
第一章:
一、机器学习就是自动找函式

二、首先明确,你 想找什么样的函式
大致可分为三种:
1、回归,函数的输出是一个数值

2、分类
(1)二元分类

(2)多层次分类

3、生成:产生有结构的复杂东西,如文句、图片等。拟人化的说法,即创造
三、怎样去告诉机器 ,你想找什么样的函式
1、函数的LOSS:预测结果的出错率。损失函数(loss function)是用来估量模型的预测值f(x)与真实值y的不一致程度的,它是一个非负的实值函数。损失函数越小,通常函数的鲁棒性也就越好,鲁棒性一般指稳定性。

2、有监督学习:
通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现预测和分类的目的,也就具有了对未知数据进行预测和分类的能力。简单来说,就像有标准答案的练习题,然后再去考试,相比没有答案的练习题然后去考试准确率更高。监督学习中的数据中是提前做好了分类信息的, 它的训练样本中是同时包含有特征和标签信息的,因此根据这些来得到相应的输出。
有监督算法常见的有:线性回归算法、BP神经网络算法、决策树、支持向量机、KNN等

3、无监督学习
训练样本的标记信息未知, 目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,此类学习任务中研究最多、应用最广的是"聚类" (clustering),聚类目的在于把相似的东西聚在一起,主要通过计算样本间和群体间距离得到。深度学习和PCA都属于无监督学习的范畴。
无监督算法常见的有:密度估计(densityestimation)、异常检测(anomaly detection)、层次聚类、EM算法、K-Means算法(K均值算法)、DBSCAN算法 等。
4、强化学习:属于无监督学习,用于描述智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。

5、迁移学习:将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中
6、教机器学习如何去学习

7、终身学习

8、异常检测(anomaly detection): 对不匹配预期模式或数据集中其他项目的项目、事件或观测值的识别。 通常异常项目会转变成银行欺诈、结构缺陷、医疗问题、文本错误等类型的问题。异常也被称为离群值、新奇、噪声、偏差和例外。
四、机器怎样找出你想要的函数式
1、限制函数式的寻找范围

2、给定函数式的寻找方法:梯度下降

第二章:
一、Regression: Output a scalar

以预测宝可梦进化后的cp值为例
分三步
第一步、模型
确定模型
第二步、Goodness of Function(确定评价函数)——损失函数
有了这些真实的数据,那我们怎么衡量模型的好坏呢?从数学的角度来讲,我们使用距离。求实际进化后的CP值与模型预测的CP值差,来判定模型的好坏。
也就是使用 损失函数(Loss function) 来衡量模型的好坏,和越小模型越好。

