
NLP自然语言处理
一、形式语言和自动机(源码)
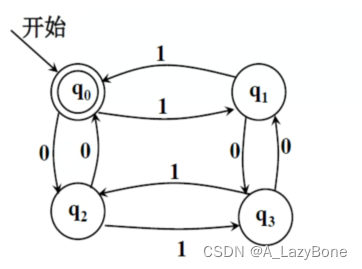
- 请设计程序实现如下有限自动机,并输入三个不同的字符串,对字符串进行合法性检测(即判断字符串中的字符是否在输入符号集中),之后由有限自动机判断字符串是否被接受。
- 状态集:{q0,q1,q2,q3} (可用其他字符代替)
- 输入符号集:{0,1}
- 初始状态:q0 终止状态:q0
- 状态转移函数:

讯享网 - 利用简单循环实现
for(int i=0; i<strlen(str); i++){ if(str[i]!='0' && str[i]!='1'){ cout<<"字符串中的字符不在输入符号集中"<<endl; flag=1; break; } if(str[i]=='1'&&statment==0) statment=1; else if(str[i]=='0'&&statment==0) statment=2; else if(str[i]=='0'&&statment==1) statment=3; else if(str[i]=='1'&&statment==1) statment=0; else if(str[i]=='0'&&statment==2) statment=0; else if(str[i]=='1'&&statment==2) statment=3; else if(str[i]=='0'&&statment==3) statment=1; else if(str[i]=='1'&&statment==3) statment=2; } 讯享网

二、二元文法模型(源码)
- 使用免费的中文分词语料库,如人民日报语料库PKU,使用语料库中的常见词编写一个句子,使用二元语法(即每个词只与和它相邻的前一个词有关)在语料库中对句子中的词进行词频统计,输出句子的出现概率。
- 简单使用二维数组构建语料库,并循环遍历语料库,此方法仅适用于小型语料库,不适合大型语料库。

讯享网string Langue[3][5]={
{"<BOS>","商品","和","服务","<EOS>"}, {"<BOS>","商品","和服","物美价廉","<EOS>"}, {"<BOS>","服务","和","货币","<EOS>"}};
