
1、区别介绍
(1)Scaling
归一化用于将数据归一到某一个范围,如[0,1]或者[0,10],主要是范围上的变化
(2)Normalization
标准化用于改变数据的分布情况,通过将数据分布转变成正态分布
2、适用场景
(1)Scaling
当应用与距离与相似度度量的时候,归一化起到弥足关键的作用,如支持向量机(SVM)和K近邻算法(KNN)
(2)Normalization
当应用要求数据满足正态分布时,对原始数据进行标准化操作,将有利于算法的进行,如线性判别器 (LDA)和高斯朴素贝叶斯(Gaussian naive Bayes)
3、代码实现
(0)导入函数库
#modules we'll use import pandas as pd import numpy as np #for Box-Cox Transformation from scipy import stats #for min_max scaling from mlxtend.preprocessing import minmax_scaling #plotting modules import seaborn as sns import matplotlib.pyplot as plt #set seed for reproducibility np.random.seed(0) 讯享网
(1)Scaling

讯享网#generate 1000 data points randomly drawn from an exponential distribution original_data = np.random.exponential(size=1000) #mix-max scale the data between 0 and 1 scaled_data = minmax_scaling(original_data, columns=[0]) #plot both together to compare fig, ax = plt.subplots(1,2) sns.distplot(original_data, ax=ax[0]) ax[0].set_title("Original Data") sns.distplot(scaled_data, ax=ax[1]) ax[1].set_title("Scaled data")
结果显示

可以从上图中看出,原数据的范围分布在0到8之间,经归一化转变后的数据分布在0到1之间
(2)Normalization
#normalize the exponential data with boxcox normalized_data = stats.boxcox(original_data) #plot both together to compare fig, ax=plt.subplots(1,2) sns.distplot(original_data, ax=ax[0]) ax[0].set_title("Original Data") sns.distplot(normalized_data[0], ax=ax[1]) ax[1].set_title("Normalized data") 结果显示
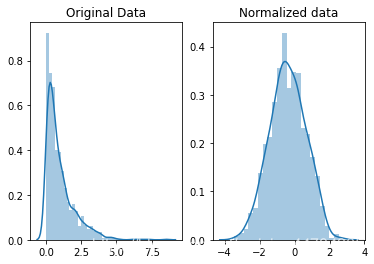
从图中可以看出,经标准化操作后的数据分布服从正态分布
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/37478.html