
最近Harness engineering在AI 圈又火了起来,在openclaw之后,这个概念有AI 头部公司Antropic和openai一起强调,晚上找了一些资源,感觉还是云里雾里,恰好台大李弘毅开放了对应的一期视频,这里刚好记录下。
讲Harness之前,先聊聊大模型应用侧的演进化,到目前为止基本是三个阶段:
- 最早期大家都是与大模型进行one on one的交流,just one loop in a time,这时候一个好的prompt很重要,因为这决定了大模型的输出
- 当人类一次又一次的体会大模型的5s记忆时(实际上大模型没有记忆,他是在一个小黑屋里的,他只能知道当前的input,然后完成词语接龙),终于忍无可忍,提出了context enginner,把之前的内容也告诉大模型,让他有了一定的记忆
- 后面也就是现在,我们已经不满足与大模型在一个文本框里进行one loop by one loop的交互,我们希望大模型又能力与环境自己交互,一个成熟的大模型应该自己解决实际问题,自我进化反思,不是依赖与人类反馈,这个时候就是Harness Enginnering提出
那么什么是Harness Engineering,顾名思义,就是一套控制驾驭大模型的工程,是一套方法论,通过设计一套外部框架或规则,来规范与引导 AI 模型(尤其是作为 Agent 时)的行为。它与传统的 Prompt Engineering 有所重叠,但更强调对多轮对话过程与执行逻辑的控制。
Harness Engineering 的本质目标是减少模型的不确定性
具体的怎么操作呢,李老师将其细化为以下三个控制层面:
1. 通过人类语言控制-认知框架
通过在 Prompt 中加入强制性步骤 ,其实就是给AI写一个工作手册,一把来说就是一个agent.md 或 System Prompt,利用自然语言为 AI 设定身份、价值观和逻辑准则。
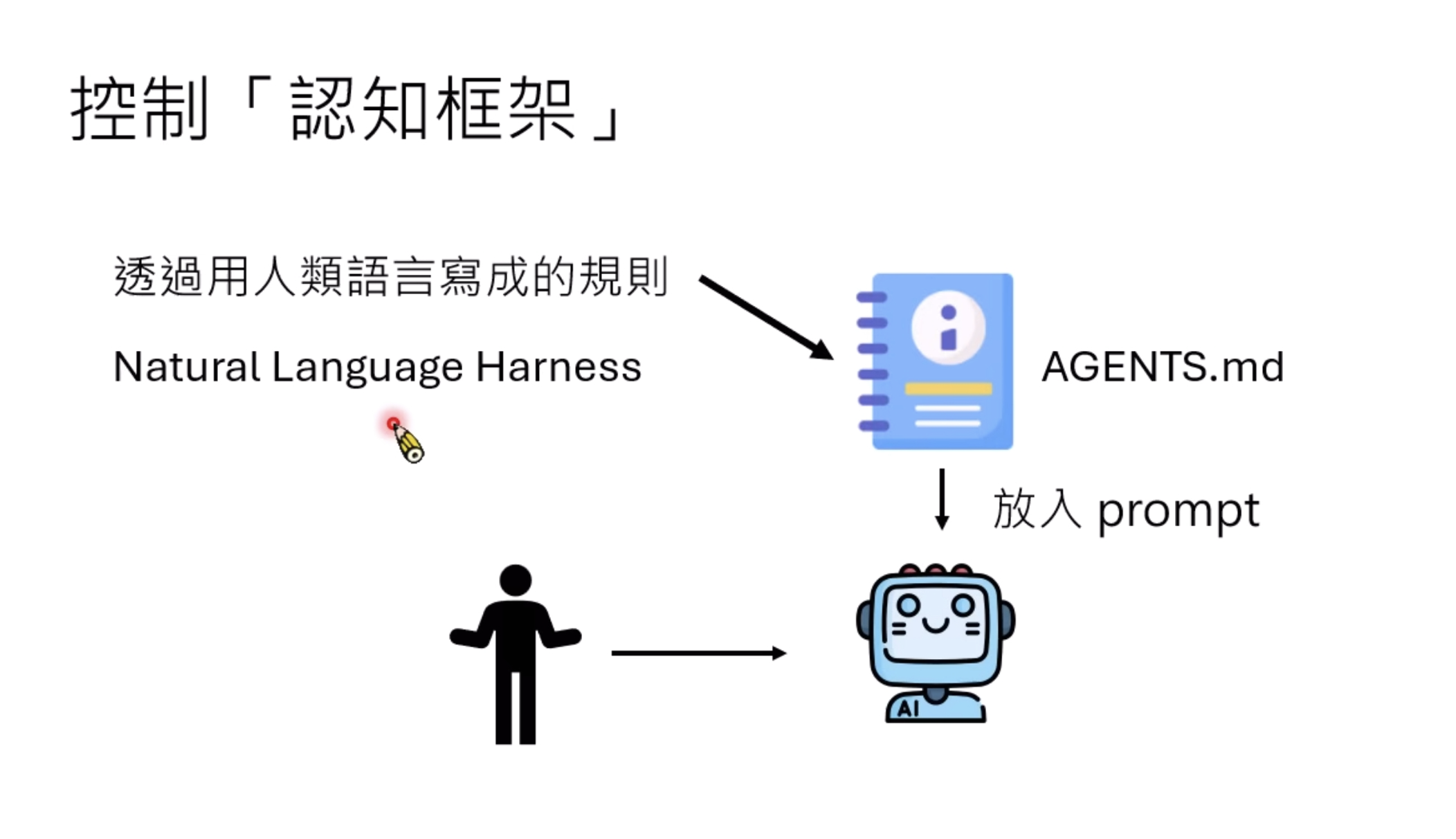
最后还提到了一些论文和研究:
2. 透过工具控制能力边界
