
目录
提示词编写
CO-STAR 结构化框架
少样本提⽰ / 多⽰例提⽰
思维链提⽰
⾃动推理与零样本链式思考
⾃我批判与迭代
LLM接入方式
API远程调用
开源模型本地部署
大模型本地部署
一、本地部署概述
1.1 什么是本地部署
1.2 适用场景
二、主流推理框架
三、Ollama 部署详解
3.1 Ollama 简介
3.2 安装步骤
3.3 修改模型存储路径
3.4 拉取模型
3.5 运行与测试
3.6 版本对比
四、模型获取平台
4.1 Hugging Face(国外)
4.2 魔搭社区 ModelScope(国内)
五、本地部署完整流程
六、注意事项
七、快速参考命令
SDK和官方客户端库
SDK 安装与使用教程
一、OpenAI SDK
安装
使用示例
二、Anthropic SDK (Claude)
安装
使用示例
三、Google Gemini SDK
安装
使用示例
四、百度文心千帆 SDK
安装
使用示例
五、阿里通义千问 SDK
安装
使用示例
六、环境变量配置(推荐)
Windows
Linux/Mac
Python 代码读取
七、快速对照表
CO-STAR 结构化框架
少样本提⽰ / 多⽰例提⽰
请根据以下⽰例,分析后续的客⼾反馈,并提取产品名称、情感倾向和具体问题。 ⽰例1: • 反馈:“笔记本的电池续航太差了,完全达不到宣传的10⼩时,最多就4⼩时。” • 分析: ◦ 产品名称:笔记本电池 ◦ 情感倾向:负⾯ ◦ 具体问题:续航远低于宣传 ⽰例2: • 反馈:“客服响应很快,⾮常专业地帮我解决了软件激活问题,点赞!” • 分析: ◦ 产品名称:客服服务 ◦ 情感倾向:正⾯ ◦ 具体问题:⽆ 现在请分析这个: • 反馈:“我刚买的⽿机,才⽤了⼀周左边就没声⾳了,太让⼈失望了。”
思维链提⽰
例如,⼿动写⼀个思维链作为少样本提⽰的⽰例: Q:“罗杰有五个⽹球,他⼜买了两盒⽹球,每盒有3个⽹球,请问他现在总共有多少个⽹球?” A:“罗杰起初有五个⽹球,⼜买了两盒⽹球,每盒3个,所以,他总共买了2×3=6个⽹球,将起始 的数量和购买的数量相加,可以得到他现在总共的⽹球数量:5+6=11,所以罗杰现在总共有11个⽹ 球”
⾃动推理与零样本链式思考
罗杰有五个⽹球,他⼜买了两盒⽹球,每盒有3个⽹球,请问他现在总共有多少个⽹球?请⼀步步进⾏推理并得出结论。
⾃我批判与迭代
请执⾏以下两个步骤: 步骤⼀:编写代码 写⼀个Python函数 find_max ,⽤于计算⼀个数字列表中的最⼤值。 步骤⼆:⾃我审查与优化 现在,请从代码健壮性和可读性的⻆度,审查你上⾯编写的代码。 请回答:
- 如果输⼊是空列表,函数会怎样?如何改进?
- 变量命名和代码结构是否清晰?能否让它更易于理解?
- 请根据你的审查,给出⼀个优化后的最终版本。
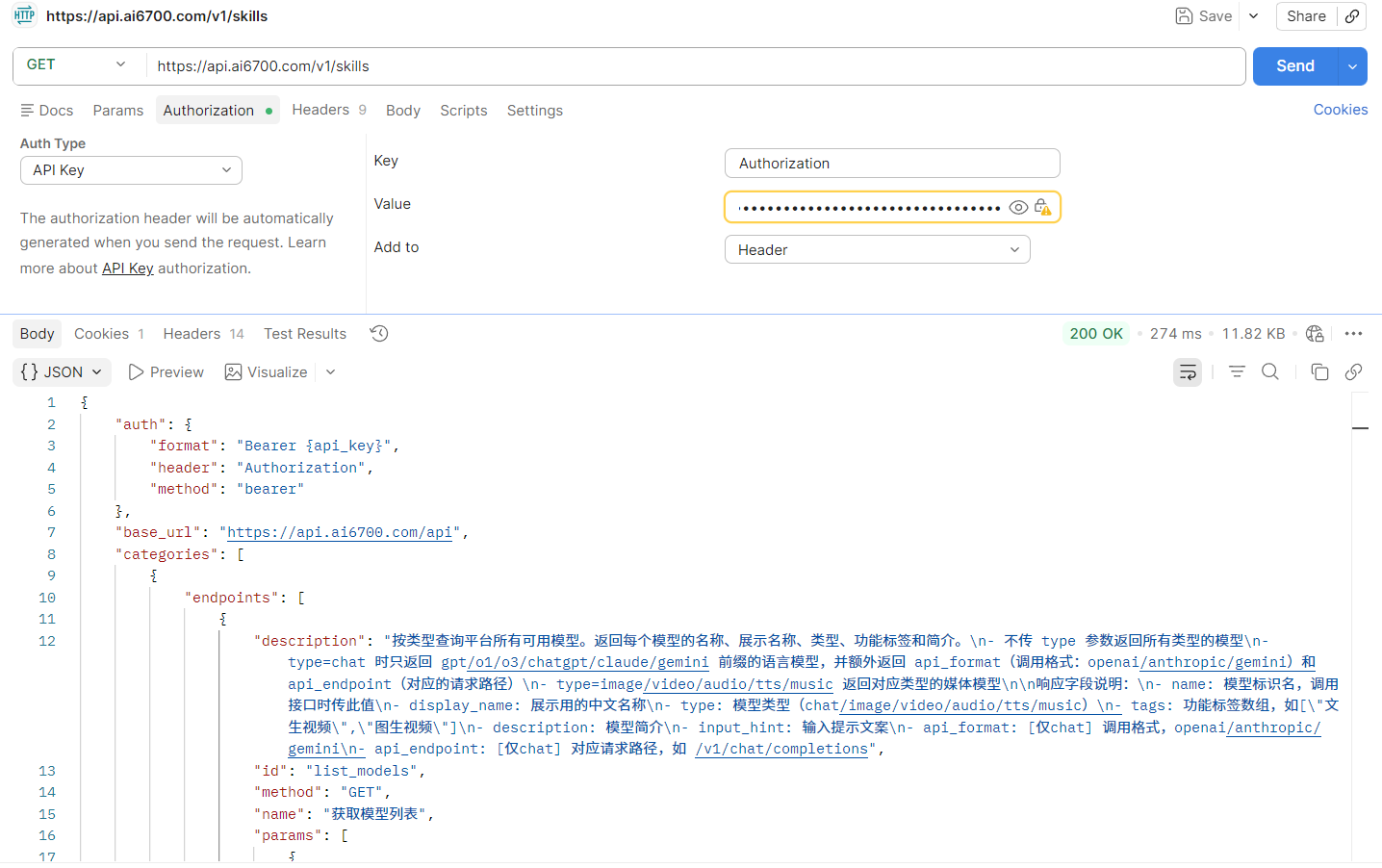
API远程调用
运营商服务器部署LLM,提供远程调用接口 适⽤于快速开发、集成到现有应⽤以及不想管理硬件资源 的场景
1. 注册账号并获取 API Key:在模型提供商的平台上注册,获得⽤于⾝份验证的密钥。
- 查阅 API ⽂档:了解请求的端点、参数(如模型名称、提⽰词、温度、最⼤⽣成⻓度等)和返回的 数据格式。
- 构建 HTTP 请求:在你的代码中,使⽤ HTTP 客⼾端库(如 Python 的 requests )构建⼀个包 含 API Key(通常在 Header 中)和请求体(JSON 格式,包含你的提⽰和参数)的请求。
- 发送请求并处理响应:将请求发送到提供商指定的 API 地址,然后解析返回的 JSON 数据,提取⽣ 成的⽂本。
小应用:

开源模型本地部署
运营商服务器部署LLM
大模型本地部署
一、本地部署概述
1.1 什么是本地部署
将开源的大语言模型(如 Llama、ChatGLM、Qwen 等)部署在自己硬件环境(本地服务器或私有云)中的方式。
核心流程:
- 下载模型文件(权重 + 配置文件)
- 使用推理框架在本地加载并运行模型
- 通过 API 方式进行交互
1.2 适用场景
考量因素 本地部署 云端API 数据敏感性 ✅ 数据留在本地 ❌ 需上传第三方 技术实力 需要 MLops 能力 低门槛 成本 固定硬件成本 按量付费 定制需求 可微调 通用能力
