
Dify是一个开源的大型语言模型(LLM)应用开发平台,旨在简化AI应用的创建、部署和管理过程。它提供了一个直观的可视化界面,让开发者甚至非技术人员都能快速构建基于大语言模型的应用。包括可视化工作流、多模型支持、RAG引擎、API快速集成、可观测性与运维、开源与自托管等。
该篇博客从本地部署到Dify平台使用都有介绍,并且通过MCP Agent连接MySQL实现基于数据库真实数据进行问答。
Dify在github上给出了硬性要求需要满足条件
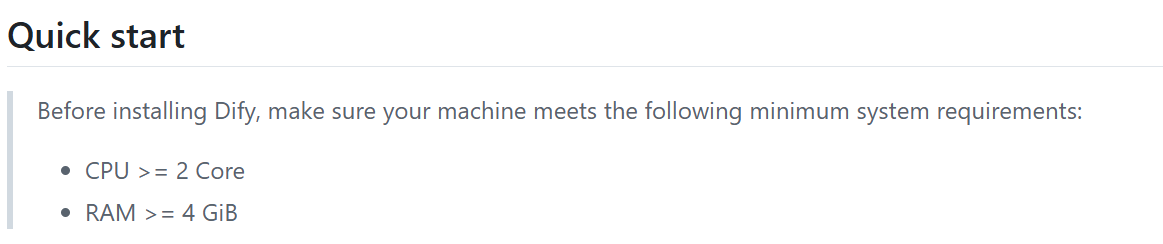
任务管理器 》性能 》虚拟化(开启)
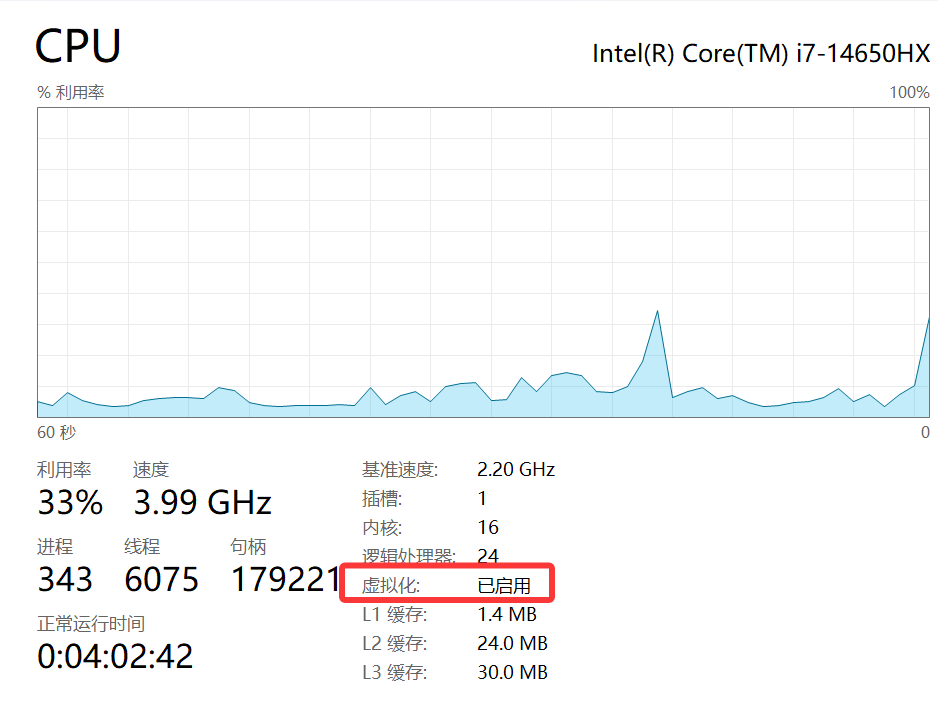
控制面板 》程序 》启用或关闭程序:勾选:
Virtual Machine Platform
Windows虚拟机监控程序平台
适用于Linux 的 Windows子系统
命令行安装wsl
检查wsl版本
wsl --status没有安装过会显示

进行安装
wsl.exe --install置默认版本为wsl2
wsl --set-default-version 2点击进入官网
