
大模型 Skill(技能) 是一种标准化的、可插拔的能力扩展机制,它通过封装领域知识、执行流程、工具调用和参考资源,让通用大模型在特定任务中表现出专家级的能力。Skill 不是让模型重新训练,而是在推理时为其提供精确的行动指南。
Skill 的核心组成
一个标准的 Skill 通常包含三部分:
- 元数据:描述技能的名称、功能和适用场景,类似“名片”
- 行动指南:用自然语言编写的标准作业程序(如
SKILL.md),明确每一步该做什么 - 执行资源:实际的工具脚本、API 调用或参考文档
Skill 与插件/工具的区别
- 插件/工具:像厨房里的“菜刀”或“烤箱”,AI 知道它是什么,但不知道如何用它完成复杂任务
- Prompt:像站在厨师旁边“喊话”,需要详细指挥每一步
- Skill:是一本完整的“菜谱”+“预制菜包”,AI 调取后自动按标准流程执行
Skill 的三大核心价值
- 确定性与可控性:通过固化 SOP(标准作业程序)减少 AI 的“乱发挥”和幻觉
- 极低的 Token 消耗:采用“渐进式加载”机制,平时只挂载目录,真正需要时才读取详细内容
- 真正的能力复用:一次编写,多处共享,可沉淀为个人或团队的数字资产
Skill 生态现状
你提供的链接展示了当前丰富的 Skill 生态:
- 平台方:Vercel Labs、Anthropic、Microsoft Azure 等提供了基础框架
- 垂直领域:Supabase(数据库)、shadcn/ui(UI组件)、Remotion(视频)等封装了专业能力
- 工具集成:Browser-use(浏览器自动化)、GitHub Copilot for Azure(云开发)等
应用场景
- 代码开发:自动生成符合团队规范的 Git 提交信息、代码审查
- 文档生成:按公司模板生成技术文档、API 文档
- 数据分析:封装特定业务的数据处理流程
- 自动化任务:定时抓取信息、翻译、通知等流水线作业
Skill 的出现标志着 AI 从“能说会道”的聊天机器人向“行家里手”的超级员工进化。2026 年被称为“Skills 时代”,各大平台如 Coze 2.0、Claude 均已原生支持,让普通人也能通过“口喷式开发”快速创建自己的技能库。
从trae.cn下载windows版本,安装国内版即可。
node --version npm --version python -V 可以查到版本号就可以啦
# 创建项目目录 mkdir hello # 进入项目目录 cd hello # 创建README.md文档 touch README.md # 创建skill目录 mkdir -p .traeskillszh-translator # 创建SKILL.md文件 cd .traeskillszh-translator 将下面文档的内容粘贴到SKILL.md文件中。
打开设置-规则和技能。如果没有看到,点击技能旁边的圆圈箭头刷新。
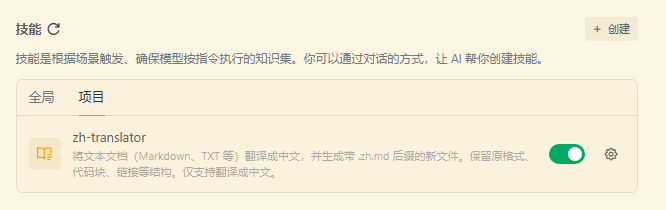
SKILL.md文档内容如下。
--- name: zh-translator description: 将文本文档(Markdown、TXT 等)翻译成中文,并生成带 .zh.md 后缀的新文件。保留原格式、代码块、链接等结构。仅支持翻译成中文。 --- # 中文翻译技能 用途 将任意文本文档(尤其是 Markdown 文件)翻译成中文,并按照规范生成对应的中文翻译文件。 例如:`readme.md` → `readme.zh.md`;`guide.en.md` → `guide.zh.md`。 本技能只输出中文翻译,不生成英文或其他语言版本。 适用场景 - 用户明确要求将某个文档翻译成中文。 - 用户提供文件路径,希望获得中文版本。 - 用户需要批量处理多个文档的中文翻译。 核心原则 1. 保留原格式:不改变 Markdown 标记、代码块、HTML 标签、URL、图片链接等非文本结构。 2. 精准翻译:只翻译自然语言段落、标题、列表项、表格内的文本、链接的显示文字、图片的 `alt` 属性。 3. 