
2026年2月5日,Anthropic 正式发布了其最新旗舰模型 Claude Opus 4.6。这不仅是 Claude 系列中最强大的模型,更通过引入”Agent Teams”(智能体团队)功能,标志着 AI agent 从单兵作战正式迈向多智能体协作的新时代。
这次更新在技术指标上树立了新标杆,同时通过深度产品化——Office 工具集成、代理团队架构——将前沿 AI 能力转化为实际生产力工具。正如 Notion 的 AI Lead Sarah Sachs 所评价的那样:”Claude Opus 4.6 感觉不再像是一个工具,而更像是一个有能力的协作者。”
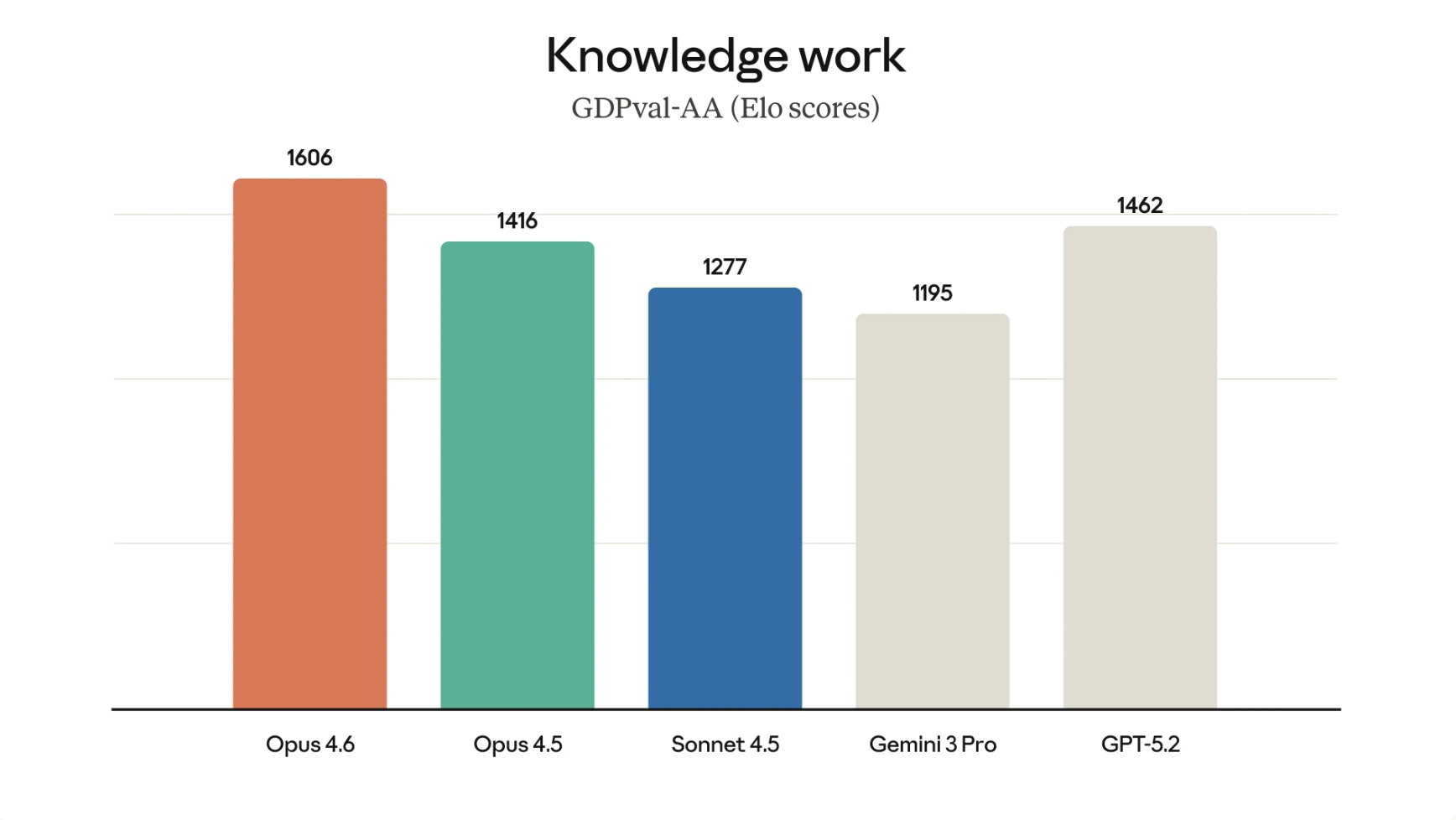
Opus 4.6 是在 Opus 4.5 基础上的又一次重大飞跃,在多个关键能力上实现了显著跃升。
Opus 4.6 在编程能力上实现了质的提升:
- 更谨慎的任务规划:能够避免盲目执行,在开始行动前进行充分的思考和准备
- 大型代码库操作:可以在复杂的项目结构中更可靠地导航,理解数百万行代码的组织关系
- 主动代码审查与调试:能够发现并纠正自己的错误,在编码过程中形成自我纠错机制
- 长期代理任务执行:能够维持对复杂任务的理解,在长时间会话中保持连贯性
这些能力的提升在实际应用中得到了验证。在 Terminal-Bench 2.0 这个真实世界代理编码评估中,Opus 4.6 取得了最高分。在 SWE-bench Verified 上也表现出色。Rakuten 的测试案例更为直观:Opus 4.6 在一天内自主关闭了 13 个 issue,并将 12 个 issue 正确分配给合适的团队成员,管理一个约 50 人的组织、6 个代码仓库。
GitHub 的首席产品官 Mario Rodriguez 的评价印证了这一点:"早期测试显示 Claude Opus 4.6 能够胜任开发者每天面临的复杂、多步骤编码工作——尤其是需要规划和工具调用的代理工作流。"
这是 Opus 级别模型首次提供 100 万 token 的上下文窗口(Beta 版),这一突破带来了三个直接影响:
信息检索能力的质变:在海量文档中精准定位隐藏信息的能力大幅提升。在 MRCR v2 的 8-needle 1M 变体测试中,Opus 4.6 达到 76% 的分数,而 Sonnet 4.5 仅为 18.5%。这意味着 Opus 4.6 在海量文本中寻找特定信息的能力远超同类模型。
