
目录
前言
CREATE创建节点并创建关系
创建多条关系
对已存在的节点创建关系
批量创建节点
关系的规范
使用MATCH进行条件匹配
多标签匹配
以路径的形式返回节点和边的关系
使用函数id / labels返回节点id和标签
使用DELETE删除指定的节点或者关系
使用SET更新属性或者标签
使用REMOVE删除指定的属性或者标签
使用MERGE避免重复插入节点
使用UNION / UNION ALL做联合查询
使用order by / skip / limit对查询结果做处理
使用distinct进行去重
使用is null和is not null判断属性是否存在
使用in和or做范围查询
使用case when做条件分支处理
使用字符串函数
使用数学函数
查看关系起点和终点,以及关系类型
创建/删除索引和约束
查看索引和约束
关系的条件查询
返回List
返回Map
尽量使用OPTIONAL MATCH
使用最短路径函数shortestPath
写在最后
前言
本文演示常见的Cypher操作,默认每个代码块对应一条Cypher语句,但为了展示多条Cypher之间的相关性,可能会将多条Cypher放到一个代码块中,并通过‘;’进行隔开。由于一个完整的Cypher中不用包含‘;’,所以实际执行时,请按照';'分割后逐条执行。
本文比较重点的文字部分通过阴影背景标注出来,所有代码均测试通过,Neo4j的版本为3.5.4,如果你的版本更高,那么肯定是兼容的。
CREATE创建节点并创建关系
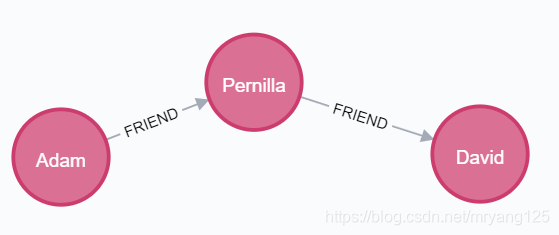
1)方案1,以路径的形式进行创建。
CREATE (adam:User {name: 'Adam'})-[:FRIEND]->(pernilla:User {name: 'Pernilla'})-[:FRIEND]-> (david:User {name: 'David'}) return adam,david,pernilla讯享网
2)方案2,节点和关系平行创建。
讯享网CREATE (adam:User {name: 'Adam'}), (pernilla:User {name: 'Pernilla'}), (david:User {name: 'David'}), (adam)-[:FRIEND]->(pernilla), (pernilla)-[:FRIEND]->(david) return adam,david,pernilla
不管哪种方案,执行结果都是一样的。注意:
在create语句中,return子句不是必须的。
如果使用了return子句,默认的,在仅返回节点的情况下,如果节点之间包含了关系,那么也会将关系一起返回。
创建多条关系
CREATE (andrew:User {name: 'Andrew'}), (peter:User {name: 'Peter'}), (andrew)-[:FRIEND]->(peter), (andrew)-[:BROTHER]->(peter) return andrew, peter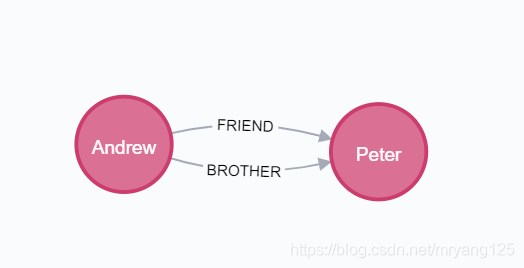
对已存在的节点创建关系
先查询出节点,后创建关系即可。
讯享网CREATE (tony:User {name: 'Tony'}), (hank:User {name: 'Hank'}) return tony, hank
MATCH (tony:User {name: 'Tony'}), (hank:User {name: 'Hank'}) CREATE (tony)-[r:CUT_HAIR]->(hank) return tony, hank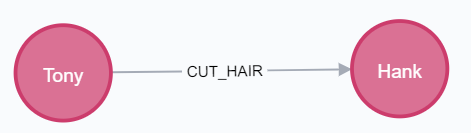
批量创建节点
使用unwind,声明多个节点的集合,再执行create
讯享网UNWIND [{name:"Lisi"},{name:"Zhangsan"}] AS mynodes CREATE (n:Person) SET n = mynodes
关系的规范
关系的箭头可以是朝左,也可以是朝右,但不能既朝左又朝右。
创建关系时,不必指定别名,但必须指定方向,且必须指定关系类型。
如下,前三个是正确的,最后三个是错误的。
CREATE (tony:User {name: 'Tony'})-[r:CUT_HAIR]->(hank:User {name: 'Hank'}) return tony, hank; CREATE (tony:User {name: 'Tony'})<-[r:CUT_HAIR]-(hank:User {name: 'Hank'}) return tony, hank; CREATE (tony:User {name: 'Tony'})<-[:CUT_HAIR]-(hank:User {name: 'Hank'}) return tony, hank讯享网CREATE (tony:User {name: 'Tony'})<-[r:CUT_HAIR]->(hank:User {name: 'Hank'}) return tony, hank; CREATE (tony:User {name: 'Tony'})-[]->(hank:User {name: 'Hank'}) return tony, hank; CREATE (tony:User {name: 'Tony'})-[:]->(hank:User {name: 'Hank'}) return tony, hank