不翻译内容: - 代码块内的所有内容(包括注释) - 行内代码(如 `variable_name`) - URL 或文件路径 - Frontmatter 中的键名(但可翻译键值中的自然语言,如 `description: "..."`) 4. 文件命名: - 从原文件名中移除已存在的语言代码后缀(如 `.en`、`.zh`、`.zh-CN` 等),再添加 `.zh`。 - 扩展名保持原样(通常为 `.md`,也支持 `.txt` 等)。 - 示例: - `guide.md` → `guide.zh.md` - `guide.en.md` → `guide.zh.md` - `readme.txt` → `readme.zh.txt` 5. 避免覆盖:若目标文件已存在,询问用户是否覆盖、跳过或指定新名称。 6. 分块处理长文档:如果文档超过模型上下文限制(例如大于 10 万字符),自动分段翻译,然后组合结果。 执行步骤 当用户要求翻译文档时,请严格遵循以下流程: 第一步:确认参数 - 源文件路径:用户提供的文件路径(支持相对路径或绝对路径)。 - 若用户未提供文件路径,主动询问:“请提供需要翻译的文档路径。” 第二步:读取源文件 使用 `read_file` 工具读取完整内容。如果文件不存在或无法读取,报告错误并终止。 第三步:规范化目标文件名 按上述命名规则计算目标文件路径。例如: - 输入 `docs/api.md` → `docs/api.zh.md` - 输入 `docs/api.zh.md` → `docs/api.zh.md`(已包含 `.zh`,但可询问是否覆盖) 第四步:检查目标文件是否存在 使用 `stat` 或尝试读取目标文件。若存在: - 明确告知用户:“目标文件 `xxx.zh.md` 已存在。是否覆盖?(是/否/另存为)” - 根据用户回复执行:覆盖、跳过或要求提供新文件名。 第五步:执行翻译 1. 解析文档结构:识别标题、段落、代码块、列表、表格、引用、图片、链接、内联代码、HTML 标签等。 2. 逐块翻译: - 对于代码块(包括围栏式 ` `和缩进式)、行内代码、URL、纯 HTML 标签(无文本内容) → 保持原样。 - 对于标题、段落、列表项、表格单元格、引用块、链接文本、图片 alt 文本 → 翻译成中文。 - 对于 Frontmatter(YAML 格式):保留键名,仅翻译值为普通字符串的项(如 `title: "My Post"` → `title: "我的文章"`)。不翻译数组、对象或包含代码的值。 3. 术语一致性:同一术语在全文中保持相同译法。例如 `API` → `API`(不翻译),`endpoint` → `端点`。 4. 保留空行和缩进:确保翻译后文档结构与原文档一致。 第六步:写入新文件 使用 `write_to_file` 工具将翻译后的内容写入目标路径。使用 UTF-8 编码。 第七步:反馈结果 向用户报告: - 生成的文件路径 - 处理的段落/字数统计(可选) - 任何特殊处理(如跳过的代码块数量、已存在的文件覆盖情况) 示例对话 用户:将 `docs/quickstart.md` 翻译成中文 AI(遵循本技能): 学习使用 Skill(技能)的**方式是 “先体验、再拆解、后创造”。下面是一套从零到精通的学习路径。
1. 安装别人写好的 Skill
- 使用
npx skills add <仓库名>安装社区技能(例如npx skills add vercel-labs/agent-skills)。 - 或者在 Claude、Cursor 等客户端中通过 UI 导入
.md技能文件。
2. 触发使用
直接用自然语言说出需求,AI 会自动匹配技能。例如:
- “将
readme.md翻译成中文”(如果已安装翻译技能) - “用代码审查技能检查
app.py”
3. 观察 AI 的行为
注意 AI 是否按照技能描述中的步骤执行(比如先读文件、再处理、最后写入)。可以要求 AI “解释你正在执行的步骤”,从而理解技能指令如何影响模型推理。
拿一个简单的 code-formatter 技能为例:
--- name: code-formatter description: 使用 Prettier 格式化 JavaScript/TypeScript 代码文件。 --- # 代码格式化器 执行步骤 1. 读取用户指定的代码文件。 2. 运行 `npx prettier --write
<文件路径>
`。 3. 返回格式化结果。
关键要素:
- 元数据:
name和description用于匹配触发。 - 步骤:清晰、可执行的指令,可以包含工具调用(如
read_file)或 shell 命令。 - 边界条件:什么时候用、什么时候不用、如何处理错误。
试着找 3-5 个不同用途的 Skill(翻译、代码审查、文件整理等),对比它们的结构和写法。
1. 选择一个你重复做的小任务
例如:“把当前文件夹下的所有 .txt 文件合并成一个 combined.txt”。
2. 用脚手架初始化
npx skills init my-file-merger 3. 编辑生成的 SKILL.md
— name: file-mergerdescription: 将当前目录下所有 .txt 文件合并成一个 combined.txt,按文件名顺序合并。
文件合并器
步骤
- 使用 `ls *.txt` 或 `readdir` 列出所有 .txt 文件。
- 按文件名排序。
- 依次读取每个文件的内容。
- 将内容用 ` — 文件分隔符 — ` 拼接。
- 写入 `combined.txt`。
- 报告合并了哪些文件。 在对话中加载该技能(根据客户端操作),然后说 “合并所有 txt 文件”。观察 AI 是否按步骤执行。如果出错,调整
SKILL.md的描述,让步骤更具体。4. 测试你的技能
5. 迭代改进
- 添加错误处理(如“如果没有 txt 文件,提示用户”)。
- 添加参数(如“允许用户指定输出文件名”)。
- 添加互斥声明(防止和其他文件操作技能冲突)。
资源类型 推荐内容 获取方式
官方文档 Vercel AI Agent Skills 规范
npx skills docs 或访问 GitHub 仓库
示例库 官方示例技能集
npx skills add vercel-labs/skill-examples
社区技能 他人分享的实用技能 GitHub 搜索
agent-skills 或
claude-skills
视频教程 “Building AI Skills” 系列 YouTube 搜索对应关键词
练习项目 为自己常用的工具(如 ffmpeg、jq)包装成 Skill 自建
误区 正确做法 以为 Skill 需要写代码 大部分 Skill 只需 Markdown 指令,代码脚本是可选的 一次性加载多个 Skill 一次只启用 1-2 个职责清晰的 Skill,避免冲突 步骤写得太模糊(如“处理文件”) 写具体:“第一步:用
read_file 读取;第二步:用正则替换…” 忘记测试边界情况 主动测试空文件、超大文件、无权限文件等场景 不读官方规范 花 10 分钟阅读 Skill 的 YAML frontmatter 完整字段说明
- 第 1-2 天:安装 3 个现成 Skill,每天用它们完成真实任务。
- 第 3-4 天:打开这些 Skill 的
SKILL.md,画出它们的执行流程图。 - 第 5-6 天:模仿写一个极简 Skill(如“统计文件行数”)。
- 第 7-9 天:给自己的常用命令行工具(
ffmpeg、jq、pandoc)写 Skill 包装。 - 第 10-12 天:学习使用
scripts/目录,写一个调用 Python 脚本的 Skill。 - 第 13-14 天:发布你的 Skill 到 GitHub,并尝试用
npx skills add安装回来。
写 Skill 就像给一个聪明的实习生写 SOP(标准操作流程):
- 步骤要足够详细,让实习生不需要猜。
- 列出不允许做的事(负面约束)。
- 给出例子(好/坏行为的对比)。
- 规定遇到意外时如何求助(询问用户)。
掌握这些,你就能把任何重复性任务固化为 Skill,让 AI 成为你可靠的下属。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/268326.html