
过去几个月,Claude 对很多开发者来说,几乎像空气一样不可或缺。
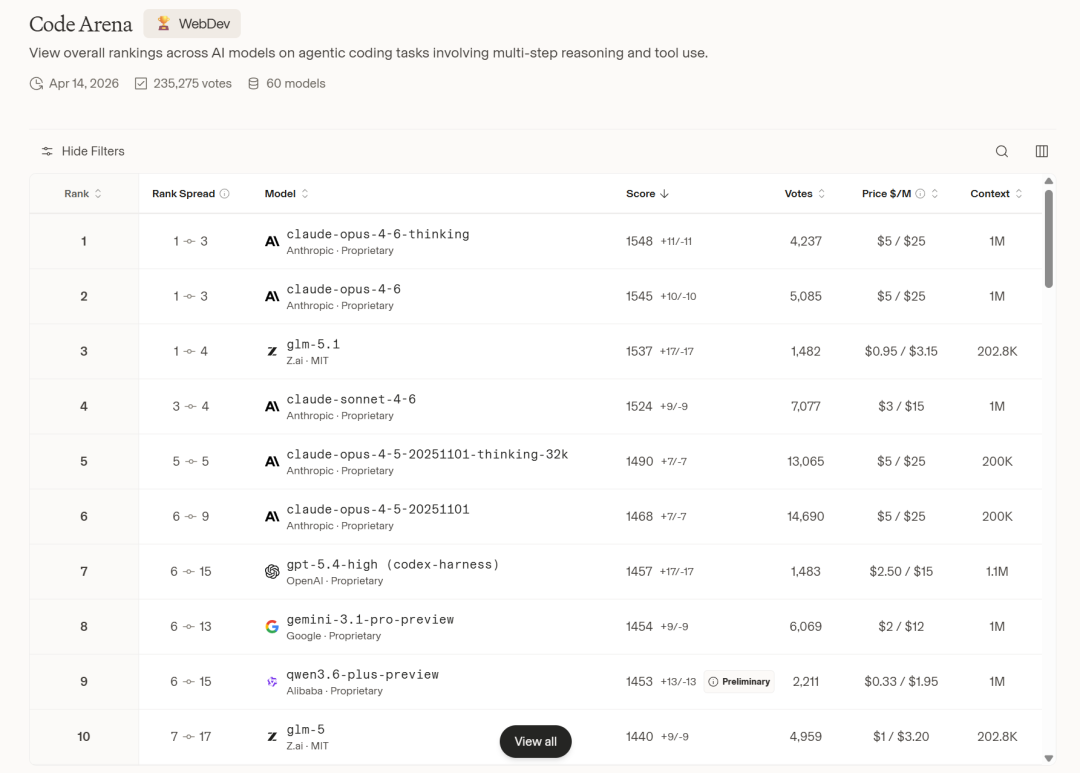
写代码时开着它,调试 bug 时用它找思路,构思技术方案时也离不开它的协助。这并非夸张,而是反映了其已深度嵌入不少开发者工作流的现实。在编程这个垂直赛道上,Claude 的实力有目共睹,并且被各种榜单长期验证。例如,在 Code Arena 的 WebDev 榜单中,Anthropic 的模型表现强势:Claude Opus 4.6 Thinking 位列第一,Claude Opus 4.6 紧随其后排名第二,即便是其“中杯”模型 Sonnet 4.6 也高居第四。
然而,最近 Claude 的一项新要求让局面骤变:用户需要提供政府签发的带照片身份证件,并可能通过摄像头完成实时自拍验证才能使用。此举性质突然发生了根本性转变。
这套流程实际上将大部分用户挡在了门外。即便持有护照的用户,也需要面对更高的实名门槛和由此带来的隐私顾虑。这绝不是一个普通的功能更新。
问题的核心在于,当公认的最强模型主动提高了使用门槛,开发者将如何重新分配资源与权衡利弊?是继续追求极致的性能,还是转向更稳定、更易获取的替代方案?