匹配关系时,可以不指定箭头,也可以不指定关系类型,甚至可以不指定别名。在不指定箭头的情况下,系统匹配任意方向的关系。在不指定类型的情况下,系统匹配任意类型的关系。
MATCH (tony:User {name: 'Tony'}) -[r]-(hank:User {name: 'Hank'}) return tony, hank
使用MATCH进行条件匹配
MATCH匹配可以通过标签内属性来筛选,也可以通过where来筛选。标签内属性筛选一定能够转成where筛选,但是where筛选不一定能够转成标签内属性筛选。
下面两组Cypher分别等价。
讯享网MATCH (stu:Student{name:'LiMing'}),(u:User{name:'LiMing'}) MATCH (u)<-[s:SAME_NAME{name: u.name}]-(stu) RETURN stu, u; MATCH (stu:Student),(u:User) WHERE stu.name ='LiMing' and u.name = 'LiMing' MATCH (u)<-[s:SAME_NAME{name: u.name}]-(stu) RETURN stu, u
MATCH (book:Book{ id:123,title:"Neo4j Guide"}) return book; MATCH (book:Book) where book.id = 122 and title="Neo4j Guide" return book下面的这个Cypher无法转成标签内属性筛选。
讯享网MATCH (stu:Student)-[s:SAME_NAME{name: u.name}]->(u:User) where stu.name = u.name return stu, u
多标签匹配
返回同时包含多个标签的节点,可以在节点中声明,也可以在where中声明。
match (n:Person:User) return n讯享网match (n) where n:Person:User return n
以路径的形式返回节点和边的关系
路径是节点和关系的组合
MATCH p = (stu:Student)-[s:SAME_NAME{name: u.name}]->(u:User) where stu.name = u.name return p使用函数id / labels返回节点id和标签
Neo4j中,在没定义唯一约束的情况下,每次执行create,都会创建新的节点或者关系,但是节点或者关系的id始终是唯一的。通过id函数可以获取节点的唯一id,通过labels函数可以获取节点的所有标签。
创建两个同名的‘川普‘节点,以下Cypher执行两次,可以看出<id>是不同的
讯享网CREATE (u:User{name:'Trump'})
MATCH (u:User) where u.name='Trump' return id(u)| id(u) |
|---|
| 318 |
| 357 |
讯享网MATCH (u:User) where u.name='Trump' return labels(u)
| labels(u) |
|---|
| ["User"] |
| ["User"] |
使用DELETE删除指定的节点或者关系
如果当前需要删除的节点和其它节点具有关系,那么必须先删除关系,然后才能删除节点。否则直接删除即可。
MATCH (u:User) where id(u)=318 delete u讯享网MATCH (stu:Student)-[s:SAME_NAME{name: u.name}]->(u:User) where id(s) = 443 delete s
使用SET更新属性或者标签
set不仅仅可以用来更新属性,也可以用来为节点新增一个不存在的属性,更重要的是它可以为已存在的节点添加新的标签。
create (book:Book{ id:123,title:"Neo4j Guide", price:119.5}) return book; match (book:Book{ id:123,title:"Neo4j Guide"}) set book.title='Neo4j Guide 2nd' return book新增属性
讯享网match (book:Book{ id:123,title:"Neo4j Guide"}) where id(book)=317 set book.pages = 200 return book
set可以添加标签
create (u:User{name:"Mask"}) return u; match (u:User{name:"Mask"}) set u:User:Person使用REMOVE删除指定的属性或者标签
不同于delete,remove仅仅可以删除属性或者标签