选择AMD64进行下载
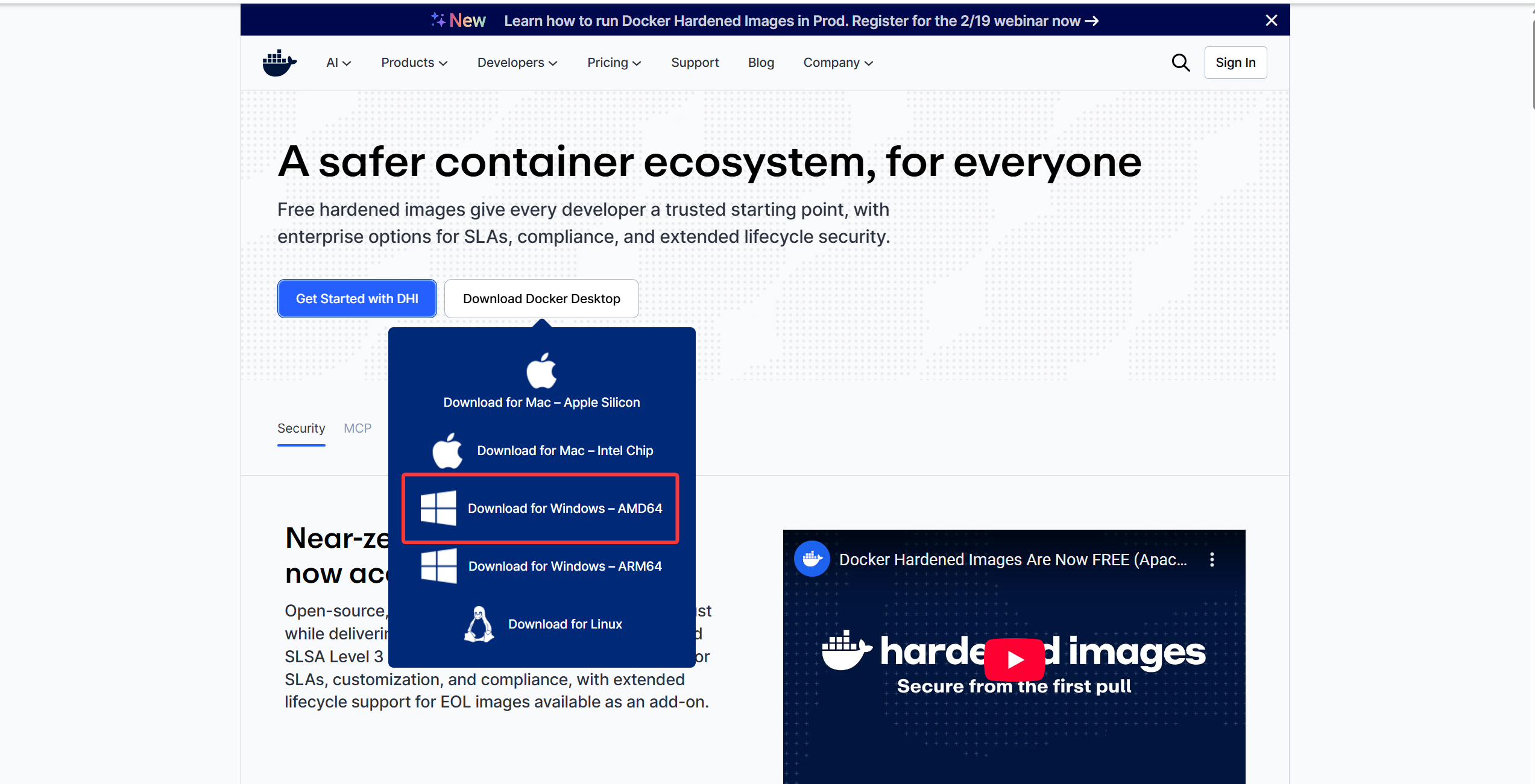
而后直接双击安装包下载即可,新版的docker无需勾选任何选项直接下载也无需下载Docker Compose
测试docker安装,最后运行出: Hello from Docker!表示运行成功
# docker版本 docker --version # docker compose版本 docker-compose --version # 测试运行 docker run hello-world 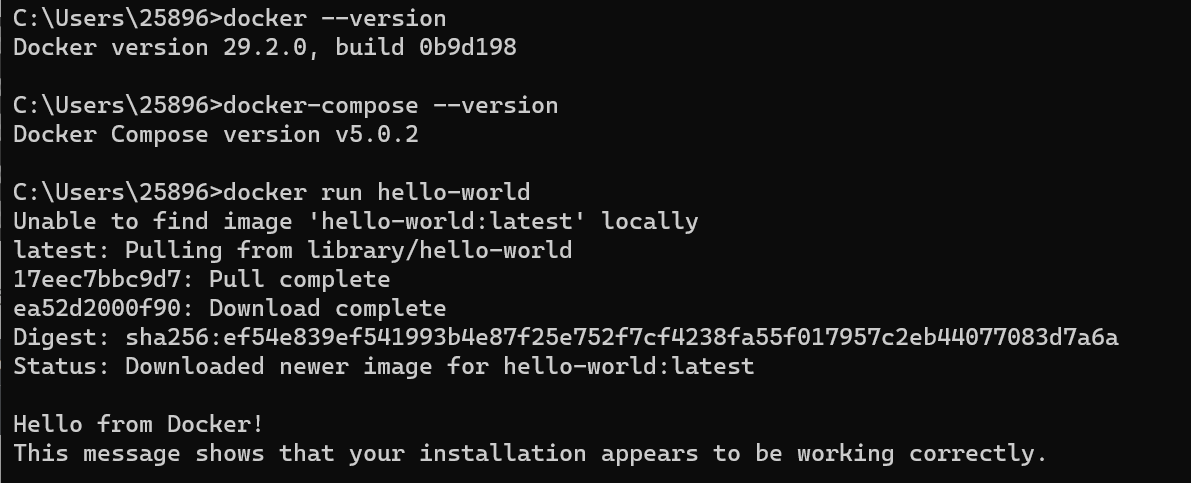
安装好docker后需要进行登录(邮箱也行),然后进行一个配置,点击右上角的设置按钮
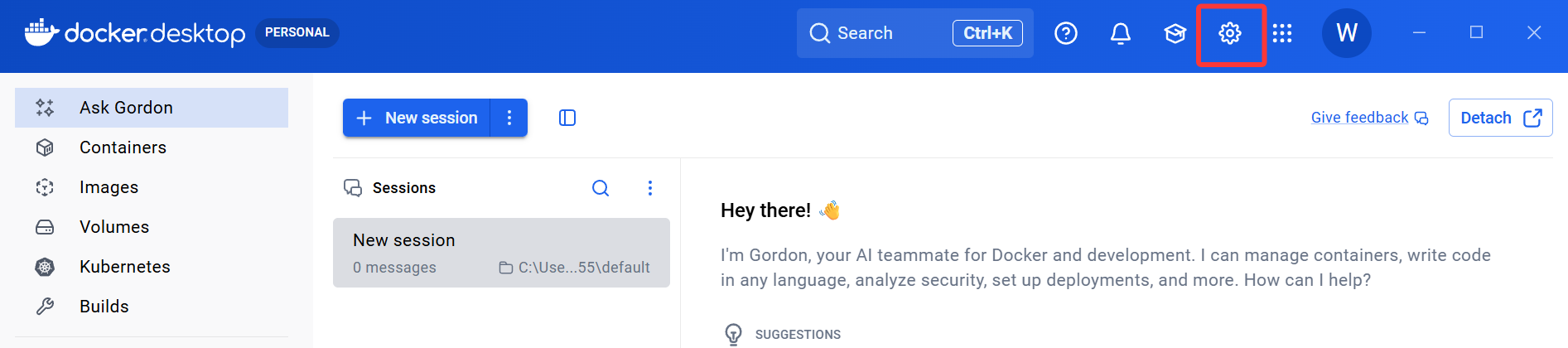
选择Docker Engine,在其中配置Docker的镜像
"registry-mirrors": [ "https://docker.m.daocloud.io", "https://hub-mirror.c.163.com" ]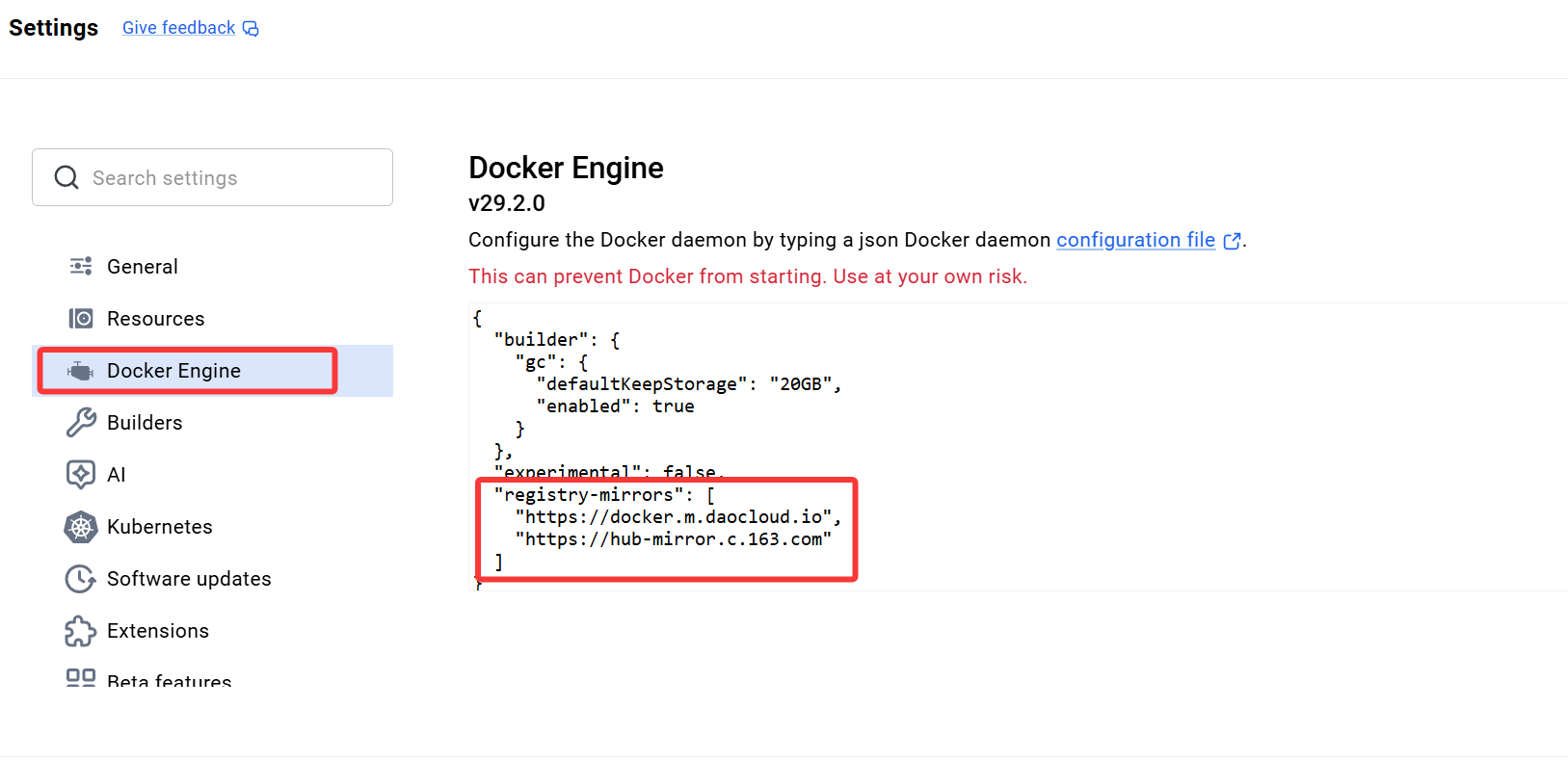
