
*本文信息主要来源于书籍《鲲鹏处理器架构与编程》以及论文《Kunpeng 920: The First 7-nm Chiplet-Based 64-Core ARM SoC for Cloud Services》 *
笔者已然写了一篇上述论文的分析博客,但尚觉论文内容对chiplet架构描述不够清晰,因此查阅《鲲鹏处理器架构与编程》一书,借此文以记录补充内容。
由于书是2020年出版,论文是由鲲鹏设计团队于2021年发表,很多命名、表述不相一致,鄙人觉得以论文描述为主,论文分析请移步:
论文解析——Kunpeng 920…
指令集架构
待补充
处理器chiplet架构

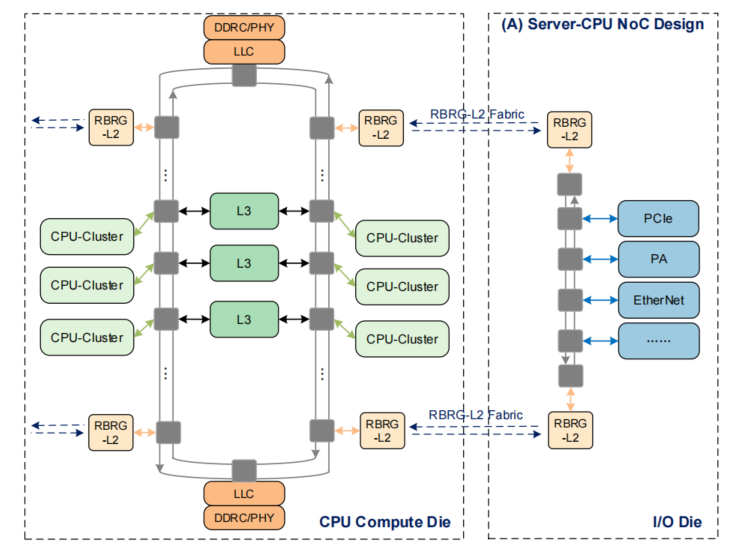
超级内核集群(CPU-compute die)
- 8个CPU集群(cluster)
- 每个CPU集群有4个Taishan V110核,整个die共32个core
- 四路DDR控制器相对摆放
- 双HHA(Hydra Home Agent)用于die内的一致性管理
- GIC用于中断管理
- 双SLLC(super cluster link layer)用于cache一致性的die间通信
- Peri_ICL用于系统功能管理

CCL(core cluster)
- 4 cores / cluster
- 每个core私有 64KB L1i + 64KB L1D
- 每个core私有 512KB L2
- 单CPU cluster共享LLC TAG,LLC DATA则挂载在NoC网络中与该cluster最近的L3 DATA

- cluster内共享L3:tag cache + data cache
- tag cache:存储tag,减少监听延迟;4个core共享tag cache
- data cache:存数数据,获得大容量;data cache分割为4份给4个core使用

