
背景:
对于其他数据存储系统来说,统计表的行数是再基本不过的操作了,一般实现都非常简单;但对于HBase这种key-value存储结构的列式数据库,统计 RowCount 的方法却有好几种不同的花样,并且执行效率差别巨大!下面来研究下吧~
测试集群:HBase1.2.0 - CDH5.13.0 四台服务器
注:以下4种方法效率依次提高
一、hbase-shell的count命令
这是最简单直接的操作,但是执行效率非常低,适用于百万级以下的小表RowCount统计!
讯享网
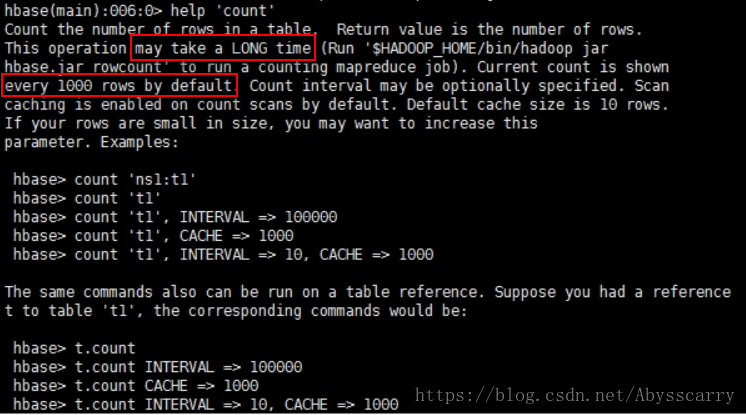
hbase> count 'ns1:t1' hbase> count 't1' hbase> count 't1', INTERVAL => hbase> count 't1', CACHE => 1000 hbase> count 't1', INTERVAL => 10, CACHE => 1000 讯享网
此操作可能需要很长时间,来运行计数MapReduce作业。默认情况下每1000行显示当前计数,计数间隔可自行指定。
默认情况下在计数扫描上启用缓存,默认缓存大小为10行。

行数为 3000W 的表测试结果:
讯享网hbase(main):001:0> count 'sda_crm_calls'
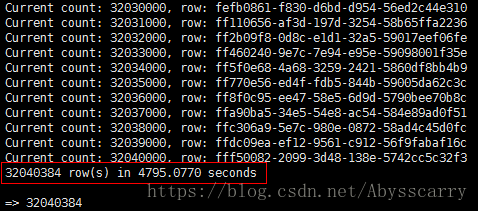
默认INTERVAL为1000行时花了80分钟。。
hbase(main):001:0> count 'sda_crm_calls', INTERVAL => 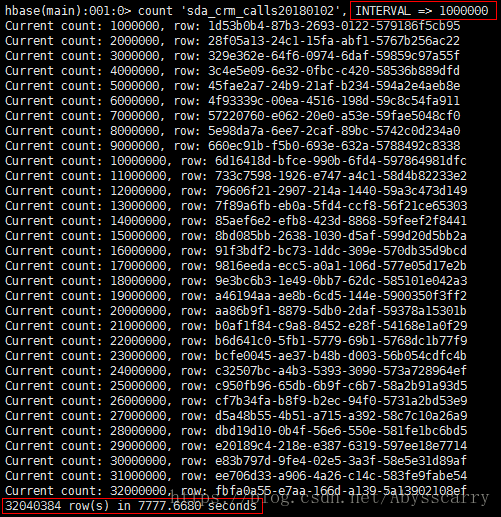
INTERVAL为行时花了130分钟。。
二、scan方式设置过滤器循环计数(JAVA实现)
这种方式是通过添加 FirstKeyOnlyFilter 过滤器的scan进行全表扫描,循环计数RowCount,速度较慢! 但快于第一种count方式!
基本代码如下:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/36565.html