第三步、best function(找出最好的一个函数)——梯度下降法
找到一个使损失函数最小时候的参数

用梯度下降法,找到一个**参数
梯度是什么?梯度下降又是什么?
梯度:
- 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率
- 在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向
梯度下降:“下山最快路径”的一种算法
先考虑简单的一个参数w
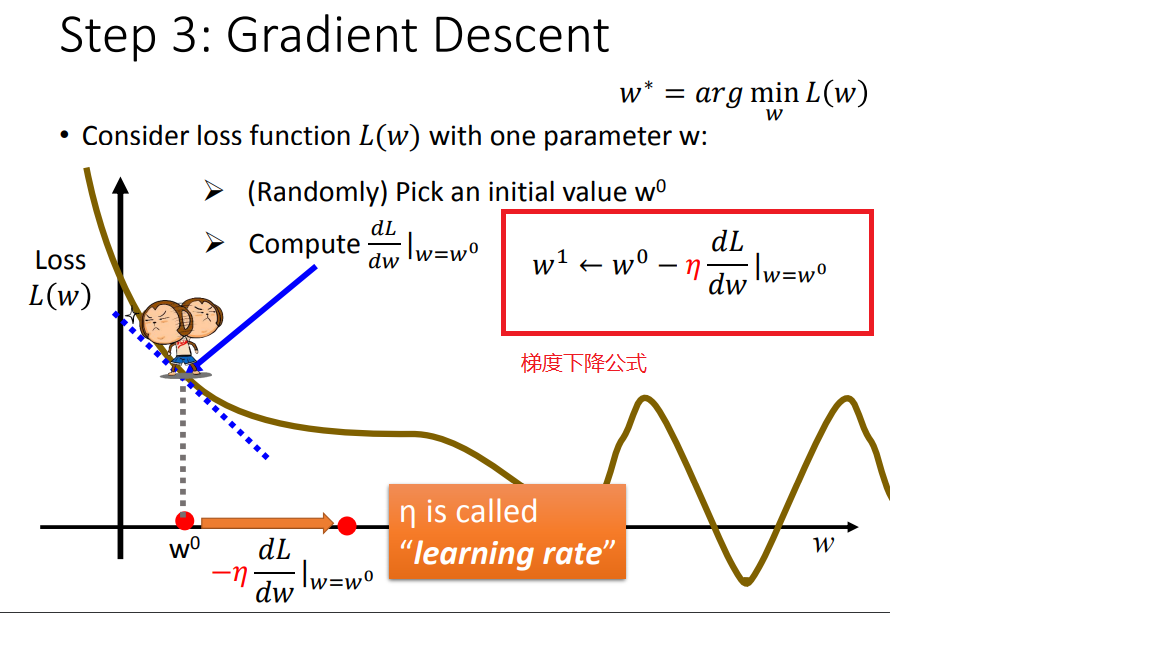
在这里引入一个概念 学习率 :移动的步长,如图7中 η (eta)
步骤1:随机选取一个 w0 。
步骤2:计算微分,也就是当前的斜率,根据斜率来判定移动的方向。
大于0向右移动(增加w)
小于0向左移动(减少w)
步骤3:根据学习率移动。
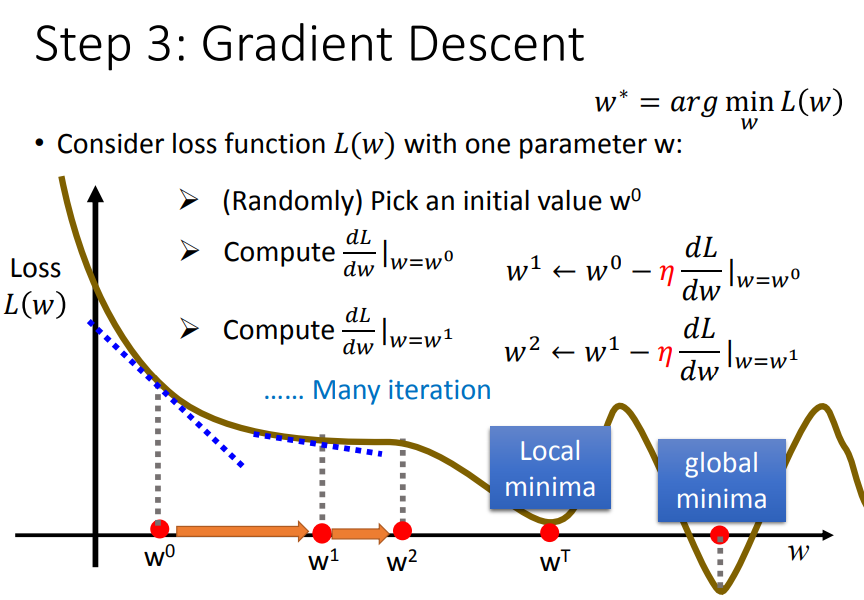
重复步骤2和步骤3,直到找到最低点。
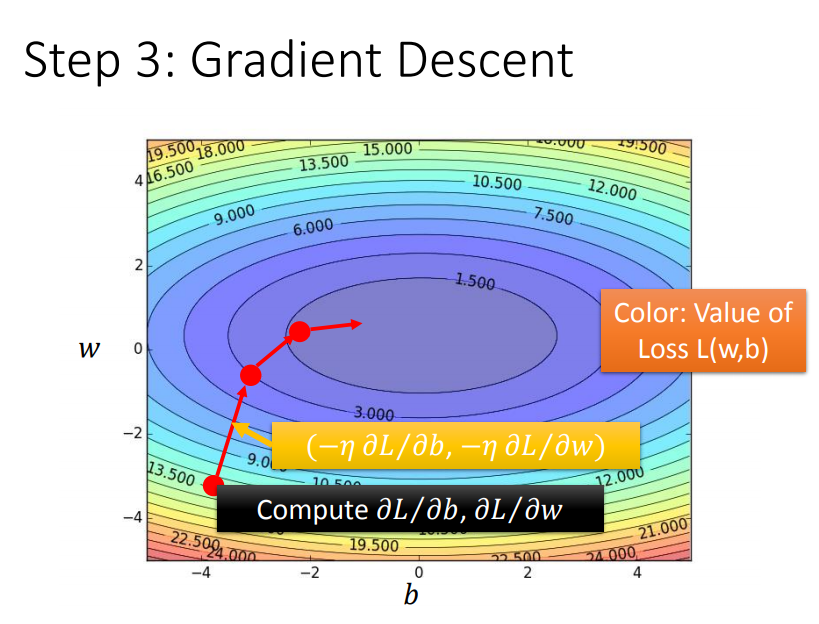
再考虑两个参数(w、b)

