

正文
ArXiv URL:http://arxiv.org/abs/2604.11462v1
大语言模型(LLM)驱动的 Agent 被寄予厚望,人们期待它能像人类一样在复杂的数字世界中完成多步骤的长期任务。然而,一个严峻的现实是,当任务链条拉长,即使是当前最顶尖的模型,其表现也会急剧下降。问题的根源在于两大顽疾:“上下文瓶颈”(Context Bottleneck)与“中间遗忘”(Lost-in-the-Middle)现象。当 Agent 在网页浏览、信息检索等真实环境中持续互动时,海量的无关信息(即“噪声”)会不断涌入并堆积在模型的记忆中,迅速稀释关键信息的信噪比,最终导致推理链条的断裂和任务的失败。
为了解决这一难题,来自 CurrentsAI Research、斯坦福大学等机构的研究者们提出了一个名为 ActiveContext 的全新框架。其核心思想极具颠覆性:不再被动地扩大或检索上下文,而是引入一个轻量级的“记忆管家”模型,通过强化学习(RL)进行训练,使其学会主动地为负责执行任务的强大基础模型(LLM)管理和“净化”工作记忆。这种“共生式”架构将上下文管理与任务执行彻底解耦,让一个专门的 7B 模型(ContextCurator)扮演“认知建筑师”的角色,为冻结的、强大的“任务执行者”(TaskExecutor,如 Gemini 或 GPT-4o)动态筛选和提炼信息。
实验结果极为亮眼。在 WebArena 基准测试中,该框架将 Gemini-3.0-flash 的成功率从 36.4% 提升至 41.2%,同时还将 Token 消耗降低了 8.8%。在信息检索任务 DeepSearch 中,它更是实现了惊人的 8 倍 Token 节省。最引人注目的发现是,一个经过专门训练的 7B ContextCurator,在上下文管理这项任务上的表现,竟能与 GPT-4o 相媲美。这证明了上下文管理是一种可以被有效“外包”给小模型的独立认知技能,为构建更高效、可扩展且经济的自主 Agent 系统开辟了一条全新的道路。
问题的核心:当 Agent 迷失在信息噪声的海洋中
要理解 ActiveContext 的创新之处,我们必须先深入剖析当前 Agent 系统面临的困境。在执行长时程任务时,Agent 需要维护一个不断更新的工作记忆,记录历史观察和行动,以便为后续决策提供依据。然而,真实世界的数字环境充满了信息熵。例如,一个普通的网页,其 DOM(文档对象模型)中超过 90% 的内容都是结构性噪声,如广告、样式脚本、冗余的导航栏等。在进行多轮检索增强生成(RAG)时,搜索引擎返回的大量文档片段同样会引入语义噪声和干扰项。
当 Agent 将这些未经处理的原始信息流直接塞入其有限的上下文窗口时,灾难便开始了。Transformer 架构固有的“中间遗忘”效应使得模型难以关注到埋藏在冗长上下文中间的关键信息。随着交互轮次的增加,噪声不断累积,信噪比(SNR)急剧恶化。早期步骤中引入的微小偏差或无关信息,可能会在后续的推理中被放大,最终导致“级联式逻辑失败”(cascading logical failures),即一步错、步步错。研究者在实验中发现,即便是像 Gemini-3.0-flash 这样的前沿模型,在 WebArena 和 DeepSearch 上的原始成功率也仅为 36.4% 和 53.9%,这暴露了一个残酷的事实:单纯依靠暴力扩大上下文窗口,并不能保证有效的长程推理。问题的关键不在于容量,而在于上下文的质量。
过去,研究者们尝试了多种策略来缓解这一问题,但都存在局限性。