长期连贯性的保持:能够处理数百万级别的长上下文而不出现"上下文腐烂"(context rot)现象,保持信息追踪的一致性。在 Vending-Bench 2 测试中,Opus 4.6 比前代 Opus 4.5 多赚取了 3,050.53 美元,展示了在长时间任务中的持续注意力。
更大的输出能力:支持最多 128k token 的输出,无需多次请求即可完成大型任务。这对于生成大型代码库、完整文档、复杂报告等任务至关重要。
Thomson Reuters 的 CTO Joel Hron 指出:"Claude Opus 4.6 代表了长上下文性能的有意义飞跃。在我们的测试中,我们看到了它以更高的一致性处理更大规模信息的能力。"
Opus 4.6 引入了更智能的推理控制机制,这是针对实际使用中"过度思考"问题的解决方案:
Adaptive Thinking(自适应思考):模型可以根据上下文线索自动判断何时需要使用扩展思考,而不是简单的开/关二选一。这意味着对于简单问题,模型会快速响应;对于复杂问题,则会投入更多计算资源进行深度推理。
Effort Controls(努力级别控制):提供四个档位——low、medium、high(默认)、max,开发者可以在智能程度、速度和成本之间找到平衡点。Anthropic 官方建议:如果发现模型在特定任务上"过度思考",可以将 effort 从默认的 high 降为 medium。
这一机制的引入是对开发者反馈的直接回应。正如 Windsurf CEO Jeff Wang 所言:"Opus 4.6 思考时间更长,这在需要深度推理的任务上得到了回报。"
这是 Opus 4.6 最引人注目的创新,也是 AI agent 发展史上的一个重要节点。
传统的 AI agent 工作模式是串行的——一个 agent 逐步完成任务。这种方式虽然简单直接,但在处理复杂任务时面临效率瓶颈:单 agent 受到上下文窗口和计算资源的限制,且无法充分利用并行计算能力。
Agent Teams 则将任务拆分给多个 agent,每个 agent 拥有自己的责任范围,直接协调并并行工作。Scott White,Anthropic 的产品负责人,将这一功能比作"拥有一个天才团队为你工作", noting that segmenting agent responsibilities allows them "to coordinate in parallel [and work] faster."