梯度下降法的效果

红色部分代表损失函数最大
梯度下降的缺点
总结一下梯度下降法:我们要解决使L(x)最小时参数的**值,梯度下降法是每次update参数值,直到损失函数最小。

但是梯度下降法会出现问题呢?
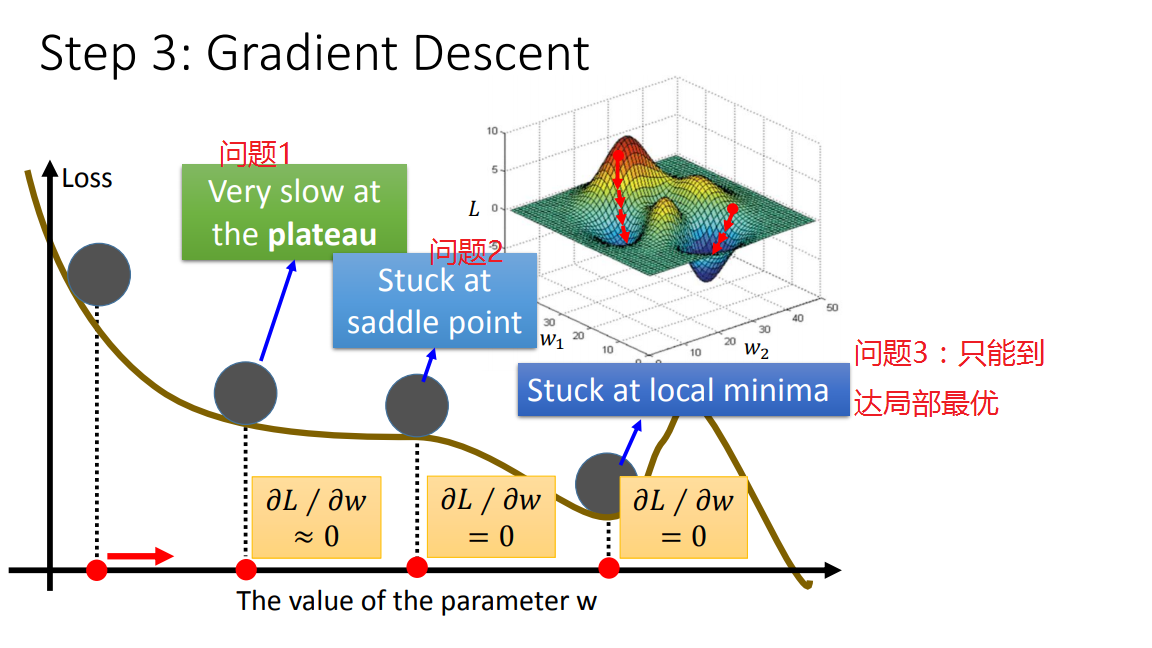
二、如何做的更好呢
方法1、select another model(选择另一个模型):
1、model改用不同函数的performance:
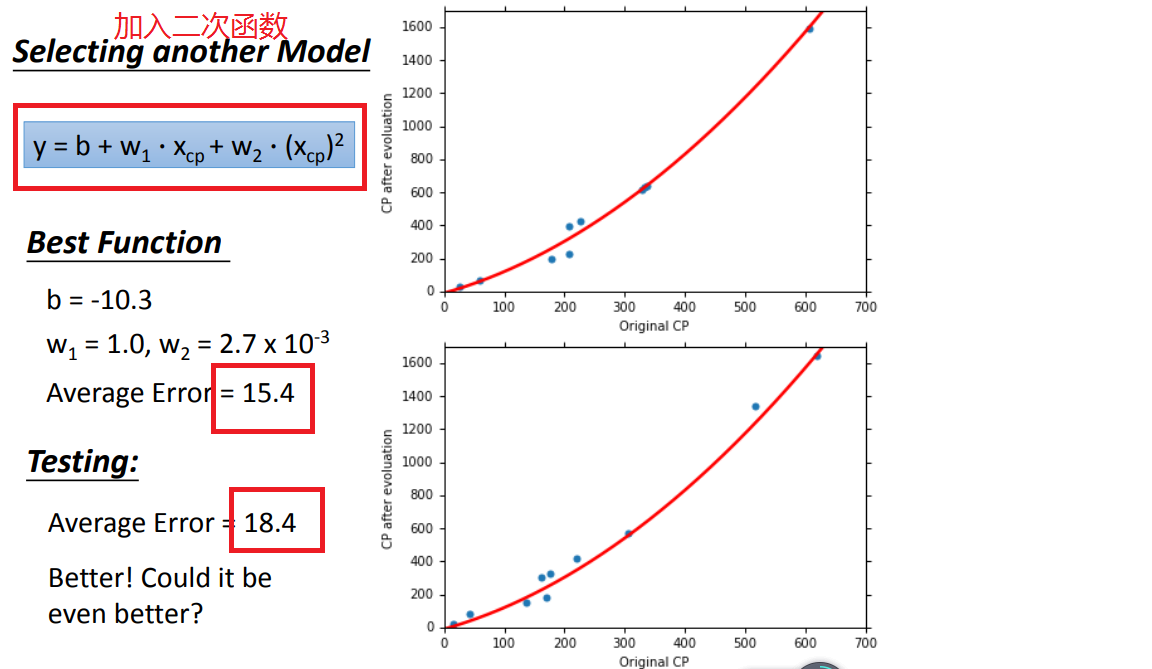