一类是被动式记忆系统,如 MemGPT 或各类 RAG 变体。它们将上下文管理视为一个静态的“检索”问题,通过语义相似度从记忆库中捞取信息。这类方法的弊端在于“检索偏见”(retrieval bias)。它们常常无法召回那些对于推理至关重要、但在文本上与当前查询并无直接相似性的“推理锚点”(reasoning anchors)。例如,任务早期获得的一个网址或一个特定指令,可能在后期某个完全不同的场景下才变得关键。
另一类是单体式学习架构,即试图让一个模型同时承担任务执行和记忆管理。这种方式造成了严重的“能力分裂”:小模型缺乏处理复杂逻辑所需的推理深度,而像 GPT-4 这样的大模型虽然强大,但其闭源、昂贵的特性使得对其进行直接的策略微调(on-policy fine-tuning)变得不切实际。
正是在这样的背景下,ActiveContext 提出了一种全新的解题思路。
破局之道:引入“认知建筑师”的主动上下文管理
ActiveContext 框架的核心,是将记忆管理从一个被动的存储工具,重塑为一个主动的、序贯决策过程。它采用了一种互补的“共生认知架构”,将系统解耦为两个高度专业化的组件:
- 任务执行者 (TaskExecutor):一个强大的、冻结的闭源或开源基础模型,如 GPT-4o 或 Gemini-3.0-flash。它的唯一职责是基于当前最高质量的信息进行推理和决策,生成最终的行动指令(如点击按钮、输入文本等)。由于它被“冻结”,我们无需对其进行任何训练,可以直接利用其强大的通用能力。
- 上下文策展人 (ContextCurator):一个轻量级的、可训练的专门策略模型。它的角色如同一个“认知建筑师”,唯一的任务就是主动管理和净化
TaskExecutor的工作记忆。它会审视历史上下文和当前的原始观察,然后决定哪些信息应该被保留,哪些应该被剪枝,最终生成一个精炼、高信噪比的工作记忆。
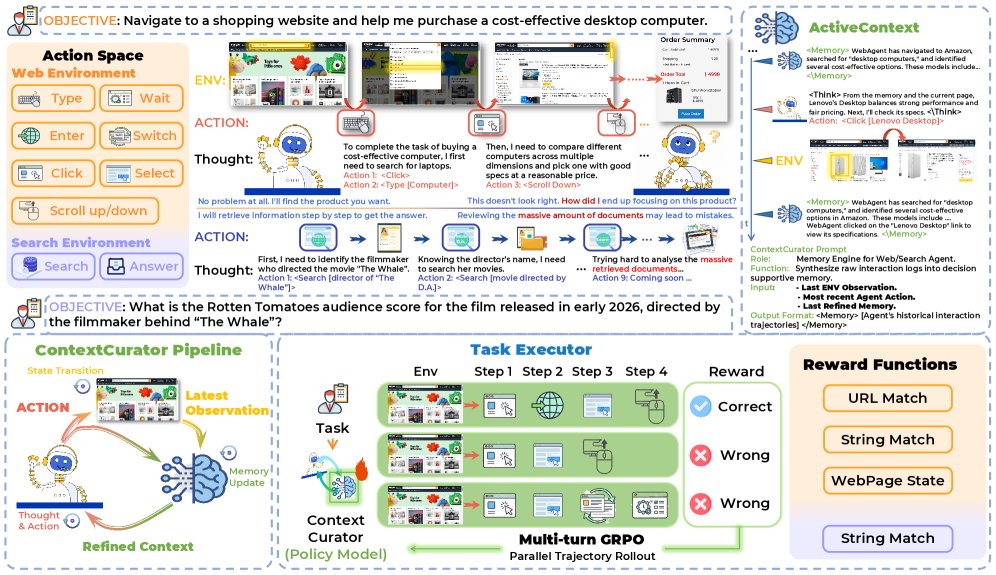
图 1:ActiveContext 框架总览。 上图展示了标准 LLM Agent 在网页和搜索任务中遇到的上下文瓶颈。下图则展示了 ActiveContext 的共生架构:ContextCurator 主动将充满噪声的观察(Verbose Observations)提炼成高保真的工作记忆(High-Fidelity Working Memory),供 TaskExecutor 使用。右下角是用于优化 ContextCurator 的强化学习流程。
在任意一个时间步 ,这种共生互动分两阶段进行:
- 阶段一:上下文策展 (Context Curation)。
ContextCurator接收到截至目前的所有历史信息 (包括过去的观察、行动和记忆),然后做出决策,生成一个提炼后的新工作记忆 。这个过程可以表示为 ,其中 是ContextCurator的策略网络。它不是简单的信息压缩,而是一个基于策略的、有目的的选择过程,旨在“主动降低信息熵”。 - 阶段二:基于上下文的执行 (Context-Conditioned Execution)。
TaskExecutor接收到ContextCurator精心准备的记忆 和当前环境的原始观察 ,然后生成下一步的任务行动 。即 。由于输入给TaskExecutor的是经过净化的高质量信息,其宝贵的注意力资源可以完全集中在与任务最相关的信号上,从而做出更精准的判断。
这种解耦设计巧妙地解决了前述困境。它既利用了大模型的强大推理能力,又通过一个专门的小模型解决了上下文污染问题。更重要的是,这个小模型是可以被高效训练的。
如何训练一个聪明的“记忆管家”?强化学习的妙用
