
Cluade opus 4.6 推出Agent Teams,实现Agent任务规划处理,调用subAgent 进行执行,实现SubAgent之间的通信。我常用OpenCode 主打开源工具持续跟进最新的实现方式。
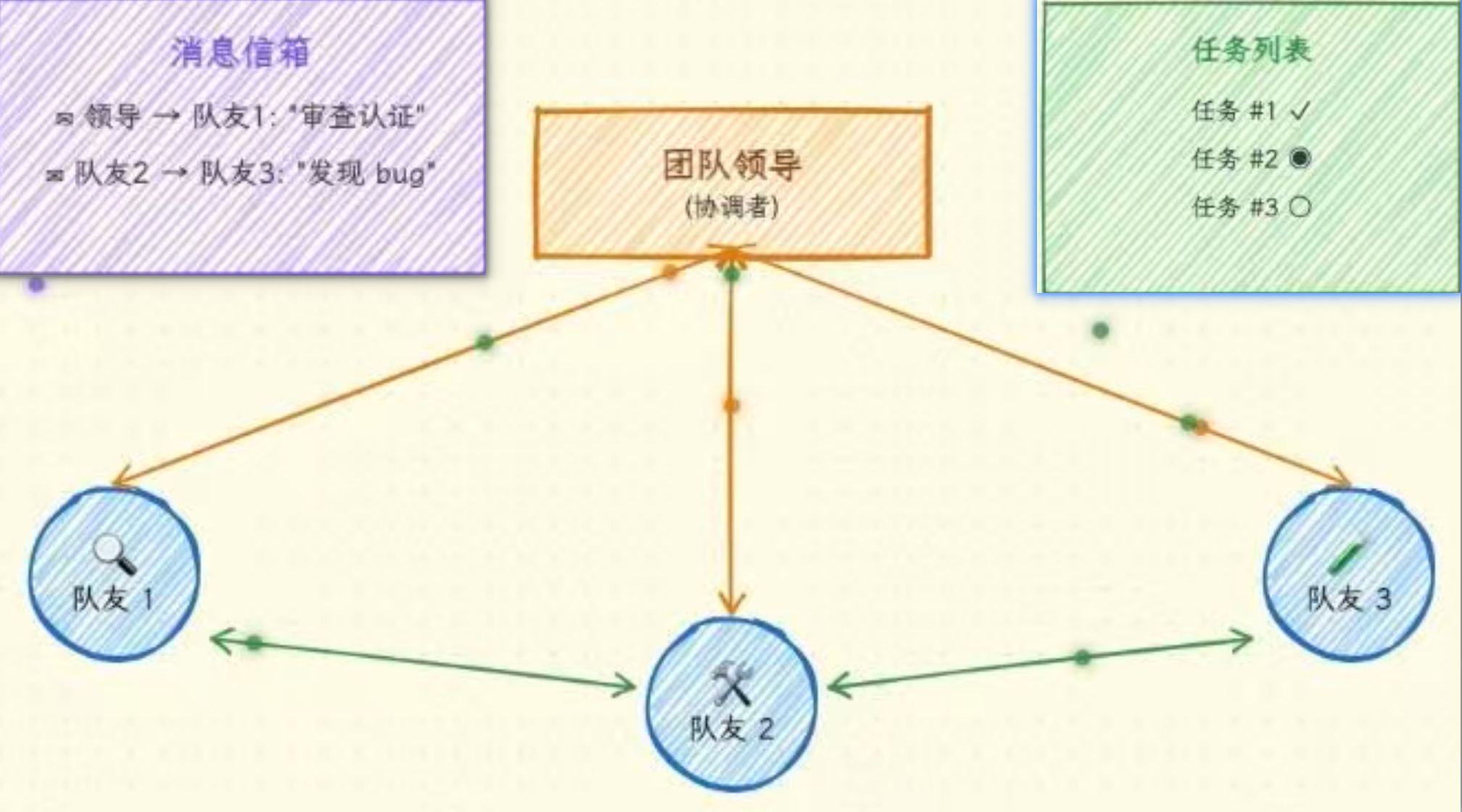
1.1 Agent Teams 的优势
维度 优势
内置协作 内置 write/broadcast 通信机制,开箱即用
生命周期管理 内置 spawnTeam/discoverTeams/cleanup,完整的生命周期
优雅关闭 内置 requestShutdown/approveShutdown,确保任务完整性
简单易用 无需手动管理 session,自动处理上下文
深度集成 与 Claude Code 深度集成,无缝协作
1.2 OpenCode 的优势
维度 优势
高度灵活 可自定义通信方式,不受固定协议限制
丰富的工具 LSP、AST Grep、MCP 等强大的工具层
技能生态 可复用的 Skills,便于共享**实践
规则系统 Rules 层提供强大的全局约束能力
成本优化 支持国产模型,成本仅为 Claude 的 2-20%
本地部署 支持本地部署,数据隐私有保障
1.3 适用场景
使用 Agent Teams 的场景
✅ 推荐:
- 快速原型开发
- 不需要定制化的协作逻辑
- 预算充足,追求极致体验
- 使用 Claude 生态系统
❌ 不推荐:
- 需要自定义通信协议
- 成本敏感的场景
- 需要本地部署
- 与其他 AI 模型集成
2.1 通用**实践
1. 明确任务边界
不好的做法:
- 任务描述过于模糊:“帮我实现用户系统”
- 缺少具体要求和验收标准
好的做法:
- 详细描述需求:
- 实现用户认证功能(注册、登录、JWT、密码重置、登出)
- 技术栈:TypeScript + Express
- 验收标准:
- 单元测试覆盖率 >80%
- 通过 ESLint 检查
- 不使用 any 类型
2. 合理拆分任务
不好的做法:
- 任务太大:“实现整个用户系统”
- 涉及文件过多:
src/* - 单个 Worker 难以完成
好的做法:
- 将大任务拆分为多个小任务:
- 任务 1:实现用户注册 API
- 任务 2:实现用户登录 API
- 任务 3:实现 JWT 中间件
- 每个任务涉及的文件数量合理
- 每个 Worker 可以在 30-60 分钟内完成
3. 设置合理的审批阈值
根据项目复杂度调整阈值:
项目复杂度 审批阈值 说明 simple 7 简单项目,7 分及以上即可通过 medium 8 中等复杂度,8 分及以上通过 complex 9 复杂项目,需要 9 分及以上
这样可以根据项目实际情况调整审查标准,避免过于严格或过于宽松。
4. 周期性清理上下文
清理流程:
- 设置最大 session 期限(如 1 小时)
- 定期检查所有 Workers 的 session 年龄
- 如果 session 超过最大期限:
- 调用 background_cancel 取消后台任务
- 从 Workers 列表中删除
- 记录清理日志
- 这样可以避免上下文无限累积,节省资源
2.2 OpenCode 特定实践
1. 充分利用 Tools 层
不好的做法:
- 让 AI 自己找文件:“请自己找相关的文件”
- AI 可能找到不相关或过时的文件
好的做法:
- 使用 Tools 层精确获取上下文:
