
一、商品检索功能介绍
1、功能简介
什么是搜索, 计算机根据用户输入的关键词进行匹配,从已有的数据库中摘录出相关的记录反馈给用户。
常见的全网搜索引擎,像百度、谷歌这样的。但是除此以外,搜索技术在垂直领域也有广泛的使用,比如淘宝、京东搜索商品,万芳、知网搜索期刊,csdn中搜索问题贴。也都是基于海量数据的搜索。
1.1、入口: 两个
首页的分类

搜索栏

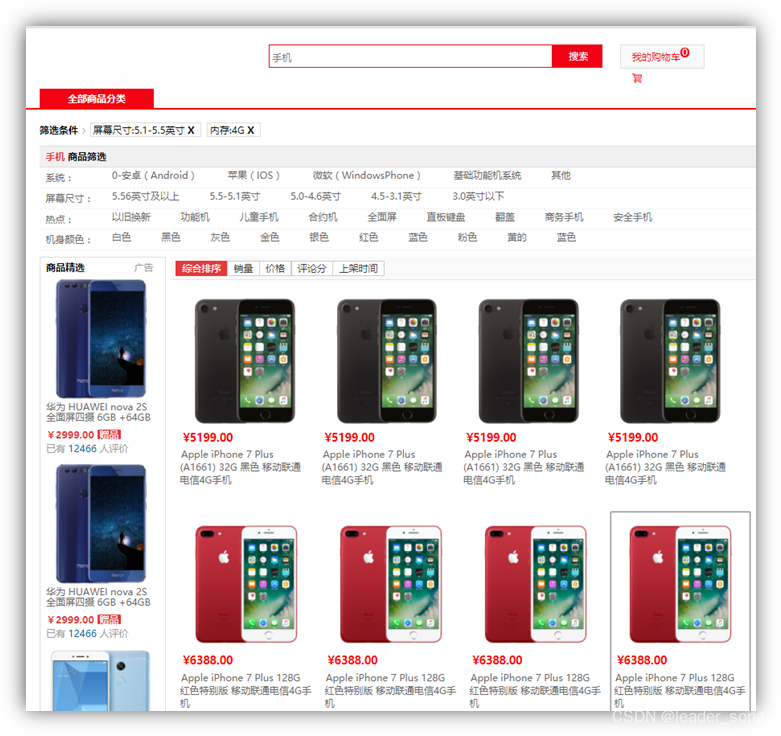
1.2、列表展示页面
2、全文检索工具ElasticSearch
2.1、lucene与elasticsearch、solr
lucene只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来的应用。
好比lucene是类似于jdk,而搜索引擎软件就是tomcat 的。
目前市面上流行的搜索引擎软件,主流的就两款,elasticsearch和solr,这两款都是基于lucene的搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,对于数据的操作,修改、添加、保存、查询等等都十分类似。就好像都是支持sql语言的两种数据库软件。只要学会其中一个另一个很容易上手。
从实际企业使用情况来看,elasticSearch的市场份额逐步在取代solr,国内百度、京东、新浪都是基于elasticSearch实现的搜索功能。国外就更多了 像维基百科、GitHub、Stack Overflow等等也都是基于ES的。
2.2、elasticSearch的使用场景
- 为用户提供按关键字查询的全文搜索功能。
- 著名的ELK框架(ElasticSearch,Logstash,Kibana),实现企业海量日志的处理分析的解决方案。大数据领域的重要一份子。
2.3、elasticsearch的基本概念
| cluster |
整个elasticsearch 默认就是集群状态,整个集群是一份完整、互备的数据。 |
| node |
集群中的一个节点,一般只一个进程就是一个node |
| shard |
分片,即使是一个节点中的数据也会通过hash算法,分成多个片存放,默认是5片。 |
| index |
相当于rdbms的database, 对于用户来说是一个逻辑数据库,虽然物理上会被分多个shard存放,也可能存放在多个node中。 |
| type |
类似于rdbms的table,但是与其说像table,其实更像面向对象中的class , 同一Json的格式的数据集合。 |
| document |
类似于rdbms的 row、面向对象里的object |
| field |
相当于字段、属性 |
2.4、中文分词
elasticsearch本身自带的中文分词,就 是 单 纯 把 中 文 一个字一个字的分开,根本没有词汇的概念。但是实际应用中,用户都是以词汇为条件,进行查询匹配的,如果能够把文章以词汇为单位切分开,那么与用户的查询条件能够更贴切的匹配上,查询速度也更加快速。
分词器下载网址:https://github.com/medcl/elasticsearch-analysis-ik
IK分词器 smartcn
可以进行拓展分词
动态分词
3、根据业务搭建数据结构
3.1、建立mapping!
这时我们要思考三个问题:
- 哪些字段需要分词
- 例如:商品名称 红米 手机 K30Pro
- 我们用哪些字段进行过滤(当做查询的条件)
- 平台属性值
- 分类Id
- 品牌、价格区间、热度、评论、销量
- 哪些字段我们需要通过搜索查询出来。
- Id(隐藏),商品名称,价格,图片等。
以上分析的所有显示,以及分词,过滤的字段都应该在es中出现。Es中如何保存这些数据呢?
“根据上述的字段描述,应该建立一个mappings对应的存上上述字段描述的信息!”
根据以上制定出如下结构:mappings
Index:goods
type:info
document: properties - rows
field: id,price,title…
Es中index默认是true。
info= Type
对应的mapping 结构:
讯享网 |
注意:ik_max_word 中文词库必须有!
attrs:平台属性值的集合,主要用于平台属性值过滤。
3.2 构建实体与es mapping建立映射关系
讯享网 |
讯享网 |
3.2 初始化mapping结构到es中
package com.atguigu.gmall.list.controller; @RestController @RequestMapping("api/list") public class ListApiController {Jest @Autowired private ElasticsearchRestTemplate restTemplate; / * * @return */ @GetMapping("inner/createIndex") public Result createIndex() { restTemplate.createIndex(Goods.class); restTemplate.putMapping(Goods.class); return Result.ok(); } }通过kibana查看mapping

