
这篇文章是以色列开发人员塔利·加希尔的研究成果。她在查阅了所有公开发布的关于浏览器内部机制的数据,并花了很多时间来研读网络浏览器的源代码。她写道:
在 IE 占据 90%市场份额的年代,我们除了把浏览器当成一个“黑箱”,什么也做不了。但是现在,开放源代码的浏览器拥有了过半的市场份额,因此,是时候来揭开神秘的面纱,一探网络浏览器的内幕了。呃,里面只有数以百万行计的C++ 代码…
本篇文章的英文原版:How Browsers Work: Behind the Scenes of Modern Web Browsers。
本文主要参考和更新自下面两篇译文:
1)前端必读:浏览器内部工作原理
2)前端文摘:深入解析浏览器的幕后工作原理
第一章 简介
浏览器是使用最广的软件之一。在这篇博文中,我将介绍浏览器的幕后工作原理。通过阅读本文,我们将会了解,从您在地址栏输入 google.com ,直到您在浏览器屏幕上看到 Google 首页的整个过程中都发生了些什么。
1.1 讨论的浏览器
目前使用的主流浏览器有五个:Internet Explorer、Firefox、Safari、Chrome和 Opera浏览器。本文主要以开源浏览器为主进行分析,即 Firefox、Chrome和 Safari(部分开源)。根据 StatCounter 浏览器统计数据,目前(2016年 2 月)Firefox(14.67%)、Safari(9.46%)和 Chrome(55.33%) 浏览器的总市场占有率将近 80%(这个数字在2011年8月的时候,才将近60%)。由此可见,如今开源浏览器在浏览器市场中占据绝大多数的市场份额。
1.2 浏览器的主要功能
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示您想要访问的网络资源。这里所说的资源一般是指 HTML 文档,也可以是 PDF、图片或其他的类型。资源的位置由用户使用 URI(统一资源标示符)指定。
浏览器解释并显示HTML文件的方式是在 HTML 和 CSS 规范中指定的。这些规范由网络标准化组织 W3C(万维网联盟)进行维护。多年以来,各浏览器都没有完全遵从这些规范,同时还在开发自己独有的扩展程序,这给网络开发人员带来了严重的兼容性问题。如今,大多数的浏览器都开始尽量遵从规范。
1.3 浏览器的高层结构(High Level Structure)
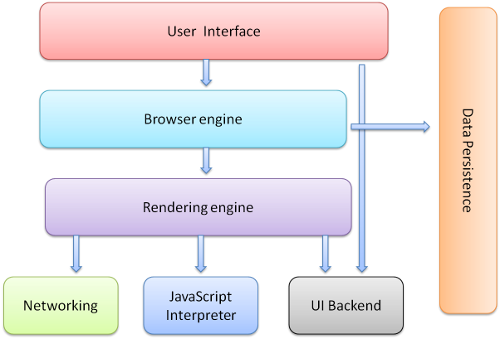
浏览器的主要组件包括:
- 用户界面 - 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的你请求的页面外,其他显示的各个部分都属于用户界面。
- 浏览器引擎 - 在用户界面和渲染引擎之间传送指令。
- 渲染引擎 - 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端 - 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器。用于解析和执行 JavaScript 代码,比如chrome的javascript解释器是V8。
- 数据存储。这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5)定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。

讯享网
图1.1:浏览器的主要组件。 值得注意的是,不同于大多数浏览器,Chrome 浏览器为每个标签页(Tab)都分配了各自的渲染引擎实例,每个标签页都是一个独立的进程(即每个标签页面都在独立的“沙箱”内运行,在提高安全性的同时,一个标签页面的崩溃也不会导致其他标签页面被关闭)。
对于构成浏览器的这些组件,后面会逐一详细讨论。
第二章 渲染引擎(The rendering engine)
渲染引擎的职责就是渲染,即在浏览器窗口中显示所请求的内容。这是每一个浏览器的核心部分,所以渲染引擎也称为浏览器内核。
默认情况下,渲染引擎可显示 HTML 和 XML 文档及图片。通过插件(或浏览器扩展程序),还浏览器渲染引擎也可以显示其它类型的内容。例如,使用 PDF 查看器插件就能显示 PDF 文档。在本章中,我们将集中介绍其主要用途:显示应用了CSS的 HTML 内容和图片。
2.1 渲染引擎简介
本文所讨论的浏览器(Firefox、Chrome和Safari)是基于两种渲染引擎构建的。Firefox 使用的是 Gecko,这是 Mozilla 公司“自制”的渲染引擎。而 Safari 和 Chrome(28版本以前)浏览器使用的都是 Webkit。
2013年7月10日发布的Chrome 28 版本中,Chrome浏览器开始正式使用Blink内核。所以,Webkit已经成为了Chrome浏览器的前内核。
Webkit 是一种开放源代码渲染引擎,起初用于 Linux 平台,随后由 Apple 公司进行修改,从而支持苹果机和 Windows。有关详情,请参阅 webkit.org。
2.2 主流程(The main flow)