二、主流推理框架
框架 特点 适用场景 vLLM 高吞吐量,性能极佳 生产环境 TGI Hugging Face 出品,功能全面 生产环境 Ollama 用户友好,一键运行 快速入门、本地开发 LM Studio 图形化界面 桌面端使用
三、Ollama 部署详解
3.1 Ollama 简介
专为本地部署和运行 LLM 设计的开源工具,简化模型的安装、运行和管理。
官网:https://ollama.ai
3.2 安装步骤
- 下载:访问官网下载对应系统安装包
- 安装:按向导完成安装
- 验证:
# 访问服务 http://127.0.0.1:11434
命令行验证
ollama –version
3.3 修改模型存储路径
模型默认安装在 C:UsersXXX.ollama,可通过以下方式修改:
方式一:系统环境变量
变量名:OLLAMA_MODELS 变量值:自定义路径
方式二:Ollama 界面设置
设置完成后需重启 Ollama。
3.4 拉取模型
查找模型:https://ollama.com/search
以 DeepSeek-R1 为例:
# 拉取 1.5b 版本(轻量) ollama pull deepseek-r1:1.5b 拉取 70b 版本(需要高性能 GPU)
ollama pull deepseek-r1:70b
3.5 运行与测试
命令行交互:
ollama run deepseek-r1:1.5b
API 调用:
curl “http://127.0.0.1:11434/api/chat"; -d ‘{ ”model“: ”deepseek-r1:1.5b“, ”messages“: [{”role“: ”user“, ”content“: ”夸夸我“}], ”stream“: false }’
3.6 版本对比
四、模型获取平台
4.1 Hugging Face(国外)
- 官网:https://huggingface.co/
- 开源模型库,重要性不亚于 GitHub
4.2 魔搭社区 ModelScope(国内)
- 官网:https://www.modelscope.cn/
- 阿里达摩院推出,汇聚数千个预训练模型
- 便于国内用户下载,速度快
五、本地部署完整流程
┌─────────────┐ │ 下载模型 │ ← Hugging Face / 魔搭社区 └──────┬──────┘ ↓ ┌─────────────┐ │ 准备环境 │ ← GPU服务器 + 驱动 └──────┬──────┘ ↓ ┌─────────────┐ │ 选择推理框架 │ ← vLLM / Ollama / TGI └──────┬──────┘ ↓ ┌─────────────┐ │ 启动服务 │ ← 本地 API 服务 └──────┬──────┘ ↓ ┌─────────────┐ │ 调用模型 │ ← HTTP 请求 / SDK └─────────────┘
六、注意事项
- 硬件要求:大模型需要足够显存(如 70B 模型需要多卡 GPU)
- 存储空间:模型文件通常几十 GB 到几百 GB
- 推理速度:本地部署速度受硬件限制
- 模型选择:根据任务需求和硬件配置选择合适的模型版本
七、快速参考命令
# 拉取模型 ollama pull
<模型名>
运行模型(交互式)
ollama run
<模型名>
查看已安装模型
ollama list
删除模型
ollama rm
<模型名>
API 调用(非流式)
curl http://localhost:11434/api/generate -d ‘{ ”model“: ”
<模型名>
“, ”prompt“: ”你好“ }’
SDK和官方客户端库
自己的服务器部署LLM进行调用 ”“” 实际上,本地部署开源大模型,不仅需要开放的大模型的源代码,还包括模型的参数/权重、训练数据等。 “”“
SDK 安装与使用教程
一、OpenAI SDK
安装
pip install openai
使用示例
from openai import OpenAI 初始化客户端
client = OpenAI(api_key=”your-api-key“)
对话补全