- 使用 LSP 获取文件中的符号定义
- 使用 AST Grep 查找依赖关系
- 构建精确的上下文信息
- 这样可以减少 AI 的搜索时间,提高准确性
2. 合理选择 Category
根据任务类型选择合适的 Category:
任务类型 Category 说明 修复拼写错误 quick 简单任务,快速执行 添加注释 quick 简单任务,快速执行 架构设计 ultrabrain 复杂逻辑,需要深度推理 调试复杂问题 ultrabrain 复杂逻辑,需要深度推理 UI 组件开发 visual-engineering 前端/UI 相关 动画实现 visual-engineering 前端/UI 相关 编写文档 writing 文档撰写 API 文档 writing 文档撰写
合理选择 Category 可以优化性能和成本。
3. 合理选择 Skills
根据任务需求选择合适的 Skills:
任务类型 推荐的 Skills 说明 后端开发 code-philosophy, git-master 代码风格 + Git 操作 前端开发 frontend-ui-ux, playwright UI/UX + 浏览器测试 代码审查 code-review 代码审查流程 Git 操作 git-master Git 操作 文档编写 writing 文档撰写
使用合适的 Skills 可以提高任务完成质量。
4. 利用 Rules 层强制约束
Rules 层配置示例:
配置项 值 说明 enforce true 强制执行规则 naming.variables camelCase 变量使用小驼峰 naming.functions camelCase 函数使用小驼峰 formatting.indent 2 缩进 2 个空格 formatting.quotes double 使用双引号 forbidden_patterns console.log, any type 禁止的模式
作用:
- 即使 AI 生成不符合风格的代码,也会被 Rules 层自动拒绝或提示修改
- 确保所有生成的代码符合项目标准
- 提高代码质量的一致性
2.3 性能优化
1. 并行优化
好的做法:
- 同时启动所有 Workers:
- 使用 Promise.all 并行创建所有后台任务
- 所有 Workers 同时开始执行
- 总执行时间取决于最慢的那个 Worker
不好的做法:
- 串行启动 Workers:
- 使用 for 循环逐个创建 Worker
- 每个 Worker 启动后才启动下一个
- 总启动时间 = 所有 Worker 启动时间之和
性能对比:
- 并行启动:N 个 Worker,总启动时间 ≈ max(各 Worker 启动时间)
- 串行启动:N 个 Worker,总启动时间 = sum(各 Worker 启动时间)
2. 成本优化
使用更经济的模型:
模型 成本(输入/输出) max_tokens qwen3-coder-next
\(0.07/\)0.30/M 4000 glm-4.7
\(0.60/\)2.20/M 8000
成本对比(相对于 Claude Opus 4.6):
- Claude Opus 4.6: \(5/\)25/M(基准)
- GLM-4.7: 12% 成本
- Qwen3-Coder: 1.2% 成本
优化策略:
- 简单任务使用更便宜的模型(qwen3-coder)
- 复杂任务使用最强的模型(glm-4.7)