渲染引擎解析HTML文档,并将文档中的标签转化为dom节点树,即”内容树”。同时,它也会解析外部CSS文件以及style标签中的样式数据。这些样式信息连同HTML中的”可见内容”一道,被用于构建另一棵树——”渲染树(Render树)”。
渲染树由一些带有视觉属性(如颜色、大小等)的矩形组成,这些矩形将按照正确的顺序显示在频幕上。
渲染树构建完毕之后,将会进入”布局”处理阶段,即为每一个节点分配一个屏幕坐标。再下一步就是绘制(painting),即遍历render树,并使用UI后端层绘制每个节点。
值得注意的是,这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
主流程示例
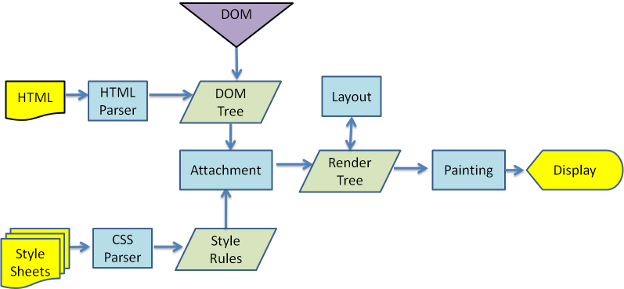

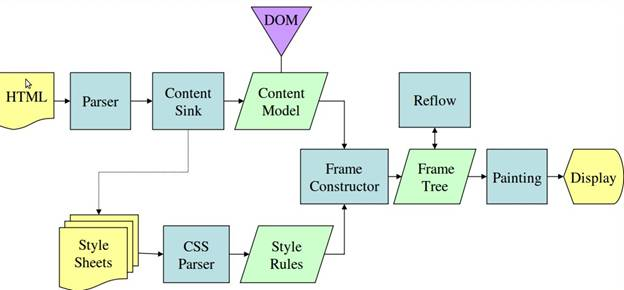
从图2.2 和图2.3可以看出,虽然 Webkit 和 Gecko 使用的术语略有不同,但整体流程还是基本相同的。
- Gecko将视觉格式化元素组成的树称为”框架树”(frame)。每个元素都是一个框架。Webkit使用的术语是”渲染树”(render),它由”渲染对象”组成。
- 对于元素的放置,Webkit 使用的术语是”布局”(layout),而 Gecko 称之为”重排”(reflow)。
- Webkit称利用dom节点及样式信息去构建render树的过程为attachment,Gecko在html和dom树之间附加了一层,这层称为内容接收器,相当制造dom元素的工厂。
我们会逐一论述流程中的每一部分:
第三章 解析与DOM树构建(Parsing and DOM tree construction)
3.1 解析(Parsing-general)
1.文法(Grammars)
解析是以文档所遵循的语法规则(编写文档所用的语言或格式)为基础的。所有可以解析的格式都必须对应确定的语法(由词汇和语法规则构成)。这称为与上下文无关的文法。人类语言并不属于这样的语言,因此无法用常规的解析技术进行解析。
2.解析器-词法分析器(Parser-Lexer combination)
解析一般可分为两个子过程:语法分析和词法分析。
语法分析指对语言应用语法规则。
词法分析就是将输入分解为符号,符号是语言的词汇表——基本有效单元的集合。对于人类语言来说,它相当于我们字典中出现的所有单词。
解析工作一般由两个组件共同完成:
1)词法分析器(有时也称为标记生成器),负责将输入内容分解成一个个有效标记。词法分析器知道如何将无关的字符(比如空格和换行符)分离出来。;
2)解析器负责根据语言的语法规则分析文档的结构,从而构建解析树。
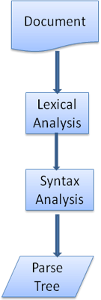
解析是一个迭代的过程。通常,解析器会向词法分析器请求一个新标记,并尝试将其与某条语法规则进行匹配。如果发现了匹配规则,解析器会将一个对应于该标记的节点添加到解析树中,然后继续请求下一个标记。
如果没有规则与该标记匹配,解析器就会将标记存储到内部,并继续请求下一个标记,直至找到可与所有内部存储的标记匹配的规则。
如果没有规则(即没有找到相应的语法规则),解析器就会引发一个异常。这意味着文档无效,包含语法错误。
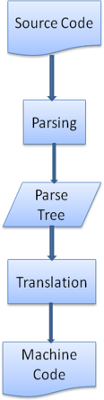
3.转换(Translation)
很多时候,解析树还不是最终结果。解析通常是在转换过程中使用的,而转换是指将输入文档转换成另一种格式。编译就是一个例子。编译器可将源代码编译成机器代码,具体过程是首先将源代码解析成解析树,然后将解析树翻译成机器代码文档。
4.解析示例(Parsing example)
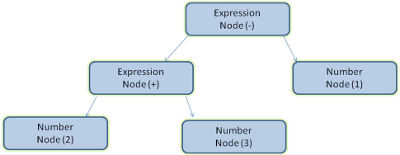
在图3.1中,我们通过一个数学表达式建立了解析树。现在,让我们试着定义一个简单的数学语言,用来演示解析的过程。
词汇表:我们用的语言可包含整数、加号和减号。
语法规则:1)构成语言的语法单位是表达式、项和运算符。2)该语言可以包括多个表达式。3)一个表达式定义为两个项通过一个操作符连接。4)运算符可以是加号或减号。5)项可以是一个整数或一个表达式。
现在来分析一下”2+3-1”这个输入。
匹配语法规则的第一个子串是2,而根据第5条语法规则,这是一个项。匹配语法规则的第二个子串是 2 + 3,而根据第 3 条规则(一个项接一个运算符,然后再接一个项),这是一个表达式。下一个匹配项已经到了输入的结束。2 + 3 - 1 是一个表达式,因为我们已经知道 2 + 3 是一个项,这样就符合“一个项接一个运算符,然后再接一个项”的规则。2 + +不与任何规则匹配,因此是无效的输入。
5.词汇和语法的正式定义
- 1)词汇通常用正则表达式表示。
例如,我们的示例语言可以定义如下:正如您所看到的,这里用正则表达式给出了整数的定义。
INTEGER :0|[1-9][0-9]* PLUS : + MINUS: -
讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/36481.html