根据技术社区的挖掘和官方文档,Agent Teams 的核心架构包括完整的生命周期管理、协调机制和优雅关闭流程:
Team Lifecycle(团队生命周期):
spawnTeam/discoverTeams/cleanup— 创建、发现和清理团队requestJoin/approveJoin/rejectJoin— 团队成员加入流程
Coordination(协调机制):
write(直接消息)/broadcast(群发消息)— 点对点和广播通信机制approvePlan/rejectPlan— 计划审批流程
Graceful Shutdown(优雅关闭):
requestShutdown/approveShutdown/rejectShutdown— 确保任务完整性的关闭流程
目录结构也已经完整定义:
~/.claude/ ├── teams/{team-name}/ │ ├── config.json │ └── messages/{session-id}/ └── tasks/{team-name}/ 有趣的是,技术社区在 Claude Code 2.1 的二进制文件中发现了 TeammateTool 的完整实现——尽管在发布时被功能标记关闭。2026年2月6日,这个功能被正式开启,用户可以通过 CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 环境变量启用。这表明 Anthropic 在产品发布前就已经完成了完整的架构设计和实现。
Agent Teams 特别适合以下类型的任务:
代码库审查:多个 agent 并行检查不同模块,各自负责独立的上下文窗口,最后汇总发现。这种方式比单一 agent 串行审查效率高出一个数量级。
多领域研究:不同 agent 负责不同信息源的检索和整合。例如,一个 agent 负责技术文档,另一个负责市场报告,第三个负责竞品分析,最后由团队 leader 综合所有信息。
复杂工作流:将大型任务拆解为独立的子任务并行处理。例如,在软件开发中,一个 agent 负责后端 API 设计,另一个负责前端界面实现,第三个负责测试用例编写,最后进行集成。
人工干预机制:开发者可以通过 Shift+Up/Down 或 tmux 快速接管任何子 agent,实现人工干预和协作。这种设计在自动化和人类监督之间建立了灵活的平衡。
与 Opus 4.6 相伴发布的 Claude Code 2.1,表面上看是三个增量功能:技能热重载(skill hot-reload)、生命周期钩子(lifecycle hooks)、和分支子智能体(forked sub-agents)。但实质上,这标志着 Claude Code 从"终端代码助手"演变为全功能的 agent 操作系统。
Skill-Scoped Hooks(技能作用域钩子):实现可移植的治理机制。技能级别的钩子允许在特定任务前后执行操作,类似传统软件的中间件。这意味着技能可以携带自己的前置和后置逻辑,实现细粒度的控制和审计。
Sub-Agent Isolation(子智能体隔离):创建"策略孤岛"。每个子 agent 在独立的上下文窗口中运行,互不干扰,便于实施细粒度的权限和策略控制。这种隔离不仅提高了安全性,还便于调试——当某个 agent 出现问题时,不会影响其他 agent 的运行。
Hook Emission(钩子事件发射):作为 agent 间的事件总线。钩子触发的事件可以被其他 agent 监听和响应,实现松耦合的协调。这种设计为复杂的 agent 协作模式奠定了基础。
这些特性结合起来,使得开发者可以构建"可移植的治理"、"策略孤岛"和"代理间事件总线",解锁了之前不可能的架构模式:受监督的 agent 群体、动态任务委托、分布式治理等。
Claude Code 2.1 展示了一个明确的趋势:AI agent 平台正在向"操作系统"的方向演进。技能、钩子、子 agent、上下文管理这些概念,与传统操作系统的进程、线程、库、系统调用惊人地相似:
这种架构预示着未来可能出现:
- Agent 应用生态:类似移动应用商店的 agent 技能市场
- 治理框架:针对 agent 行为的标准化治理和安全机制