删除其中一条属性
讯享网match (book:Book{ id:123,title:"Neo4j Guide"}) remove book.price return book
删除其中一个标签
match(u:User{name:"Mask"}) remove u:Person使用MERGE避免重复插入节点
merge类似于create,但是连续执行create操作会插入属性重复的节点,连续执行merge能够避免这个问题。
merge判重的依据是节点属性数量一致,值也一致,才认为重复。
例如重复执行下面一条语句,最终只会生成一个节点。
讯享网MERGE (gp2:GoogleProfile2{ Id: ,Name:"Nokia"})
但是如果执行了上述语句,再执行下面语句,会生成两个节点
MERGE (gp2:GoogleProfile2{ Id: ,Name:"Nokia",addr:"Beijing"})使用UNION / UNION ALL做联合查询
UNION 的作用是将两个结果集的拼在一起。
使用UNION / UNION ALL时,列名必须一致,一般情况下必须使用 as 指定相同的列名,因为列名是前缀.属性名。
UNION可过滤重复记录, UNION ALL 不能过滤重复记录。

以下两个Cypher分别返回了48和20条记录。
讯享网match (m:Member) return m.m_name as name, m.m_age as age, m.m_addr as addr union all match (u:User) return u.name as name, u.age as age, u.addr as addr
match (m:Member) return m.m_name as name, m.m_age as age, m.m_addr as addr union match (u:User) return u.name as name, u.age as age, u.addr as addr使用order by / skip / limit对查询结果做处理
order by 默认按照升序(asc)排序,可指定为desc。如果一个match中没有order by,那么Neo4j默认按照节点的id升序排序。
skip 从起始位置开始忽略指定的记录数。
limit 限制返回的条数。
当这几个关键字同时存在时,优先级顺序为 order by > skip > limit。如:
讯享网match (m:Member) return m
| id(m) | m.age |
|---|---|
| 331 | 21 |
| 364 | 33 |
| 367 | 20 |
match (m:Member) where m.age >= 20 return m order by m.age skip 1 limit 2| id(m) | m.age |
|---|---|
| 331 | 21 |
| 364 | 33 |
使用distinct进行去重
讯享网MATCH (a:User)-[]->(b:User) RETURN DISTINCT b.name
| b.name |
|---|
| "herry" |
| "mask" |
| "Perter" |
| "Pernilla" |
| "David" |
| "Hank" |
| "Berlin" |
| "Donload" |
| "Peter" |
| "Tony" |
使用is null和is not null判断属性是否存在
null表示不存在,Neo4j中不会存储null值的属性。
在没有使用optional match的情况下,属性的值不可能为null。
如果一个节点存在某个属性,那么这个属性的值必定不为null,所以 null 仅仅是用来判断属性是否存在的,并不是用来判断这个属性的值是否为null。
例如,查询Member中,没有city这个属性的节点:
match (m:Member) where m.city is null return m使用in和or做范围查询
类似于MySQL,in 和 or 的用法一致,但在Neo4j中用[ ]来指定in的范围。
讯享网MATCH (n:Member) where n.name in ['jerry', 'Harvy'] or n.age = 21 RETURN n LIMIT 25

使用case when做条件分支处理
类似于MySQL的case when,可以根据不同的条件返回不同的结果,以达到if else的效果。
MATCH (n:Member) RETURN CASE n.name WHEN 'jerry' THEN 'j' WHEN 'mask' THEN 'm' ELSE 'who' END AS result使用字符串函数
常见的字符串函数,如转大写,转小写,字符串截取。
讯享网match (u:User) return upper(u.name), lower(u.name), substring(u.name, 0,1)

使用数学函数
常见的数学函数,如求数量,求最大值,求最小值,求总和,求平均值。
