
OpenSpec 指的是一个规范驱动开发SDD(Spec-Driven Development) 的范式,为AI编码提供了"规格说明书",把AICoding从"凭感觉写代码"提升到"按规格任务执行"的高度,告别"开盲盒"式的AI编程。
一句话定义:
在写任何一行代码之前,先定义一份"AI可执行的规格说明书(Spec)"
它的核心思想是:
- 人类负责:定义规则(Spec)
- AI 负责:执行规则(生成代码)
(1)什么是规范驱动开发(SDD)?
规范驱动开发(Spec-Driven Development, SDD)是一种软件开发方法论,其核心理念是:
- 规范定义行为:系统的行为由规范(Specification)明确定义
- 代码实现规范:代码是对规范的实现,而非规范的替代
- 规范驱动变更:所有变更都从规范变更开始
- 规范即文档:规范既是需求文档,也是设计文档
(2)和传统开发有什么不同?
从"描述需求" → "定义系统行为"
AI 编程助手(如 Claude / Copilot)存在几个致命缺陷:
- ❌ 模糊输入 → 不稳定输出
- ❌ 无法形成"系统级约束"
- ❌ 无版本追踪(改了啥说不清)
- ❌ 上下文一长就失控
- ❌ 遗漏重要功能 & 添加了不必要的功能
OpenSpec 通过"规范驱动"解决这些问题:
- ✅ 明确共识:编码前锁定需求
- ✅ 结构化管理:所有规范集中管理
- ✅ 可审查:Spec 可读、可评审
- ✅ 可执行:AI根据确定的需求生成代码
- ✅ 可追踪:所有变更都有历史
❗ 其本质就是: AI 不再自由发挥,而是严格执行 Spec
Node.js >= 20.19.0
全局安装
npm install -g @fission-ai/openspec@latest
验证是否安装成功:
openspec --version
cd openspec-demo
openspec init
初始化过程中会让你选择 AI 编程工具(推荐 Claude Code)。
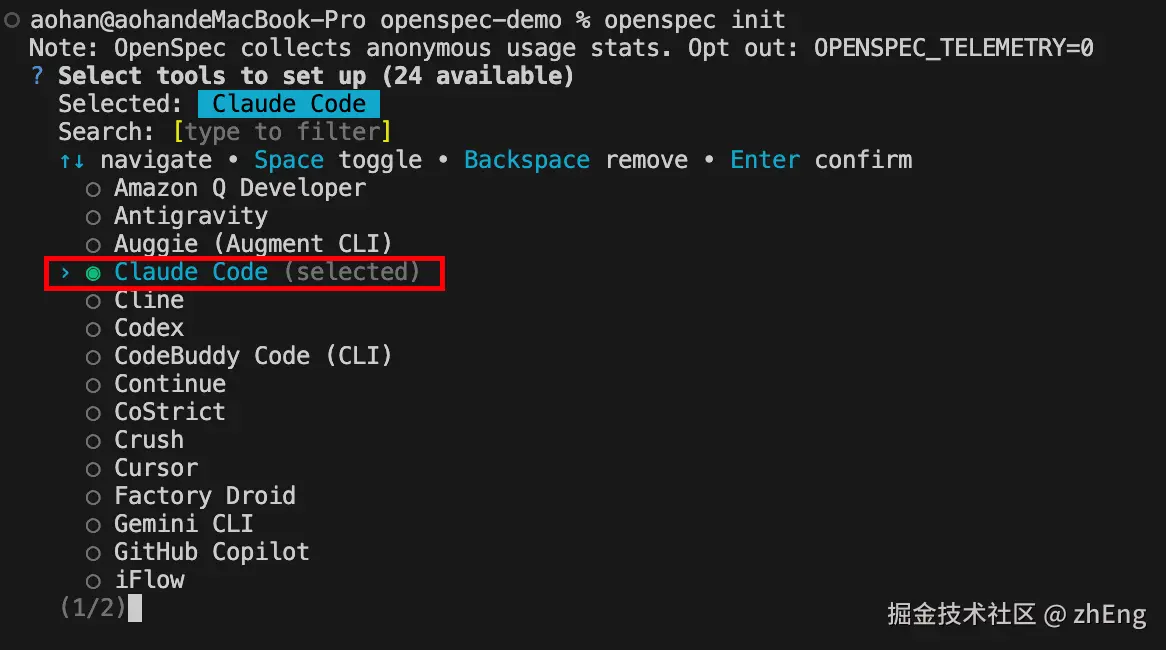 完成后会生成核心目录:
完成后会生成核心目录:
openspec/ ├── specs/ # 当前系统规范(源真相) ├── changes/ # 变更提案 └──── archive/ # 历史归档- 核心作用:发起一个变更提案
- 做什么:
- 在
openspec/changes/下创建一个独立变更目录 - 引导你编写变更说明(proposal.md) :为什么改、改什么、影响范围
- 生成待完善的规格文档(spec),先和AI对齐需求,在写代码
- 在
- 场景:
- 新增功能
- 重构模块
- 修复重大问题前的需求对齐
- 核心作用:探索与分析当前规范与变更
- 做什么:
- 读取
openspec/specs/里的现有规范,帮你理解系统当前行为 - 分析待处理的变更提案,评估影响范围、依赖关系
- 辅助你细化方案、拆分任务,避免开发时偏离规范
- 读取
- 适用场景:
- 开发前做技术调研、
- 理解现有系统、
- 评估变更风险
- 核心作用:将规范变更落地到代码实现
- 做什么:
- 读取指定变更提案的规范文档
- 引导 Claude 按规范生成 / 修改代码,严格对齐 spec
- 确保代码实现与规范完全一致,避免 "写的和想的不一样"
- 适用场景:
- 规范定稿后
- 正式开发 / 迭代代码阶段
- 核心作用:归档已完成的变更,更新项目规范
- 做什么:
- 将已实现的变更规范合并到
openspec/specs/(项目 "源真相") - 把变更目录移动到
openspec/changes/archive/归档 - 生成交付记录,让项目规范始终保持最新状态
- 将已实现的变更规范合并到
- 适用场景:代码开发完成、测试通过后,正式纳入项目规范
propose→ 定义需求,定义规范explore→ 分析影响apply-change→ 按照规范生成代码archive→ 更新规范,归档
这其实就是:把软件开发变成"规范驱动流水线"
这是上一篇文章使用Claude Code实现的TodoList
Claude Code 入门实战:从安装配置到真实项目落地
本次需求:
- 待办事项的列表改为使用Table展示,并且支持批量改变完成状态和删除功能;
- 在列表中增加创建时间和更新时间两个字段,展示格式为YYYY-MM-DD hh:mm:ss