for(int t=0;t<len-1;t++){ int a=0,b=0; for(int i=0;i<3;i++){ for(int j=0;j<4;j++){ if(sentence[t]==Langue[i][j]){ b++; if(sentence[t+1]==Langue[i][j+1]){ a++; } } } } son[t]=a; mon[t]=b; cout<<"P("<<sentence[t+1]<<"|"<<sentence[t]<<")="<<a<<"/"<<b<<endl; } 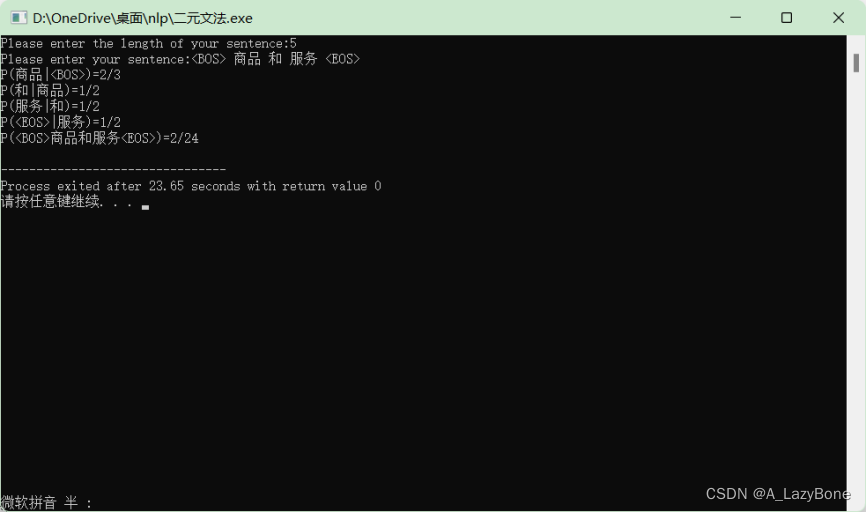
三、基于mindspore的情感分类实验(详细步骤)
1、概论
- 情感分类是自然语言处理中文本分类问题的子集,属于自然语言处理最基础的应用。它是对带有感**彩的主观性文本进行分析和推理的过程,即分析说话人的态度,是倾向正面还是反面。通常情况下,我们会把情感类别分为正面、反面和中性三类。虽然“面无表情”的评论也有不少;不过,大部分时候会只采用正面和反面的案例进行训练,下面这个数据集就是很好的例子。
- 传统的文本主题分类问题的典型参考数据集为20 Newsgroups,该数据集由20组新闻数据组成,包含约20000个新闻文档。 其主题列表中有些类别的数据比较相似,例如comp.sys.ibm.pc.hardware和comp.sys.mac.hardware都是和电脑系统硬件相关的题目,相似度比较高。而有些主题类别的数据相对来说就毫无关联,例如misc.forsale和soc.religion.christian。
- 就网络本身而言,文本主题分类的网络结构和情感分类的网络结构大致相似。在掌握了情感分类网络如何构造之后,很容易可以构造一个类似的网络,稍作调参即可用于文本主题分类任务。但在业务上下文侧,文本主题分类是分析文本讨论的客观内容,而情感分类是要从文本中得到它是否支持某种观点的信息。比如,“《阿甘正传》真是好看极了,影片主题明确,节奏流畅。”这句话,在文本主题分类是要将其归为类别为“电影”主题,而情感分类则要挖掘出这一影评的态度是正面还是负面。