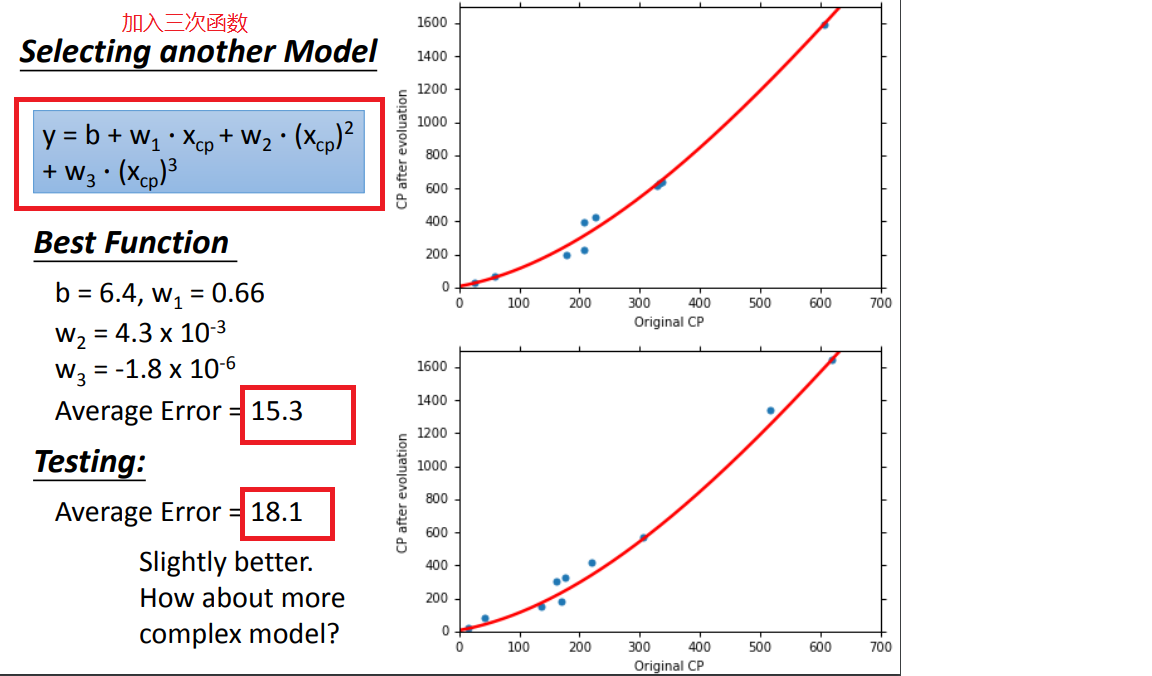
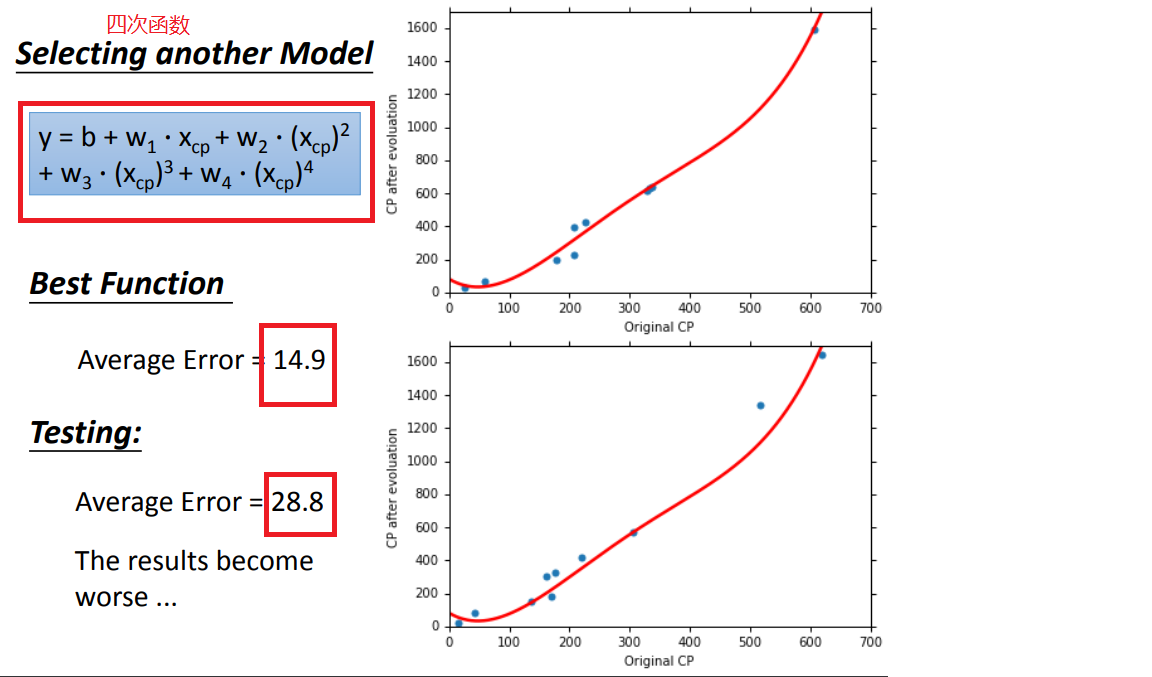
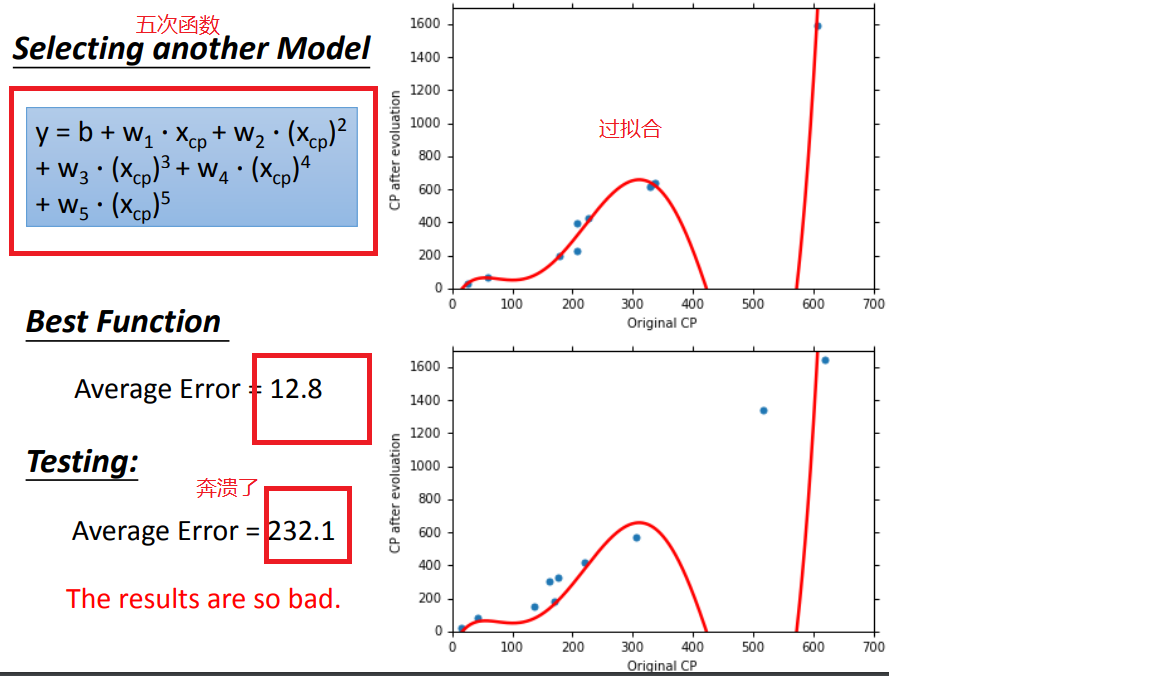
模型的选择:A more complex model yields lower error on training data.A more complex model does not always lead