仅仅通过指令(System Prompt)告诉一个 7B 模型“请为我总结关键信息”,是远远不够的。小模型无法凭空知道对于一个它看不透的、更强大的黑箱模型(TaskExecutor)来说,哪些信息是“关键”的。这种模糊的指令很容易导致“幻觉式剪枝”(hallucinated pruning),即模型随意丢弃真正重要的“推理锚点”,或保留一堆无关的噪声。
为了让 ContextCurator 学会真正有效的上下文管理策略,研究者将其训练过程构建为一个序贯决策问题,并采用了一种基于强化学习的方法——多轮组相对策略优化 (Multi-Turn Group Relative Policy Optimization, MT-GRPO)。
这个训练流程的设计堪称整个研究的点睛之笔。其核心逻辑如下:
研究者将 TaskExecutor 及其与环境的互动,整体视为一个增强的、对 ContextCurator 来说部分可观察的马尔可夫决策过程(POMDP)。ContextCurator 在这个过程中做出决策(即生成记忆 ),然后观察 TaskExecutor 利用这份记忆采取行动 后,整个任务最终是否成功。
$\(
縛brace{m_{t}simpi_{phi}(cdot|c_{t})}{ ext{Curator Decision}}longrightarrow縛brace{a{t}simpi_{ ext{exec}}(cdot|m_{t},o_{t})}{ ext{Executor Action}}longrightarrow縛brace{R( au)}{ ext{Distal Outcome}} \)$
这里的奖励 是一个稀疏的、延迟的(distal)信号。只有在整个任务轨迹 结束时,系统才会根据任务是否成功给予一个奖励(例如,成功为 1,失败为 0)。ContextCurator 在每一步的决策,都不会立即得到反馈。它必须学会将其在早期步骤中的信息筛选行为,与最终的任务成败关联起来。
MT-GRPO 算法通过运行多组(Group)并行的试验轨迹来收集数据。在每一轮优化中,它会比较那些最终成功和失败的轨迹。对于在成功轨迹中 ContextCurator 所做出的决策(即生成的记忆),算法会给予正向的激励;反之,对于导致失败的决策,则给予负向的惩罚。通过这种方式,ContextCurator 的策略网络 会被逐步优化,使其越来越倾向于生成那些能够帮助 TaskExecutor 走向成功的上下文记忆。
这个过程的巧妙之处在于,它实现了跨模型的对齐,而无需访问 TaskExecutor 的内部参数或梯度。ContextCurator 通过观察 TaskExecutor 行为的最终结果,间接地学会了后者的“偏好”和“推理需求”。它学会了识别并保留那些看似微不足道但对后续步骤至关重要的“推理锚点”,同时大胆地剪除会干扰 TaskExecutor 的大量噪声。
实验见真章:更少的 Token,更高的成功率
为了验证 ActiveContext 的实际效果,研究者在两个极具挑战性的长时程任务基准上进行了广泛实验。
- WebArena:一个模拟真实网页浏览的环境,包含购物、论坛、代码托管(Gitlab)等多种场景。它考验 Agent 在充斥着大量结构性噪声的原始 DOM 树中进行多步操作的能力。
- DeepSearch:一个复杂的 RAG 环境,要求 Agent 通过多轮检索和综合,从充满语义噪声的搜索结果中提炼答案。
在 WebArena 上的表现:
实验结果(见下表)清晰地表明,主动上下文管理不仅降低了成本,更提升了性能上限。
- 性能提升:以 Gemini-3.0-flash 作为