- 现状:添加相同的待办事项可以添加成功;期望:不允许添加重复的待办事项,并给出存在重复的待办事项提示;
- 改为Table展示后再调整下页面的样式,待办事项清单的宽度以及背景颜色;
Step 1 :通过 /openspec-propose调用openspec的skills
/openspec-propose提交需求后,系统自动在openspec/change目录下创建了本次需求的独立目录enhance-todo-list,这里的目录名称可以理解为就是本次的需求ID。- 目录自动生成标准化需求文档,支持反复评审打磨,确保需求清晰,边界明确后再进入开发阶段,避免需求存在偏差
创建proposal.md提案文件
Why
当前待办事项应用使用List组件展示,功能较为基础,不支持批量操作。同时,缺少对重复事项的校验机制,以及用户无法直观查看待办事项的创建和更新时间。这些限制降低了应用的用户体验和管理效率。
What Changes
- UI组件升级: 将List组件替换为Table组件,支持更丰富的展示和交互
- 批量操作: 新增批量改变完成状态和批量删除功能
- 时间字段增强: 添加创建时间(createdAt)和更新时间(updatedAt)字段,格式化为
YYYY-MM-DD hh:mm:ss
- 重复校验: 添加待办事项内容去重机制,防止重复添加
Capabilities
New Capabilities
batch-todo-operations: 批量操作待办事项(批量完成/取消完成、批量删除)todo-time-tracking: 待办事项时间记录和展示(创建时间、更新时间)todo-duplicate-validation: 待办事项重复性校验
Modified Capabilities
todo-crud: 基础待办事项增删改查(添加重复校验到创建操作)
Impact
- 代码变更:
src/components/TodoList.tsx: 重构为Table组件,添加批量操作逻辑src/types/todo.ts: 添加updatedAt字段- 新增依赖:
dayjs 时间处理库
- API变更:
- addTodo: 添加重复校验逻辑
