
博文大纲: 1、为什么要分表? 2、MySQL分表 3、利用merge存储引擎实现分表 4、MySQL分区 讯享网
1、为什么要分表?
数据库数据越来越大,随之而来的是单个表中数据太多。以至于查询速度变慢,而且由于表的锁机制导致应用操作也搜到严重影响,出现了数据库性能瓶颈。
mysql中有一种机制是表锁定和行锁定,是为了保证数据的完整性。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。当出现这种情况时,我们可以考虑分表或分区。
2、MySQL分表
Mysql分表分为垂直切分和水平切分,具体区别如下:
垂直切分是指数据表列的拆分,把一张列比较多的表拆分为多张表 通常我们按以下原则进行垂直拆分: 把不常用的字段单独放在一张表; 把text,blob(binary large object,二进制大对象)等大字段拆分出来放在附表中;
经常组合查询的列放在一张表中; 垂直拆分更多时候就应该在数据表设计之初就执行的步骤,然后查询的时候用join关键起来即可。
注:只有myisam引擎的原表才可以利用merge存储引擎实现分表。
merge分表,分为主表和子表,主表类似于一个壳子,逻辑上封装了子表,实际上数据都是存储在子表中的。 我们可以通过主表插入和查询数据,如果清楚分表规律,也可以直接操作子表。
讯享网mysql> create database test; mysql> use test; mysql> create table member( -> id bigint auto_increment primary key, -> name varchar(20), -> sex tinyint not null default '0' -> )engine=myisam default charset=utf8 auto_increment=1; <!