
你是否厌倦了每次与AI助手对话时,都要重复解释你的数据库schema、API规范或微服务架构?Claude的Skills系统正是为此而生。它允许你将领域知识、工作流程和**实践封装成可复用的模块,让Claude从一个通用助手,进化为深刻理解你业务逻辑的“后端架构专家”。本文将深入解析Skills的核心机制与**实践,助你高效构建专属的智能工作伙伴。
传统的AI对话如同每次雇佣一名新员工,你需要反复进行岗前培训。而Skills系统则相当于为这位“员工”配备了一本详尽的、可随时查阅的“岗位手册”。它基于开放的Agent Skills标准,不仅确保了跨工具的兼容性,还通过Claude Code的扩展,具备了调用控制、子代理执行等高级能力。
Skills与普通Prompt的核心区别在于其模块化与持久化:
- 普通Prompt:每次对话需重新注入上下文,知识无法沉淀。
- Skills:将知识封装成独立模块,一次创建,跨所有对话自动按需加载。
维度 普通 Prompt Skills
作用范围 单次对话 跨所有相关对话
加载方式 每次手动提供 相关任务时自动加载
上下文占用 每次都占用 按需加载,未使用时零占用
知识管理 分散在多次对话中 集中管理,持续优化
一致性 依赖人工记忆 标准化,确保一致
这尤其适合后端开发中那些需要反复说明的上下文,例如:
- 数据库知识:复杂的BigQuery表关系、数据清洗规则。
- API规范:服务端接口的认证、限流、错误码定义。
- 微服务架构:服务间调用链路、消息队列的使用规范。
“把你反复向 Claude 解释的偏好、流程、领域知识打包成 Skills,让 AI 成为你的领域专家”
将所有Skills的详细内容一次性加载会迅速耗尽宝贵的上下文窗口。Claude Skills采用了精妙的“渐进式披露”三级加载机制,像一本智能书籍,只在你需要时才展开具体章节。
三级加载机制详解:
- 元数据 (Metadata):始终加载,消耗极少token(约100个),让Claude知道“有什么技能”以及“何时使用”。其核心是
description字段,必须用第三人称清晰描述功能与触发场景。
--- name: pdf-processing description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction. ---例如,一个处理PDF报告的Skill,其description应写为:“提取和分析PDF格式的后端服务日志报告。当用户需要从PDF中获取结构化日志数据时使用。”而非第一人称的“我可以帮你提取PDF…”。
- 指令 (Instructions):当用户请求匹配Skill描述时加载,提供具体操作指南。
