
今天讨论里出现了一个新词:Harness。
简单来说,它是一套新兴的“Agent控制系统”,专门用来约束和管理AI行为。就在最近,字节跳动开源了Harness项目,迅速在AI圈爆火,狂揽超过49k的Star。这个热度也吸引了资本的重仓押注,李开复和陆奇两位顶级投资人罕见同框,布局Harness多智能体赛道。
它之所以这么受关注,是因为它解决了一个核心难题:模型能力再强,也需要一套“外挂系统”来管着它,否则在真实任务里就容易失控——跑着跑着忘了目标、上下文越来越乱、报错了也不知道怎么恢复。
而Harness的本意,就是“马具”“缰绳”——不是用来替马跑,而是用来让它在边界内跑得更稳、更远。放在今天这个阶段看,Harness刚好概括了第七天的主题:项目正在从“疯狂往前冲”,转向“开始给系统补上缰绳”。
这不是刹车,而是让系统在可控的边界内,跑得更稳、更远。

会议一开场,大家的目光落在一块屏幕上——AI自己分析出来的周贡献度看板。
这块看板的逻辑不是简单的“提交行数”或“提交次数”,而是分析提交内容与项目的相关度、贡献度,综合打出一个分数。换句话说,它靠理解来作判断,而不是靠硬指标堆排名。
如果觉得分数不客观怎么办?答案很直接:去改提示词。代码就在仓库里,规则由团队自己定义。这意味着,当AI开始参与评价人的时候,团队不再是被动的使用者,而变成了规则的制定者。
看板把每个人的提交内容都列了出来,做了什么事一目了然。有人提议:以后是不是每天过这个就行了?工作量自然就展示出来了。
这是今天最重要的概念引入。
项目里还没有“Harness”这层定义,连CLAUDE.md都没有生成。有人决定今天补一个初版,大家后续一起完善——把AI的边界固定下来,比如对文档读取的限制、对代码修改的约束、对高风险操作的兜底。以后大家有什么新的边界限制条件,都可以往里加。
放到工程语境里看,Harness并不是单纯多一份文档,而是一层专门用来约束、托住和校正 AI 行为的控制面。它不负责告诉 AI 一定要往哪走,但会先告诉它哪些路不能走、哪些动作不能越界。
这个做法的行业背景很有意思。现在大厂基本上都在用AI编程,甚至有些项目人类写的代码已经是零,但他们都有一套自己的规范。OpenAI内部有一个项目,100多行代码没有一行是人类写的,但因为有规范,迭代到100多行依然稳定。Claude Code的源码被爆出来是“屎山”——确实全部是AI生成的,但“屎山归屎山,你就说好不好用吧?”
这提醒我们:AI生成的代码可以不那么优雅,但只要边界卡得住、规范跟得上,它依然可以好用。
飞书机器人已经接进了测试环境,大家可以直接用“恒海AI”体验。一个贴心的设计是:机器人会读取你的飞书名字,记住它,放到上下文里。它不是在对一个匿名的“用户”说话,而是在对“你”说话。
但这里遇到一个典型的产品体验难题:思考过程要不要返回给用户?
