
紧接我的实战项目——人脸情绪识别
Kaggle开源数据集(人脸情感识别 FER)——priya-dwivedi训练的一个六层卷积神经网络模型
链接:https://github.com/priya-dwivedi/face_and_emotion_detection
讯享网


模型使用过程解读:

使用PIL库Image的open方法读取一张图片,转换成numpy数组形式后使用matplotlib库显示图片。

调用人脸识别开源库face_recognition找出包含脸部的位置


以上还是图片的读取展示
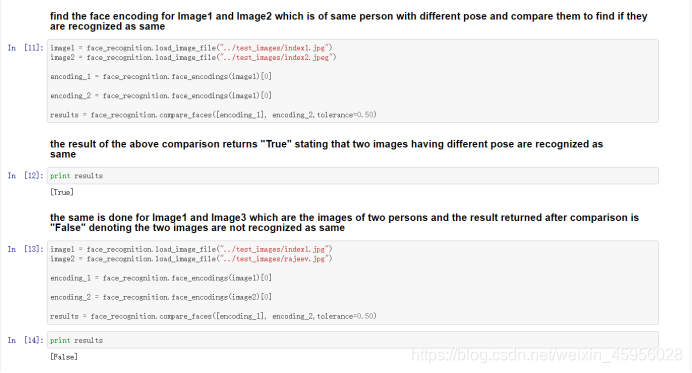
find the face encoding for Image1 and Image2 which is of same person with different pose and compare them to find if they are recognized as same
找到具有不同姿势的同一人的Image1和Image2的人脸编码,并进行比较,以确定它们是否被识别为相同,相同则为True
the same is done for Image1 and Image3 which are the images of two persons and the result returned after comparison is “False” denoting the two images are not recognized as same
对两个人的图像Image1和Image3也进行了同样的处理,比较后返回的结果为“False”,表示两个图像不被识别为相同
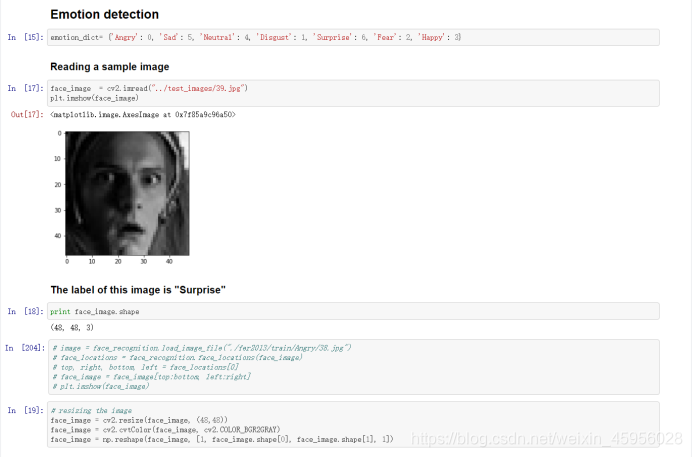
开始进入情绪检测环节,先定义好情绪编码类别,这个情绪对应的数字要和模型训练时的一致,然后使用opencv读取图片,使用cvtColor进行颜色空间转换,然后再将图片转换成(1,48,48,1)的形式,再利用keras的load_model导入训练好的模型model_v6_23.hdf5进行predict,np.argmax返回一个numpy数组中最大值的索引值,emotion_dict.items()对应的是’Angry’: 0……,使用列表推导式将’Angry’: 0转换成0:‘Angry’,图片中的情绪是Surprise,model.predict得到的结果举个例子可能是[0.1, 0.1, 0.2, 0.2, 0.3, 0.3, 0.9],使用np.argmax返回结果predicted_class=6,label_map[6]对应的就是’Surprise’。
{‘Angry’: 0, ‘Sad’: 5, ‘Neutral’: 4, ‘Disgust’: 1, ‘Surprise’: 6, ‘Fear’: 2, ‘Happy’: 3}

模型使用过程解读:


使用ImageDataGenerator图片生成器进行图片的处理,进行了归一化、rotation_range旋转、shear_range错位变换、zoom_range缩放变化。使用flow_from_directory获取目录下的图片并生成DirectoryIterator,使用class_indices获得从类名到类索引的映射的字典,路径下每个子目录都将被作为不同的类,类名将按字典序映射到标签的索引。
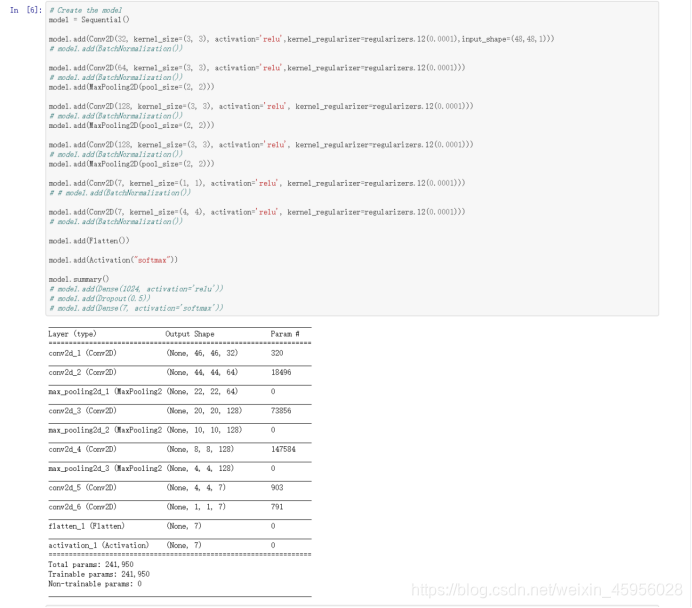
上图为 LittleVGG模型,共有六层卷积层,kernel_regularizer是一个正则化处理

她也使用ModelCheckpoint去获取最优目标的模型权重,optimizer=Adam(lr=0.0001, decay=1e-6),优化器采用Adam,lr代表学习率,默认1e-3,decay代表每次更新时学习率下降。参数steps_per_epoch是通过把训练图像的数量除以批次大小得出的,用于指定每个epoch所使用的迭代次数,validation_steps设置了验证使用的validation data steps数量(batch数量)。

上图展示训练过程中的loss。

这里是拿测试集的数据再进行预测,使用到predict_generator,使用np.argmax获得预测的一串y_pred, 再将结果放进混淆矩阵confusion_matrix(真实值,预测值),得到一个矩阵形式,参考这个理解:

接着使用classification_report来得到精确度,召回率,F1值等信息。

以上就是查看类别标签。

以上步骤为验证测试集,cv2.copyMakeBorder()用来给图片添加边框,putText添加文字

这个针对单一图片。

这个是针对网络摄像头。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/28658.html