在github上下载dify的文件
下载好后,在docker-main 》 docker 路径下,将.env.example的文件后缀名该文.env
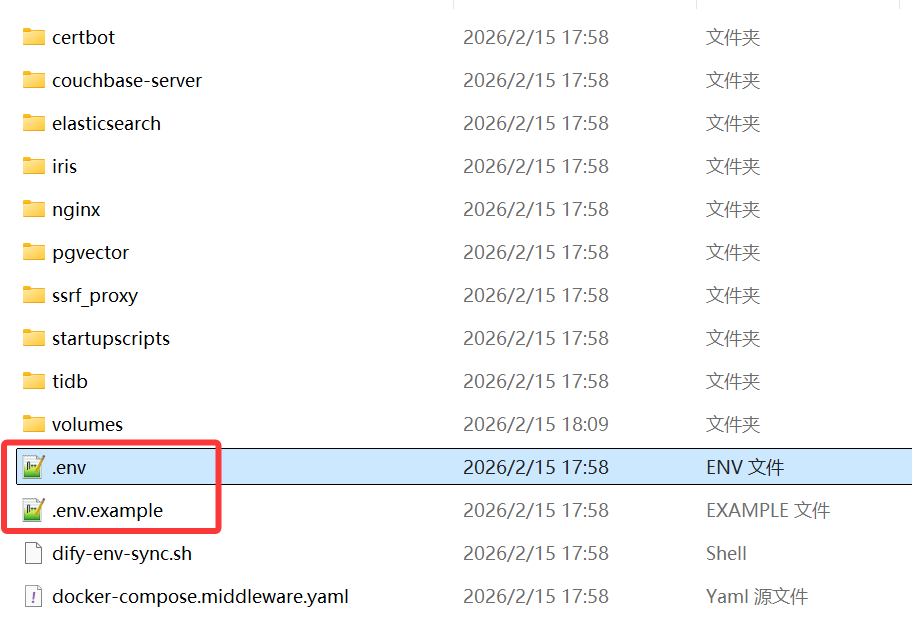
修改好后在该路径下进行下载安装
docker-compose up -d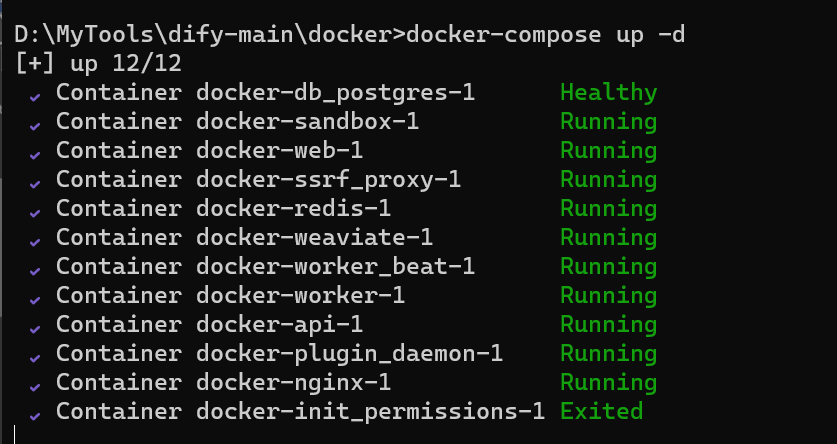
配置好后在浏览器中输入以下网址即可进入本地部署的Dify(端口默认80)
localhost:80/install随后进行一个用户配置即可(注意:在使用Dify前确保Docker是在运行的)
在Ollama官网下载windows版本,下载好后直接install即可
在安装包下载好后,在导航栏输入,即可进入,若显示running则表示安装成功(端口默认11434)
http://localhost:11434/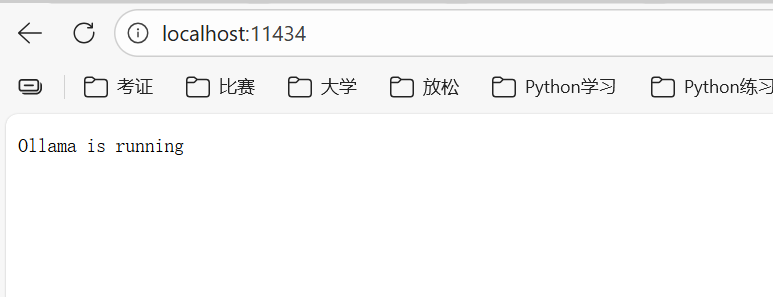
现在开始在ollama中下载部署本地模型,在ollama官网点击 Models