有人在测试让AI自己去接入腾讯会议的MCP,结果AI输出了一大串——仔细一看,思考过程也被返回来了,显得非常冗长。这时出现了两种意见:一个人觉得应该保留,因为他想看到整个过程;另一个人觉得在飞书里看到这么长一串,体验很不友好。
最后的结论很务实:做个开关。WebChat上可以有个开关让想看的人自己打开;飞书这边默认关闭。普通用户不需要看到这些技术细节。
这个讨论虽然小,但它反映了一个重要的意识:系统正在从“能跑”走向“好用”,而“好用”的起点,就是知道什么该给用户看,什么不该给。

今天还推进了一个技术层面的重要工作——WebChat和飞书的消息处理被统一到了同一个中间层,叫Orchestrator(协调层)。不管用户从WebChat还是飞书进来,底层都走同一套消息机制,聊天记录可以跨渠道同步。
消息机制用的是NATS队列,采用带ACK的推模式。但带ACK有个问题:必须设超时时间,而AI模型处理的时间是不确定的。有人给了一个任务,默认30秒超时,结果worker一直在说“任务队列”,其实已经在处理了只是还没完成,导致不停重试。这说明在AI系统里,传统的超时和重试机制需要重新思考。
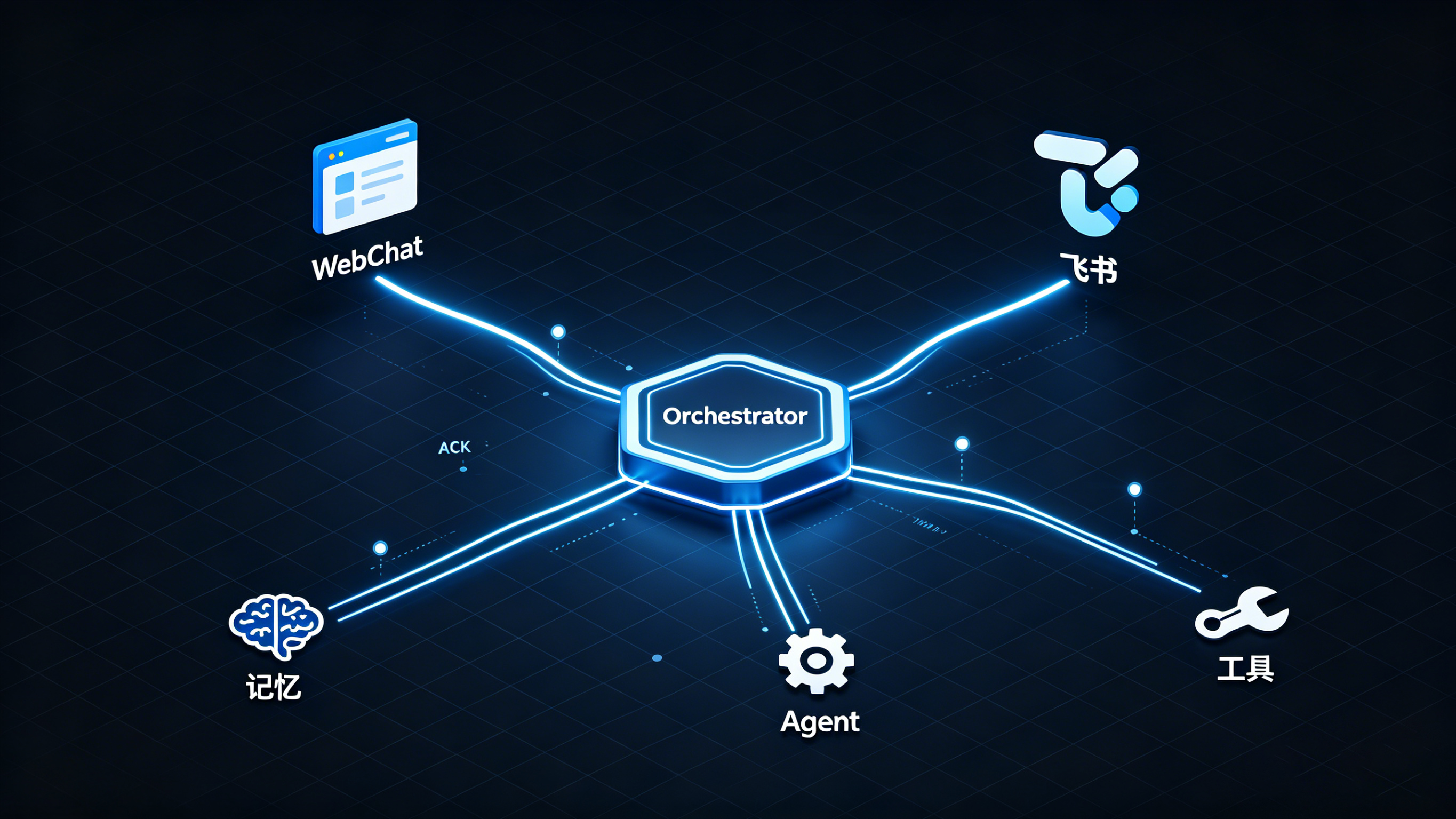
