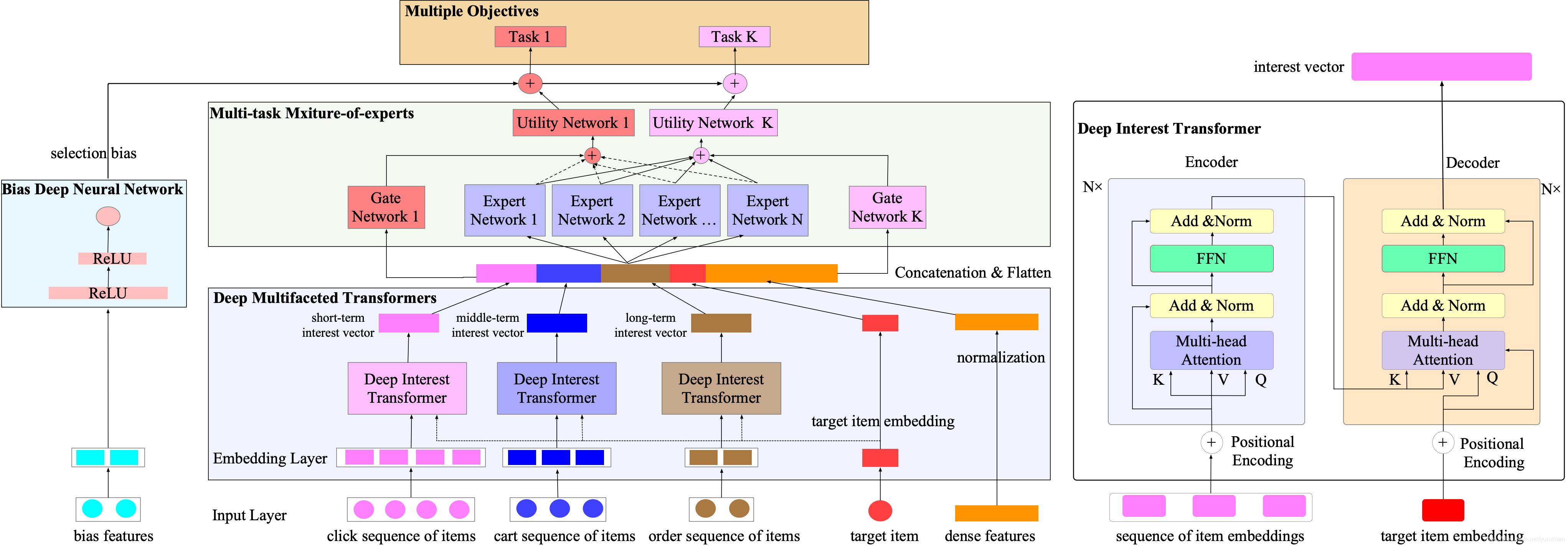
Encoder. encoder对行为序列的embedding使用self-attention block,使得序列里的每个商品能与输入序列里的全部sku交互。self-attention机制建模用户行为序列中任意两个商品的相互关系,能够更好地从历史行为中学习用户的兴趣。
Decoder. 由于用户的兴趣是多样的,decoder使用目标商品做为query,encoder的输出做为keys和values。decoder学习目标商品和历史序列中每个商品的attention score,为每个目标商品学习唯一的兴趣表示。兴趣向量随着不同的目标商品而发生变化,提高了模型的表达能力。

2 Multi-gate Mixture-of-Experts Layers
在电商推荐系统中,通常有不同的学习目标,例如CTR、CVR和GMV。排序系统应该能够预估这些不同目标,结合这些目标得到一个最终的排序分数。为了刻画多任务的关系,使用MMoE来进行多目标排序。DMT在Deep Multifaceted Transformers层的输出后添加MMoE。
3 Bias Deep Neural Network
由于曝光的商品来源于之前的排序系统,并且用户会有选择偏差,排序模型使用隐式反馈数据进行训练会是有偏的。本文主要研究了电商系统中的两种选择偏差:Position bias 和Neighboring bias。Position bias是指用户倾向于点击排在靠前的商品。Neighboring bias是指商品被点击的概率受其附近的商品所影响。DMT使用Bias Deep Neural Network建模选择偏差。网络输入是bias特征。
4 Model Training and Prediction
Training 在训练阶段,对于每个任务 图片 ,预估分数 图片 由从多任务学
习层的 图片 和深度偏差网络 图片 使用sigmoid函数得到。对于每个任务使用交叉熵损失函数,总的loss 图片 为每个目标的loss加权和:、
3、Experiments

4、Conclusions

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/48269.html