match (u:User) return count(*), min(u.age), max(u.age), sum(u.age), avg(u.age)
查看关系起点和终点,以及关系类型
若以关系r为参数,则type(r)返回关系类型,startNode(r)返回关系起点,endNode(r)返回关系终点。
讯享网match (u1:User)-[f:FRIEND] ->(u2:User) return f, id(f), type(f), startNode(f), endNode(f)

创建/删除索引和约束
Neo4j也提供索引机制,类似于MySQL的索引,可以加快匹配过程,实际的生产环境中必须按照查询的属性建立索引。建立了索引,也会占用额外的磁盘空间。
约束(CONSTRAINT)和索引(INDEX)的关系:
约束也是索引,但索引不一定是约束。如果对某个属性创建了约束,那么无法再次对该属性创建索引。
Neo4j在3.x的版本创建索引时无法自定义索引名称,在4.x的版本中可以自定义索引名称,但索引名称必须唯一。
如果节点的某个属性创建了索引,那么使用该属性的查询不用显示声明即可走索引查询。
社区版Neo4j仅支持唯一约束 Unique node property constraints,即约束属性值必须唯一。
企业版Neo4j不仅支持唯一约束还支持属性非空约束,即通过EXISTS约束属性必须存在,包含三类:
Node property existence constraints 节点属性必须存在
Relationship property existence constraints 关系属性必须存在
Node key constraints 节点的属性必须存在,且属性的值必须唯一
创建/删除单属性索引:
CREATE INDEX ON :User(name)讯享网DROP INDEX ON :User(name)
创建/删除多属性索引,即组合索引:
CREATE INDEX ON :Person(name, age)讯享网DROP INDEX ON :Person(name, age)
创建/删除约束。
CREATE CONSTRAINT ON (u:Member) ASSERT u.name IS UNIQUE讯享网DROP CONSTRAINT ON (member:Member) ASSERT member.name IS UNIQUE
查看索引和约束
查看索引有两种方式:call db.indexes 和 :schema。前者会提供更加详细的信息,但通常情况下使用:schema就够了。
查看约束的方式:call db.constraints。
索引的状态state标识索引是否正常,如果是ONLINE意味着索引正常,如果是OFFLINE那么索引异常。异常状态下查询无法走索引。
如果某天你查询Neo4j的接口响应缓慢,优先检查索引是否存在,索引是否是ONLINE状态。
分别执行这三个函数,可以看出不同点



关系的条件查询
1)存在关系类型为ROOMATE或者BROTHER的节点组
match (u:User),(u1:User) where (u)-[:ROOMATE|BROTHER]-(u1) return u,u12)查询具有一条或者两条ROOMATE关系的节点
讯享网match (a:User)-[:ROOMATE*1..2]->(b:User) return a, b
3)指定查询具有两条ROOMATE关系的节点
match (a:User)-[:ROOMATE*2]->(b:User) return a, b返回List
讯享网RETURN [x IN range(0,10) WHERE x % 2 = 0 | x^3] AS result
| result |
|---|
| [0.0, 8.0, 64.0, 216.0, 512.0, 1000.0] |
这段Cypher实际上是分两阶段执行,首先执行:
RETURN [x IN range(0,10) WHERE x % 2 = 0] AS result| result |
|---|
| [0, 2, 4, 6, 8, 10] |
然后对集合中的每个元素取立方即可。
| 在List中的操作并不是 or 的意思,应该理解成Linux中的管道流更加合适。
返回Map
数据准备,执行以下Cypher
讯享网create (p:Person{name:"Martin Sheen"}); create (p:Person{name:"Charlie Sheen", realName:"Carlos Irwin Estévez"}); create (p:Movie{title:"Wall Street", year:1987}); create (p:Movie{title:"Red Dawn", year:1984}); create (p:Movie{title:"Apocalypse Now", year:1979}); match(p:Person{name:"Martin Sheen"}), (m:Movie{year:1987}) create (p)-[:ACTED_IN]->(m); match(p:Person{name:"Martin Sheen"}), (m:Movie{year:1979}) create (p)-[:ACTED_IN]->(m); match(p:Person{name:"Charlie Sheen"}), (m:Movie{year:1979}) create (p)-[:ACTED_IN]->(m); match(p:Person{name:"Charlie Sheen"}), (m:Movie{year:1987}) create (p)-[:ACTED_IN]->(m); match(p:Person{name:"Charlie Sheen"}), (m:Movie{year:1984}) create (p)-[:ACTED_IN]->(m);