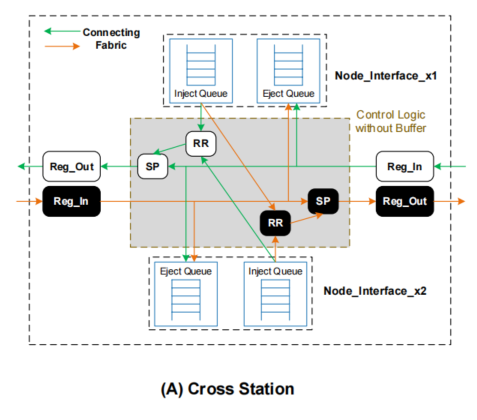
交叉站(Cross station)可以访问两个方向ring的flit,每个CS可以连接两个节点,每个节点都已一个弹入队列和一个弹出队列。弹入队列可以将flit注入到两个方向ring中,弹出队列可以接收两个方向ring中的flit,两个队列都可以访问两个方向的ring是为了保证以最短的路由路径获得flit。
CS的两个节点在kunpeng920中可以连接CPU-cluster和L3 data,两个节点的弹入队列中的报文片通过轮询(round-Robin)的方式注入到ring中。
POE_ICL
系统配置的硬件加速器,一般用作分组顺序整理器、消息队列、消息分发或者实现某个处理器内核的特定任务。
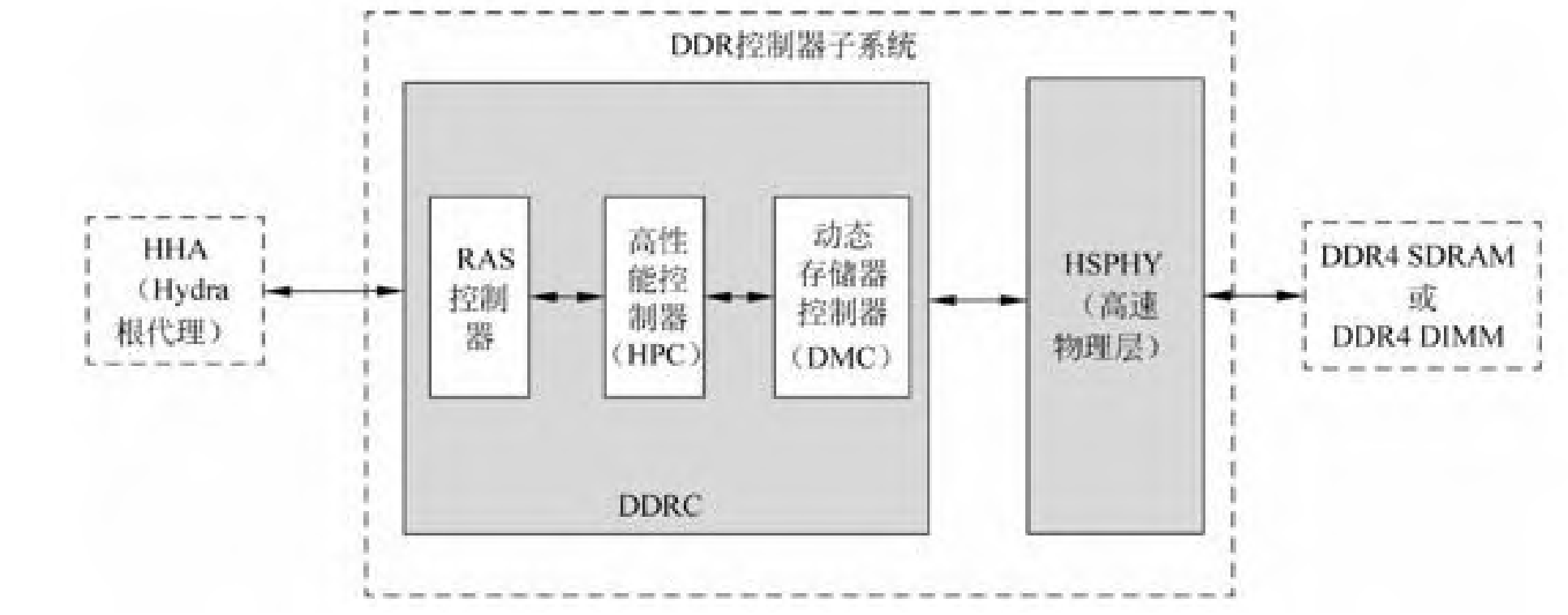
主存系统:DDR控制器 + Hydra根代理(HHA)
在鲲鹏处理器架构中,由主存系统维护die间和片间数据一致性,该一致性的协议标准即为HCCS。
超级IO集群(Compute-IO die)

ICL的内部结构
每个ICL包含系统总线接口、系统存储管理单元SMMU(可选)、用于初始化的系统控制部件(由firmware使用)、若干调度器、分发器等
如图是compute-IO die的ICL数据流