- 根据 task complexity 动态选择模型
3. 上下文优化
主要受限于与调用模型,比如DeepSeek v3.2 只支持128k的上下文,GLM-4.7 上下文窗口支持 200K,太多内容丢失,太少关键信息不足。
优化原则:
- 只传递必要的上下文
- 限制文件数量(如最多 15 个)
- 限制符号数量(如最多 20 个)
- 使用 AST Grep 只获取需要的符号
上下文构建流程:
- 只读取任务相关的文件
- 使用 LSP 获取精确的符号定义
- 过滤和精简上下文信息
- 构建精简的上下文对象
优势:
- 减少 token 使用量,降低成本
- 提高响应速度
- 减少噪音,提高准确性
3.1 核心要点
- Claude Agent Teams 是 Anthropic 内置的多智能体协作系统,提供了完整的生命周期管理、协调机制和优雅关闭流程。
- OpenCode 四层架构(Agents + Skills + Tools + Rules)通过灵活的组合实现了类似甚至更强大的多智能体协作能力。
- 实现核心:在 OpenCode 中实现 Claude Agent Teams 的关键在于:
- 使用
delegate_task的 background 模式实现并行执行 - 使用
session_id维护上下文连续性 - 使用 Skills 层封装可复用流程
- 使用 Rules 层定义全局约束
- 使用 Tools 层获取精确的代码上下文
- 使用
- 选择建议:
- 如果追求开箱即用、简单易用 → Claude Agent Teams
- 如果需要高度定制、成本优化、本地部署 → OpenCode
3.2 展望
随着 AI 技术的发展,多智能体协作系统将变得更加成熟和易用:
- 更智能的协调机制:自动识别任务依赖、动态调整资源分配
- 更强的可观测性:实时监控 agent 行为、性能分析和调试支持
- 更丰富的工具生态:更多的 MCP 服务器、更多的 Skills
- 更低的使用成本:更高效的推理、更好的成本优化
7.3 给开发者的建议
- 从小任务开始:先从简单的功能或 bug 修复开始,逐步增加复杂性
- 建立你的 Skills:定义项目特定的技能和**实践
- 设置合理的规则:使用 Rules 层强制代码风格和约束
- 保持人工监督:始终审查 Agent 生成的代码,不要完全信任
- 持续学习和优化:关注技术发展,优化你的 agent 团队配置
- Anthropic:《Introducing Claude Opus 4.6》
- Anthropic:《Claude Code 2.1 Release Notes》
- OpenCode 文档:https://opencode.dev/docs
- Cursor Blog:《Scaling long-running autonomous coding》
- TechCrunch:《Anthropic launches Claude Opus 4.6 with 1M token context》
- Medium:《Implementing Multi-Agent Systems with OpenCode》
- GitHub:https://github.com/anthropics/claude-code
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/275077.html