- 相对于传统的文本主题分类,情感分类较为简单,实用性也较强。常见的购物网站、电影网站都可以采集到相对高质量的数据集,也很容易给业务领域带来收益。例如,可以结合领域上下文,自动分析特定类型客户对当前产品的意见,可以分主题分用户类型对情感进行分析,以作针对性的处理,甚至基于此进一步推荐产品,提高转化率,带来更高的商业收益。特殊领域中,某些非极性词也充分表达了用户的情感倾向,比如下载使用APP时,“卡死了”、“下载太慢了”就表达了用户的负面情感倾向;股票领域中,“看涨”、“牛市”表达的就是用户的正面情感倾向。所以,本质上,我们希望模型能够在垂直领域中,挖掘出一些特殊的表达,作为极性词给情感分类系统使用:垂直极性词=通用极性词+领域特有极性词垂直极性词=通用极性词+领域特有极性词按照处理文本的粒度不同,情感分析可分为词语级、短语级、句子级、段落级以及篇章级等几个研究层次。这里以“段落级”为例,输入为一个段落,输出为影评是正面还是负面的信息。
- 本次实验,以IMDB影评情感分类体验MindSpore在自然语言处理上的应用。
2、流程
- 安装Ananconda
- 添加环境变量
讯享网C:\ProgramData\Anaconda3; C:\ProgramData\Anaconda3\Scripts; C:\ProgramData\Anaconda3\Library\mingw-w64\bin; C:\ProgramData\Anaconda3\Library\bin;
- 创建环境,并激活
conda create -n panda python=3.7.5 conda activate panda 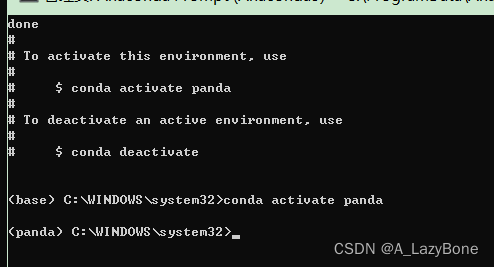
- jupyter配置环境kernels:
讯享网conda deactivate conda install ipykernel conda activate $your env name$ conda install ipykernel conda install nb_conda python -m ipykernel install --user --name panda --display-name panda
- 查看内核并进入
jupyter kernelspec list jupyter lab - 构建文件结构,下载mindspore放入该文件夹
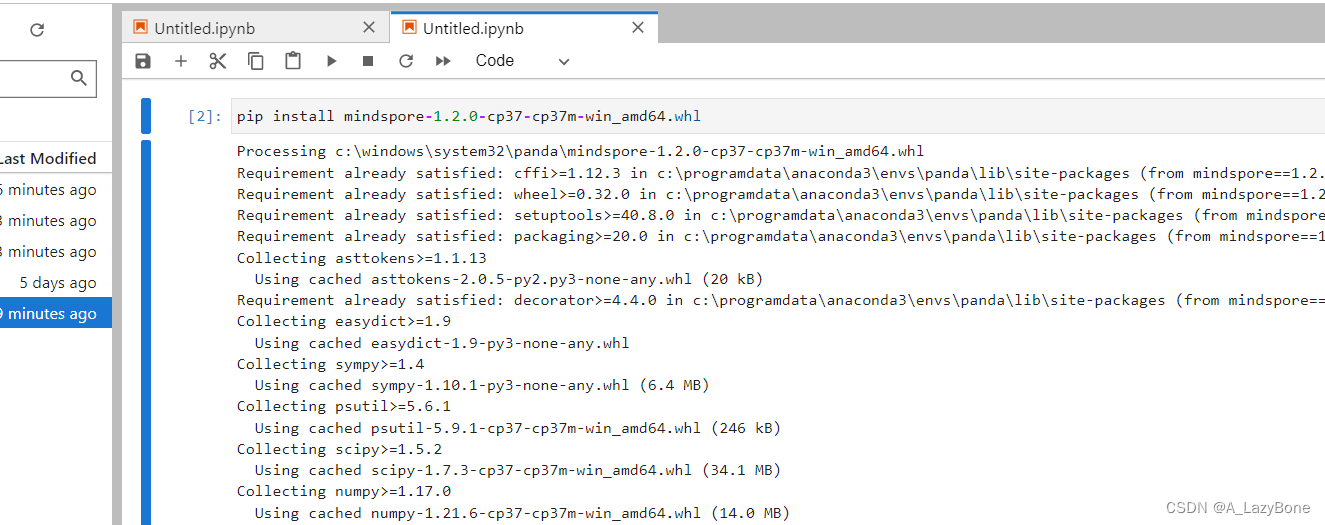