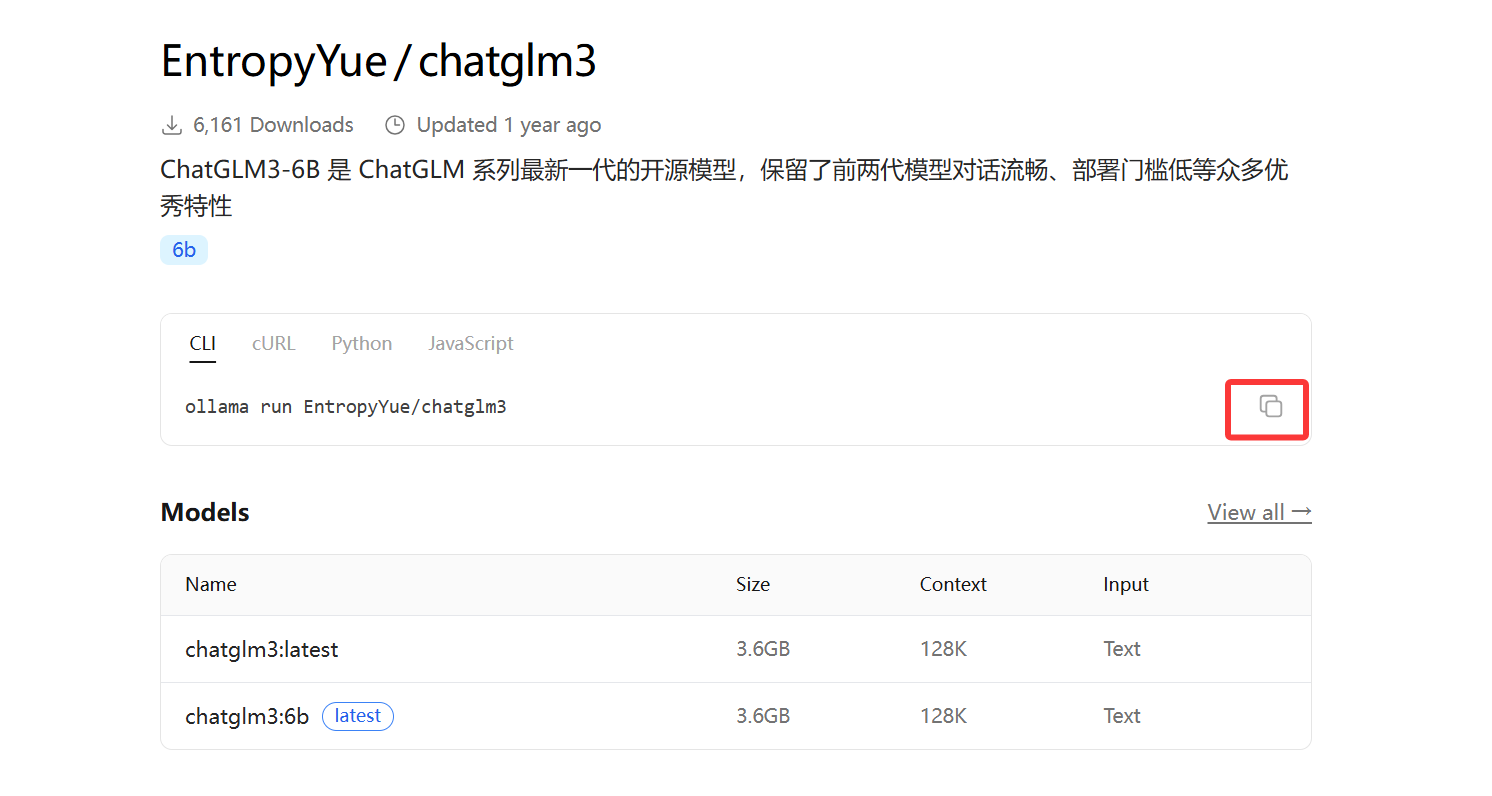
进入模型搜索选择页面,选择自己所需模型即可,这里博主选择的是ChatGLM3-6B模型是 ChatGLM 系列最新一代的开源模型,保留了前两代模型对话流畅、部署门槛低等众多优秀特性
复制命令在命令行中回车下载即可
2.1.1 使用ollama本地部署模型
首先在docker文件夹的.env文件中添加,接受模型调用地址
# 启用自定义模型 CUSTOM_MODEL_ENABLED=true指定 Ollama 的API地址
OLLAMA_API_BASE_URL=host.docker.internal:11434
在点击右上角个人头像框 》设置 》模型供应商 》安装Ollama
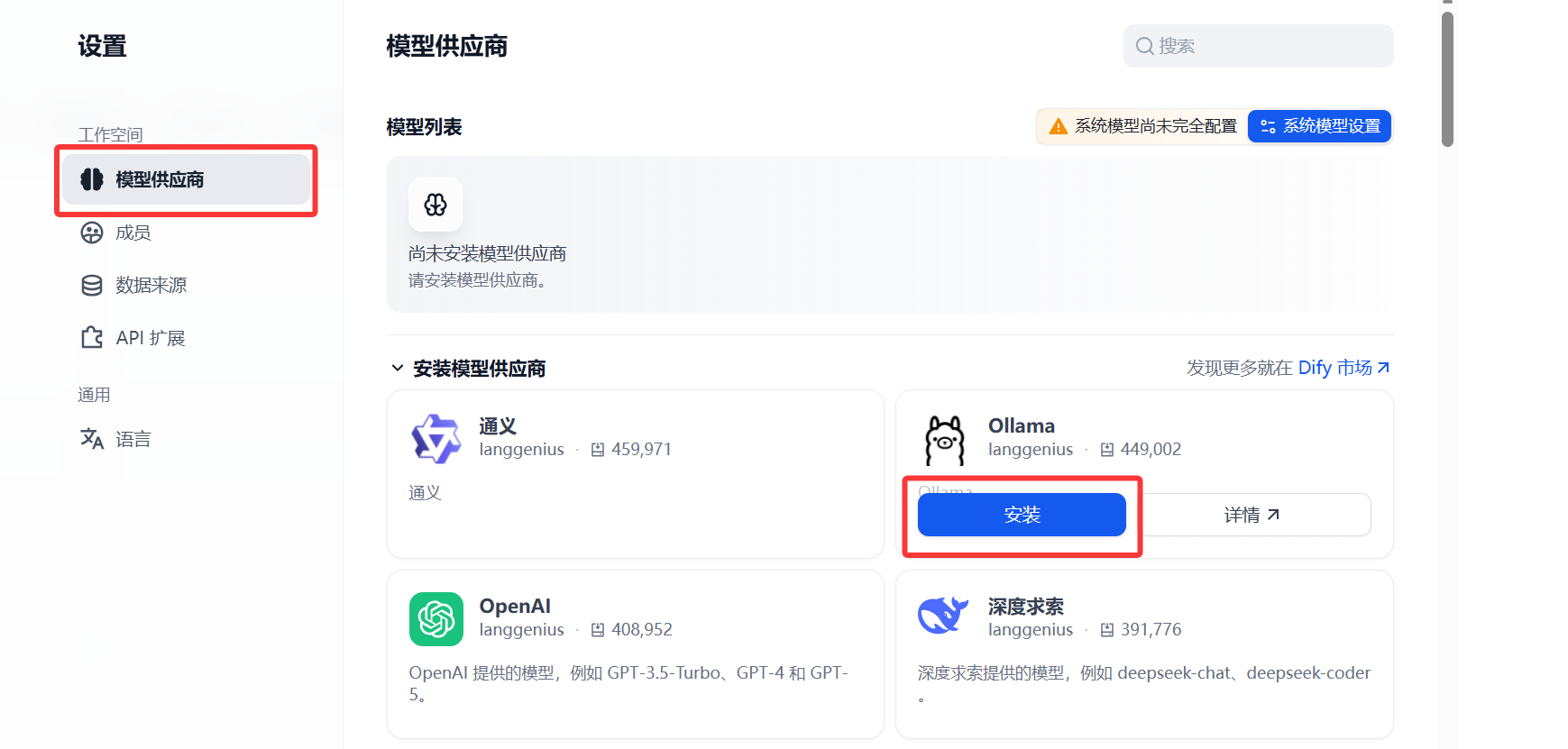
下载好ollama后选择 添加模型,模型名称处要与ollama下载时的名称一致,基础url即为Ollama指定的API地址
http://host.docker.internal:11434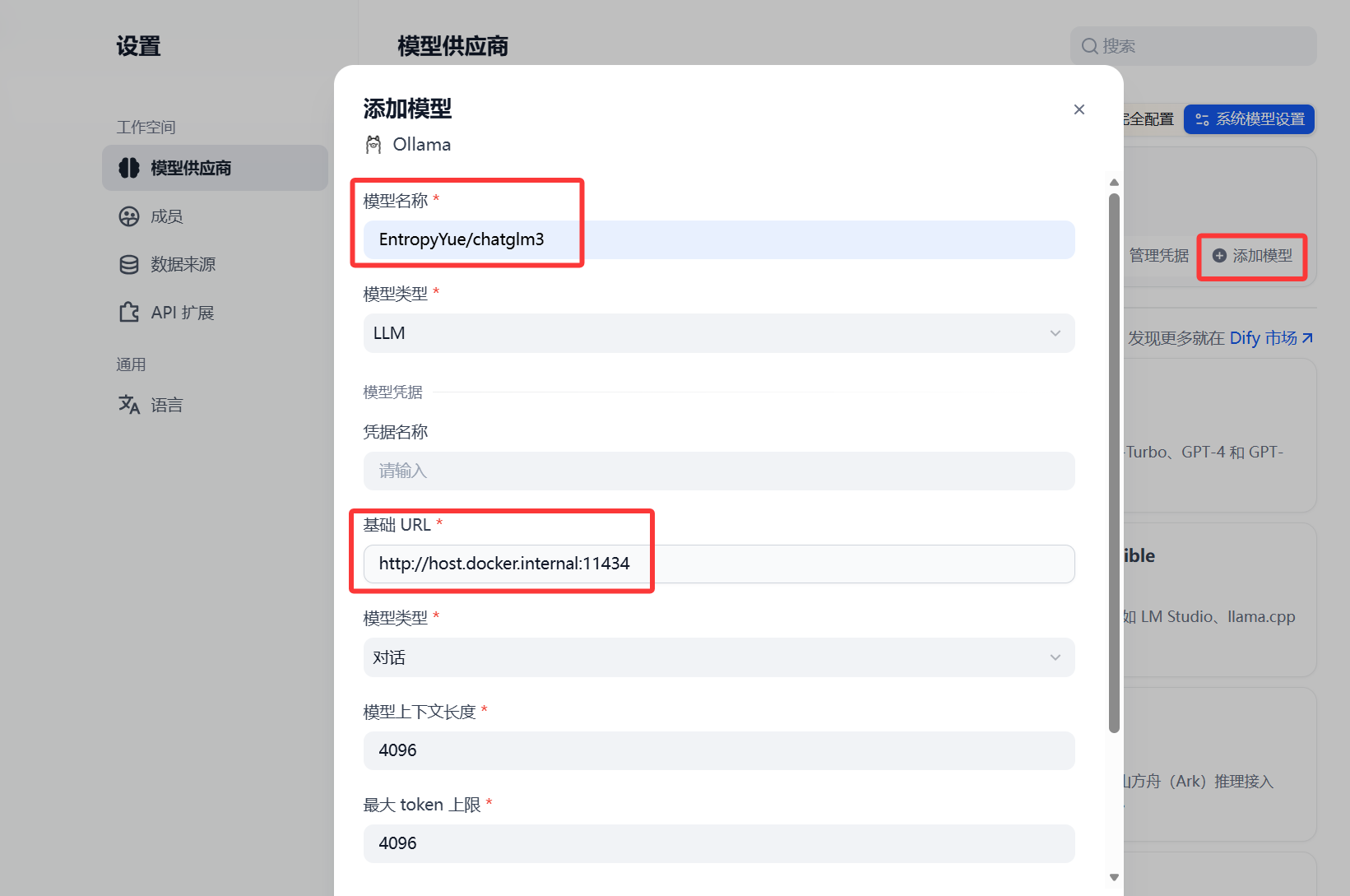