to better performance on testing data.会导致过拟合
方法2、consider the hidden factors(考虑其他隐藏因素)
防止过拟合:
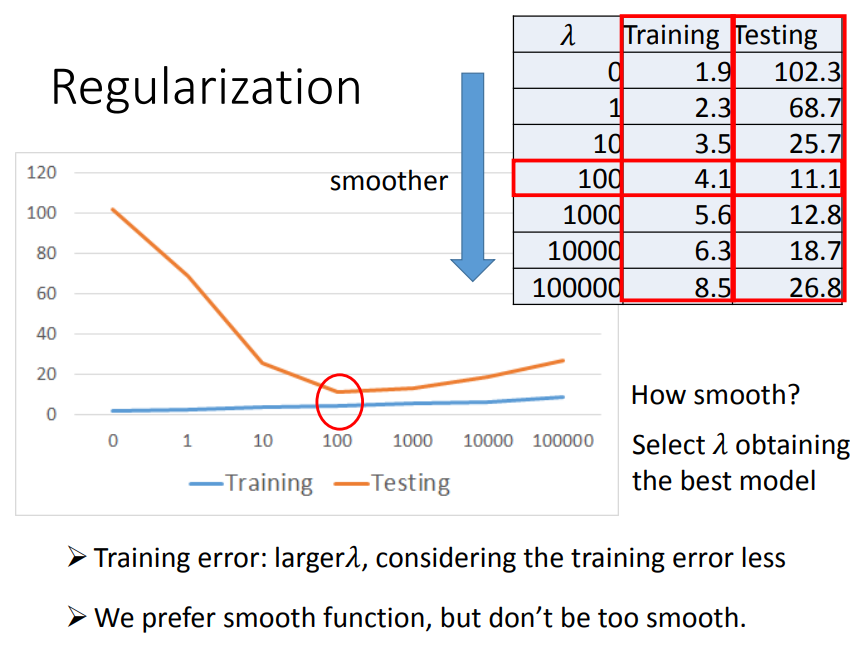
方法:正则化
1、比如先考虑一个参数w,正则化就是在损失函数上加上一个与w(斜率)相关的值,那么要是loss function越小的话,w也会越小,w越小就使function更加平滑(function没那么大跳跃)