--插入数据--> mysql> insert into member(name,sex) values('tom1',1); mysql> insert into member(name,sex) select name,sex from member; <!--将上面第二条插入语句多执行几次,即可插入大量的数据--> mysql> select count(*) from member; <!--我这里插入了4096条数据--> +----------+ | count(*) | +----------+ | 4096 | +----------+ 1 row in set (0.00 sec)
2)对上面完整的表进行分表
分表注意事项: 子表和主表的字段定义需要一致,包括数据类型,数据长度等; 当分表完成后,所有的操作(增删改查)需要对主表进行,虽然主表并不存放实际的数据。 <!--创建两个分表,表结构必须和上面完整的表结构一致--> mysql> create table tb_member1 like member; mysql> create table tb_member2 like member; <!--创建merge引擎的表作为主表,并关联上面的两个分表--> mysql> create table tb_member( -> id bigint auto_increment primary key, -> name varchar(20), -> sex tinyint not null default '0' -> )engine=merge union=(tb_member1,tb_member2) insert_method=last charset=utf8; 注:在上面创建主表时,指定的“insert_method=last”有三个可选参数,分别是:last:表示插入到最后一张表里面;first:表示插入到第一张表里面;NO:表示该表不能做任何写入操作,只作为查询使用。
3)查看刚刚创建的三个表结构如下:
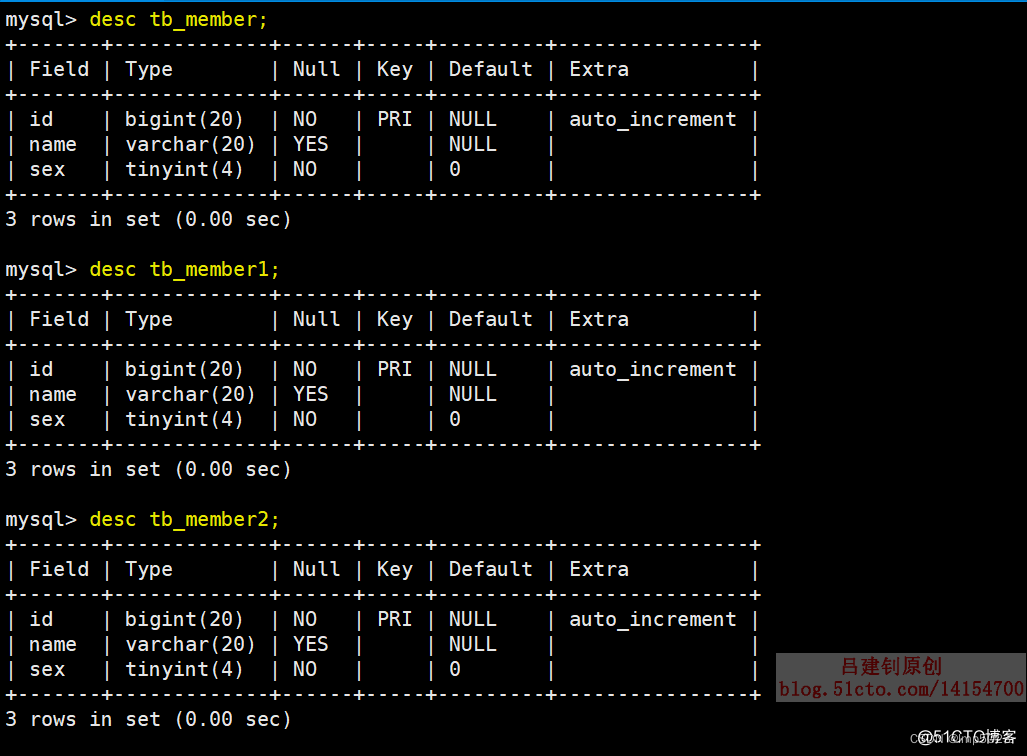
讯享网
4)将数据分到两个表中:
讯享网mysql> insert into tb_member1(id,name,sex) select id,name,sex from member where id%2=0; Query OK, 2048 rows affected (0.01 sec) Records: 2048 Duplicates: 0 Warnings: 0 mysql> insert into tb_member2(id,name,sex) select id,name,sex from member where id%2=1; Query OK, 2048 rows affected (0.01 sec) Records: 2048 Duplicates: 0 Warnings: 0
5)查看主表和两个子表中的数据
第一个子表部分数据如下:
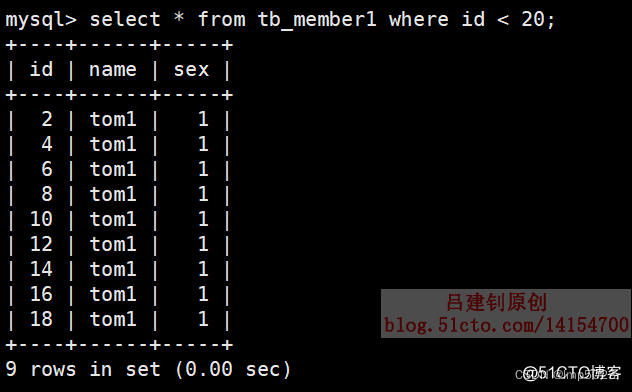
第二个子表部分数据如下:
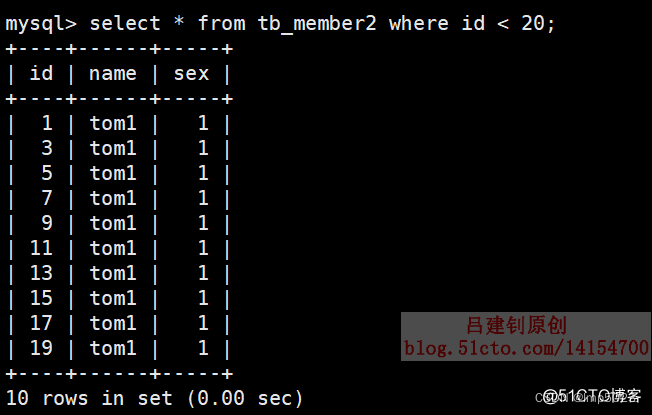
主表部分查询的部分数据如下:
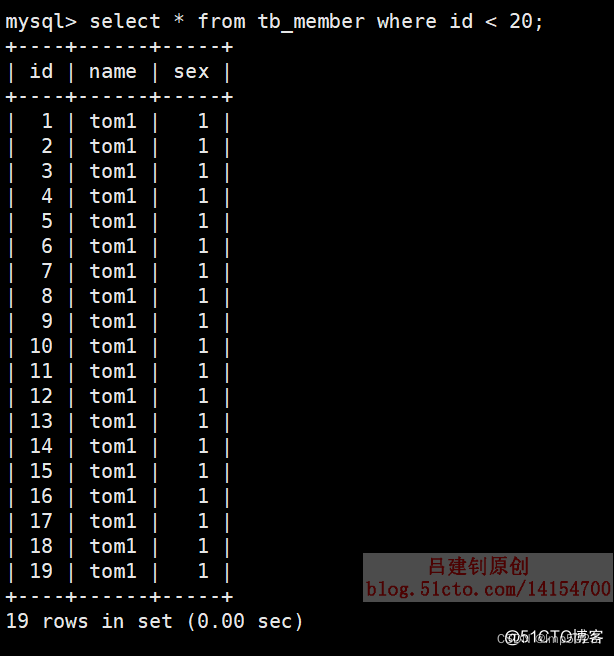
数据总行数如下:
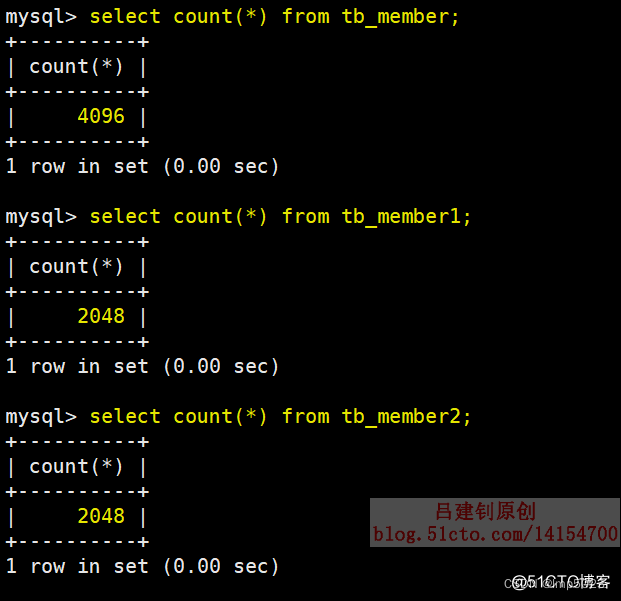
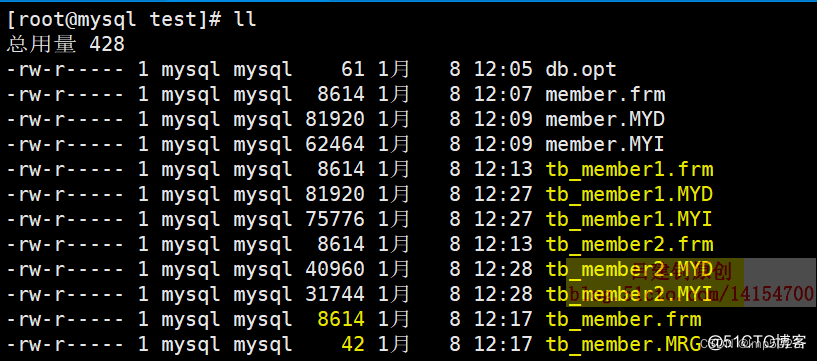