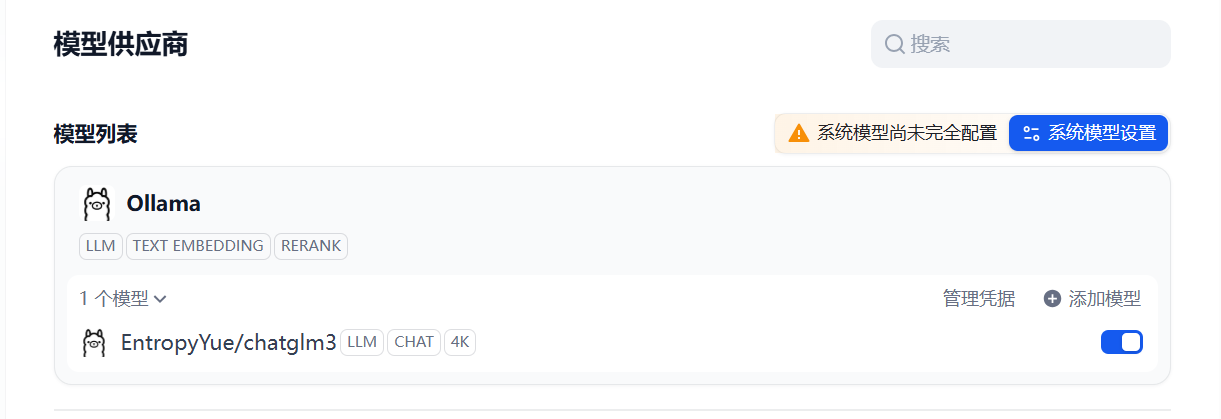
配置成功
2.1.2 调用API模型
下载通义插件,选择添加模型,点击进入阿里云百炼
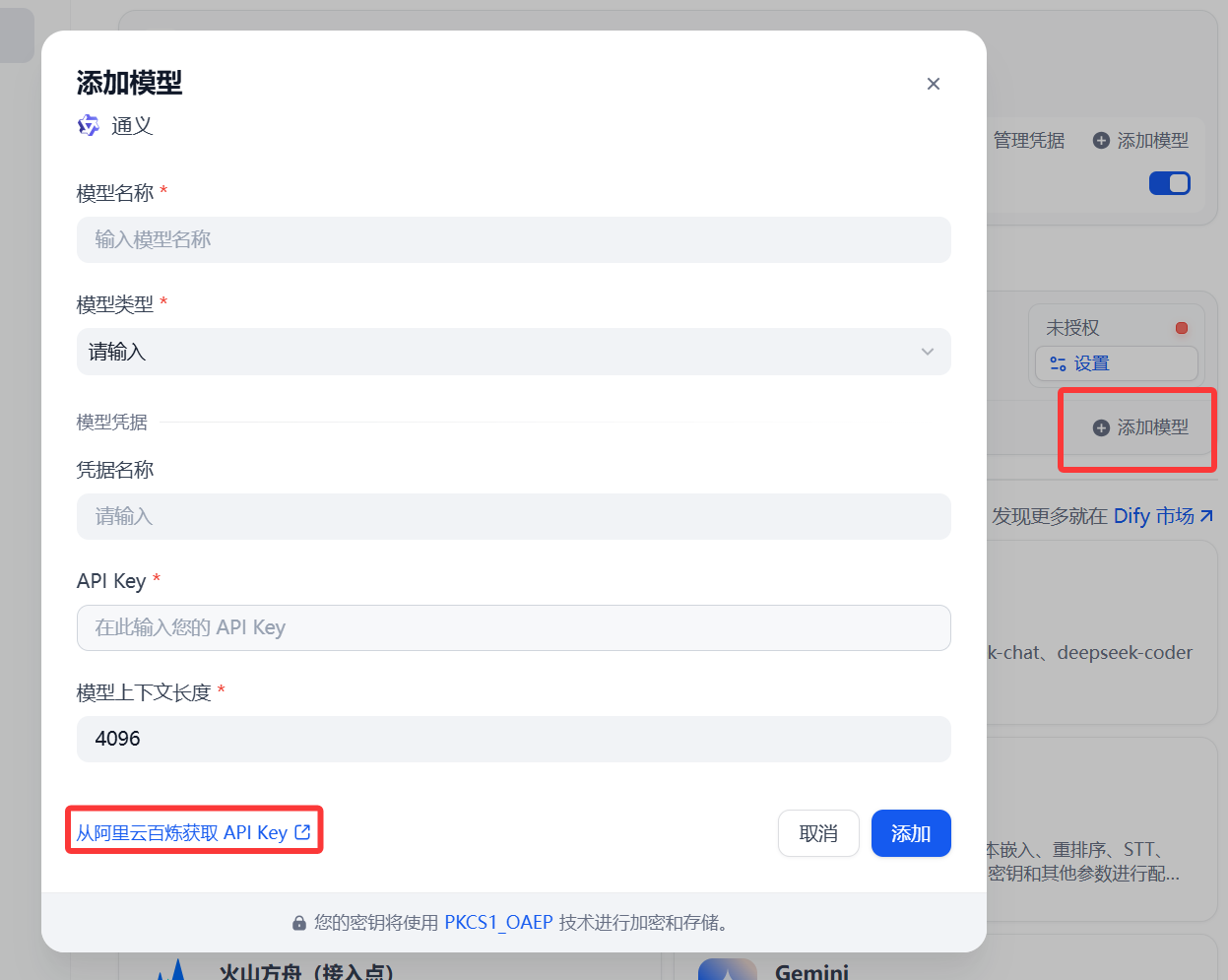
选择密钥管理,创建API Key,并复制(记得开启:免费额度用完即停)
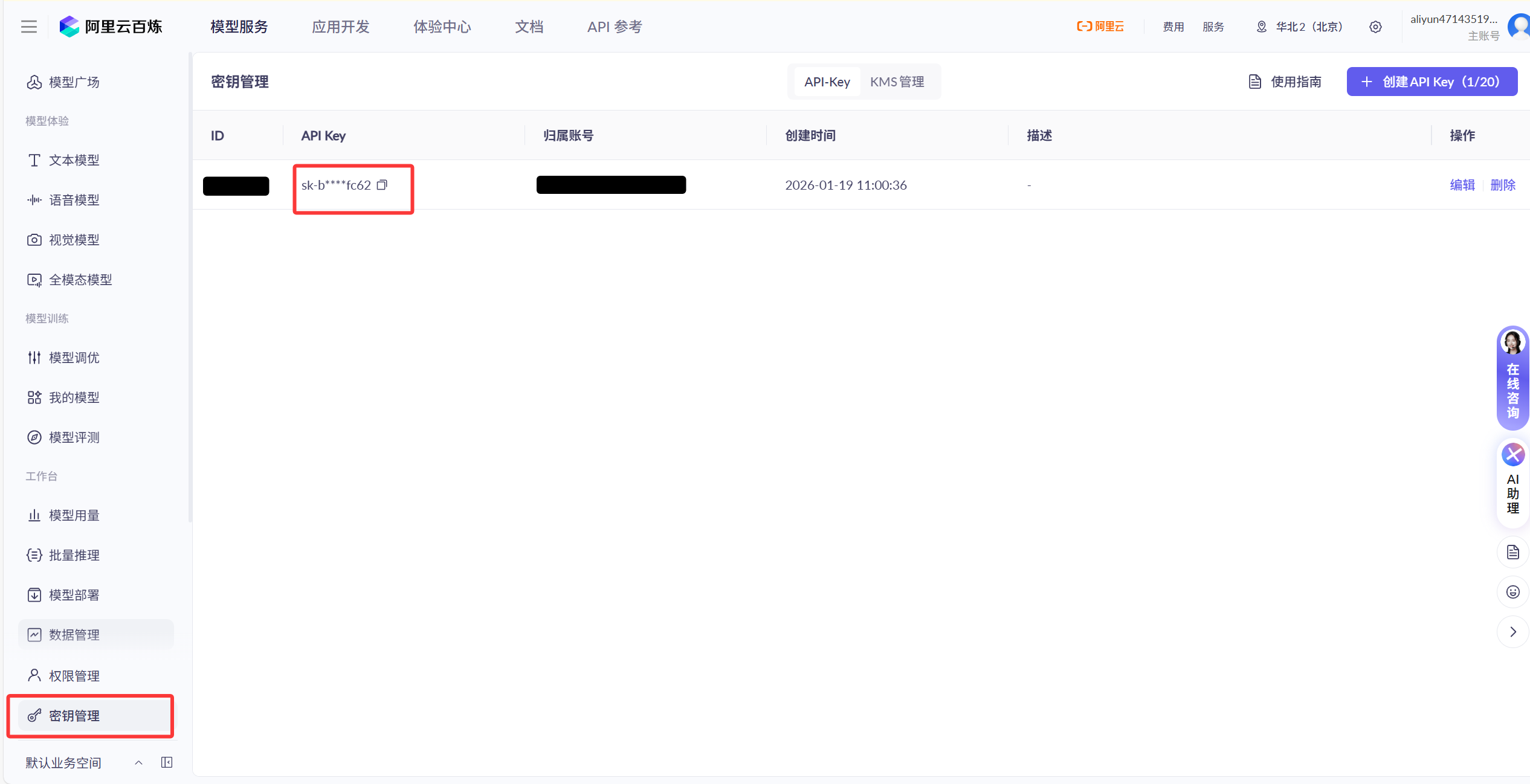

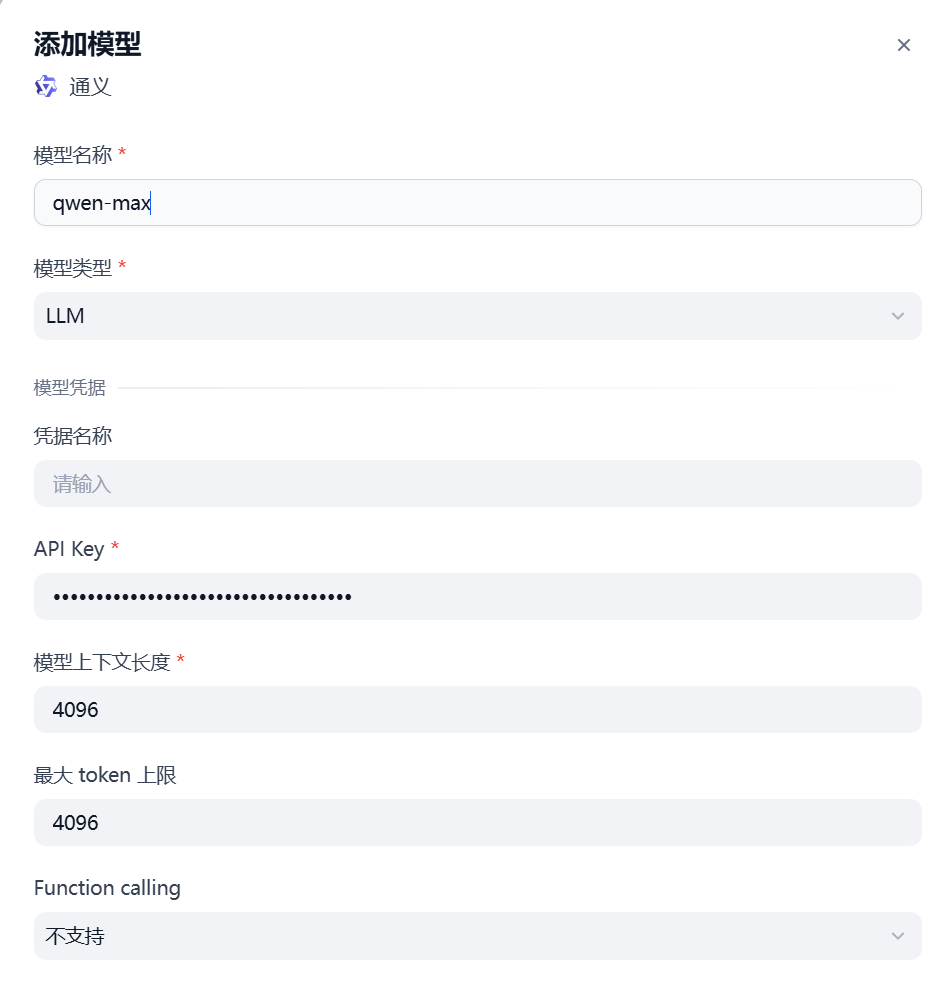
将复制好的API Key输入,模型选择qwen-max(自己选择即可)
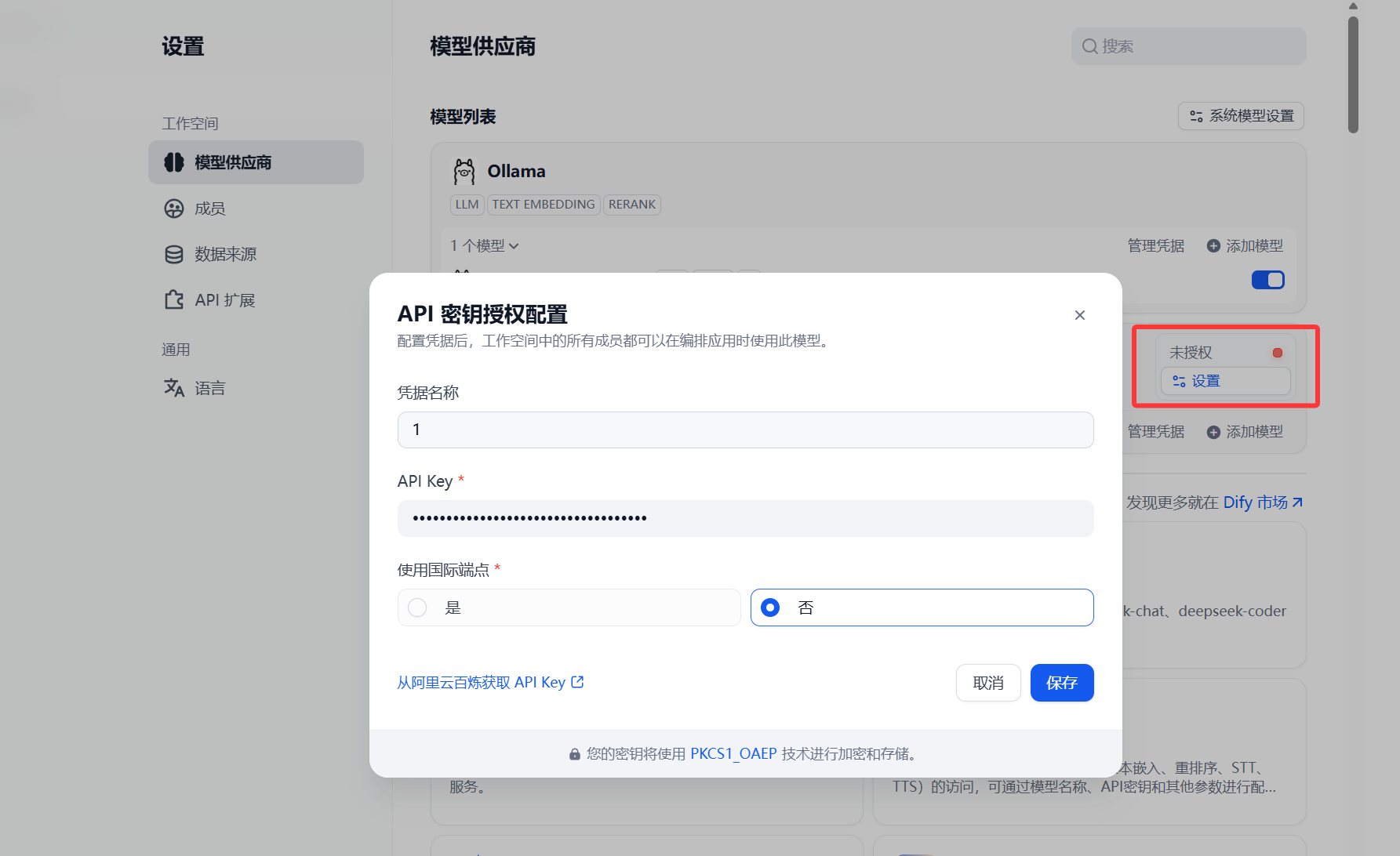
对API 密钥进行授权配置,重复操作即可
2.1.3 Dify中创建agent
将模型配置好后(本地/API任选其一),我们开始在Dify中创建Agent智能体应用,回到Dify首页,点击Agent(如果直接在全部中创建不会显示agent和聊天助手选项),点击创建空白应用
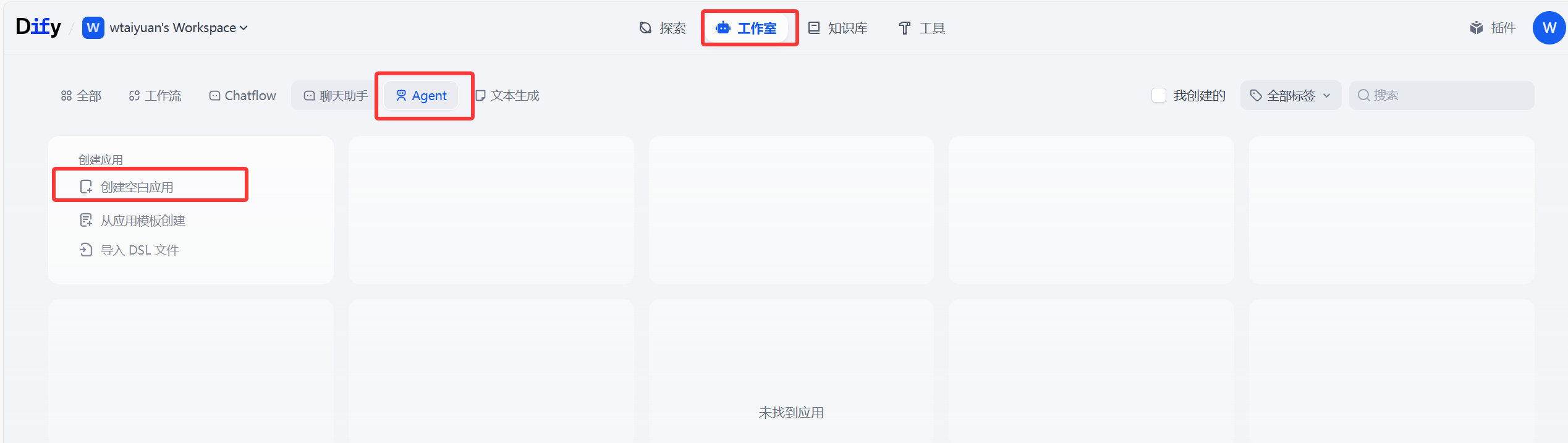