- 性能优化:agent 调度、资源管理、负载均衡等专业工具
正如 Medium 上的一篇文章所言:"这不是夸张。有了 2.1,开发者获得了仅使用 Markdown 文件、YAML frontmatter 和 shell 脚本构建实时、受控、多智能体系统的能力。不需要专有的 SDK,不需要复杂的插件架构。只有一个干净、可组合的运行时,将 agent 视为一等基础设施组件。"
Opus 4.6 的一个重要战略转向是扩展到更广泛的知识工作者群体。根据 Anthropic 产品负责人的表述,他们发现越来越多非软件工程师(产品经理、财务分析师等)也在使用 Claude Code,因为它是一个强大的任务执行引擎。
Claude in Excel(升级):能够处理更长期、更困难的任务,改进了性能。它可以在行动前规划,自动推断非结构化数据的正确结构,无需人工指导即可处理多步变更。这意味着用户可以将混乱的原始数据扔给 Claude,它会自动识别模式、构建表格、应用公式。
Claude in PowerPoint(研究预览):Claude 直接作为侧边栏集成到 PowerPoint 中。用户可以在 PowerPoint 内直接与 Claude 协作制作演示文稿,Claude 会读取布局、字体和幻灯片母版,保持品牌一致性。无论是从模板构建还是从描述生成完整演示文稿,都能无缝融入现有的设计体系。
Figma 的首席设计官 Loredana Crisan 评价道:"Claude Opus 4.6 在 Figma Make 中生成了复杂、交互式的应用和原型,具有令人印象深刻的创意范围。该模型能够一次性将详细设计和多层任务转化为代码,为团队探索和构建想法提供了强大的起点。"
这种集成将数据分析(Excel)和可视化呈现(PowerPoint)无缝连接,形成了完整的工作流闭环:用户可以在 Excel 中处理和结构化数据,然后将结果传递给 PowerPoint 生成演示文稿,整个过程由 Claude 统筹。
对于 Shortcut.ai 的联合创始人 Nico Christie 而言,"性能提升感觉几乎难以置信。Opus 4.5 感到具有挑战性的真实世界任务突然变得容易。这对于 Shortcut 上的电子表格代理来说感觉像是一个分水岭时刻。"
Opus 4.6 在多个基准测试中表现突出,展现了全方位的领先优势。
值得注意的是,GDPval-AA 的 144 Elo 点领先意味着在配对竞赛中,Opus 4.6 对战 GPT-5.2 的胜率约为 70%(50% 为平局)。这不仅是数值上的领先,更是实际应用中的显著优势。
长上下文检索:Opus 4.6 在从大型文档集合中检索相关信息的能力上表现卓越,能够保持数百万级别上下文中的信息一致性。
根本原因分析:在诊断复杂软件失败方面表现出色,OpenRCA 测试显示其能够准确识别失败的根本原因。
多语言编码:能够跨编程语言解决软件工程问题,展现了广泛的编程能力。
长期连贯性:在长时间任务中保持注意力,Vending-Bench 2 的结果证明了其持续性能。
网络安全:在发现真实代码库中的漏洞方面表现优于任何其他模型。CyberGym 测试显示,Opus 4.6 比前代模型在发现高严重性漏洞方面有显著提升。
Thomson Reuters 的测试案例最为直观:在 40 个网络安全调查中,Opus 4.6 在 38 次盲测中击败了 Claude 4.5。每个模型都在相同的代理测试装置上端到端运行,使用最多 9 个子 agent 和 100+ 工具调用。
生命科学:在计算生物学、结构生物学、有机化学和系统发育学测试中,Opus 4.6 的表现几乎是 Opus 4.5 的两倍。
Opus 4.6 的安全性能与 Opus 4.5 相当或更好,这一点尤为重要——在能力大幅提升的同时,安全性没有妥协:
- 最低的过度拒绝率(refusal of benign queries):在良性查询上的拒绝率是近期 Claude 模型中最低的,这意味着用户体验更加流畅
- 行为对齐:在欺骗、阿谀奉承、鼓励用户妄想等不当行为上保持低比率
- 针对性安全措施:针对其增强的网络安全能力,开发了六个新的网络安全探针以跟踪潜在滥用