response = client.chat.completions.create( model=”gpt-4“, messages=[ {”role“: ”user“, ”content“: ”你好“} ] ) print(response.choices[0].message.content)
嵌入向量
embedding_response = client.embeddings.create( model=”text-embedding-3-small“, input=”Hello world“ ) print(embedding_response.data[0].embedding)
二、Anthropic SDK (Claude)
安装
pip install anthropic
使用示例
import anthropic client = anthropic.Anthropic(api_key=”your-api-key“) response = client.messages.create( model=”claude-3-opus-“, max_tokens=1000, messages=[{”role“: ”user“, ”content“: ”你好“}] ) print(response.content[0].text)
三、Google Gemini SDK
安装
pip install google-generativeai
使用示例
import google.generativeai as genai genai.configure(api_key=”your-api-key“) model = genai.GenerativeModel(”gemini-pro“) response = model.generate_content(”你好“) print(response.text)
四、百度文心千帆 SDK
安装
pip install qianfan
使用示例
import qianfan 初始化
chat_comp = qianfan.ChatCompletion()
调用对话
response = chat_comp.do( model=”ERNIE-Bot-turbo“, messages=[{”role“: ”user“, ”content“: ”你好“}] ) print(response[”result“])
五、阿里通义千问 SDK
安装
pip install dashscope
使用示例
import dashscope from dashscope import Generation dashscope.api_key = ”your-api-key“ response = Generation.call( model=”qwen-plus“, messages=[{”role“: ”user“, ”content“: ”你好“}] ) print(response.output.text)
六、环境变量配置(推荐)
Windows
set OPENAI_API_KEY=your-key-here
Linux/Mac
export OPENAI_API_KEY=your-key-here
Python 代码读取
import os from openai import OpenAI client = OpenAI(api_key=os.getenv(”OPENAI_API_KEY“))
七、快速对照表
pip install openai
OpenAI(api_key=”xxx“) Anthropic
pip install anthropic
Anthropic(api_key=”xxx“) Google
pip install google-generativeai
genai.configure(api_key=”xxx“) 百度
pip install qianfan
qianfan.ChatCompletion() 阿里
pip install dashscope
dashscope.api_key=”xxx“
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/281188.html