注意:总表只是一个外壳,存取数据发生在一个一个的子表里面。 每个子表都有自已独立的相关表文件,而主表只是一个壳,并没有完整的相关表文件,当确定主表中可以查到的数据和分表之前查到的数据完全一致时,就可以将原来的表删除了,之后对表的读写操作,都可以对分表后的主表进行。上面三个表对应的本地文件如下:
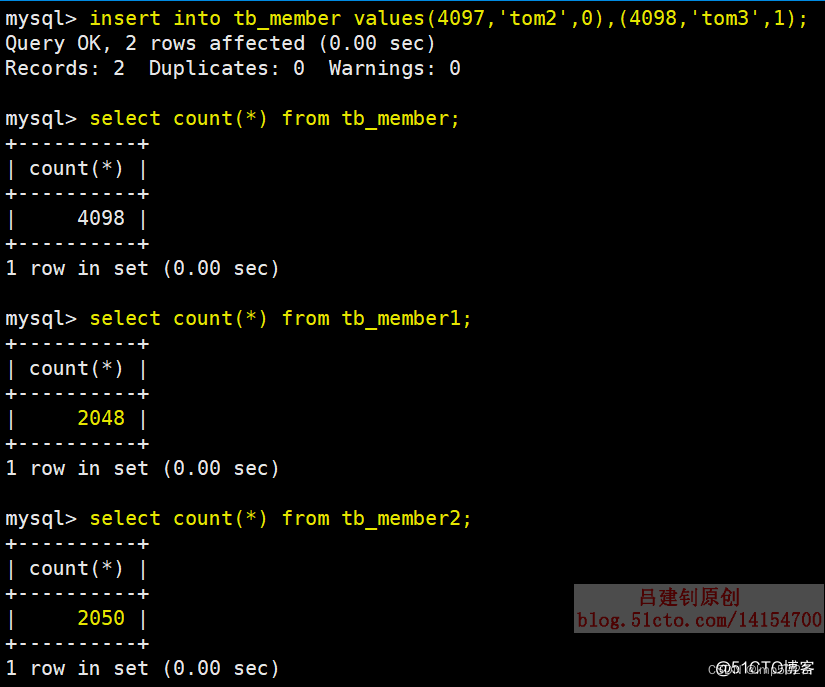
可以看出,新增的两条数据都插入在了第二张表中,因为在创建主表的时候,指定的“insert_method”是last,也就是所有插入数据的操作都是对最后一张表里进行的,可以通过alter指令修改插入方法,如下:
mysql> alter table tb_member INSERT_METHOD=first;
修改插入方法后,再自行对表进行插入数据的操作,可以发现所有的数据都写入了第一个表(我这里插入了四条数据),查看如下:
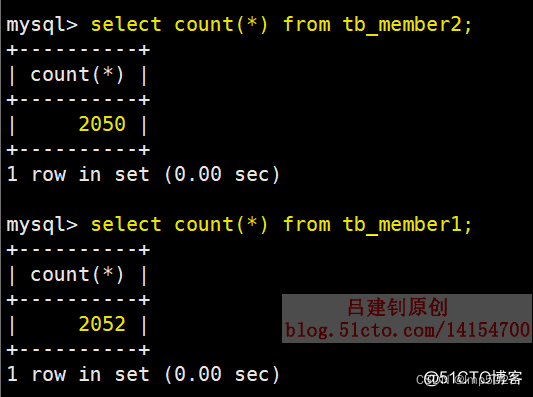
上面是新增了四条数据,可以发现都插入到了第一张表。
若将插入方法修改为no,则表示这个表不能再插入任何数据,如下:
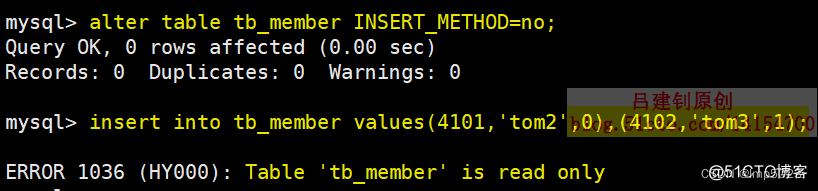
分区和分表相似,都是按照规则分解表。不同在于分表将大表分解为若干个独立的实体表,而分区是将数据分段划分在多个位置存放,分区后,表还是一张表,但数据散列到多个位置了。app读写的时候操作的还是表名字,db自动去组织分区的数据。
分区主要有以下两种形式:
水平分区:这种形式分区是对表的行进行分区,所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。