- 防御性推动:同时推动其在防御性网络安全中的应用,如自动发现和修补开源软件漏洞
Anthropic 的红队(red.anthropic.com)在博客中写道:"Claude Opus 4.6 继续了 AI 模型网络安全能力有意义的提升轨迹。我们的观点是,这是一个快速行动的时刻——赋予防御者并在窗口存在时保护尽可能多的代码。"
可用性:已上线 claude.ai、API 及主流云平台。模型标识符为 claude-opus-4-6。
定价:25 每百万输入/输出 token(与 Opus 4.5 持平)。对于超过 200k token 的 1M 上下文请求,适用溢价定价 37.5。
美国本地推理:对于需要在美国境内运行的工作负载,提供 1.1× token 价格的美国本地推理选项。
Agent Teams 的推出标志着 AI 编程代理从"超级助手"向"超级团队"的转变。这种模式的深层意义体现在三个维度:
可扩展性:单 agent 受到上下文窗口和计算资源的限制,多 agent 团队可以通过并行处理突破这些限制。就像人类团队一样,更多"人手"意味着可以同时处理更多任务。
专业化:不同 agent 可以针对特定领域或任务类型进行优化。例如,一个 agent 专门负责代码审查,另一个负责测试用例生成,第三个负责文档编写。这种分工带来的效率提升是单 agent 无法比拟的。
容错性:一个 agent 的失败不会导致整个任务失败,其他 agent 可以继续工作。这种鲁棒性对于复杂的长期任务至关重要。
Replit 的总裁 Michele Catasta 的评价抓住了这一变化的本质:"Claude Opus 4.6 是代理规划的一大飞跃。它将复杂任务分解为独立的子任务,并行运行工具和子代理,并能精准识别阻塞点。"
随着 Opus 4.6 和 Agent Teams 的普及,开发者的工作方式正在发生根本性变化:
从"写代码"到"规划任务":开发者越来越多地扮演产品经理的角色,将高层次的业务目标交给 agent 团队执行。Vercel 的 v0 总经理 Zeb Hermann 指出:"我们只在开发者会真正感受到差异时才在 v0 中发布模型。Claude Opus 4.6 轻松通过了这一门槛。"
从"线性开发"到"并行协作":多 agent 可以同时处理代码审查、测试、文档撰写等任务,大幅提升开发效率。Ramp 的 Staff Software Engineer Jerry Tsui 表示:"Claude Opus 4.6 是我几个月来看到的最大飞跃。我更愿意给它一系列跨堆栈的任务并让它运行。它足够聪明,可以为各个部分使用子代理。"
从"手动调试"到"自主修复":Opus 4.6 更强的代码审查和调试能力,让它能够在发现问题时自主修复,减少人工干预。Cognition 的 CEO Scott Wu 的评价证明了这一点:"Claude Opus 4.6 推理复杂问题的水平是我们前所未见的。它会考虑其他模型遗漏的边缘情况,并持续得出更优雅、更深思熟虑的解决方案。"
Claude Code 2.1 展示了一个明确的趋势:AI agent 平台正在向"操作系统"的方向演进。这种架构可能催生:
Agent 应用生态:类似移动应用商店的 agent 技能市场。开发者可以发布和分享特定的 agent 技能,用户可以按需组合使用。
治理框架:针对 agent 行为的标准化治理和安全机制。随着 agent 承担越来越多的自主任务,如何确保其行为符合预期和法规要求变得至关重要。
性能优化:agent 调度、资源管理、负载均衡等专业工具。就像操作系统需要进程调度器一样,agent 平台也需要类似的工具来优化资源利用。
Opus 4.6 的一个重要战略转向是扩展到更广泛的知识工作者群体。这不仅体现在 Office 工具的深度集成上,更体现在模型能力的设计上:
- 金融分析:能够处理复杂的财务数据,执行多步骤的计算和分析
- 法律推理:在 BigLaw Bench 上达到 90.2% 的分数,展现了专业领域的能力
- 研究工作:能够执行深度、多步骤的研究工作流,整合多个信息源
- 文档创作:能够创建、编辑和格式化各类文档,从技术报告到商业提案