TaskExecutor时,基线方法(Full Context,即尽可能保留所有历史信息)的成功率仅为 36.4%。而引入 ActiveContext 后,成功率提升至 41.2%,这是一个显著的进步。 - 成本降低:同时,平均每个任务的 Token 消耗从 47.4K 下降到 43.3K,减少了 8.8%。这证明
ContextCurator的剪枝是有效的。
表 1:WebArena 基准测试结果。 ActiveContext (Ours) 在多个子任务上均取得了领先的成功率(SR),同时有效控制了 Token 消耗。
在 DeepSearch 上的表现:
DeepSearch 环境的特点是语义噪声极其严重,这使得它成为检验 ActiveContext 信息提炼能力的绝佳试金石。
- 性能提升:在使用 Gemini-3.0-flash 时,成功率从 53.9% 提升至 57.1%。
- 成本大幅降低:更惊人的是 Token 消耗。基线方法平均需要 46.7K 的上下文 Token,而 ActiveContext 仅需 6.6K,实现了近 8 倍的 Token 缩减。这充分说明,在 RAG 这类信息冗余的场景下,
ContextCurator能够精准地识别并过滤掉绝大部分无用信息,只保留最核心的证据。
表 2:DeepSearch 基准测试结果。 ActiveContext 在所有模型上都实现了显著的 Token 节省,尤其是在 Gemini-3.0-flash 上达到了 85% 的缩减,同时提升了成功率。
最关键的发现:7B 模型媲美 GPT-4o
在消融实验中,研究者将 TaskExecutor 固定为 gpt-4o-mini,并对比了不同上下文管理方法的表现。其中一个对比项是使用强大的 GPT-4o 作为零样本(zero-shot)的 ContextCurator。结果发现,经过强化学习微调的 7B ContextCurator,其在上下文管理上的综合表现(成功率与 Token 效率)与 GPT-4o 相当。
这一发现意义重大。它雄辩地证明了,“主动上下文管理”是一种可以从通用推理能力中分离出来的、专门的认知技能。我们不需要一个千亿参数的庞然大物来做这件事,一个经过专门训练的、高效的 7B 模型就足以胜任。这为构建高性能、低成本的 Agent 系统“民主化”铺平了道路。
结论:从“堆料”到“精加工”,Agent 的未来在何方?
ActiveContext 的工作为解决 LLM Agent 在长时程任务中的核心瓶颈提供了一个优雅而强大的范式。它标志着一个重要的转变:业界关注的焦点,正从如何暴力地扩大模型的上下文窗口,转向如何智能地管理和利用好 Agent 有限的认知带宽。
通过引入“共生专业化”(Specialized Symbiosis)的架构,将负责推理的 TaskExecutor 和负责记忆管理的 ContextCurator 解耦,并通过强化学习进行目标对齐,ActiveContext 建立了一个新的帕累托前沿——在提升 SOTA 模型推理能力上限的同时,大幅降低了计算和 Token 成本。
这项研究为下一代高保真、可持续的自主 Agent 提供了 foundational blueprint。它告诉我们,未来的 Agent 系统可能不再是单一的、巨大的“通才”模型,而是一个由多个协同工作的、高度专业化的组件构成的“认知团队”。在这个团队里,有负责战略规划的“大脑”,有负责信息搜集的“眼睛”,也必然有一个像 ContextCurator 一样,负责梳理思绪、保持专注的“记忆管家”。这或许才是通往真正通用与高效人工智能的更可行路径。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/269342.html