恰逢此时,两个名字被推到了讨论的风口浪尖。GLM-5.1 在 4 月 7 日发布时,官方直接将其定位为“面向智能体工程(agentic engineering)的新一代旗舰模型”。而另一边,Kimi 的开发者社区这两天也正在密集讨论 k2.6-code-preview 的实际表现。

它们并非一夜之间变得无懈可击,而是突然变得更值得开发者们认真审视了。
Claude 的帮助中心列出了验证所需的三种材料:政府签发的带照片证件、带摄像头的设备,以及几分钟时间。可接受的证件包括护照、驾照或州/省 ID、国民身份证等。官方同时明确表示,不接受截图、复印件、扫描件,也不接受移动端的数字证件。
这套流程本身并不复杂。五分钟,拍张照,完成验证,对许多用户而言甚至算不上麻烦。
但关键在于,它颠覆了一个默认的假设。过去,开发者在比较模型时,“能否用上”几乎不是一个变量。大家默认所有主流模型都是触手可及的,比较的焦点集中在能力、响应速度和价格上。Claude 的身份验证要求,第一次将“能否顺畅使用”也变成了一个关键的竞争维度。
有报道将这种影响具体化了。对于部分地区的用户而言,证件持有率本身就是第一道筛选,实名验证带来的隐私顾虑是第二道,而新账号注册的整体门槛叠加起来,构成了第三道。Claude 依然强大,但它第一次明确地把“可达性”也变成了一个需要被严肃对待的竞争变量。
这件事的意义不在于验证行为本身,而在于它将模型比较从一场“纯粹的能力竞赛”,拉回到了“能力、可达性加合规摩擦”的综合竞技场。这个判断并非凭空而来,而是由官方的验证要求和真实的社区舆论反应共同塑造的。
Claude 变得难用,并不意味着所有替代品都会自动受益。GLM 和 Kimi 被推到讨论中心,各有各的理由。
先说 GLM-5.1。4 月 7 日,Z.ai 通过官方博客和 GitHub 仓库同步发布信息,将 GLM-5.1 定义为“面向智能体工程的下一代旗舰模型”。并且它被明确设计为能够处理长程任务的模型,声称能在数百轮迭代和数千次工具调用中持续优化。
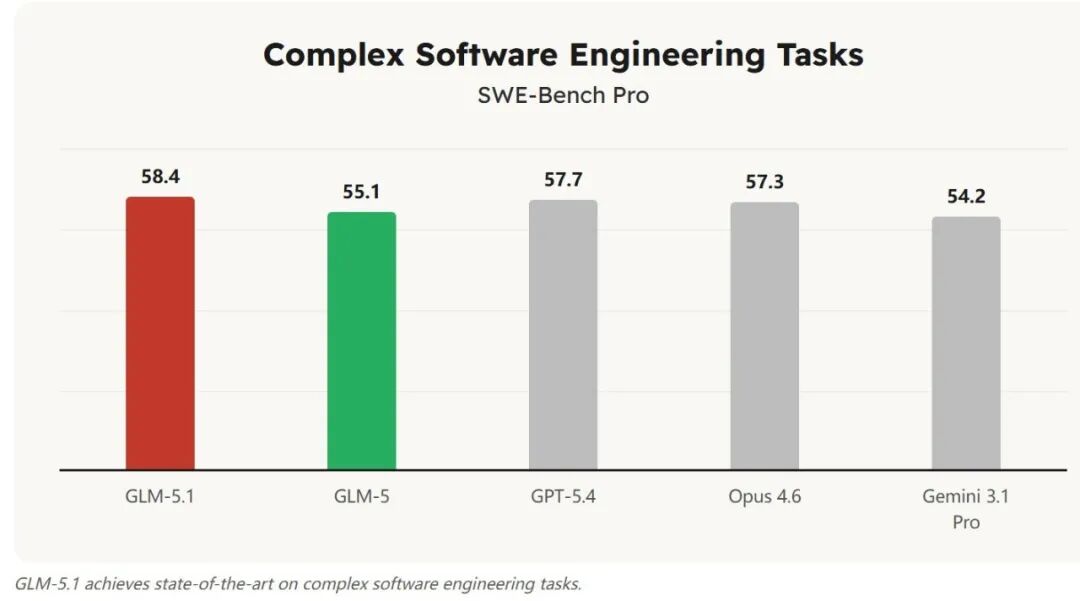
这个定位至关重要。因为它表明 GLM 已经能够在复杂的智能体工作流中提供稳定支撑。在 Code Arena 的榜单上,GLM-5.1 排名第三,位置在 Claude Sonnet 4.6 之前。虽然榜单不能完全代表所有真实场景,但这无疑是一个强烈信号,说明 GLM 真正进入了值得开发者认真评估的视野。
