
亲和性分析---根据样本个体(物体)之间的相似度,确定他们关系的亲疏,探索各变量间的关系。
一、应用场景:
1.向网站用户提供多样化的服务或投放定向广告
2.为了向用户推荐电影或商品,而卖给他们一些与之相关的小玩意
3.根据基因寻找有亲缘关系的人
测量方法:统计两件商品一起出售的频率,或者统计顾客购买了商品X后再买商品Y的比率,或者计算个体之间的相似度。
简单的规则排序:记一条规则为“如果一个人买了X,那么他很有可能购买Y。”找出规则后,还需要判 断其优劣,我们挑好的规则用。 规则的优劣有多种衡量方法,常用的是支持度(support)和置信度(confidence)。
支持度:支持度衡量的是给定规则应验的比例。

置信度:置信度衡量的则是规则准确率如何,即符合给定条
件(即规则的“如果”语句所表示的前提条件)的所有规则里,跟当前规则结论一致的比例有多
大。计算方法为首先统计当前规则的出现次数,再用它来除以条件(“如果”语句)相同的规则
数量。
二、以顾客购买面包、牛奶、奶酪、苹果和香蕉5种水果的交易记录为例。
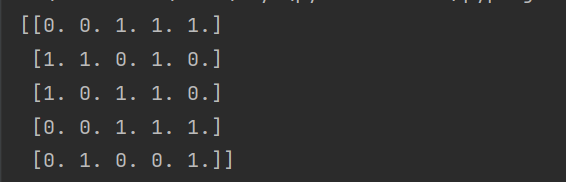
1.加载数据集--affinity_dataset.txt
import numpy as np dataset_filname = "affinity_dataset" x = np.loadtxt(dataset_filname) print(x[:5])讯享网
上述代码的运行结果为前5次交易中,顾客都买了什么。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/41382.html