- 资源与代码 (Resources & Code):仅在指令中引用时才加载,如参考文档或可执行脚本。
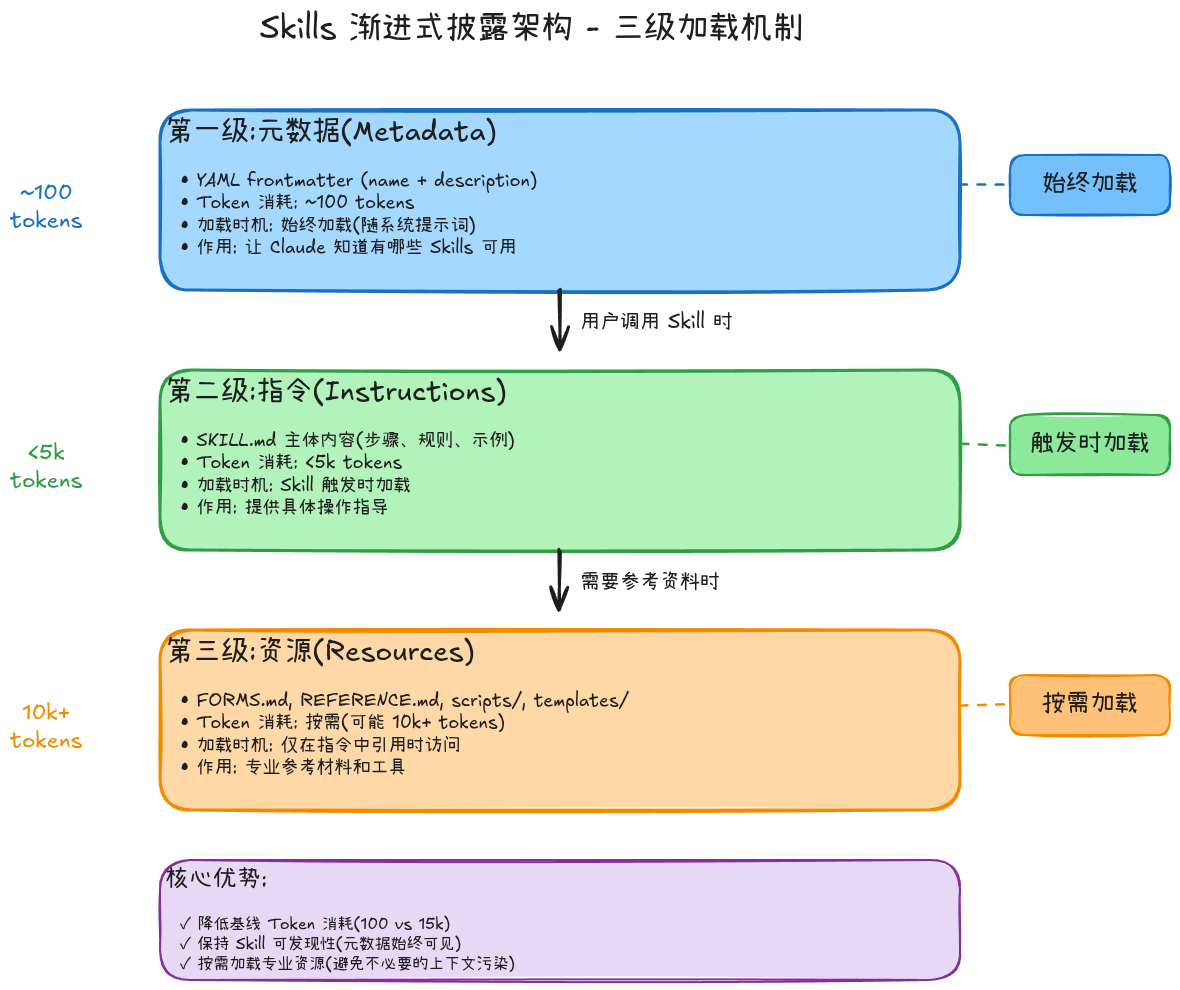
这种架构确保了极高的效率。例如,当用户请求“帮我分析API网关的访问日志PDF”时,系统会经历如下智能加载过程:
┌─────────────────────────────────────────┐
│ 步骤 1: Claude 检查所有 Skill 的元数据 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 匹配到 pdf-processing Skill │
│ description 包含 "Extract text from PDF"│
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 步骤 2: 加载 SKILL.md 的指令内容 │
│ (~3k tokens) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 步骤 3: Claude 发现需要表单填写 │
│ 读取 FORMS.md (~2k tokens) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 总 Token 消耗: 约 5k tokens │
│ 其他 9 个 Skills: 0 tokens(未加载) │
└─────────────────────────────────────────┘创建Skill始于识别高频重复痛点。问自己:哪些后端知识我总在向Claude重复?
- 场景A:数据库查询:每次都要说明表结构、排除测试账户的规则、常用聚合模式。
- 场景B:API设计评审:每次都要强调RESTful规范、鉴权逻辑、响应体格式。
一个最小化的Skill只需一个SKILL.md文件。其核心是YAML Frontmatter和具体的指令内容。
my-skill/
└── SKILL.md # 唯一必需的文件以下是一个针对“服务状态报告生成”的Skill示例框架:
---
name: bigquery-analytics
description: Analyze BigQuery data from the user_metrics and sales tables. Use when the user asks about data analysis, metrics, or BigQuery queries. Always exclude test accounts and apply standard date filters.
