
- 思考为行动导航:Thought 步骤让模型在行动前先理清思路,避免盲目操作
- 行动更新知识:每次 Observation 为模型提供新信息,更新其对世界的认知
- 错误可以被发现和纠正:如果某个行动结果出乎意料,模型可以在 Thought 中调整策略
- 可解释性强:整个推理-行动过程是透明的,人类可以审查
实验证明,在知识密集型任务(如 HotpotQA 多跳问答)和决策型任务(如 ALFWorld 家庭环境操作)中,ReAct 都显著优于纯 CoT 或纯行动方法。
- 定义工具:用结构化格式(JSON Schema)描述工具的名称、功能和参数
} } - 模型决策:LLM 看到工具定义和用户请求,决定是否调用工具以及传入什么参数
} - 执行并返回结果:程序执行工具,将结果返回给 LLM 继续处理
这个流程将 LLM 的"语言理解和决策能力"与"外部系统的执行能力"优雅地结合在一起。
3.3 工具调用的挑战
工具调用看似简单,实际上有很多难点:
● 工具选择:当有几十个工具时,模型如何选对工具?
● 参数填写:模型可能填错参数类型或遗漏必要字段
● 错误处理:工具调用失败时,模型能否理解错误信息并重试?
● 多工具协同:复杂任务需要按正确顺序调用多个工具
研究表明(arXiv:2401.07324),小参数量的 LLM 在工具调用方面相比大模型明显弱,这促使了多模型协同(Multi-LLM)架构的出现——用专门的小模型负责工具调用,大模型负责整体推理。
- 观察 Agent 在某任务上的常见错误
- 用另一个 LLM 自动生成检查代码
- 将检查代码嵌入执行环境,实时验证 Agent 的行动合法性
这大幅降低了为新任务编写 Harness 的人工成本。
[Planner LLM] 接到任务 → 生成完整执行计划 [Executor LLM] 按计划逐步调用工具执行 [Verifier] 检查每步结果是否符合预期 [Orchestrator Agent] 任务分发与协调 ├── [Research Agent] 负责信息收集 ├── [Code Agent] 负责代码编写 ├── [QA Agent] 负责测试验证 └── [Writer Agent] 负责报告撰写 代表框架:AutoGen、CrewAI、LangGraph。
记忆类型 类比 实现方式 Sensory Memory 感官刺激 当前上下文窗口 Working Memory 工作记忆 中间变量、临时存储 Episodic Memory 情景记忆 向量数据库(记录历史对话/操作) Semantic Memory 语义记忆 知识图谱、长期知识库 [Agent 行动] → [结果不符合预期] → [Reflection: 分析哪里出了问题] → [修正策略,重试] 代表性工作:Reflexion(arXiv:2303.11366),让 Agent 将失败经验写入"记忆",在后续尝试中避免同样的错误。
tools = [ DuckDuckGoSearchTool(), # 搜索工具 PythonREPLTool(), # 代码执行工具 ] llm = ChatOpenAI(model="gpt-4", temperature=0) agent = create_react_agent(llm=llm, tools=tools)
result = agent.invoke({ "input": "帮我查一下今年奥斯卡**影片,然后用 Python 统计片名的字符数" }) print(result) Agent 会自动执行: Thought: 我需要先搜索今年奥斯卡获奖信息 Action: DuckDuckGoSearch("2026 Oscar Best Picture winner") Observation: [搜索结果...] Thought: 找到了,片名是 xxx,现在计算字符数 Action: PythonREPL("print(len('xxx'))") Observation: 42 Thought: 任务完成 Final Answer: 今年奥斯卡**影片是 xxx,片名有 42 个字符 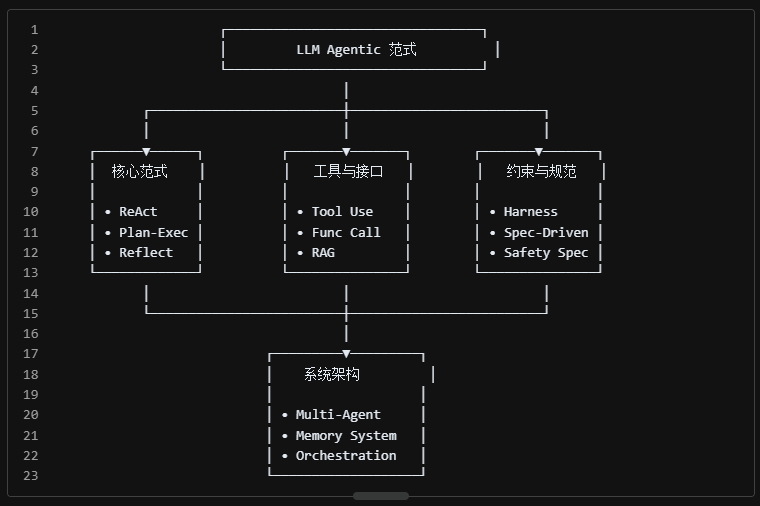
- ReAct 是基础:推理与行动的交织是 Agentic AI 的基本范式
- 工具是能力的延伸:LLM 本身有局限,工具调用让它无所不能
- 规范是安全的保障:没有约束的 Agent 是危险的,Harness 和 Spec 是工程化落地的必要条件
- 组合是未来方向:Multi-Agent + Memory + Reflection 的组合,正在让 AI 具备真正意义上的"自主完成复杂任务"的能力
- Yao, S. et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629
- Plaat, A. et al. (2025). Agentic Large Language Models, a survey. arXiv:2503.23037
- Verma, M. et al. (2024). On the Brittle Foundations of ReAct Prompting for Agentic LLMs. arXiv:2405.13966
- Jiang, J. et al. (2024). KG-Agent: Autonomous Agent Framework for Complex Reasoning over KG. arXiv:2402.11163
- Lou, X. et al. (2026). AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness. arXiv:2603.03329
- Shinn, N. et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366
- Lee, Y. et al. (2026). AEMA: Verifiable Evaluation Framework for Trustworthy and Controlled Agentic LLM Systems. arXiv:2601.11903
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/268278.html