

文丨李海伦
编辑丨徐青阳
4月16日晚,人工智能公司Anthropic宣布,其最新大模型Claude Opus 4.7已正式上线。该模型现已在所有Claude产品、官方 API,以及亚马逊、谷歌、微软三家云平台上线。定价与前代Opus 4.6一致,每百万输入token 5美元、每百万输出token 25美元。
据官方介绍,Opus 4.7在复杂软件工程任务中的表现有所增强,能够更稳定地处理长时间运行的任务,并在执行过程中更严格地遵循用户指令。模型在长时间运行的任务中具备更高的一致性,并会在输出结果前对自身产出进行自我验证。
简而言之,就是Opus 4.7针对那种很复杂、很难的工程任务,相较Opus4.6性能提升明显,做事更稳、更细致,还会自查结果再给用户。
在多模态能力方面,模型现已支持处理最长边达2,576 像素(约375万像素)的图像,较此前Claude模型提升超过三倍。这意味着它“看图更清楚了”,能捕捉到更多细节,比如小字、复杂表格或界面中的细微元素。
这一升级使其能够更好地胜任计算机操作代理、复杂图表解析等对视觉细节要求较高的任务,同时,在生成专业内容(如界面设计、演示文稿和文档)时,可展现出更高的质量与一致性。
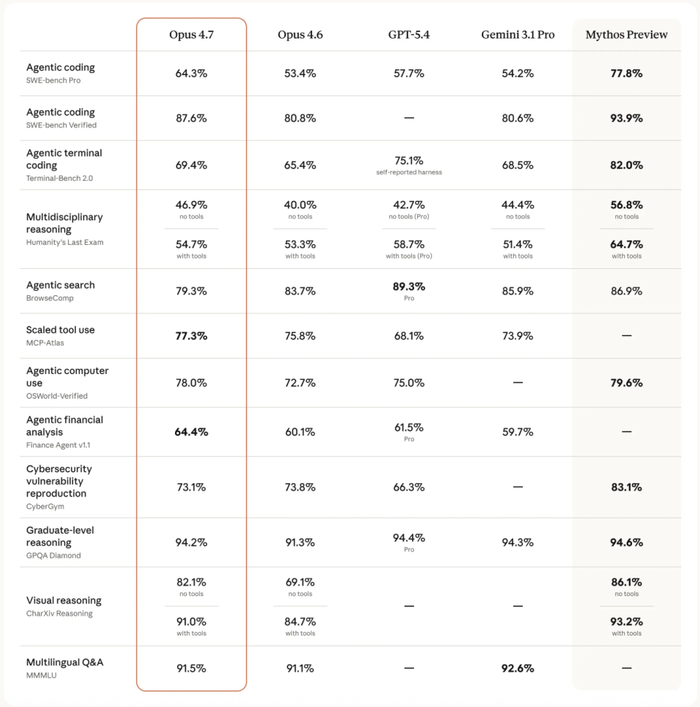
Opus 4.7在各项基准中表现全面且稳定,整体处于第一梯队,在编码、推理和多领域任务上均有较强实力,但在个别指标上略逊于最新对手(如Mythos)。图片来源:Anthropic官方
记忆方面,Opus 4.7改进了基于文件系统的记忆机制,能在跨会话的长任务中保留关键笔记。
在第三方评估GDPval-AA及Finance Agent评估中,Opus 4.7取得了当前最先进水平的得分。但Anthropic也指出,其综合能力仍不及该公司更强大的Claude Mythos Preview模型。
Anthropic表示,Opus 4.7是Anthropic此前公布的“Project Glasswing(玻璃翼)”计划下首个应用新型网络安全防护的模型。
官方介绍,在训练过程中对该模型的网络安全相关能力进行了差异化削弱,使其不及 Mythos Preview;同时在发布版本中加入了自动检测与拦截机制,用于屏蔽涉及违规或高风险网络安全用途的请求。
该机制的实际部署数据将用于评估未来是否更广泛地发布Mythos级模型。对于有合法需求的安全从业者(如漏洞研究、渗透测试、红队演练),Anthropic同步推出了“网络安全验证计划”(Cyber Verification Program),需申请加入。
在自动化行为审计中的整体不对齐行为评分方面,Opus 4.7相比Opus 4.6和Sonnet 4.6有一定程度的改进,但Mythos Preview仍然表现**,出现不对齐行为的比例最低。图片来源:Anthropic官方
根据Anthropic的内部评估显示,Opus 4.7与Opus 4.6的安全画像整体相近,欺骗、谄媚及配合滥用等行为的发生率较低。在诚实度和抵御提示注入攻击方面有所改进,但在涉及管制物质的问题上,模型更容易给出过于详细的减害建议,这一项的安全表现较前代略有所减弱。
此外,Anthropic表示同步上线新增几大功能:
Opus 4.7 新增一个xhigh(超高) 的模式:位于high和max之间,用户在处理难题时可以更细致地权衡推理深度与响应延迟之间的取舍。
Claude Code中,所有套餐的默认档位已上调至xhigh。Anthropic 建议用户在将Opus 4.7用于编程或agent类任务时,从high或xhigh档位开始尝试。
API 新增“任务预算”功能(公测中):开发者可以给模型设定一个token消耗的大致盘子,让它在长任务里知道哪儿该多花、哪儿该省。
Claude Code 新增 /ultrareview 命令:专门做代码审查,会认真读一遍改动、挑出bug和设计问题,像一个严格的老同事在review你的代码。Pro和Max用户免费送三次试用。
此外,自动模式(auto mode)的使用范围已扩展至Max用户:开启该模式后,Claude可以自己做一些小决定,不用每一步都问用户要权限,使长任务在运行过程中减少中断,同时相较于“跳过全部权限”的选项风险更低。
Anthropic表示,Opus 4.7是Opus 4.6的直接升级版,但有两项变化会影响token的用量:
其一,Opus 4.7采用了更新后的分词器(tokenizer),对模型处理文本的方式进行了改进,代价是相同输入所映射出的token数量有所增加——依内容类型不同,大致为原先的1.0至1.35倍。
其二,Opus 4.7在较高思考强度档位下的思考量有所增加,尤其是在agent类场景的后续轮次中。这一变化提升了模型处理难题时的可靠性,同时也导致输出token数量相应上升。
图注:在一项内部agent编码评估中,模型得分与各思考强度档位下token用量的关系。在该评估中,模型仅基于一条用户提示词自主完成任务,相关结果可能无法代表交互式编码场景下的实际token用量,图片来源:Anthropic官方
官方表示,用户可通过多种方式控制token用量:调整effort参数、设置任务预算,或在提示词中要求模型输出更简洁。
根据 Anthropic公布的内部编码评估结果,各思考强度档位下的token用量均有所优化,但官方建议用户结合自身的实际业务流量进行对比衡量。Anthropic在官方网站也同步发布了一份迁移指南,为从Opus 4.6升级至Opus 4.7的用户提供参考。
实测Claude Opus 4.7,好好的模型也开始不说人话了
AI可以自审代码了,Opus 4.7出手解决“屎山”





版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/277674.html