举个简单例子:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录。
垂直分区:这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
举个简单例子:一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。
2)查看当前数据库是否支持分区
MySQL 5.6之前,使用下面的参数查看当前配置是否支持分区(如果为yes则表示支持分区):
mysql> SHOW VARIABLES LIKE '%partition%'; +-----------------------+---------------+ |Variable_name | Value | +-----------------------+---------------+ | have_partition_engine | YES | +-----------------------+------------------+ 在5.6及以后采用以下方式查看:
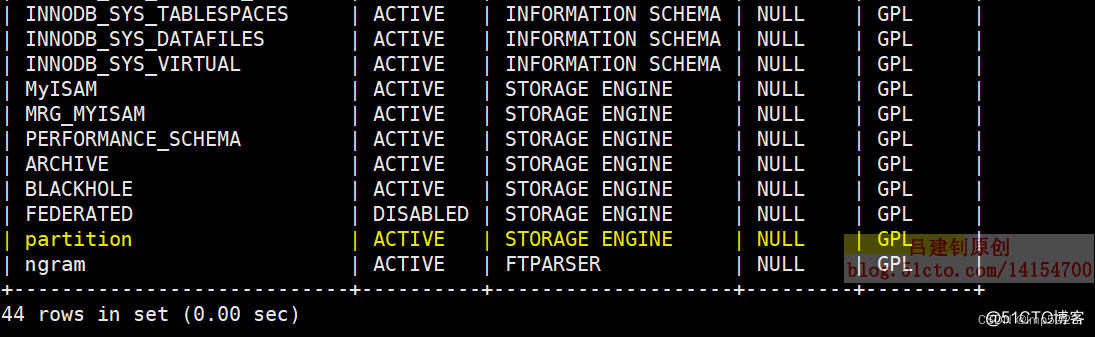
mysql> show plugins;
返回的结果中,有以下字段(如果status列为“ACTIVE”,则表示支持分区):

3)按照范围(range)方式的表分区
讯享网mysql> create table user( -> id int not null auto_increment, -> name varchar(30) not null default '', -> sex int(1) not null default '0', -> primary key(id) -> )default charset=utf8 