更根本的问题是,团队发现有些地方的代码结构没有保住。有人启动了两个chat,问它什么日志都没有,后来AI分析说——你直接在chat启动了一个agent,压根就没有走消息分发。代码写在一起的时候,每一层都可以互相调用,没有强制约束。这恰恰是Harness这一层要解决的问题——把每一层的规则依赖写下来,系统才能知道自己不能做什么。
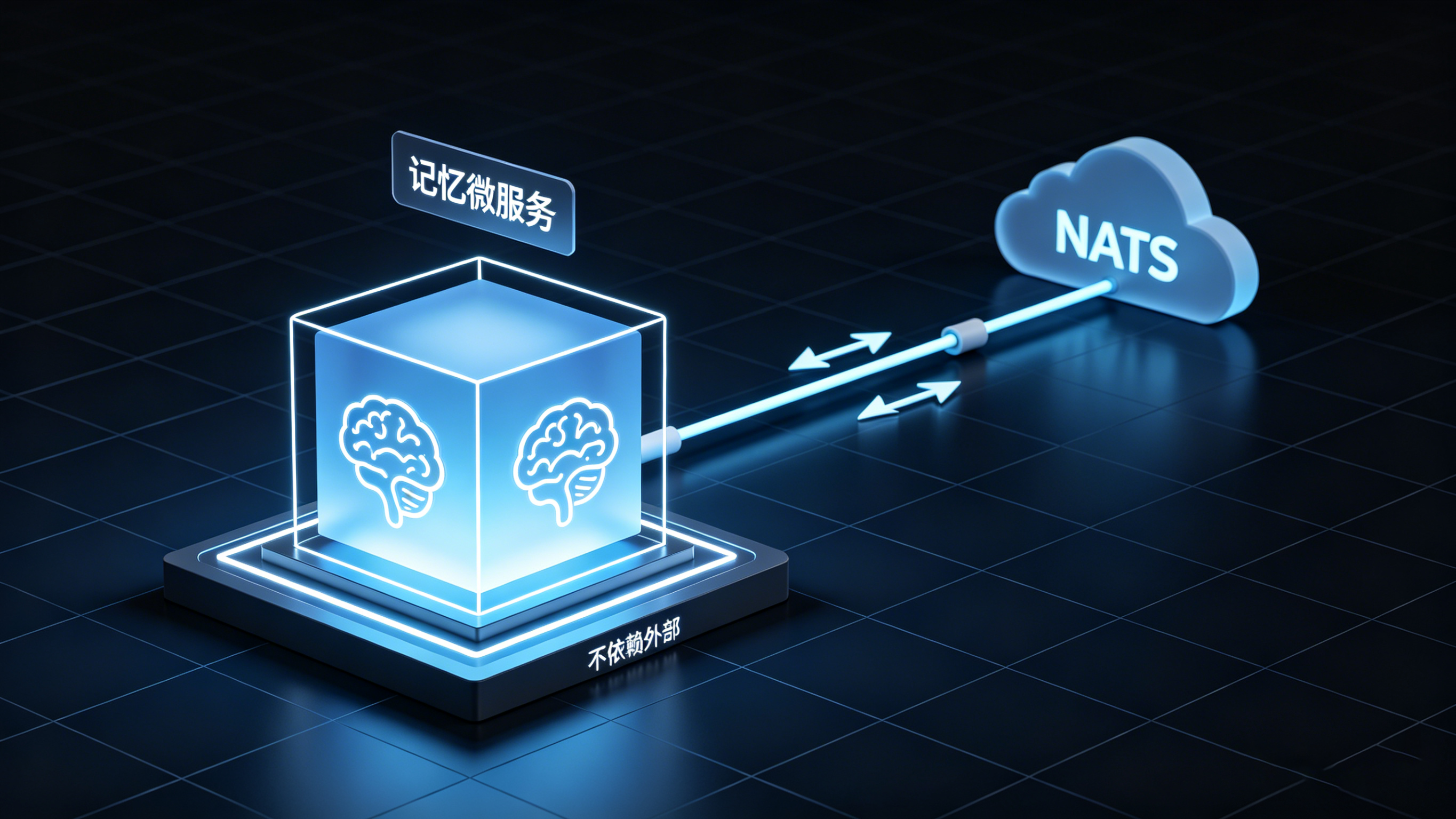
记忆系统今天也往前走了一步:记忆模块被单独抽出来,做成一个独立的微服务。它自己独立运行,所有功能都在内部实现,不依赖外部。通信走的是NATS的订阅和回复模式——不是agent直接去调用记忆,而是agent往协调层推消息,协调层再和记忆模块通信。
独立抽出来这一步的价值很清晰:它让记忆不再是一个被到处调用的散装能力,而是一个有边界、可独立迭代的服务。
记忆的测试也在推进。有人用test-suite做了初步测试,效果还可以,但召回率等量化指标还需要固定测试集来持续追踪。有人提出:应该把测试集固定下来,这样迭代过程中可以看分数的波动。
今天还讨论了一个有意思的问题:漏洞扫描发现的问题,能不能让一个后台agent自动去修?