- 安装mindspore
讯享网pip install mindspore-1.2.0-cp37-cp37m-win_amd64.whl
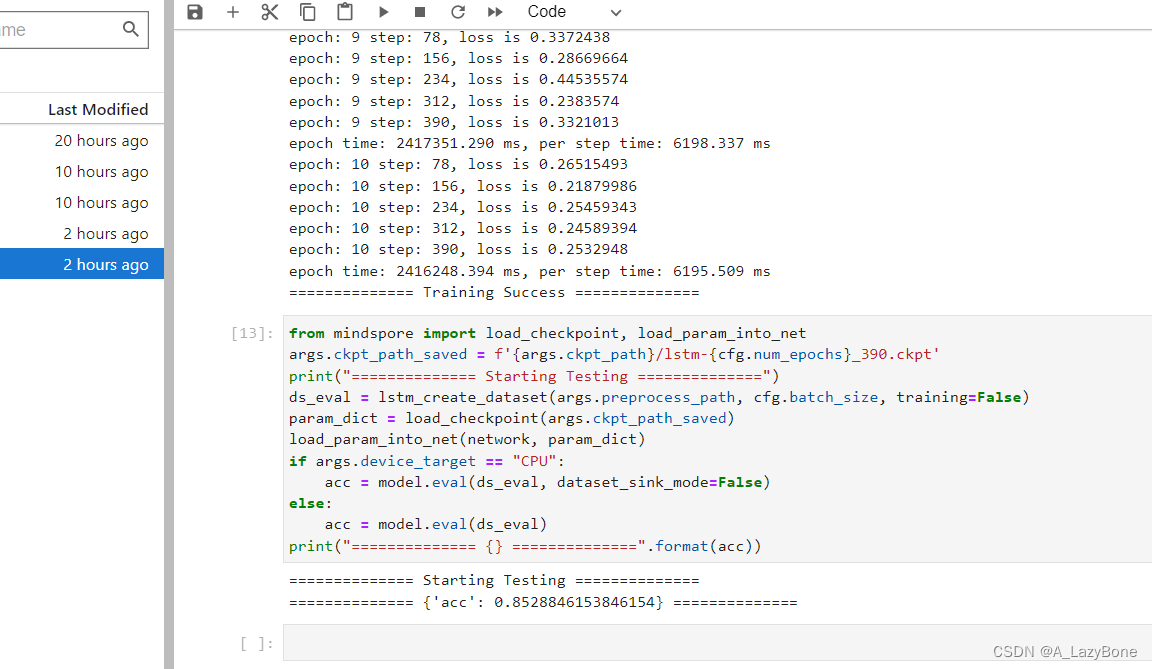
- 依次执行代码,进行训练,训练很慢,用了一天多,giao
四、汉语分词(源码)
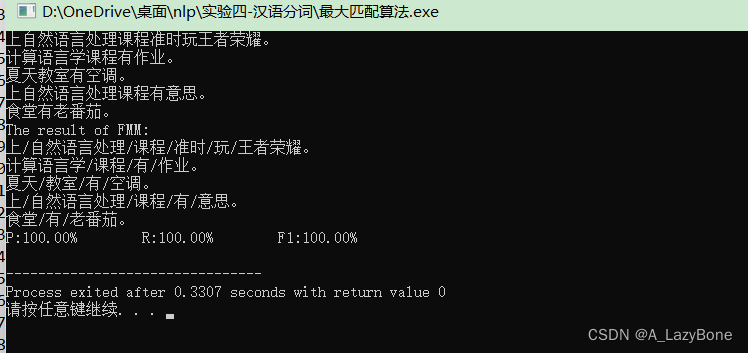
- 利用人民日报语料库或自己构建的语料库(30词以上)作为词典,任选五个句子,并基于正向最大匹配算法和最短路径法分别对这五个句子进行分词,并分别计算分词结果的正确率,召回率和F-测度值。输出句子,基于两种算法的分词结果和其对应的评价指标值。
- 词典:如{“自然语言处理”,“准时”,“课程”,“作业”,“有”,“老番茄”,“意思”,“上课”,“计算语言学”,“开心”}
句子:自然语言处理课程有意思。
分词结果:自然语言处理/课程/有/意思。
最大匹配算法:
- FMM算法描述:
(1)令i=0,当前指针p,指向输入字串初始位置,执行以下操作:
(2)计算当前指针p,到字串末端的字数n,如果n=1,转(4),结束算法。否则,令m=词典中最长单词的字数,如果n<m,令m=n;
(3)从当前p,起取m个汉字作为词w;,判断:
(a)如果wi是词典中的词,则在w;后添加一个切分标志,转©;
(b)如果wi不是词典中的词且w,的长度大于1,将wi从右端去掉一个字,转 (a)步;否则(wi的长度等于1),则在wi后添加一个切分标志,将wi作为单字词添加到词典中,执行(c )步;
(c)根据w,的长度修改指针p;的位置,如果p;指向字串末端,转(4),
否则,i=i+1,返回(2);
(4)输出切分结果,结束分词程序。 - 构建链表存储词典

typedef struct Diry{ string words; struct Diry *next; }Diry,*LinkList; ....... LinkList L; L=(LinkList)malloc(sizeof(Diry)); //头结点为空 Diry *s,*r=L; int m=sizeof(diry)/sizeof(*diry); int i,j,t=0,max=0,z; for(i=0;i<m;i++){ s=new Diry; s->words=diry[i]; r->next=s; r=s; if(s->words.length()/2>max) max=s->words.length()/2; } s=new Diry; s->words=""; //尾结点置空,方便判断词典是否遍历完成 r->next=s; r=s; r->next=NULL; - 对于词典内没有的词可实现自动添加,但不能太多,因为数据结构为链表,太多容易内存爆炸。
讯享网if(flag==1){ //当词典中没有该词的时候,链表末尾添加结点,插入新词 string u; u=u+sentence[i].at(2*j)+sentence[i].at(2*j+1); r->words=u; s=new Diry; r->next=s; r=s; r->next=NULL; wor[t]=u+"/"; t++; j++; }
- 循环剪切句子,并与词典对比,匹配成功加入wor串中
while(q-j>=1){ n=q-j; for(z=j;z<q;z++){ wor[t]=wor[t]+sentence[i].at(2*z)+sentence[i].at(2*z+1); } Diry *w=L->next; while(w->words!=""){ if(w->words!=wor[t]){ w=w->next; } else{ if(j+n<len){ wor[t]=wor[t]+"/"; t++; j=j+n; flag=0; break; }else{ wor[t]=wor[t]+"。"; t++; j=j+n; flag=0; break; } } } if(flag==1){ q--; wor[t]=""; }else break; } - 运行结果,因为词典比较简单,故成功率均为100%
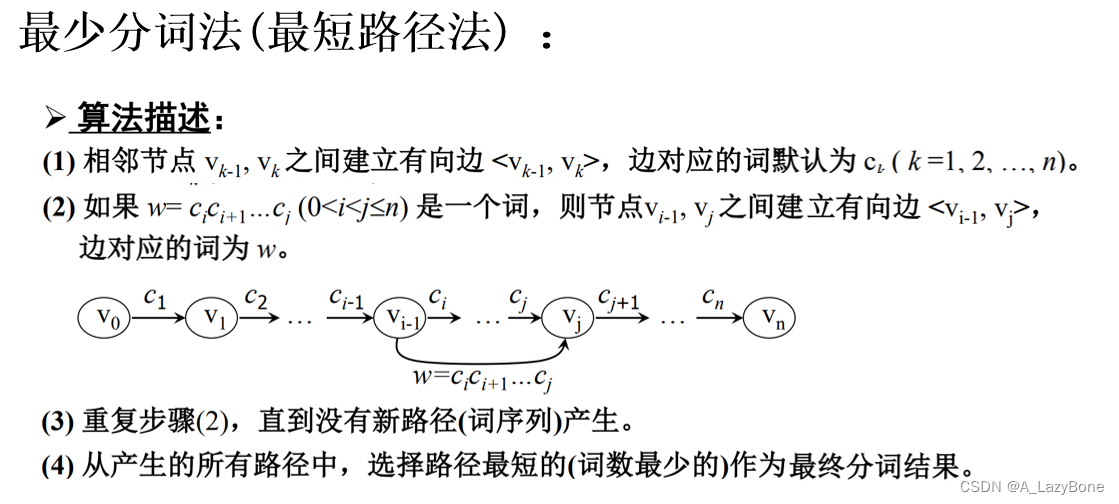
最少分词法
- 算法描述,正向匹配单词,最终分词最少的即为成功分词句子。
- 要使分词最少,匹配的词长必定要尽量最大,故顺序遍历句子,将最长的分词选中纳入结果句子中。