- 新增: batchToggleTodos、batchDeleteTodos 方法
- 用户体验:
- 提供更高效的批量操作能力
- 更清晰的时间信息展示
- 避免重复待办事项的创建
openspec/change/enhance-todo-list/specs这个文件里面的内容可以理解为是本次需求的测试用例文件。design.md&tasks.md是根据需求创建的设计文档和将需求拆解为一个个的Task文档- 这里就需要我们去确认这个
task.md文档中拆解的task是否合理,是否可以满足我们的需求,在后续apply的时候会去执行文档中所有的task
Step 2: 自动化生成代码,上述文档确认完成后,执行指令: /openspec-apply-change 需求ID
系统将会自动按照tasks.md中的任务清单,逐个执行任务
完成需求后页面效果: 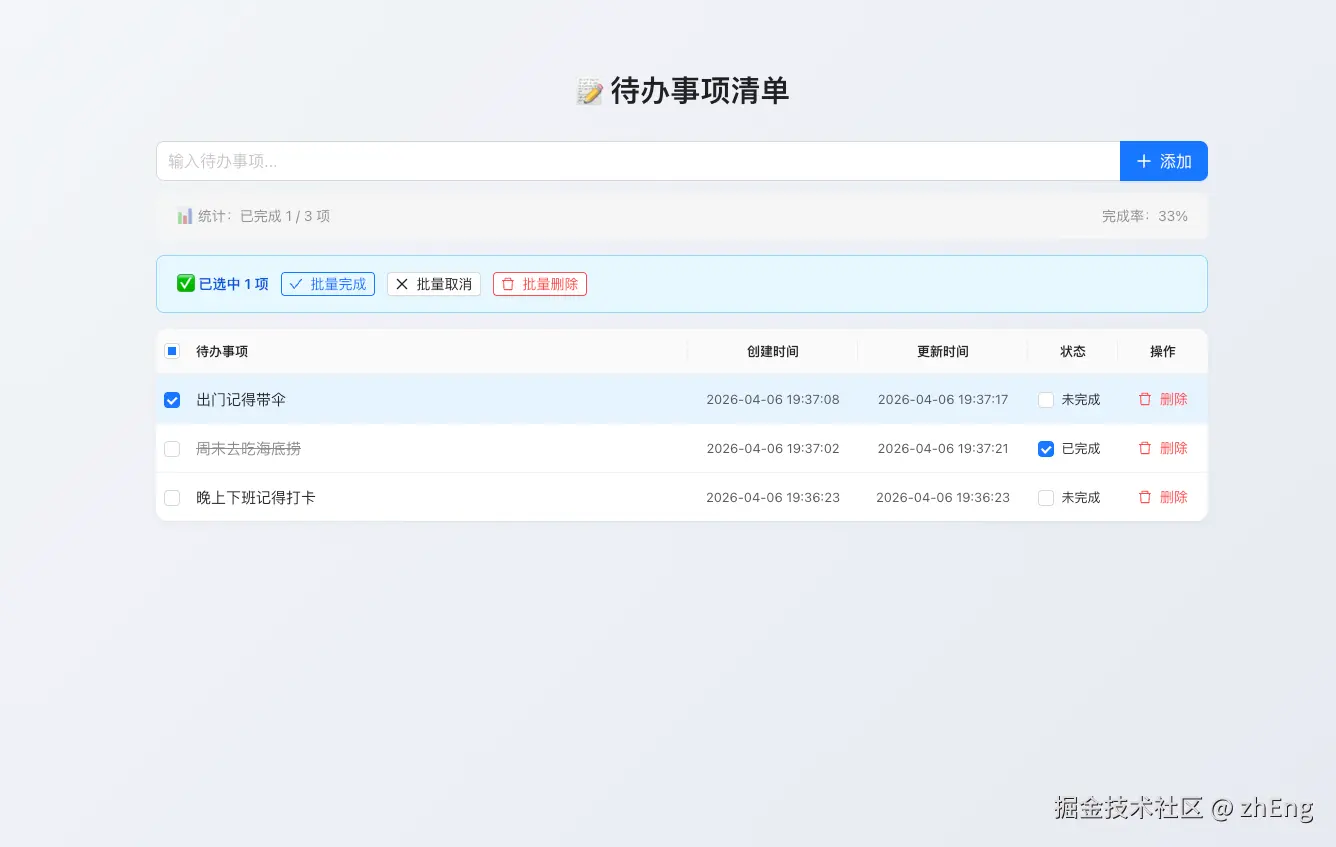
查看实现的代码,整个过程中几乎没有"手写业务代码",而是把精力放在"定义系统行为"上面。
这就是OpenSpec 和传统 AI 编程最大的不同。 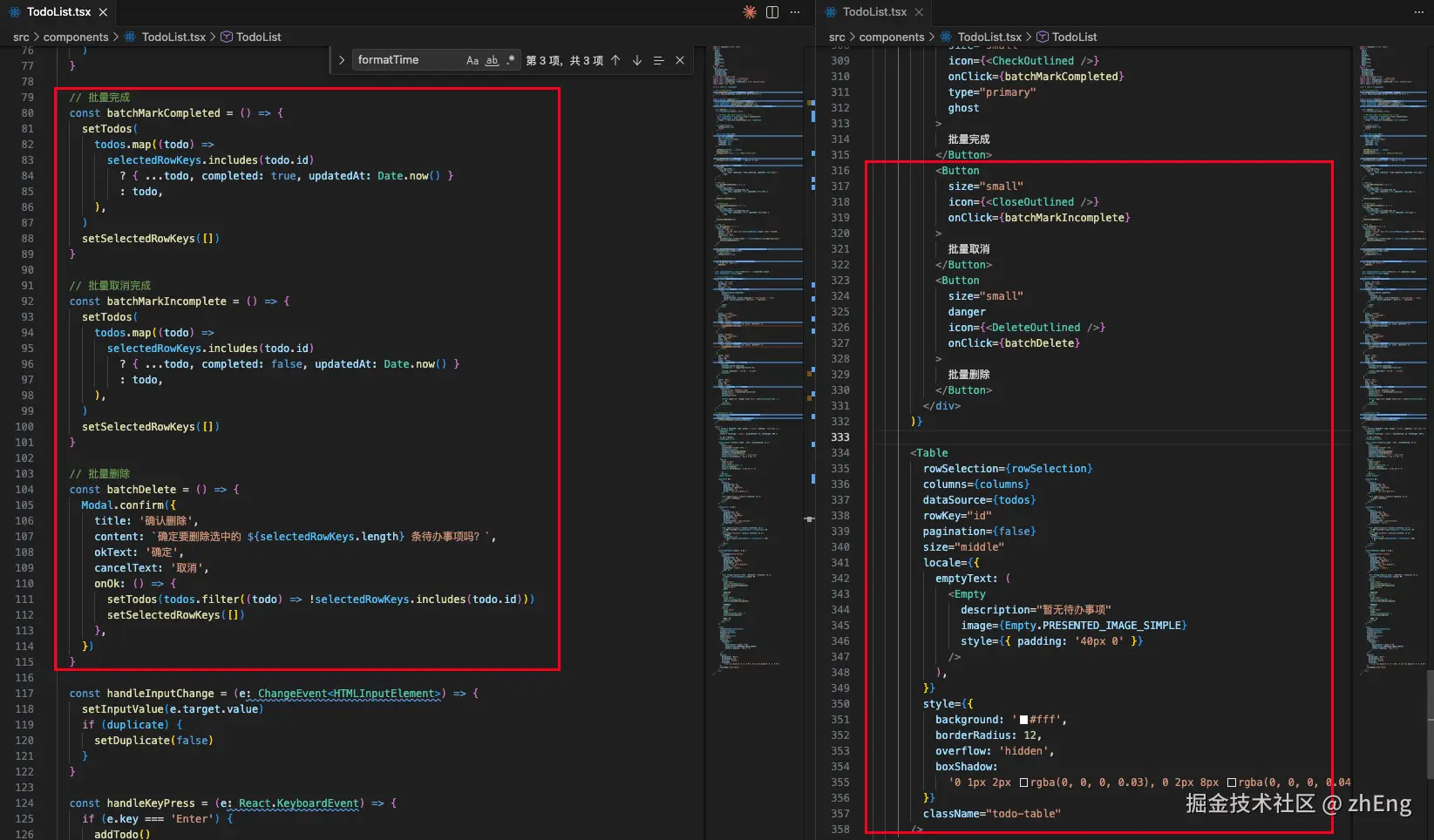
Step 3: 执行 /openspec-archive-change 需求ID将本次的迭代的需求进行归档操作,方便后续追溯
- 执行完本次的需求文件夹会被移动到
openspec/changes/archive/日期+需求ID目录下
OpenSpec 的意义,不只是一个工具,更像是一种开发范式的转变:
从"人写代码,AI辅助"
到"人定义系统,AI负责实现"
在这种模式下:
- 代码不再是"源真相",规范才是
- AI 不再是"猜需求",而是"执行规则"
- 开发过程从"不断试错",变成"按规范推进"
这背后,其实是软件工程的一次"回归":
👉 回归到"用明确的约束定义系统行为"
当 AI 编码能力越来越强,真正拉开差距的,不再是"谁写代码更快",而是:
谁能定义出更清晰、更严谨的系统规范
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/261712.html