再说 Kimi。Kimi 这边的情况稍微复杂一些。从生态接入的角度看,其基础已经铺就。Moonshot 的官方平台文档早已提供了将 Kimi K2.5 接入 Claude Code、Cline、RooCode 和 OpenCode 等工具的教程,说明它本就不是一个脱离主流编程工具链的模型。
而在更大的 云计算与智能 生态层面,Cloudflare 在 3 月 19 日宣布将 Kimi K2.5 接入其 Workers AI 服务。官方博客中甚至写道,Cloudflare 内部工程师已经在 OpenCode 环境中将 Kimi 作为智能体编程的日常工具,并集成了自动代码审查流程。

这些信号非常有分量,属于实实在在的工程落地,其说服力远胜于寻常的基准测试跑分。
与此同时,MoonshotAI/kimi-cli 的 GitHub 仓库在 4 月 14 日到 15 日期间,连续出现了针对 k2.6-code-preview 的新问题单,内容涉及思考链过长、token 消耗巨大、以及与 Claude Code 的兼容性问题。
出现开发者关心的具体问题,恰恰证明了它已经被投入真实的高强度使用中。GLM 和 Kimi 这次被推到讨论中心,不只是因为它们变强了,也因为 Claude 亲手将“进入工作流的门槛”这件事重新变得至关重要。
这部分我想写成一种观察,而非定论。许多用户对本土模型表现出的态度,与其说是敌对,不如说是一种近距离、高标准的审视。
第一层原因是历史体验的积累。开发者们对模型的敏感度更高并非没有道理。过去几年,“跑分强悍但实际体验一般”、“发布频繁但稳定性不足”、“宣传声势大于实际交付”的循环出现过不止一次。这种经历会形成一种条件反射:面对新模型时,先挑刺,再认可。这并非偏见,而是一种被市场训练出来的审慎。
最近 Kimi 社区中关于 k2.6-code-preview 的讨论就是一个缩影。开发者们迅速从真实使用细节切入:思考链过长导致 token 消耗飙升、子代理调用不稳定、文件写入权限存疑……没有人因为其出身而自动放宽标准。
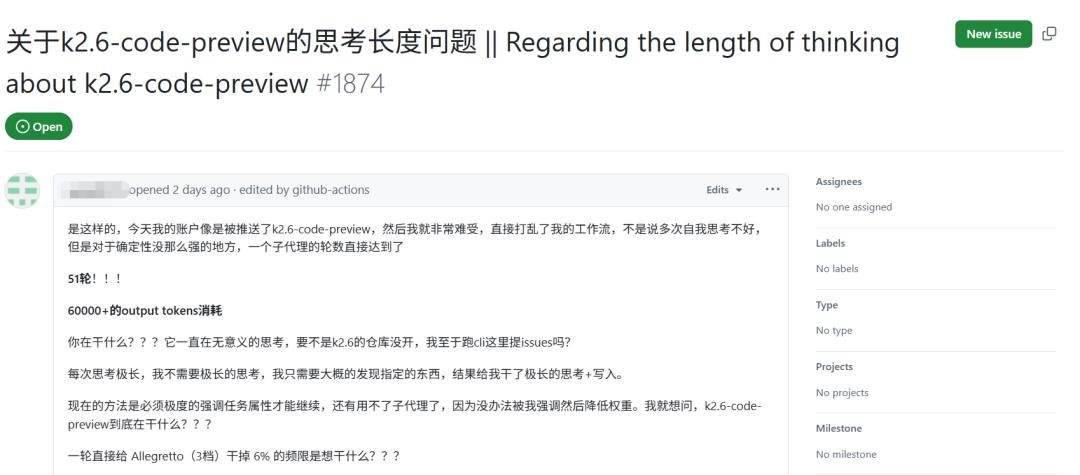
第二层原因是物理与心理上的“距离”。许多开发者并非旁观者,而是重度使用者。他们更快地触及到限额、token 消耗、插件兼容性、文件写入权限等具体问题。kimi-cli 仓库在 4 月 15 日一天内就出现了多条与插件、子代理、WriteFile 权限、Claude Code 兼容性相关的问题单。这种讨论氛围天然比泛泛而谈更为苛刻,因为提问的人都是真正在用,并且真的被问题卡住了。
所以,与其说这部分用户更敌对,不如说他们离问题更近,因此更早、更清晰地看到了缺陷。