讯享网 for(i=0;i<5;i++){ cout<<sentence[i]<<"。"<<endl; int len=sentence[i].length()/2; string wor[4*len]={}; for(j=0;j<len;){ for(u=0;u<len;u++){ wor[t]=""; for(int q=j;q<=u;q++){ wor[t]=wor[t]+sentence[i].at(2*q)+sentence[i].at(2*q+1); } Diry *w=L->next; while(w->words!=""){ if(w->words!=wor[t]){ w=w->next; }else{ u_flag=u; lee=wor[t]; flag=1; break; } } } if(u_flag<len-1&&flag==1){ wor[t]=lee+"/"; j=u_flag+1; t++; }else if(u_flag==len-1&&flag==1){ wor[t]=lee+"。"; j=u_flag+1; t++; } } sentence[i]=""; for(j=0;j<t;j++){ sentence[i]=sentence[i]+wor[j]; } }
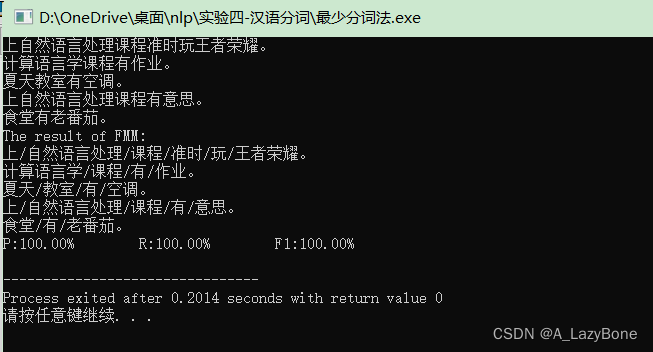
- 运行结果,同样正确率是100%
五、 形态分析(源码)
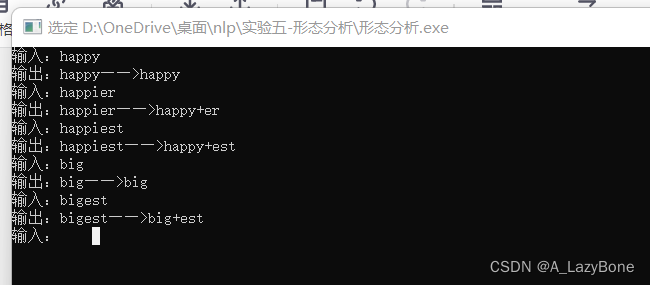
- 实现以下有限自动机的状态转移过程,通过它的状态转移过程可以识别happy的原型, 比较级happier, 最高级happiest,可以将单词的比较级和最高级转换为“原型+后缀”的形式,进行单词形态的还原,其中<i :y>为输入输出标签对,即输入i不仅进行状态转移,同时会输出y,可以理解为把i转换为y,另外ε为空输入,即不需要输入,可以输出+,可以理解为这一步转移不需要识别字符,直接输出+。状态转移过程需要自己实现。
- 最终结果:
输入:happy
输出:happy→happy
输入:happier
输出:happier→happy+er
输入:happiest
输出:happiest→happy+est - 采用双向链表作为数据结构,利用头插法构建链表