这里我们选择Agent创建
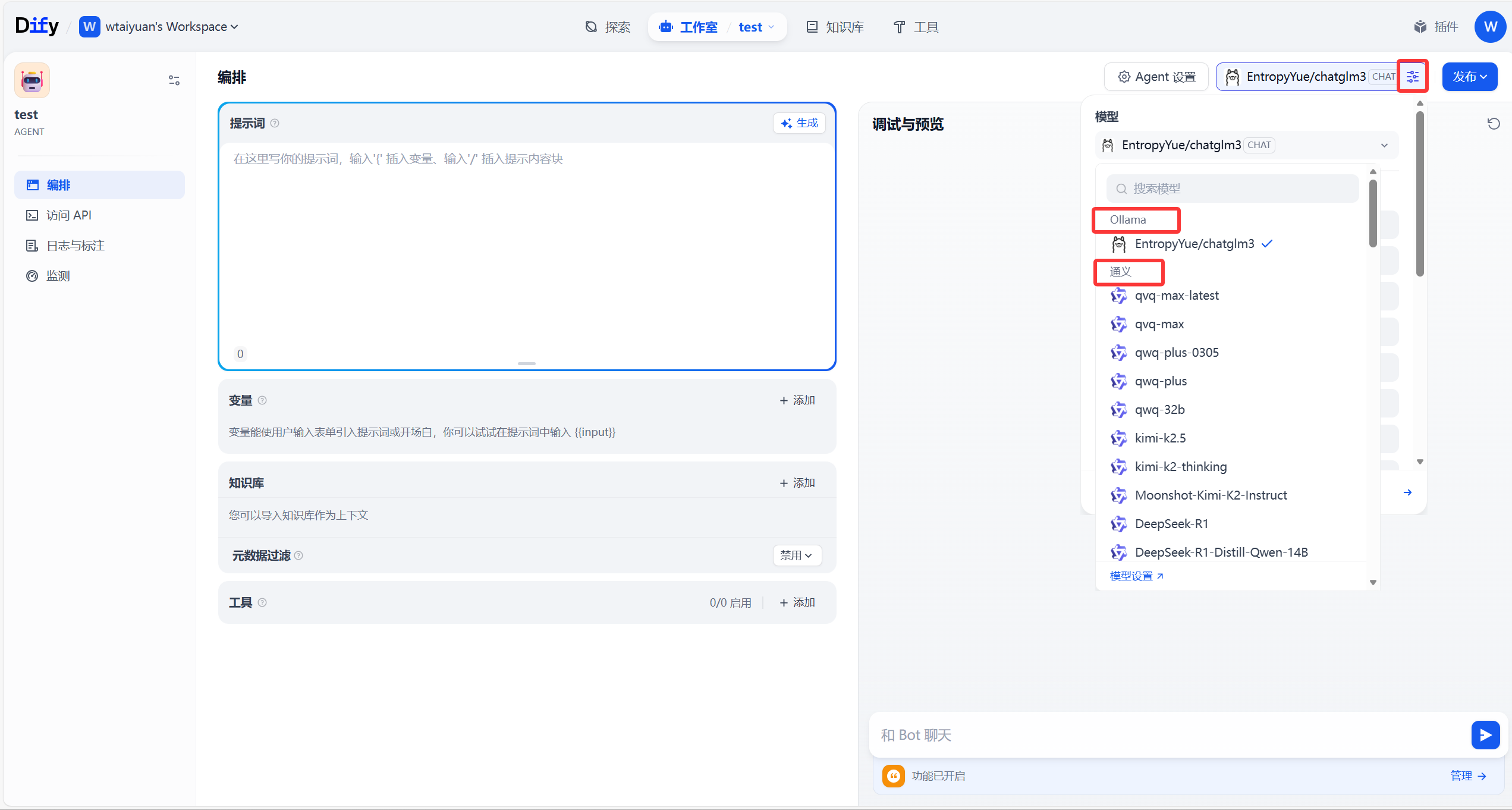
此时,会自动匹配好调用模型,可以供用户自主选择
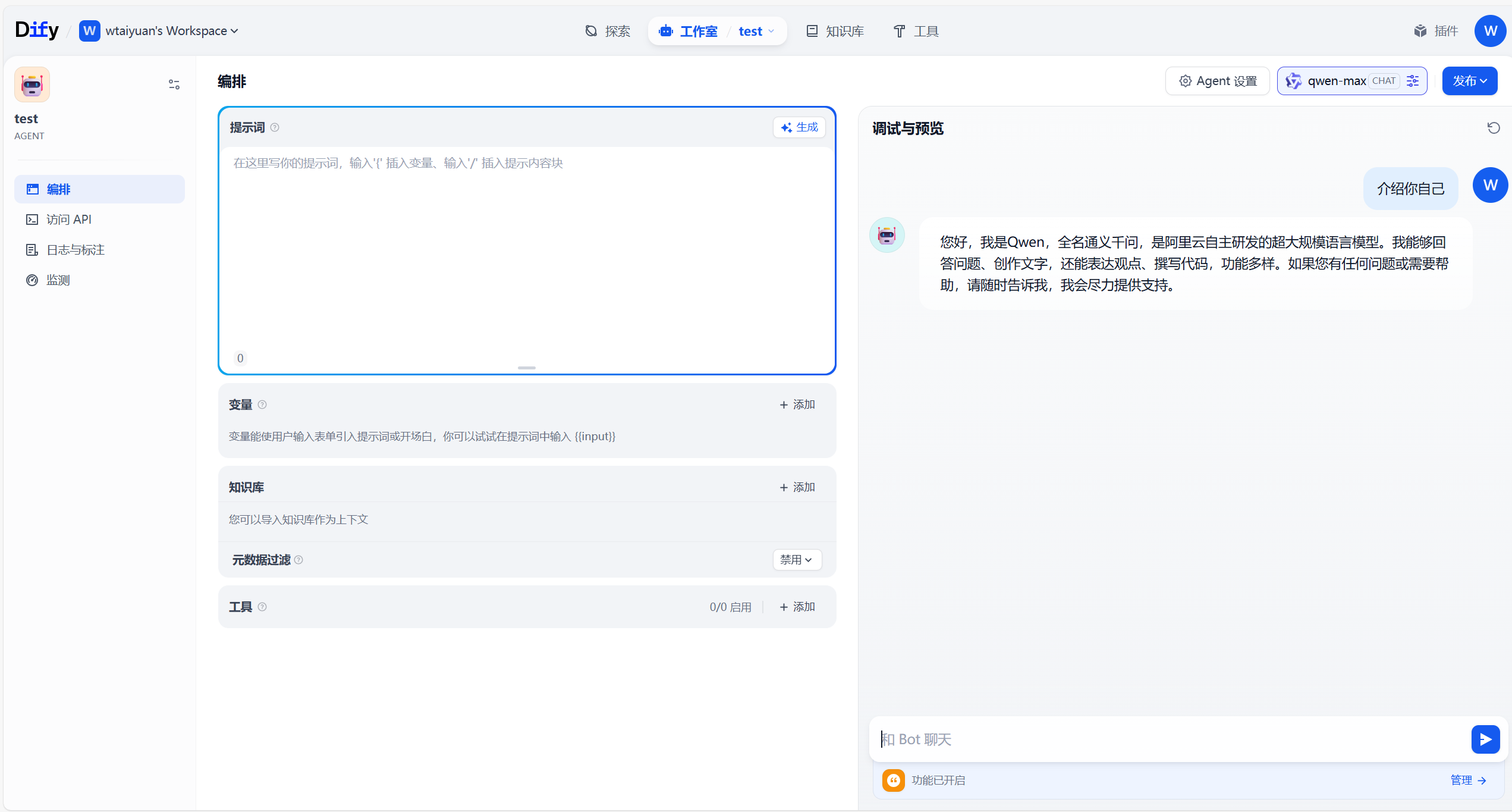
配置好之后就能使用了
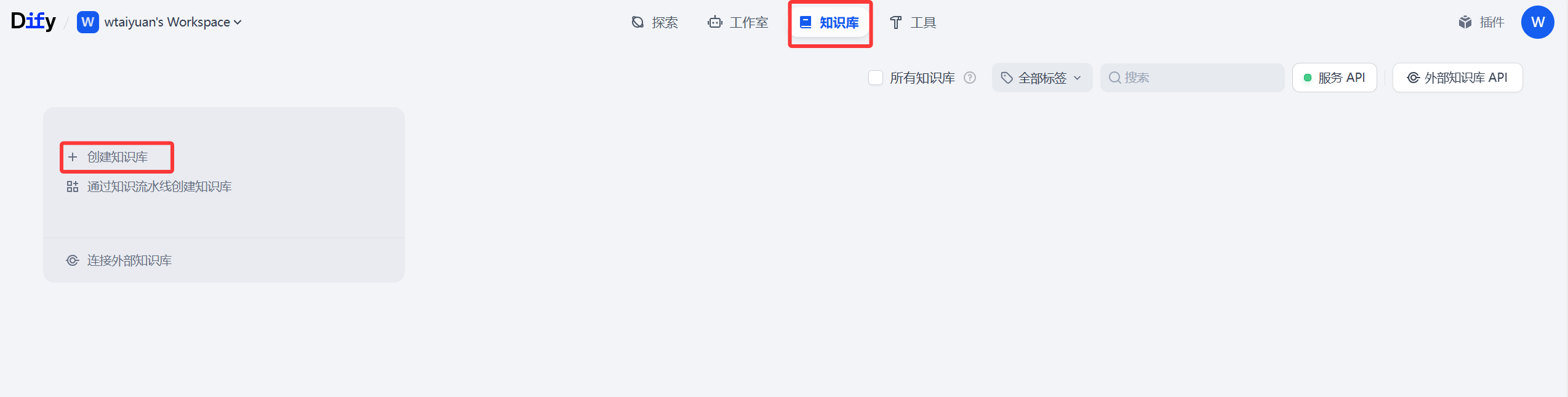
返回首页,选择知识库 》创建知识库
选择导入已有文本,选择文件,然后点击下一步
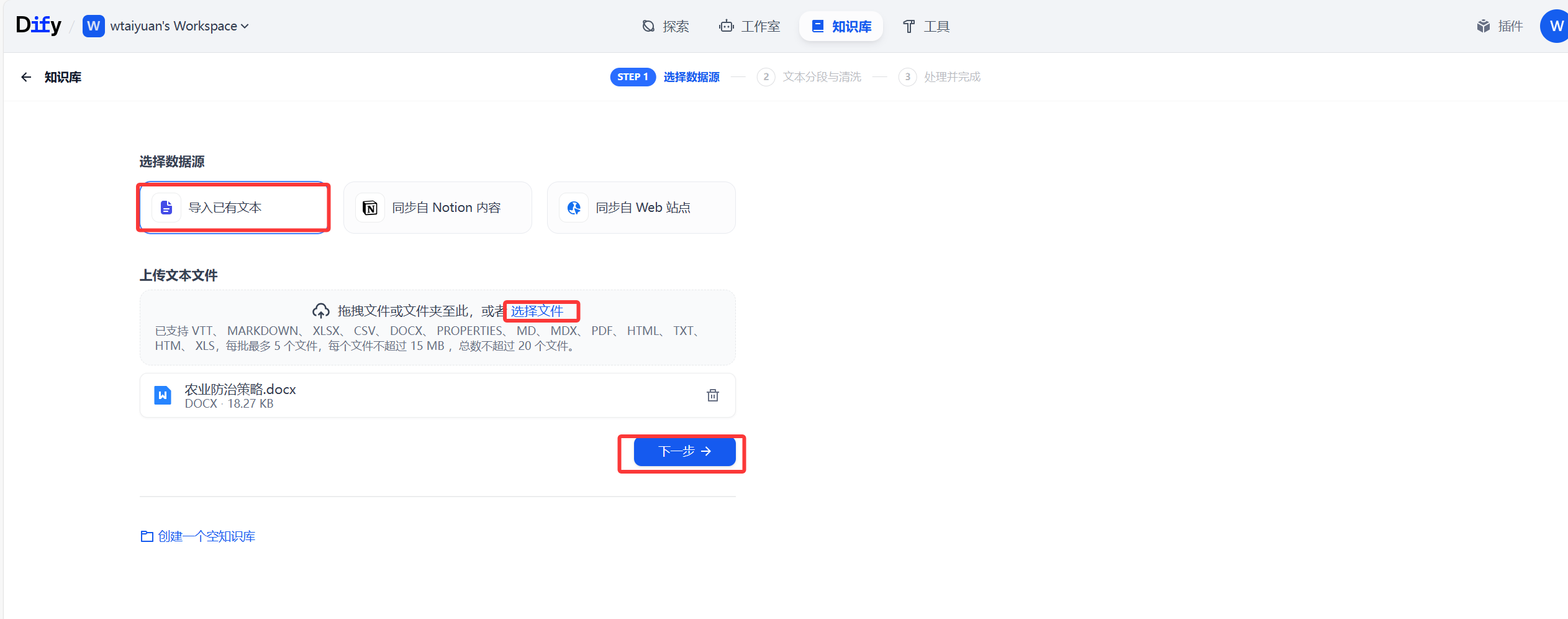
对文本进行分段与清洗,选择自己所需参数,其中Top K标识对在排名前x名的数据进行引用,Score阈值则为当大于该阈值的才进入筛选进行排名引用,保存并处理
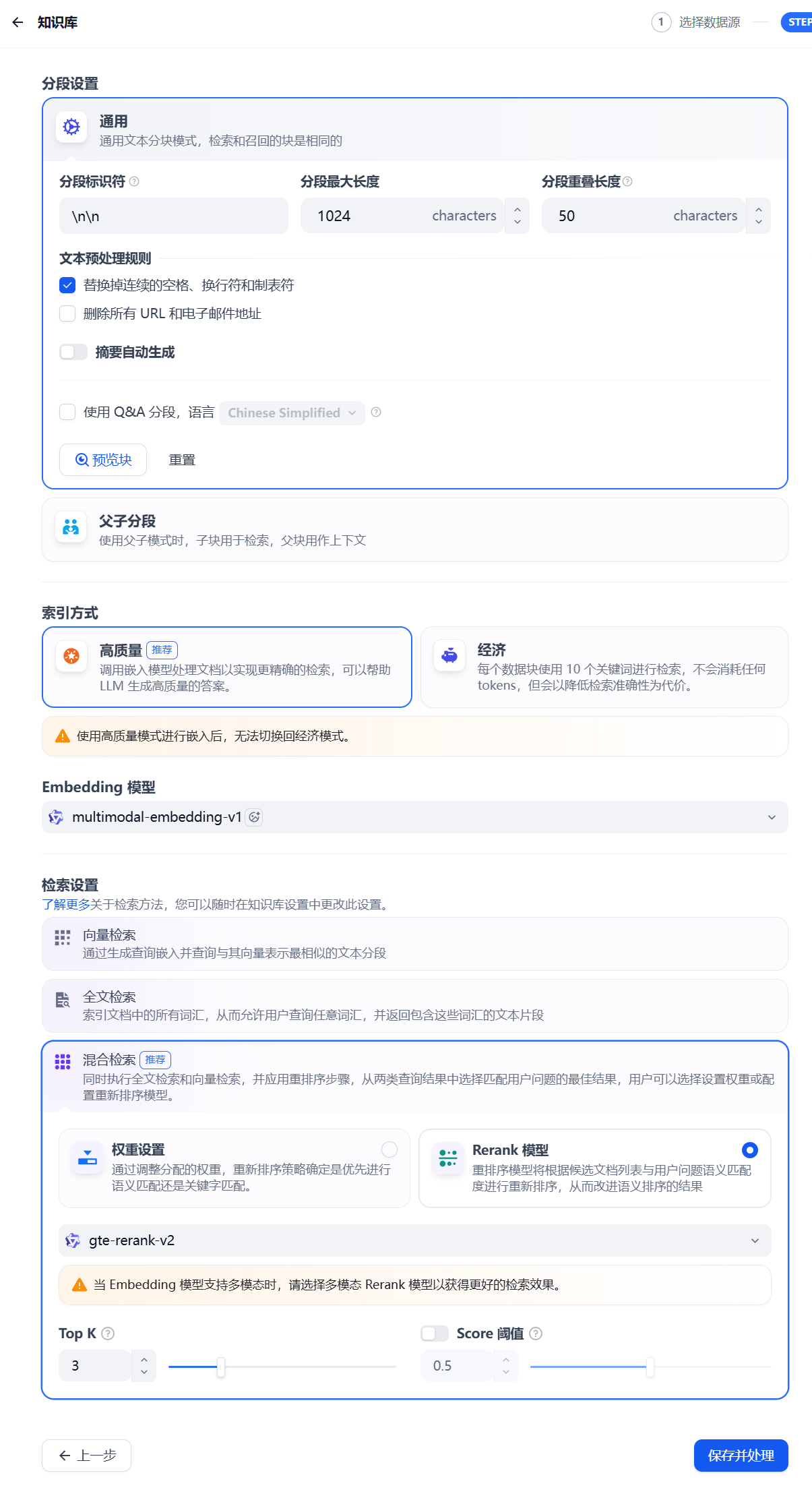 当状态显示为可以时,即成功
当状态显示为可以时,即成功
在实际使用中更多的是需要一些流程判断以及MCP插件来支持业务逻辑的实现,所以选择直接通过ChatFlow工作流编排来实现业务效果,此处博主将直接使用毕设案例进行操作