连着扫了五轮,高危已经没了,剩下中低危。但有些修复会动数据库结构,不能直接自动执行。所以需要定义边界——哪些可以让AI直接修掉,哪些只能记录告警。目前的结论是:先记录,不要让它继续修。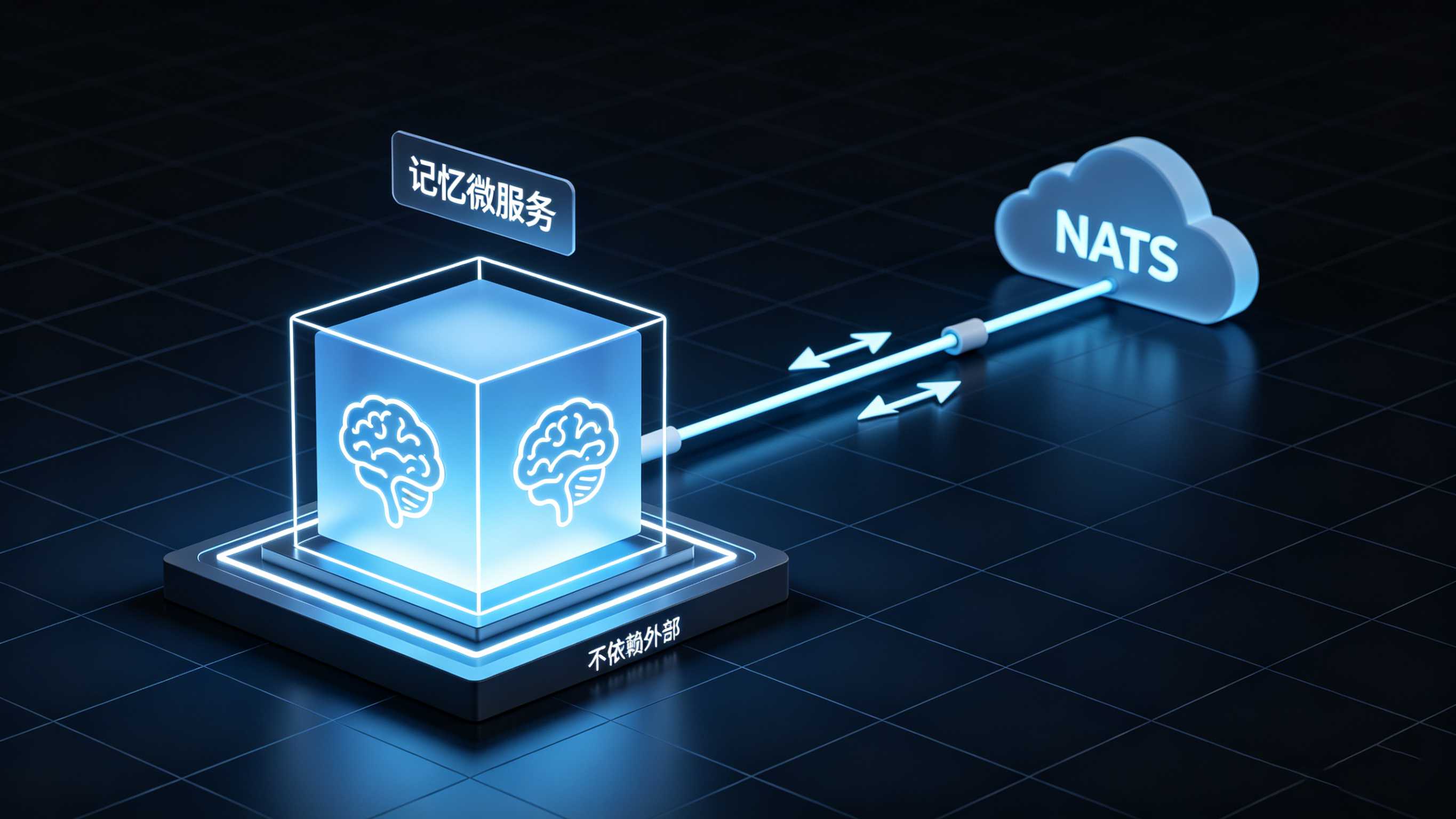
这其实就是Harness思路的一个具体应用场景:不是禁止AI做事,而是明确告诉它哪些事不能做、哪些事能做但需要人确认。
另一个务实的动作是:有人在让AI扫描代码的时候,AI提出了一些质疑——比如某些写法可以优化、某些逻辑可能有隐患。这些质疑的优先级可能没那么高,但有些是有道理的,应该存下来。
于是把这些质疑放到了一个文档里,后面逐步修复。谁手上暂时没有急事,就可以去修补。等版本合上去之后,这个文件就在了,大家都可以往上记,并标记“已修复”或“待修复”。
这个做法看似简单,但它反映了一个重要的工程意识:AI可以帮我们发现很多问题,但发现不等于解决。把问题系统化管理起来,才能让系统持续变好。

会议中大家意识到,需要更规范的项目管理。有人提到之前布过禅道,可以去上面搞一个项目管理,把目标进度都列出来——比如记忆知识库每个部分当前完成了百分之多少,类似甘特图。