auto_increment=1 -> partition by range(id)( -> partition p0 values less than (3), -> partition p1 values less than (6), -> partition p2 values less than (9), -> partition p3 values less than (12), -> partition p4 values less than maxvalue -> );
mysql> delimiter //

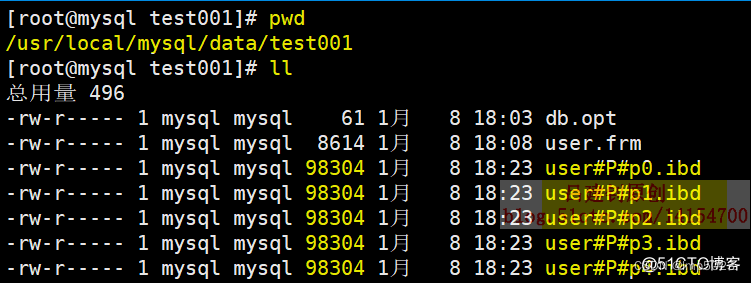
5)到存放数据表文件的目录下看一下:

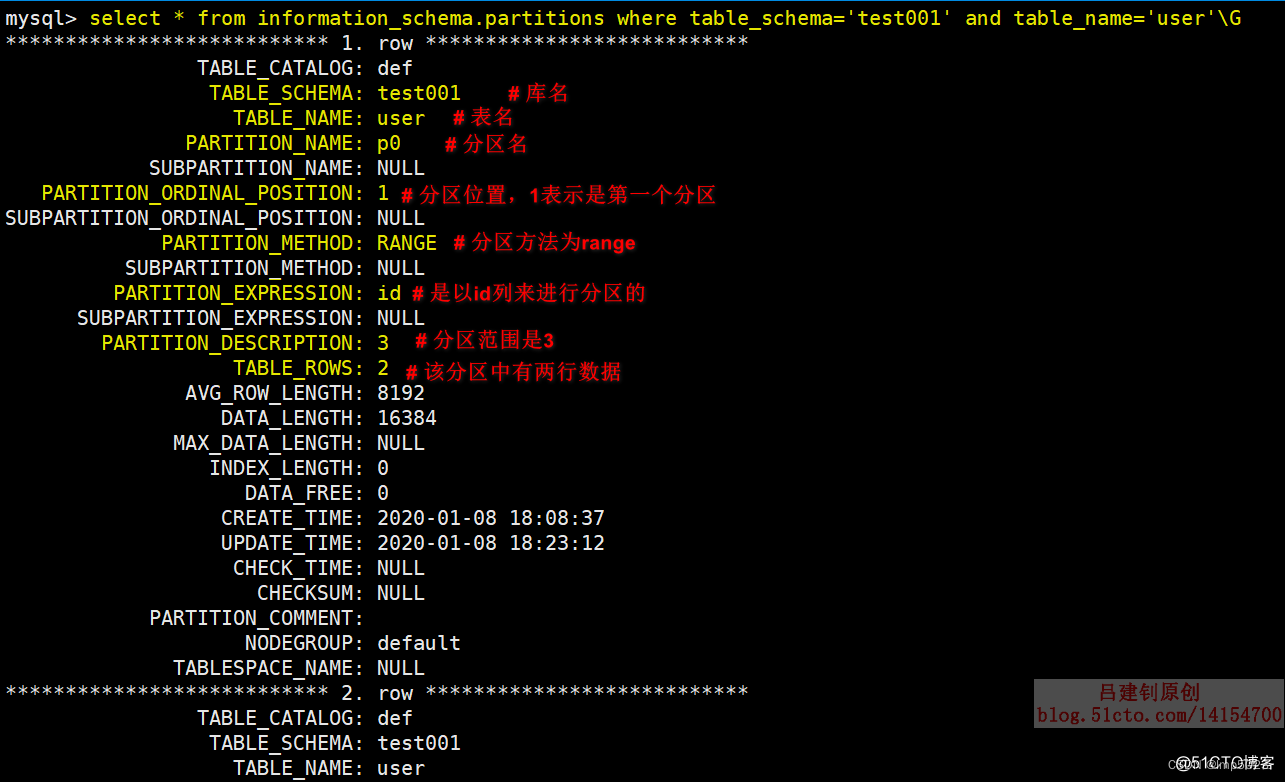
7)从information_schema系统库中的partition表中查看分区信息
8)从分区中查询数据
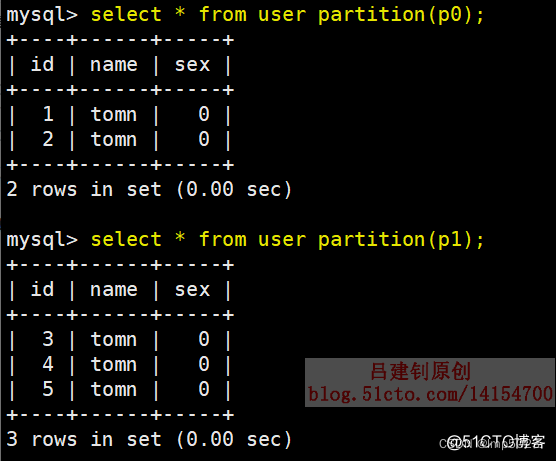
9)添加及合并分区(需要先合并分区再新增分区)
1.添加分区:
注意:由于在创建表的时候,指定的最后一个分区range是maxvalue,所以是无法直接增加分区的,如下:

大意是:MAXVALUE只能在最后一个分区定义中使用
但也不可以将最后定义了maxvalue的分区直接删除,因为删除分区的话,分区中的数据也会丢失,所以,如果需要新增分区的正确做法,应该是先合并分区,再新增分区,这样才可以保证数据的完整性,如下:
mysql> alter table user reorganize partition p4 into (partition p03 values less than (15),partition p04 values less than maxvalue );