1)现在统计Charlie Sheen所演出的电影列表
MATCH (actor:Person {name: 'Charlie Sheen'})-[:ACTED_IN]->(movie:Movie) RETURN actor { .name, .realName, movies: collect(movie { .title, .year })}| actor |
|---|
讯享网 |
注意这种结构:a{.x, x1:y1},它表示创建一个map,.x表示取a自身的属性,x1表示自定义的key,y1往往是一种经过聚合运算的数据结构。
这个例子中 RETURN actor { .name, .realName, movies: collect(movie { .title, .year })},表示返回actor的name和realName属性,并返回
新的属性,键为movies,值为一个title和year组成的集合。
上面的Cypher通过with关键字转换成如下也可以实现一样的效果,with用来传递临时变量。
MATCH (actor:Person {name: 'Charlie Sheen'})-[:ACTED_IN]->(movie:Movie) WITH actor, collect(movie { .title, .year }) AS movies RETURN actor { .name, movies }2)统计所有Person中出演过电影(Movie)的演员,及其出演的电影数量
讯享网MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie) WITH actor, count(movie) AS nrOfMovies RETURN actor { .name, nrOfMovies }
| actor |
|---|
|
讯享网 |
|
尽量使用OPTIONAL MATCH
使用match,如果没有记录,会返回无记录,而添加optional match,如果无记录则会返回null,相当于SQL中的outer join。
optional match通常用于组合查询的场景中,如果组合查询的某个子句为无记录,而其它子句有记录,那么使用match只会返回无记录,但使用optional match就可以返回null和其他记录的组合结果。
执行以下Cypher,即使第二个MATCH中无记录,也会返回结果
讯享网MATCH (a:Movie { title: 'Wall Street' }) OPTIONAL MATCH (a)-[r:ACTS_IN]->() RETURN a.title, r
| a.title | r |
|---|---|
| "Wall Street" | null |
如果我们去掉OPTIONAL,则所有结果都不会返回
MATCH (a:Movie { title: 'Wall Street' }) MATCH (a)-[r:ACTS_IN]->() RETURN a.title, r(no changes, no records)
使用最短路径函数shortestPath
shortestPath可以返回两个节点的最短路径。
例如有一些列如下的节点

现在需要返回Martin Sheen和Oliver Stone的最短路径,显然二者本身具有FRIEND关系,那么最短路径就是这个关系的路径。
Cypher如下, 其中[*..15]表示最多不超过15条边的路径。
讯享网MATCH (martin:Person { name: 'Martin Sheen' }),(oliver:Person { name: 'Oliver Stone' }), p = shortestPath((martin)-[*..15]-(oliver)) RETURN p

写在最后
本文虽然叫Cypher实战,但是只展示了Cypher的常见操作,将其理解成一篇笔记更加合适。实际上Cypher可以做更多,更复杂的操作,要深入理解并掌握透彻,官方文档才是最好的教材。我曾经花3天把Cypher操练手册看完并敲了一遍,那感觉才叫酸爽,但鉴于实际开发中用不了多少,还是会容易忘记。所以,持续学习才是硬道理。
最后,如果你的问题在我这里没有找到解决方案,或者有任何的想法,不妨在评论区留言,我们一起进步。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/36855.html