2、正则化的缺点
正则化虽然能够减少过拟合的现象,但是因为加在损失函数后面的值是平白无故加上去的,所以正则化过度的话会导致bias偏差增大
三、总结
 第三章:Where does the error come from?
第三章:Where does the error come from?

一个更复杂的模型不一定会在测试数据上得到更好的结果,导致这种情况的原因是bias(偏差)和variance (方差)
偏差(bias):偏差衡量了模型的预测值与实际值之间的偏离关系,也就是输出预测结果的期望与样本真实结果的差距。

上图中红色靶心为实际值,蓝色点集为预测值:
低偏差,低方差:这是训练的理想模型,此时蓝色点集基本落在靶心范围内,且数据离散程度小,基本在靶心范围内;
低偏差,高方差:这是深度学习面临的最大问题,过拟合。模型太贴合训练数据,导致其泛化(或通用)能力差,若遇到测试集,则准确度下降的厉害;
高偏差,低方差:这往往是训练的初始阶段;
高偏差,高方差:这是训练最糟糕的情况,准确度差,数据的离散程度也差。





通常在深度学习训练中,初始阶段模型复杂度不高,为高偏差、低方差;随着训练量加大,模型逐步拟合训练数据,准确度不断上升,复杂度开始变高,此时偏差逐渐降低,方差会逐渐变高。一般来说,随着模型复杂度的增加,方差会逐渐增大,偏差会逐渐减小。
- [高方差] :采集更多的样本数据;减少特征数量,去除非主要的特征;增加正则化参数 λ
- [高偏差] :引入更多的相关特征;采用多项式特征;减小正则化参数 λ
总结:学习能力太强造成的主要误差是方差,学习能力不行造成的主要误差是偏差。
模型的选择:



将training set 分为Training Set(训练集)和Validation set(验证集)再进行之后的步骤,并且在测试时不要去考虑测试时的偏差影响,会得到一个比较好的结果。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/47615.html