我们希望模型能有一些能力与真实世界交互,所以我们会为模型提供可调用的外部工具(如 Bash 脚本、Python 解释器、搜索 API 等)
这里对比了openclaw和cowork,cowork在程序里设置了固定的能力边界,设定了AI Agent的作用范围,更加安全,自由<-> 安全不可能同时达到。
3. 透過「工作流程」控制 ——「行為」
定义 :设计固定的互动步骤(Workflow),例如:观察 → ightarrow → 思考 → ightarrow → 行动 → ightarrow → 验证。
作用 :直接规范模型的具体行为模式。视频中提到的"强制要求模型修改前必须先 cat 文件",就是通过工作流程强制纠正了模型"瞎猜"的行为。
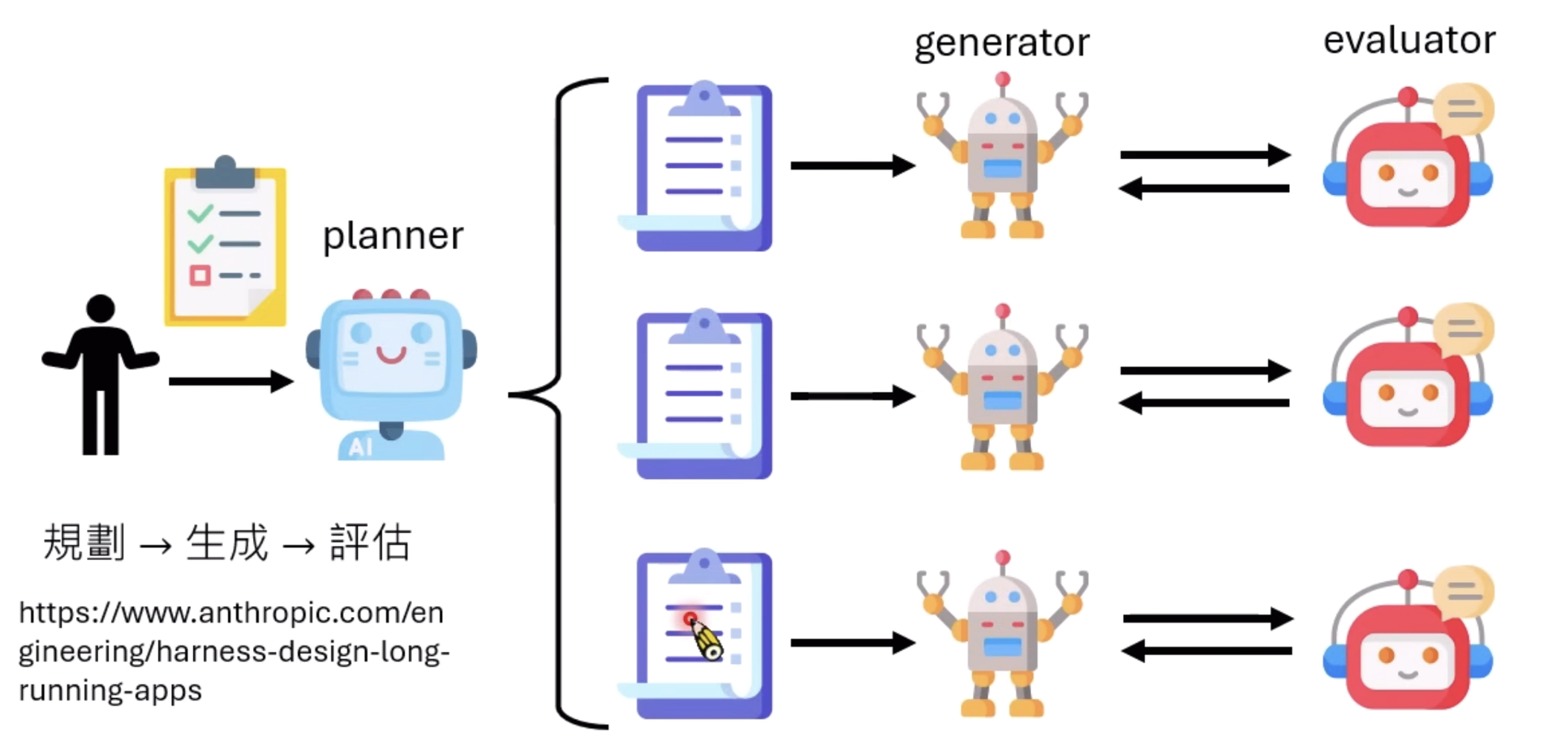
- 这个Verifier可以是另一个大模型,之前就有claude code当执行,codex当裁判的例子
- 也可以是模型应用的工具的输出的feetback
模型不断的获取feedback,然后不断演进,这个有一个专业术语,叫Ralph Loop 。