这同样是一个倾向性观察。至少在部分 开发者生态 中,Kimi 和 GLM 更容易先被当作一个“是否应该集成”的技术选项来评估,而非先被贴上某种需要特殊审视的身份标签。
支撑这个观察的事实有三类。
第一类是平台级采用。如前所述,Cloudflare 将 Kimi K2.5 接入 Workers AI,这不是一个社区讨论,而是一个工程决策。当一个全球性的基础设施公司明确表示已将你的模型用于内部生产环境,这比任何第三方评测都更具说服力。
第二类是工具链集成请求。在一些主流 开源社区 的 GitHub issue 中,有开发者直接提出“将 Kimi 加入可用模型列表”,关注点并非其来源,而是“拥有更多模型选择将非常棒”。这不能证明“广泛好评”,但足以表明在某些工具社区里,Kimi 至少被认真看作一个值得集成的候选项。
第三类是客观的公开排位。GLM-5.1 在 Code Arena WebDev 榜单排名第三,位置高于 Claude Sonnet 4.6。它未必能代表所有真实工作流的结果,但在全球可见的公开比较体系中,它已经站到了一个不容忽视的位置。
这些开发者并不一定真心“喜欢”这些模型,但他们更倾向于先把模型跑起来,结合价格、任务难度和完成度进行实际评判,然后再决定是否长期投入。
Claude 提高门槛之后,AI 编程模型的竞争第一次从“神坛”比较,回归到了“工具”比较。
过去一段时间,开发者讨论模型的方式有时近乎讨论“信仰”——你用 Claude 还是 GPT,几乎成了站队标签。但这类讨论有一个根本前提:你得能用得上。如果这个前提被动摇,那么比较就失去了大部分意义。因此,评估工具的底层逻辑因为这次事件正在发生变化。
如果验证成本、合规摩擦等因素持续增强,那么未来的模型竞争将越来越像云服务甚至基础设施之间的竞争。各种性能榜单会继续存在,但“能否顺利接入”、“是否稳定可靠”、“综合成本如何”等方面的考量,其权重注定会变得越来越重要。
Claude 的身份验证、GLM-5.1 的长程智能体定位、Kimi 被 Cloudflare 等主流工具生态接纳——这三件事放在一起,才勾勒出当前局势的核心:并没有发生简单的“谁取代谁”,而是竞争的维度被拓宽和重构了。
那么,对你来说,在选择编程助手模型时,“能力的绝对天花板”和“能否顺畅、稳定地用起来”,哪个因素的权重更大?欢迎在 云栈社区 分享你的真实体验和看法。
声明:本文观点仅供参考,不构成任何投资或技术选用建议。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/269979.html