直接进行创建ChatFlow工作流,成功后如图,而后直接删除LLM和直接问答,自主根据需求编排
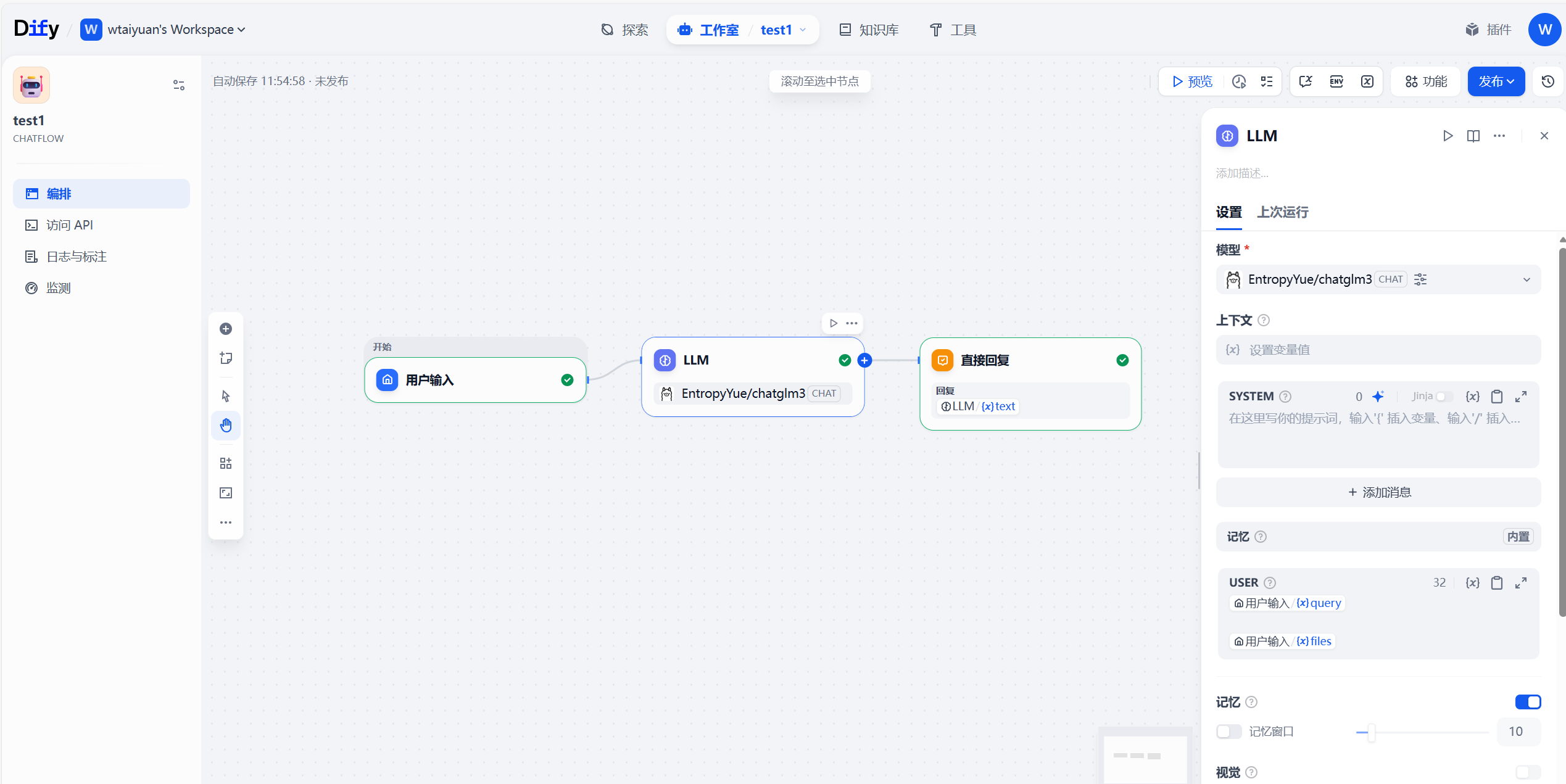
现在博主要编排一个功能包括病虫害防治/生长预测和建议/用户问答功能的工作流,实现在用户输入处编写一些变量,name表示病虫害/作物名称,type表示当前类型(用于判断是防治还是生长),相关参数如下
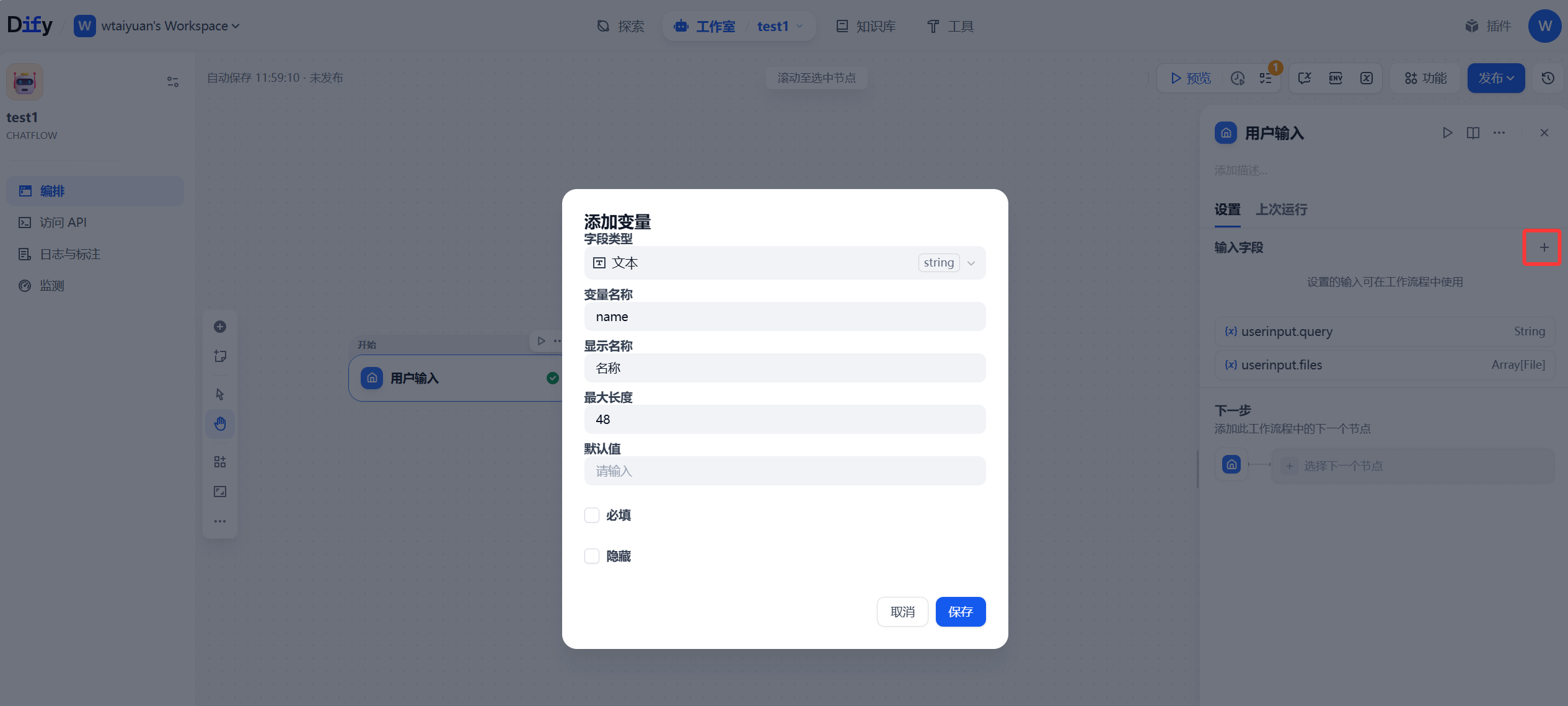
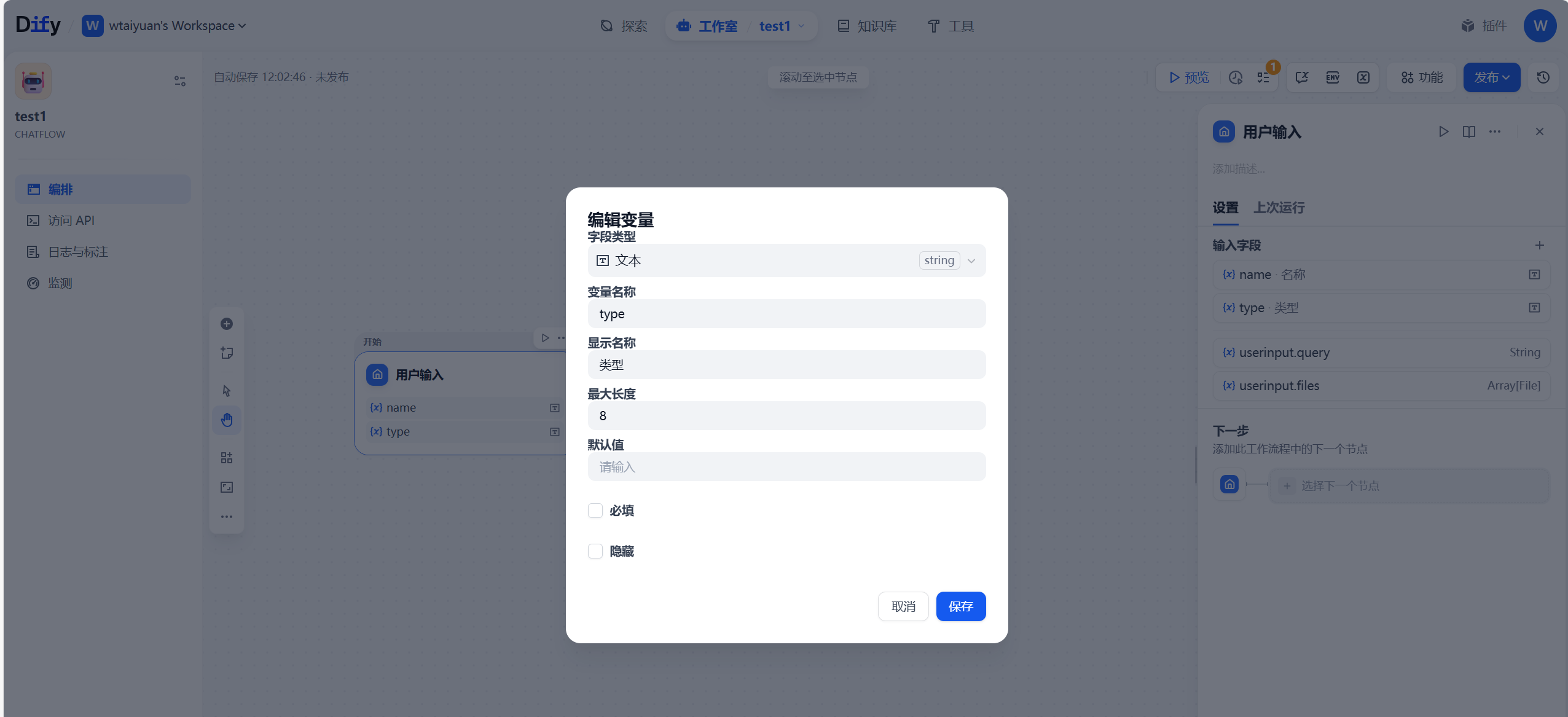
变量参数设置好后,开始编排逻辑,选择逻辑:条件分支
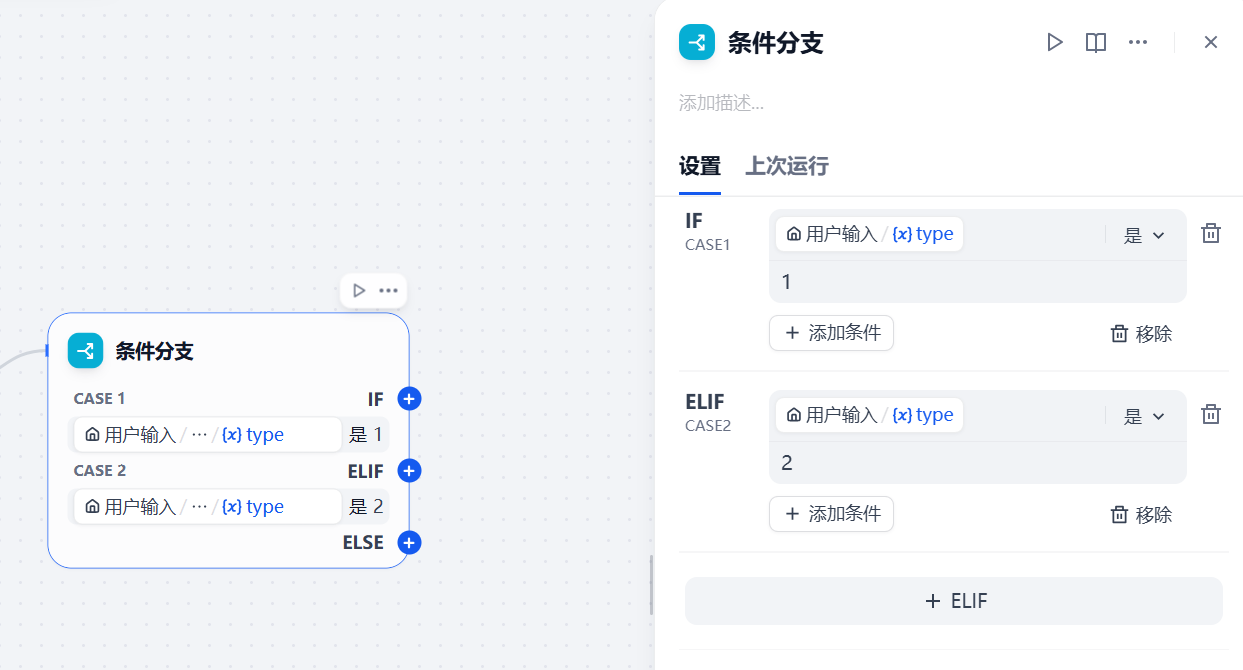
通过type值来判断工作流走向何处,此处我们设定当type是1时为病虫害防治,type是2时为农作物生长预测与建议,都不满足时进入用户问答
2.3.1 智能问答
由于是用户直接进行问答对话,所以在后面直接添加LLM模型,直接回复即可
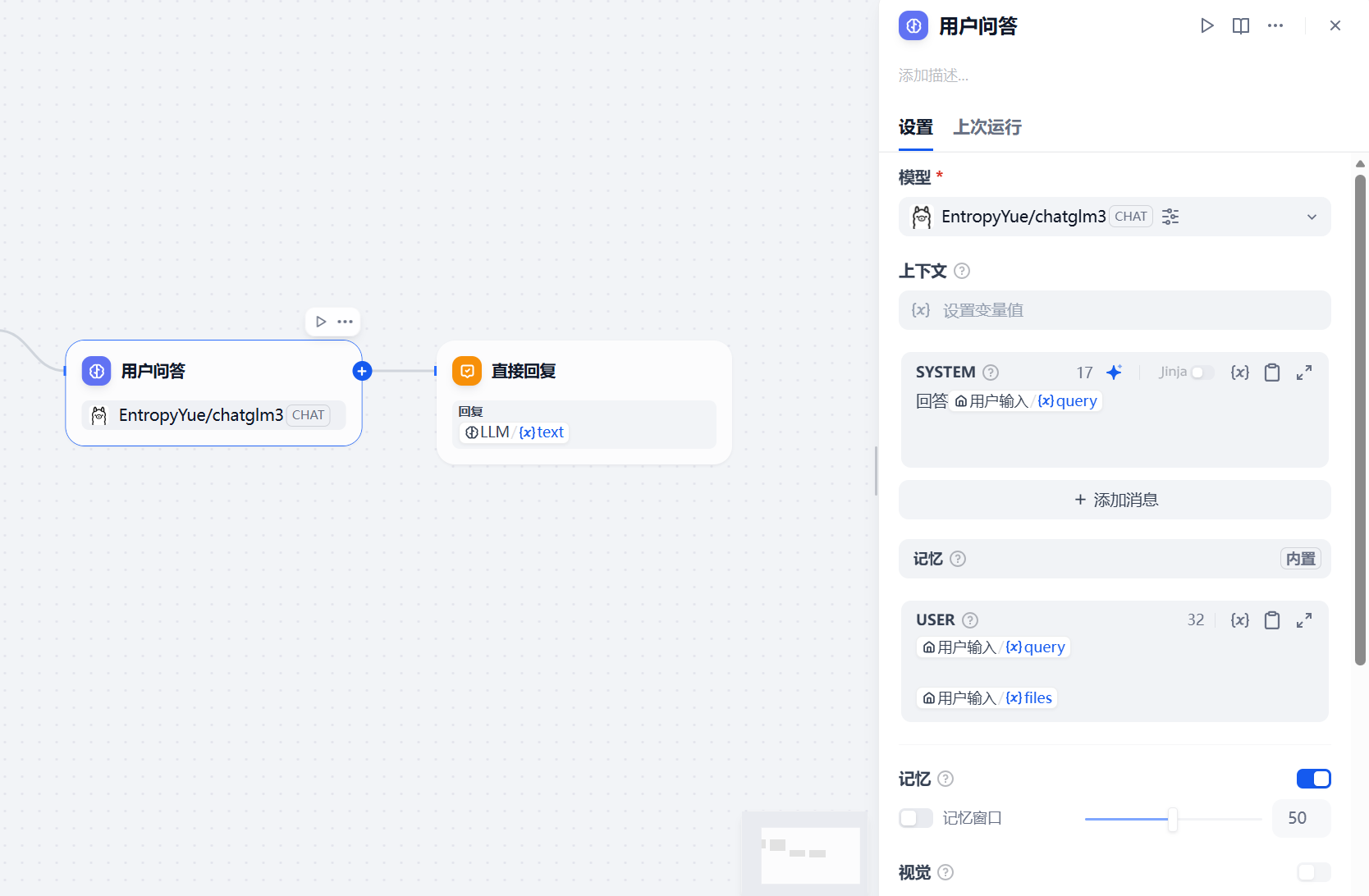
2.3.2 病虫害防治