二、商品上架,下架
封装商品上下架接口
| 实现类 讯享网 |
|
三、商品热度排名
搜索的业务处理:
- 知道哪些是查询条件,分类的id 平台属性和平台属性值、品牌、热度、价格、关键字
- 构建查询语句,主要就是进行条件判断,看有没有某些条件,如果有就把条件给拼接进去。
- 执行查询
- 解析结果,查询的结果中获取到你想要的数据 封装到java对象中 返回。
想要的数据有 skuid 名称 价格 默认图片,筛选条件 平台属性、分类、品牌。在页面展示,供用户点击进行条件筛选。
es查询的dsl语句中我们是用了hotScore来进行排序的。

但是hotScore从何而来,根据业务去定义,也可以扩展更多类型的评分,让用户去选择如何排序。
这里的hotScore我们假定以点击量来决定热度。
那么我们每次用户点击,将这个评分+1。
1、问题
1、 es大量的写操作会影响es 性能,因为es需要更新索引,而且es不是内存数据库,会做相应的io操作。
2、而且修改某一个值,在高并发情况下会有冲突,造成更新丢失,需要加锁,而es的乐观锁会恶化性能问题。
从业务角度出发,其实我们为商品进行排序所需要的热度评分,并不需要非常精确,大致能比出个高下就可以了。
利用这个特点我们可以稀释掉大量写操作。
2、解决思路
用redis做精确计数器,redis是内存数据库读写性能都非常快,利用redis的原子性的自增可以解决并发写操作。
redis每计10或100次数(可以被10或100整除)我们就更新一次es ,这样写操作就被稀释了10-100倍,这个倍数可以根据业务情况灵活设定。
Redis使用的是zset类型进行热度统计。
商品数据缓存 使用的是String类型。
3、搜索封装更新热度排名接口
讯享网 |
|
4、在service-item模块调用接口
接口调用
讯享网@Service public class ItemServiceImpl implements ItemService { @Autowired private ProductFeignClient productFeignClient; @Autowired private ListFeignClient listFeignClient; @Autowired private ThreadPoolExecutor threadPoolExecutor; @Override public Map<String, Object> getBySkuId(Long skuId) { Map<String, Object> result = new HashMap<>(); ... //获取分类信息 CompletableFuture<Void> categoryViewCompletableFuture = skuCompletableFuture.thenAcceptAsync(skuInfo -> { BaseCategoryView categoryView = productFeignClient.getCategoryView(skuInfo.getCategory3Id()); //分类信息 result.put("categoryView", categoryView); }, threadPoolExecutor); //用户每次访问商品详情时,更新商品热度incrHotScore CompletableFuture<Void> incrHotScoreCompletableFuture = CompletableFuture.runAsync(() -> { listFeignClient.incrHotScore(skuId); }, threadPoolExecutor); CompletableFuture.allOf(skuCompletableFuture, spuSaleAttrCompletableFuture, skuValueIdsMapCompletableFuture,skuPriceCompletableFuture, categoryViewCompletableFuture, incrHotScoreCompletableFuture).join(); return result; } }
常见面试问题
1.Es基础的内容
1.你们项目在es里存了哪些数据?
搜索条件:
分类数据、品牌、平台属性、热度、价格、商品名称(关键字匹配)
展示的结果:
商品id、名称、价格、默认图片
2.ES的倒排索引? (重要)
倒排索引是搜索的关键点,ES通过倒排索引实现搜索。
正排索引:根据id去找到相对应的词
| Id(索引) |
商品名称 |
| 1 |
红海行动 |
| 2 |
红海事件 |
| 3 |
红海行动事件 |
| 4 |
湄公河行动 |
倒排索引:根据词,看这个词都在哪个id文档中出现了
| 商品名称 |
Id(索引) |
| 红海 行动 |
红海1、2、3;行动1、3、4 |
| 红海 事件 |
红海1、2、3;事件2、3 |
| 红海 行动 事件 |
红海1、2、3;行动1、3、4;事件2、3 |
| 湄公河 行动 |
湄公河4;行动1、3、4 |
把指定好需要分词的 列 给进行分词处理,给词创建索引,记录这些词在哪些文档中出现了,当搜索的时候 根据词就能进行匹配,匹配词出现在哪些文档中,把文档数据拿到,实现搜索。
3.ES数据同步问题怎么处理?
商品数据 在MySQL中,ES里也存了商品数据,原本 ES的数据 就是来自于MySQL的。如果 Mysql的商品数据修改了,ES中的是不是还是原来的。这样数据就不一致了。
1.可以修改Mysql的时候 直接修改ES。(不好,耦合了)
Service-product工程修改mysql,直接操作es,由于操作es出问题,导致整个product工程不可用。由于product工程是整个电商中最基础的模块,很多模块都需要远程调用它,它不能因为别人 出问题。
2.可以在 product工程中 远程调用list工程,实现es的修改。 也耦合。
如果远程调用list服务 出问题了,也会影响product工程。
3.使用MQ进行消息通知,当这个product工程修改了mysql之后,发送个消息 通知一下 list(搜 索)工程,product工程就不用管了,该干什么干什么,没影响了。
list(搜索)工程拿到消息后,进行es数据修改。
这种 解耦了。 最终一致。
4、在商品数据修改前 先下架,下架了 ES里就没这个数据了,修改后,再重新上架,ES会重新添加。 好处:强一致。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/39373.html