HAC_ICL:海思自研加速控制器
除了ICL的基本模块,主要集成了硬件安全加速引擎、压缩/解压加速引擎等

IO_MGMT_ICL:集成了USB、RAS等加速引擎的组合部件
IMU
智能管理单元,负责整个芯片管理的部件,独立于鲲鹏处理器的计算应用系统。

die内互连网络(NoC)
每个超级集群内的子系统通过ring Bus互连互通,结合各类数据传输接口、管理单元共同构成了片上网络。
完整的片上网络由环总线、SLLC、调度器(scheduler)和分发器(Dispatch)等模块组成。
compute-die内NoC设计和Intel的Tigerlake架构的NoC设计1类似。
环总线
调度器
ICL特有器件,调度以及汇集ICL内多个设备的访存请求并有序传递到SMMU中,经过地址转换后接入ring bus的CS,将数据流量映入片上系统的其他部件。调度器也可以调整设备下发命令的服务质量,也可以对设备流量进行限制。
例如若设备需进行DMA访问,则则系统地址空间主动发起读写操作请求,并向调度器发出汇聚这些操作的请求,系统管理单元处理这一请求后使用物理地址访问总线。
分发器
die间互连:SLLC接口
超级集群(die)间通过超级集群链路层连接器(SLLC)互连。
SLLC连接多个die的环总线通路,将一个die的环总线数据按照约定的路由传输到另一个die的环总线中。
由于die内数据流量大于die间的流量,因此SLLC的带宽一般小于ring bus提供的最高带宽。
由于ring bus的data width更大,因此SLLC需要将数据分组打包并压缩后才进行传输。
片间互连:Hydra接口
协议适配层(Protocol Adapter, PA)
PA模块的主要特征
- CHI和Hydra间数据格式的转换
- 片间发送端请求缓冲区管理
- 片间接收端地址相关性检测
- 片间数据一致性处理
- 与环总线以及链路层(HLLC)间的流控处理
- 片间流量统计
Hydra接口链路层控制器(HLLC)
完成Hydra协议数据在serdes物理通道上的数据格式适配;在发送端完成Hydra协议中个逻辑通道的数据调度和CRC嵌入;在接收端完成CRC校验和来自发送端各通道的数据分发
NoC中的地址译码组件
鲲鹏架构将寻址译码分为3个层次,逐级的将访问分配到对应设备
- 一级译码集成在访问请求进入ring bus接口前,译码指示正确的环总线端口
- 二级译码集成在各ICL的分发器内,译码指示ICL内正确的分发器出口
- 三级译码继承咋使用共享总线的分发器出口处,译码结果指示具体的设备
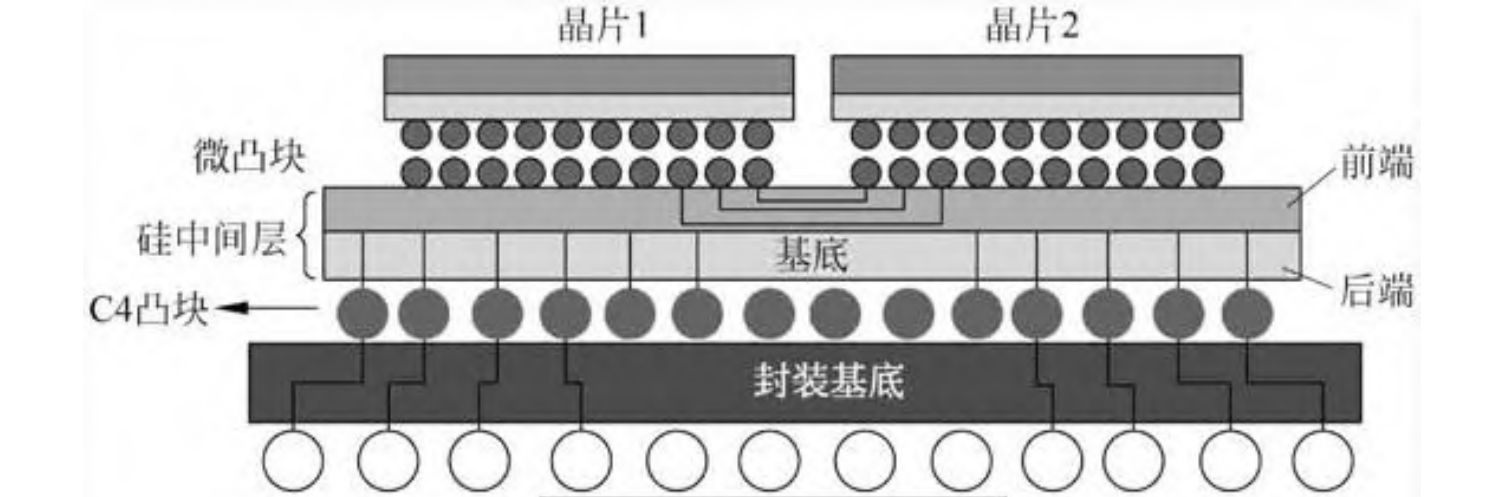
chiplet封装
采用CoWoS封装,die间双向通信带宽高达300GB/s以上
鲲鹏的软件编程框架
片上系统的NUMA架构
参考文献
- 知乎:老狼:从Ring Bus到Mesh网络CPU片内总线的进化之路
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/37105.html