今天,大家把当前发现的问题都提到了禅道上,会后每个人尽量把分配到手上的问题收口。明天上午,团队会把大家的补丁合并到一个新的测试环境上,回归测试后,发布到“恒海AI”对应的环境。当前的“恒海AI”以后会作为正式环境,同时新创建一个“恒海AI-test”机器人,以及配套部署全套的测试域名和环境。
这是项目第一次有了正式的版本发布流程。
回头看第七天——贡献度看板、Harness/CLAUDE.md、飞书开关、Orchestrator统一消息、记忆微服务、漏洞扫描边界、待修复问题列表、禅道收口……
它们拼在一起指向一个清晰的信号:项目正在从“堆功能”转向“建治理”。
Harness这一层,是给AI的行为画边界; 飞书开关是给用户体验做取舍; Orchestrator是让分层架构真正落地; 记忆微服务是让能力有独立迭代的空间; 待修复列表是把AI的发现变成可持续的资产; 禅道是把团队的协作变成可追踪的流程。
这些东西加在一起,其实就是企业级AI系统最需要、也最难长出来的内里——不是某一个功能有多强,而是整个系统在越来越复杂之后,还能不能不乱、可控、可迭代。
这,是第七天。
《从0到1:企业级AI项目迭代日记》记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/281112.html