Box 的 AI 负责人 Yashodha Bhavnani 指出:"Box 的评估显示性能提升了 10%,达到 68% 对比 58% 的基准,在技术领域接近完美分数。Claude Opus 4.6 在跨法律、金融和技术内容的多源分析等高推理任务上表现出色。"
Claude Opus 4.6 是一次全方位的重大升级,其核心价值在于:
让 AI 从"响应式工具"进化为"主动、可靠、多面手的协作者"
这种转变体现在多个层面:
- 技术层面:1M 上下文、自适应思考、多智能体协作
- 产品层面:Office 深度集成、Agent Teams 架构
- 生态层面:从开发者工具到知识工作者平台的扩展
对于开发者:
- 效率的质变:从线性执行到并行协作,生产力提升将呈指数级增长
- 技能的重定义:从"代码实现者"转变为"系统设计者"和"任务规划者"
- 新可能的开启:许多之前被认为过于复杂或不经济的工作,现在变得可行
对于企业用户:
- 成本优化:虽然单价与 4.5 持平,但效率提升意味着单位产出的成本降低
- 风险控制:多 agent 架构提供了更好的容错性和可观测性
- 竞争优势:率先采用先进 AI 工具的企业将在效率和创新上获得先发优势
对于知识工作者:
- 工作流自动化:从数据收集到分析再到呈现的全流程自动化
- 跨领域能力:不再受限于单一专业知识,可以处理跨学科的复杂任务
- 时间释放:将重复性、机械性的工作交给 AI,专注于高价值的创造性工作
Opus 4.6 和 Agent Teams 的发布,标志着 AI agent 发展历程中的一个重要里程碑。它不仅是模型能力的提升,更是一个新的协作范式的确立。
从历史角度看,这可能类似于从"个人计算"到"网络计算"的转变——单台计算机能力的提升固然重要,但网络互联带来的协作能力才是真正的变革。同样,单个 AI agent 的能力提升很重要,但多个 agent 协作带来的效率提升才是质变。
尽管 Opus 4.6 和 Agent Teams 展现了巨大的潜力,但仍面临一些挑战:
技术挑战:
- 多 agent 系统的可观测性和调试工具需要进一步完善
- 1M 上下文的性能和成本优化
- Agent Teams 的成熟度和稳定性需要经过大规模应用验证
伦理和社会挑战:
- 人机协作的边界需要明确:何时自动化、何时人工干预
- AI 自主决策的责任归属问题
- 对就业市场的影响和应对
竞争挑战:
- OpenAI、Google 等对手的快速追赶
- 技术优势窗口期的不确定性
- 生态系统的竞争:谁的 agent 平台能够吸引更多开发者和用户
正如 Andrej Karpathy 在社交媒体上所说,AI 带来的是一个”可编程的抽象层”,涉及 agents、subagents、prompts、contexts、memory、modes、permissions、tools、plugins、skills、hooks、MCP 等概念。这就像一个”强大的外星工具”,但没有说明书,每个人都在探索如何握住和操作它。
Opus 4.6 和 Agent Teams,正是 Anthropic 为这个世界提供的一份”说明书”的前几页。它告诉我们:
- 如何让多个 agent 协作完成任务
- 如何在保持安全的同时释放 AI 的潜力
- 如何将前沿技术转化为实际生产力工具
但这份说明书还远未完成。后面的篇章——如何构建可靠的 agent 生态系统、如何确保 agent 的可解释性、如何平衡自动化与人工监督——需要整个行业共同书写。
对于开发者和企业而言,现在是开始探索和实验的**时机。早期采用者将获得宝贵的经验和竞争优势;观望者则可能错失这一波技术变革的机遇。
正如 Bolt.new 的 CEO Eric Simons 所言:”Opus 4.6 一次性完成了功能完整的物理引擎,在单次通过中处理大型多范围任务。”
这句话或许是对 Opus 4.6 最好的总结——它能够在单次通过中完成复杂任务,而这正是 AI agent 从”助手”向”协作者”转变的关键。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/274559.html