---创建步骤非常简单:
- 在Claude Code的Skills目录下创建新文件夹(如
service-health-report)。 - 创建
SKILL.md文件,写入上述YAML和指令。 - Claude会自动索引该Skill,下次你提及“生成服务报告”时,它就会应用这些专业知识。
1. 简洁为王
上下文窗口是共享资源。指令应假设Claude具备通用智能,只提供它不知道的领域特定知识。避免过度解释基础概念。
Extract PDF Text
Use pdfplumber for text extraction:
python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
Extract PDF Text
PDF(便携式文档格式)是一种常见的文件格式,包含文本、图像等内容。
要从 PDF 中提取文本,你需要使用一个库。有很多 PDF 处理库可用,
但我们推荐 pdfplumber,因为它易于使用且能处理大多数情况。
首先,你需要使用 pip 安装它。然后你可以使用下面的代码...2. 设置适当的“自由度”
根据任务性质,决定给予Claude多大灵活度:
- 高自由度(开放式指引):适用于代码审查、架构建议等有多种可行方案的场景。
- 中自由度(模板化指引):适用于生成API文档、部署脚本等有推荐模式的任务。
- 低自由度(精确指令):适用于执行数据库迁移、敏感配置更改等容错率低、必须严格按步骤的操作。
⚠️ 记住: 不要低估 Claude 的智能!它是通用 AI,不需要你解释基础概念。
3. 采用“计划-验证-执行”模式处理复杂任务
对于批量更新、复杂转换等高风险操作,不要让Claude直接执行。而是让它先生成一个结构化的计划(如JSON),通过一个验证脚本检查无误后,再执行该计划。
分析 → 创建计划文件 → 验证计划 → 执行 → 验证输出这种模式能及早发现错误,确保操作的可逆性和准确性,特别适合后端的数据迁移和批量处理场景。
[AFFILIATE_SLOT_2]高级技巧:提供可执行工具脚本
即使Claude能写代码,为复杂逻辑预置工具脚本也更可靠、更省token。例如,提供一个analyze_log.py脚本来解析特定格式的日志,并在Skill指令中说明“运行此脚本以获取指标”。
Tool Scripts
analyze_form.py: Extract all form fields from PDF
bash
python scripts/analyze_form.py input.pdf > fields.json
Output format:
json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
validate_boxes.py: Check for boundary box overlaps
bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
fill_form.py: Apply field values to PDF
bash
python scripts/fill_form.py input.pdf fields.json output.pdf
必须避免的常见反模式:
- ❌ 使用Windows风格路径:始终使用Unix风格(
/)以保证跨平台兼容性。 - ❌ 提供过多选项:给出一个清晰、推荐的默认方法,而非让Claude在众多选择中困惑。
- ❌ 深层嵌套引用:保持文件引用层级扁平,最好只有一级深度。
- ❌ 描述中使用第一人称:牢记
description必须使用第三人称。
description: I can help you process Excel files and generate reports.description: Process Excel files and generate reports. Use when working with spreadsheets or when the user mentions Excel, CSV, or data analysis.Claude Skills系统将AI从被动的问答工具,转变为主动融入你工作流的领域专家。通过封装知识,它能:
- ⏱️ 极大提升效率:告别重复的上下文说明。
- ✅ 保障输出一致性:标准化团队内的代码审查、API设计等流程。
- 实现知识资产化:将个人或团队的**实践沉淀为可复用的数字资产。
对于后端开发者而言,可以从创建一个“微服务间通信规范检查”或“数据库查询优化建议”Skill开始。随着Skills库的丰富,Claude将愈发深入地理解你的整个后端架构,成为你不可或缺的超级协作者。
“把你反复向 Claude 解释的偏好、流程、领域知识打包成 Skills,让 AI 成为你的领域专家”
立即开始,识别一个你最常重复解释的后端任务,将其构建成你的第一个Skill吧。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/276962.html