上述命令的作用就是将最后一个分区分为两个分区,一个是自己所需要的分区,最后一个分区还是maxvalue(也必须是maxvalue),这样就完成了添加分区。
本地表文件如下:
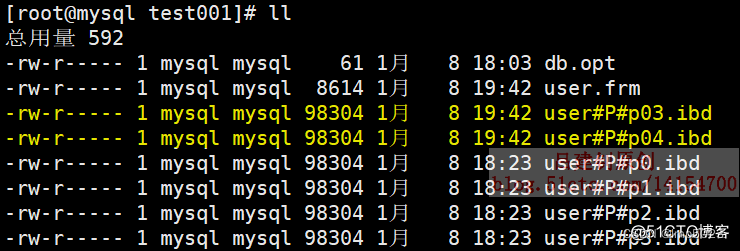
查询新增分区中的数据如下:
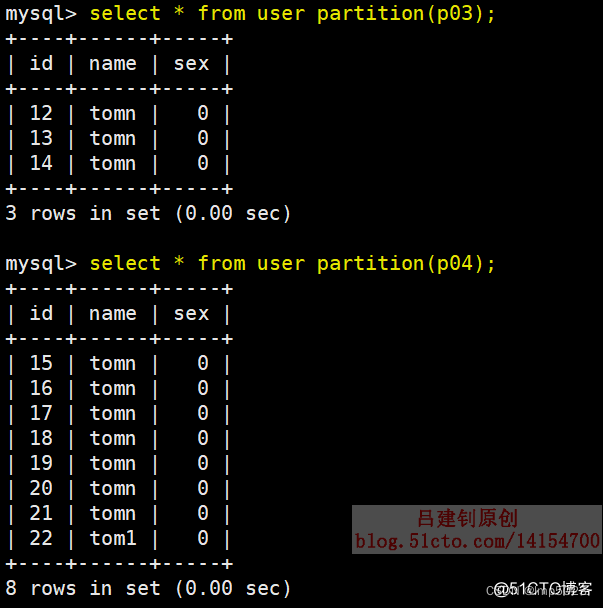
2.合并分区
将p0、p1、p2、p3四个分区合并为p02:
mysql> alter table user -> reorganize partition p0,p1,p2,p3 into -> (partition p02 values less than (12)); 可以看到p02将整合了p0,p1,p2,p3三个分区的数据,如下:
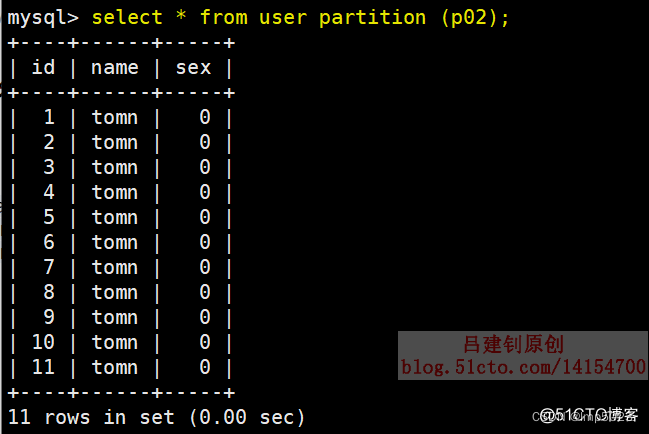
本地文件如下:
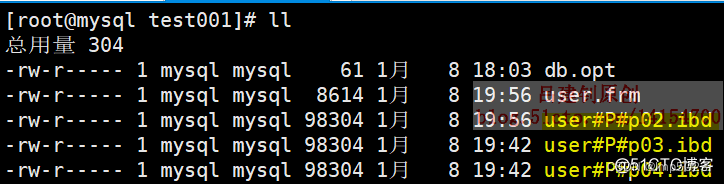
10) 删除分区
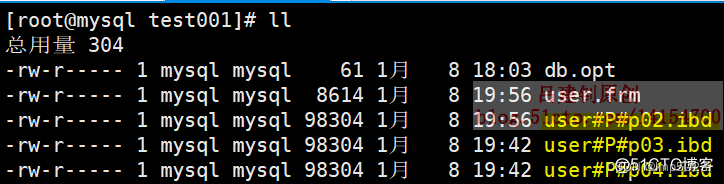
mysql> alter table user drop partition p02; #删除分区p02
注意:分区被删除后,分区中的数据也将被删除,删除分区p02的表中所有数据如下:
————————————————
版权声明:本文为CSDN博主「@ Ray」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lvjianzhaoa/article/details/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/27264.html