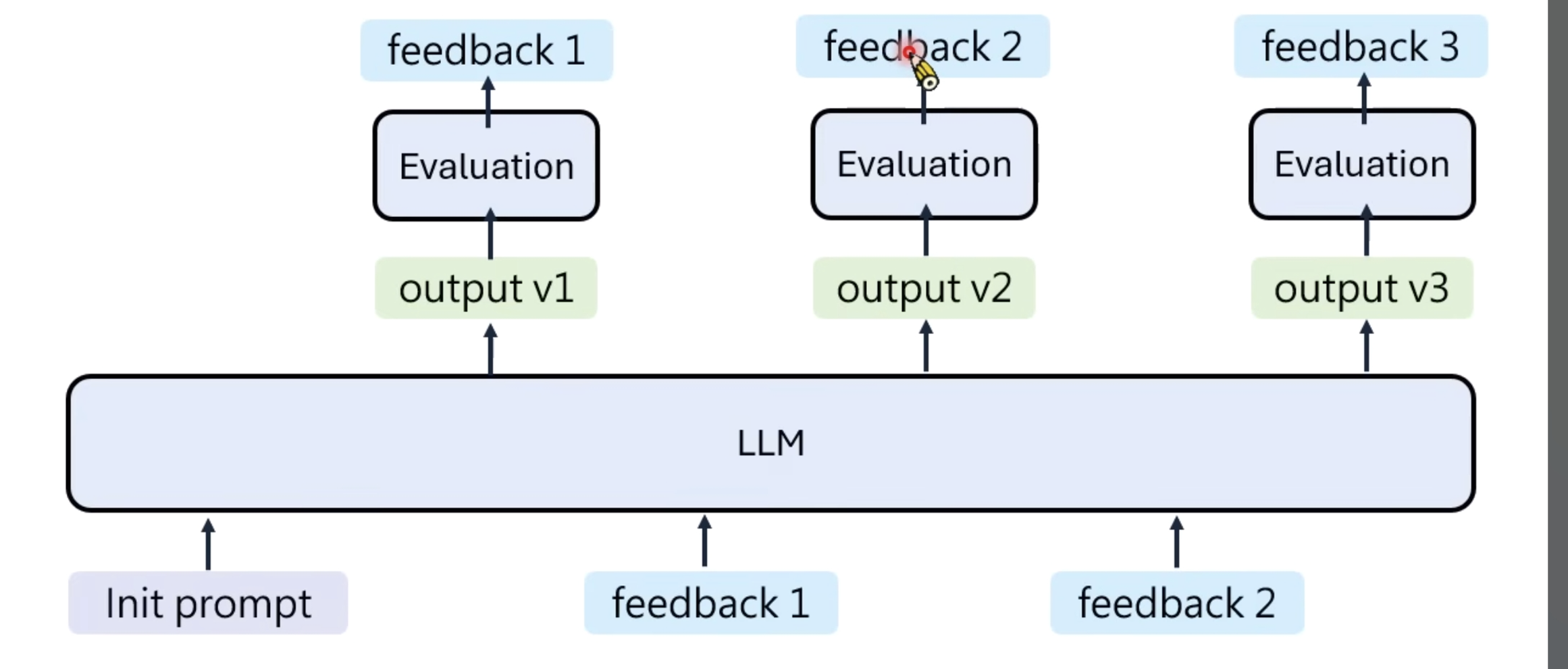
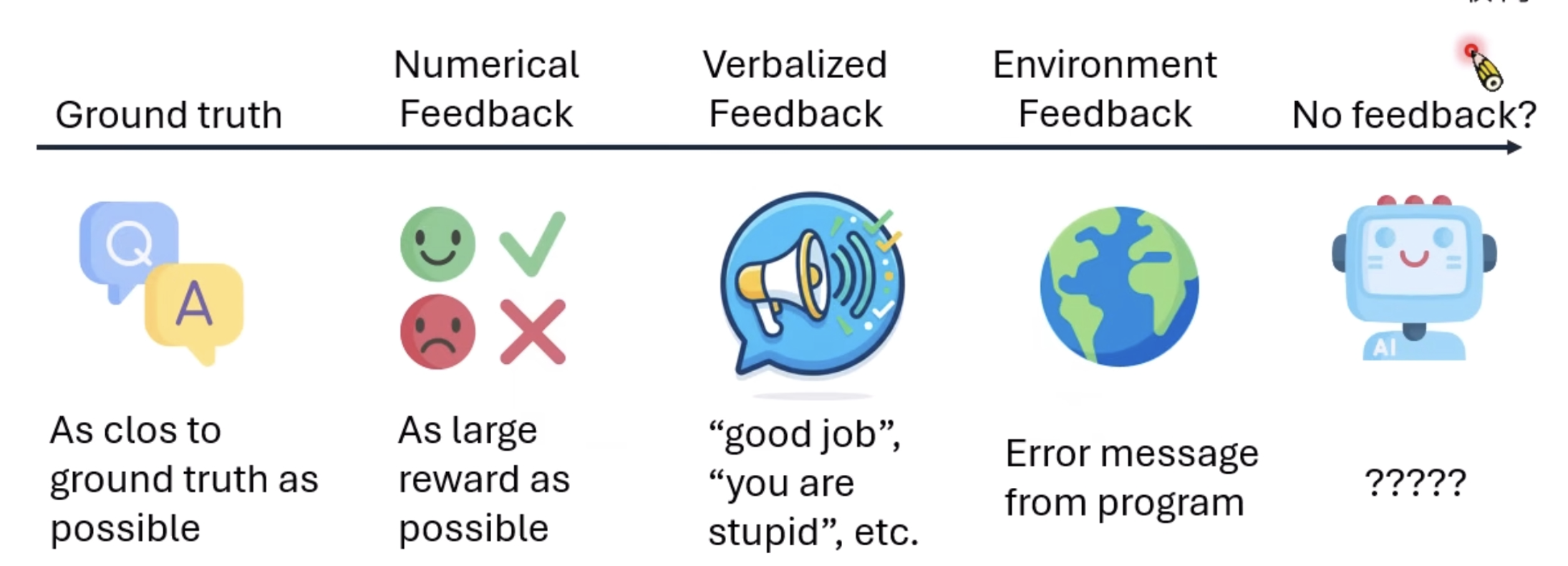
进一步的,还讨论了基于feedback的模型进化与难点:
- 简单的,模型多次feedback以后成功后,我们可以形成一个skill
- 进一步的,可以用来迭代大模型本身,利用RL的一些方法。

最后还有一个比较有意思的事情: AI也要正能量
- 不要骂AI笨蛋,否则他会越来越蠢
- Harness Engineering:有時候語言模型不是不夠聰明,只是沒有人類好好引導
- Effective harnesses for long-running agents
- 工程技术:在智能体优先的世界中利用 Codex
4.Harness design for long-running application development
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/266252.html