Word *s,*last; for(i=0;i<a.length();i++){ s=(Word*)malloc(sizeof(Word)); s->words=a.at(i); s->next=L->next; if(L->next!=NULL) L->next->pre=s; //将已有结点的pre指针指向新插入的结点 L->next=s; s->pre=L; if(i==0) last=s; //挂好尾指针,便于输出 } - 判定条件,看单词尾部,即链表头部2-3个结点,是否为er或est,如果是则修改指针,变为原型。
讯享网if(L->next->words=='r'&&L->next->next->words=='e'){ if(L->next->next->next->words=='i'){ ........ } cout<<"+er"<<endl; }else{ ........ } cout<<"+er"<<endl; } }else if(L->next->words=='t'&&L->next->next->words=='s'&&L->next->next->next->words=='e'){ ........ } cout<<"+est"<<endl; }else{ ......... } cout<<"+est"<<endl; } }else{ while(last->pre!=NULL){ //从链表尾向前遍历 cout<<last->words; last=last->pre; } cout<<endl; }
- 实验结果
六、TF-IDF(源码和教程)
- 完成华为云中自然语言处理理论、应用与实验课程中实验部分4.1-4.4的视频学习。保留学习后的截图。
- 理解并学会4.2中的TF-IDF,用代码实现TF-IDF的计算过程,数据集不限制。
- 随便找篇文章存入txt文件中,根据视频一进行汉语分词
- 搜寻停用词文件,同生成的分词文件放置同一文件夹下,分词文件别用pku,谁用谁傻逼!
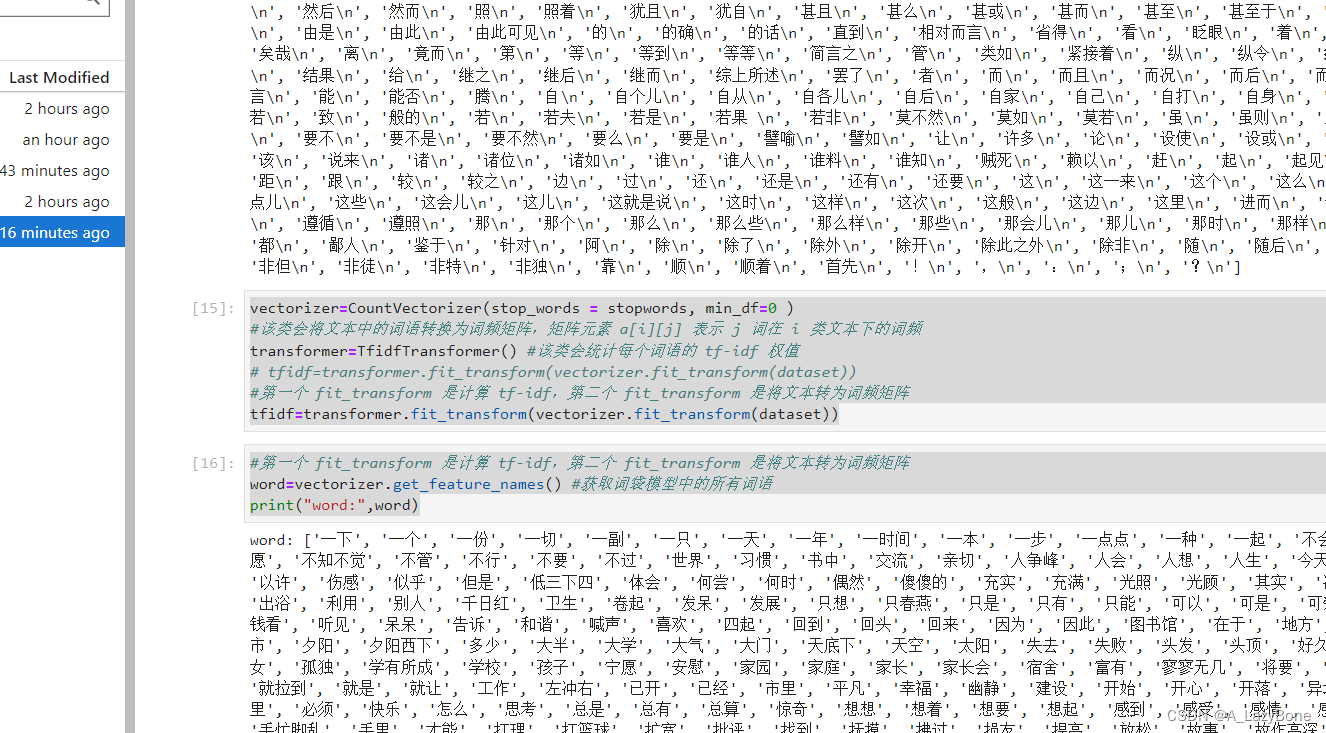
- 根据视频二基于 Python 和 scikit-learn 框架进行 TF-IDF 的实现即可
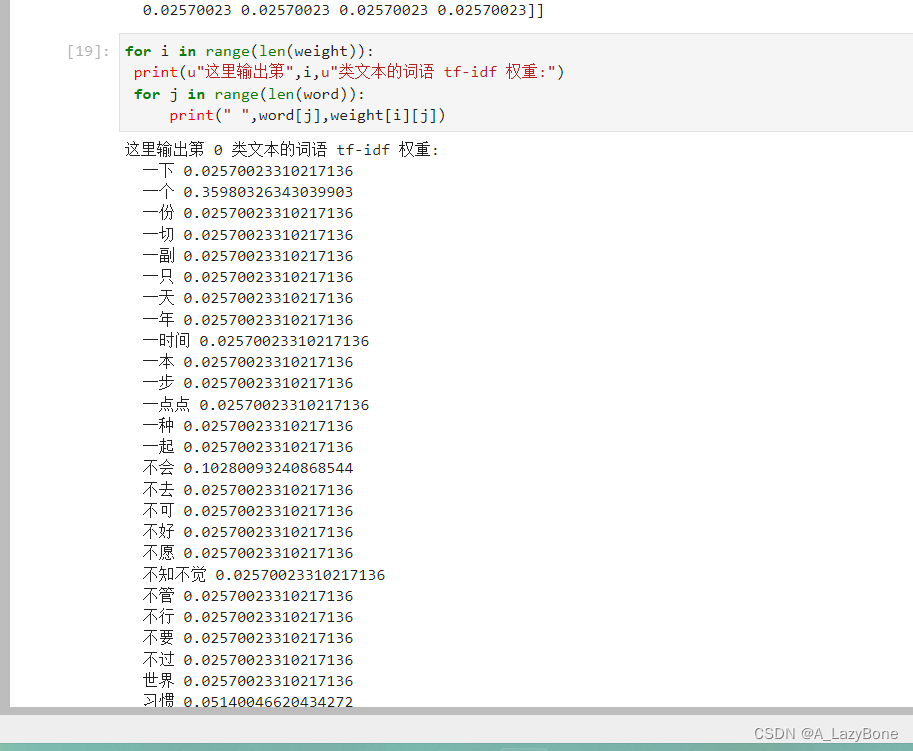
- 最终结果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/31954.html