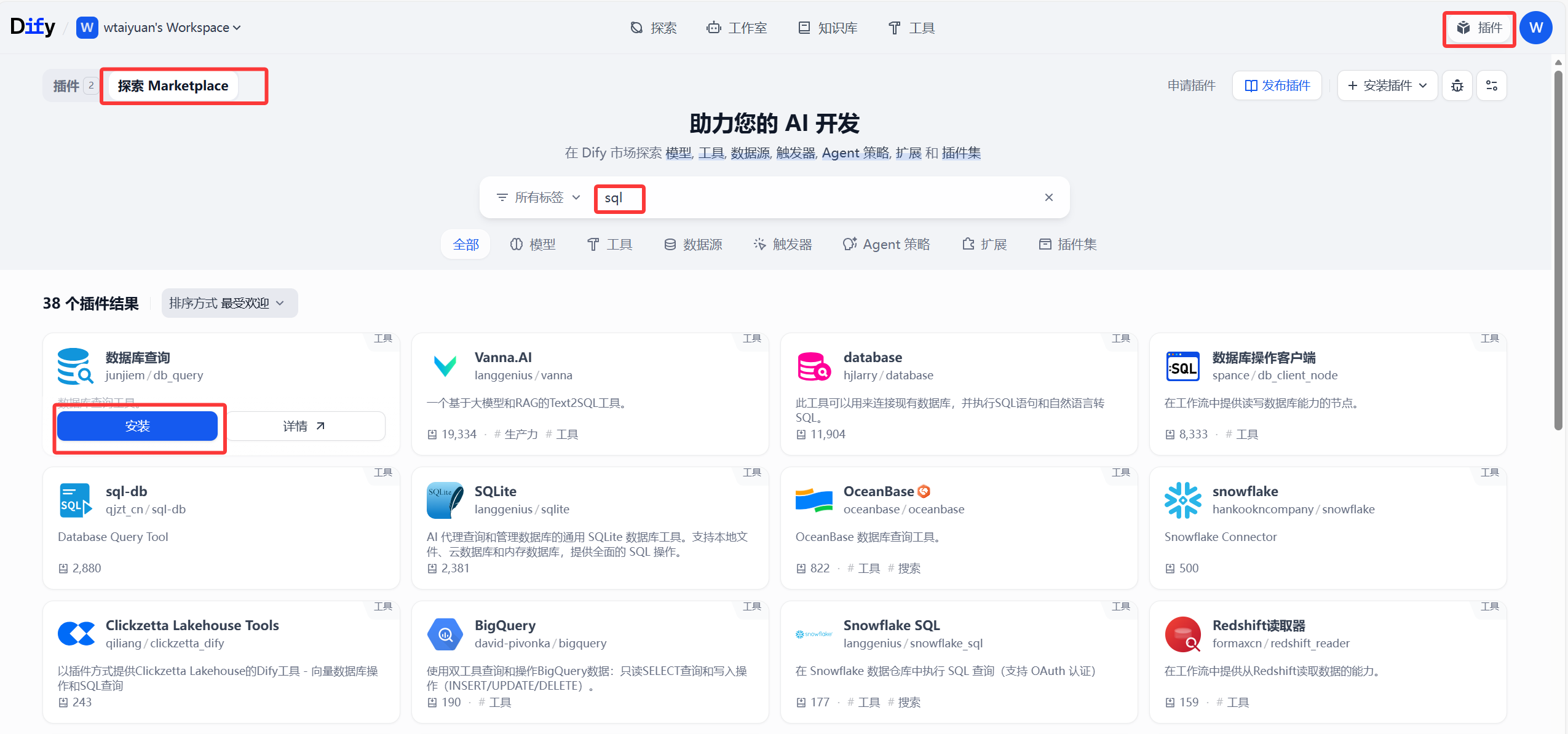
从这里开始,我们需要用到MCP进行数据库内容的调用了,点击右上角 插件 》探索Marketplace 》搜索sql 》安装数据库查询
用于连接本地数据库,对所属数据进行查询
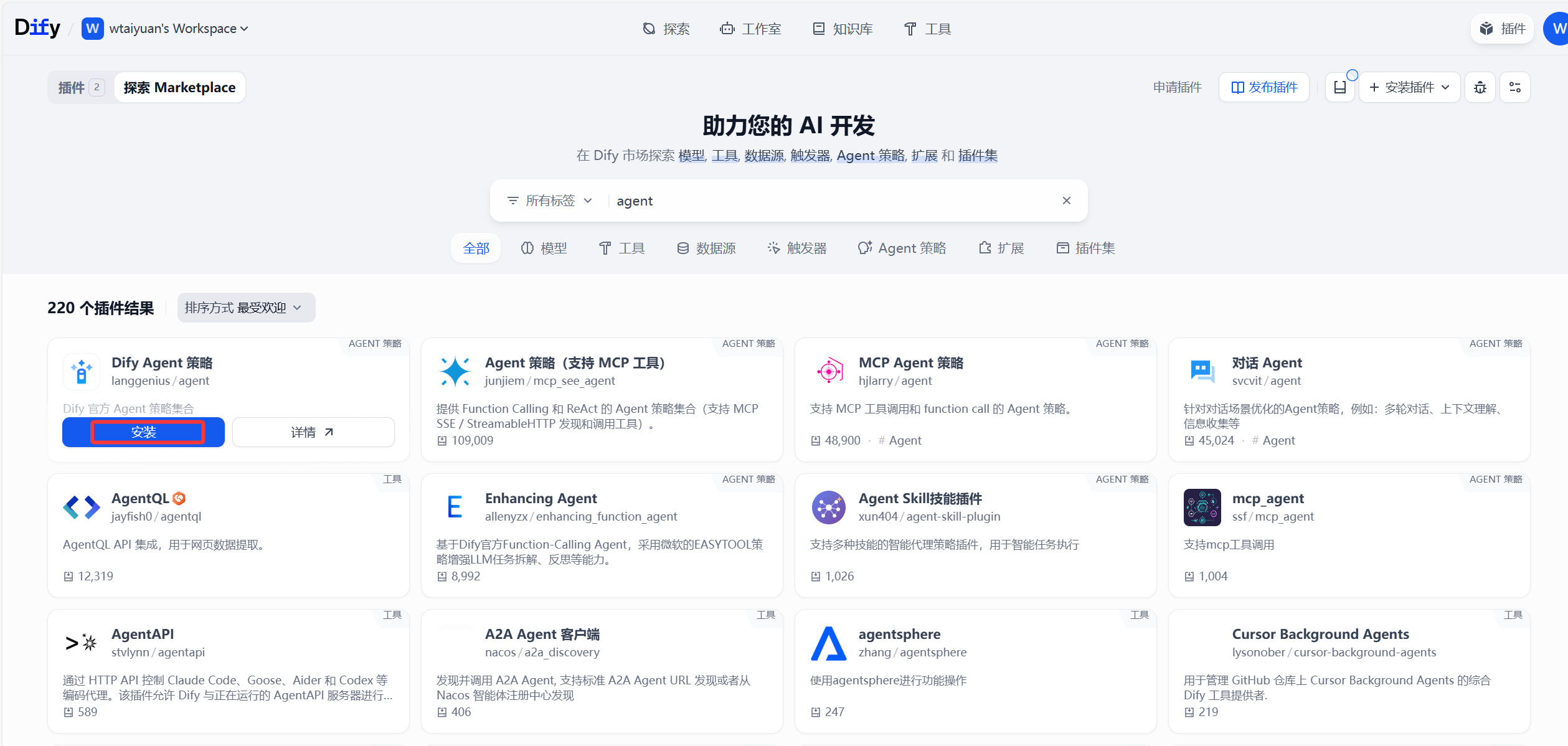
再下载一个Agent策略通过MCP对mysql进行调用
全部安装好后,回到ChatFlow工作流中,在type是1的后面添加Agent
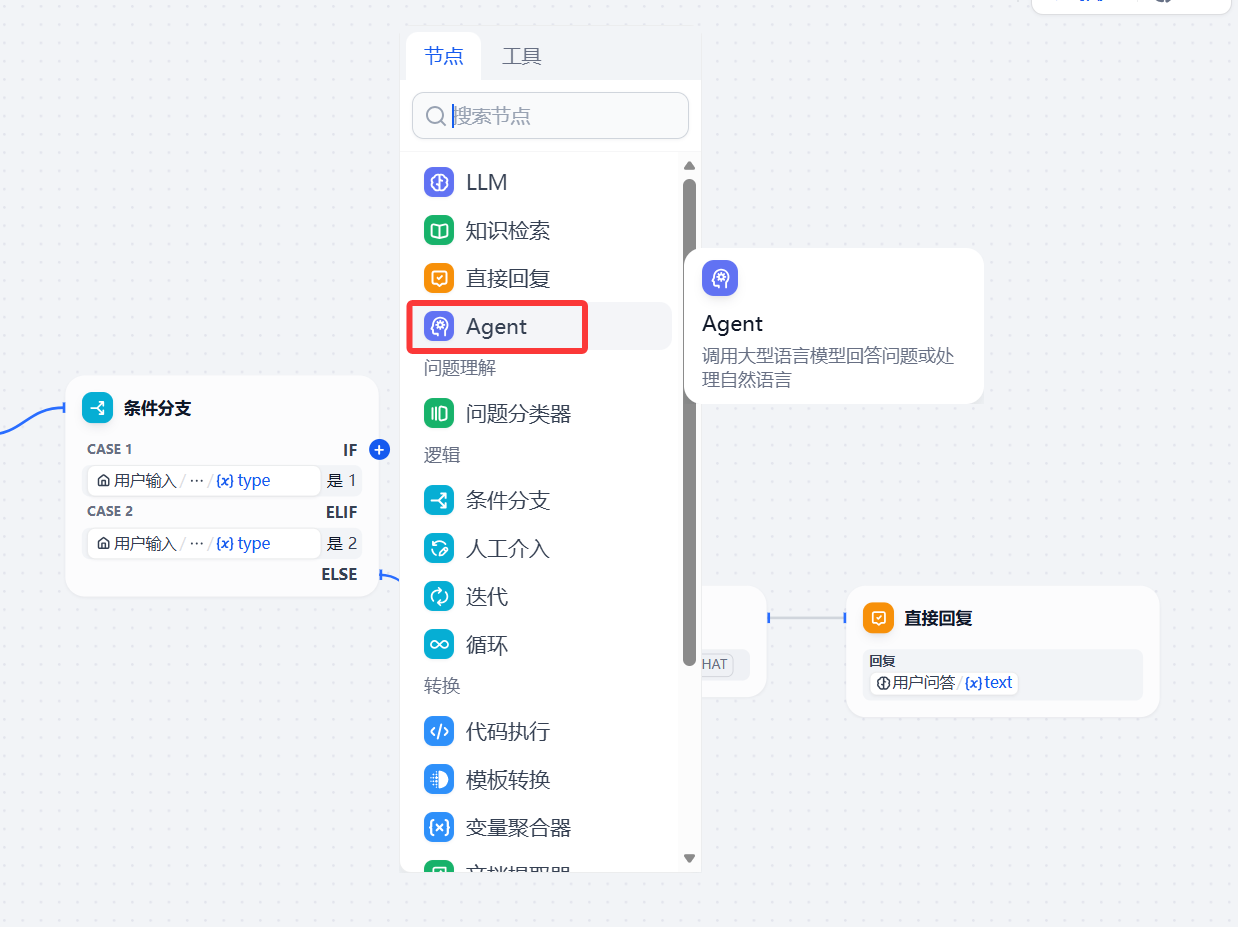
在Agent中,选择AGENT策略 》Agent 》FunctionCalling
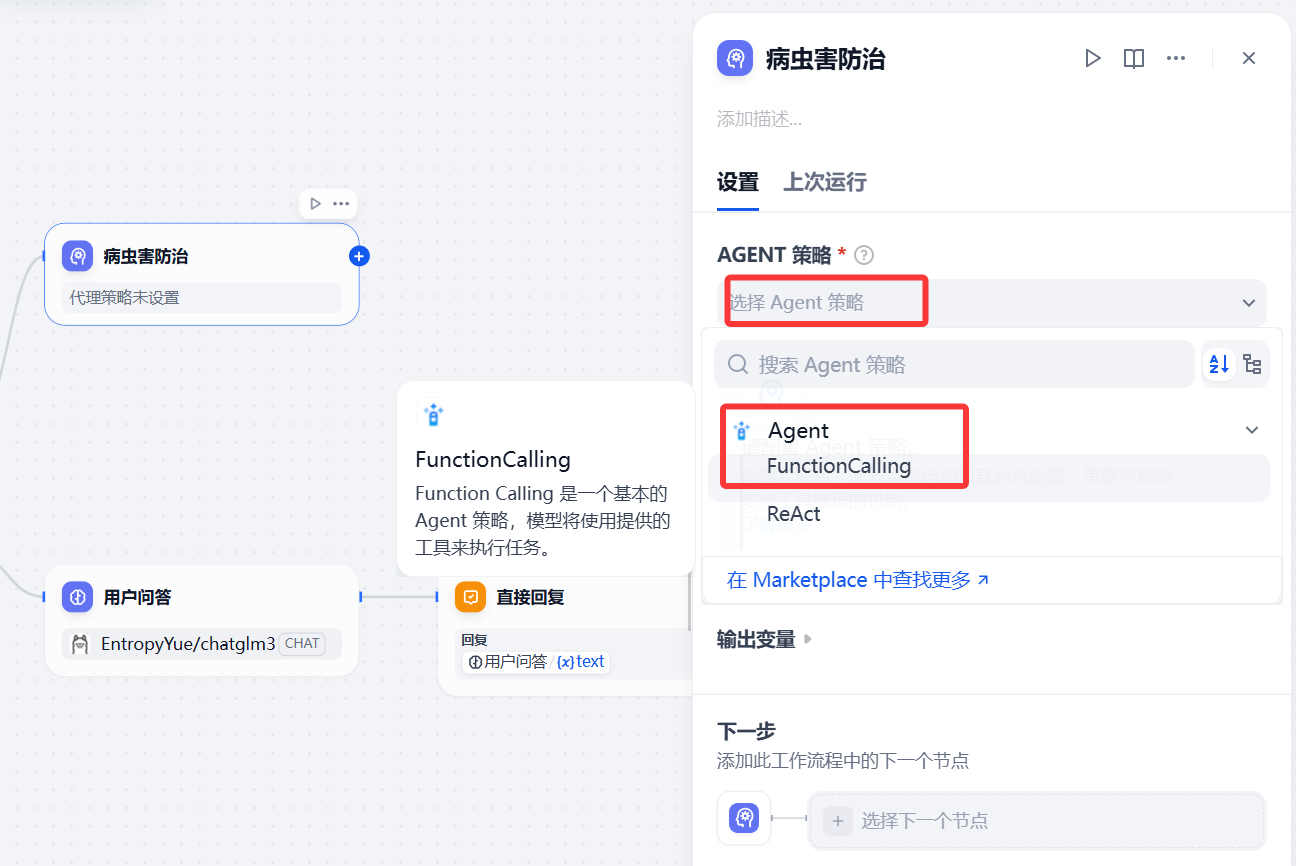
选择模型,在工具列表点击+号,添加工具 》插件 》数据库查询 》SQL查询
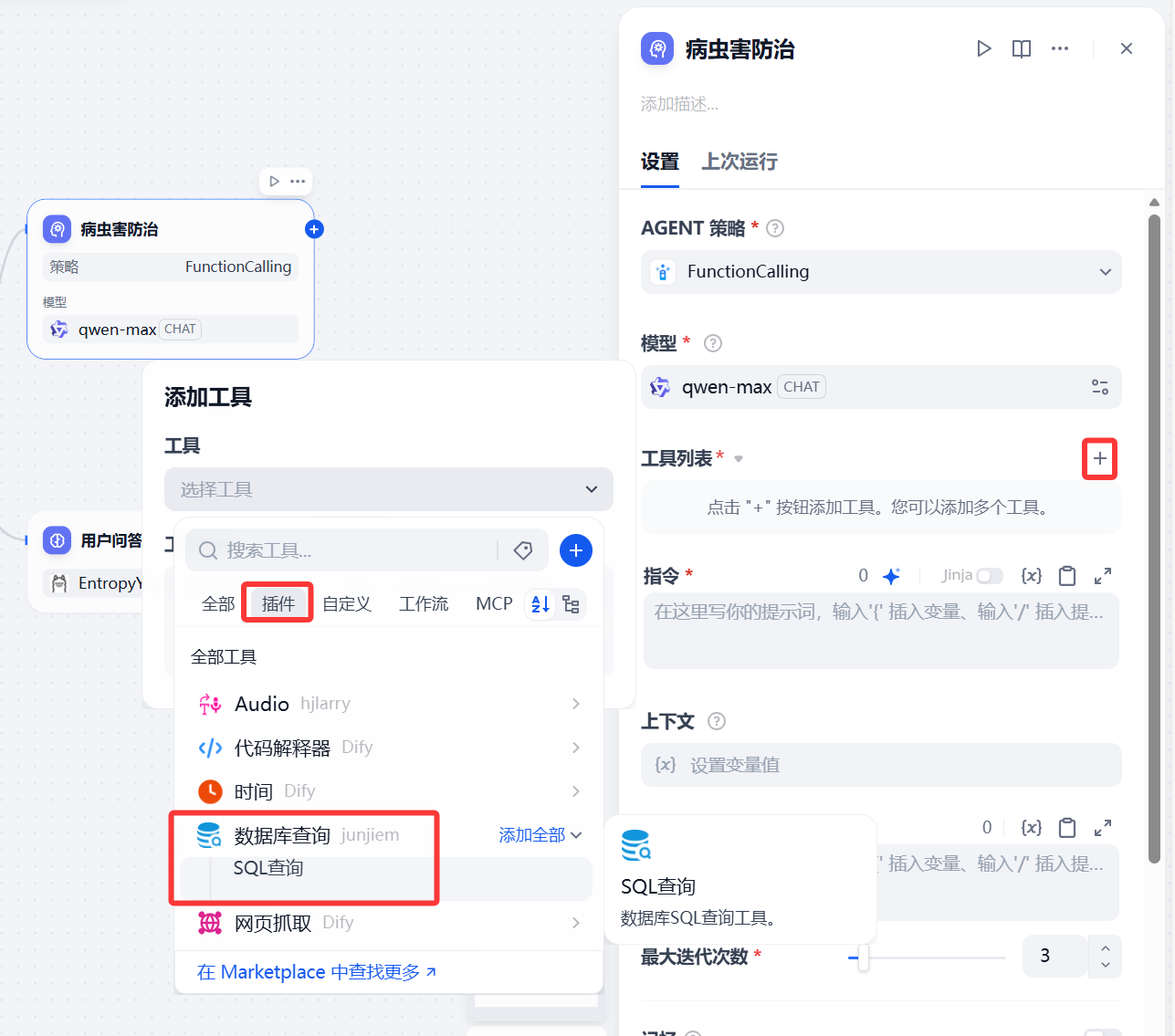
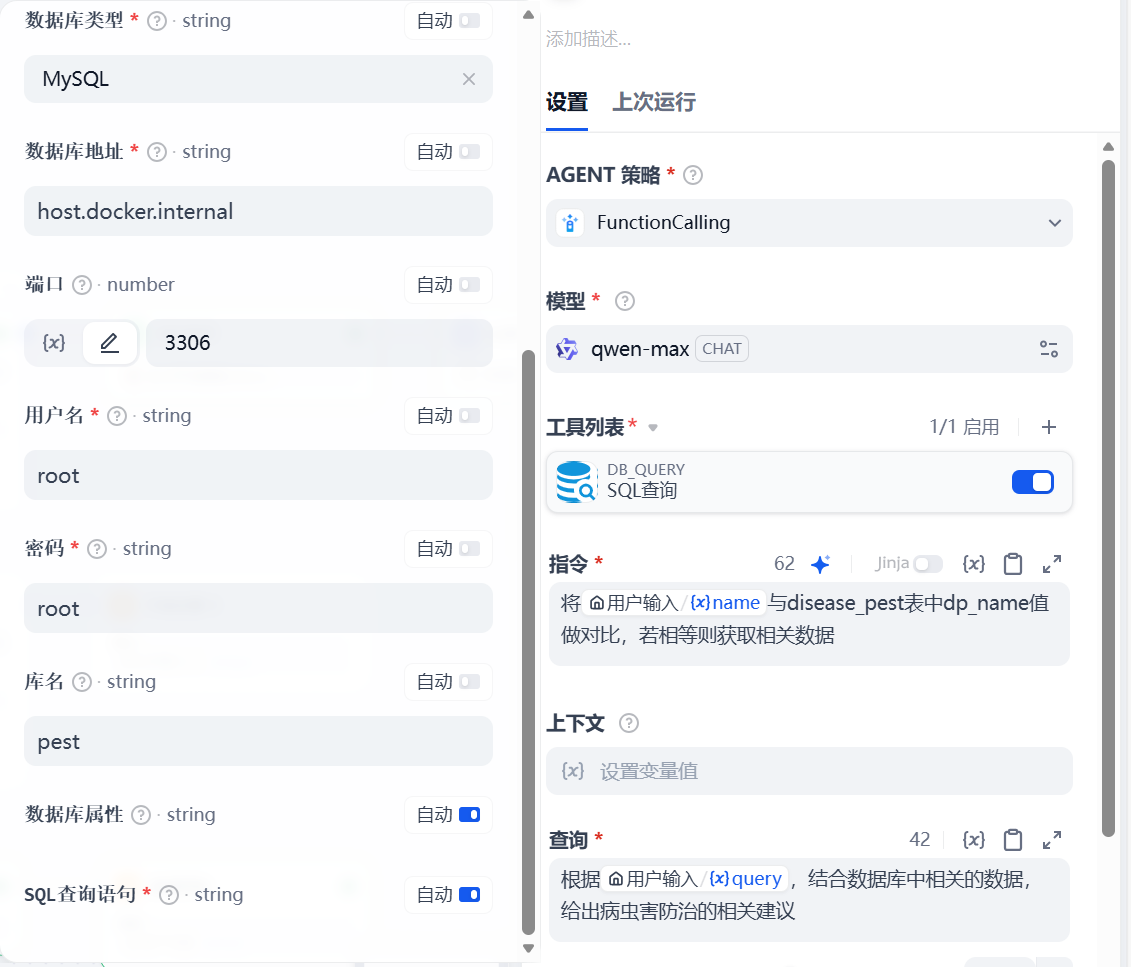
配置MySQL相关参数,填写指令(SQL查询时的指令)和查询(智能体的指令)
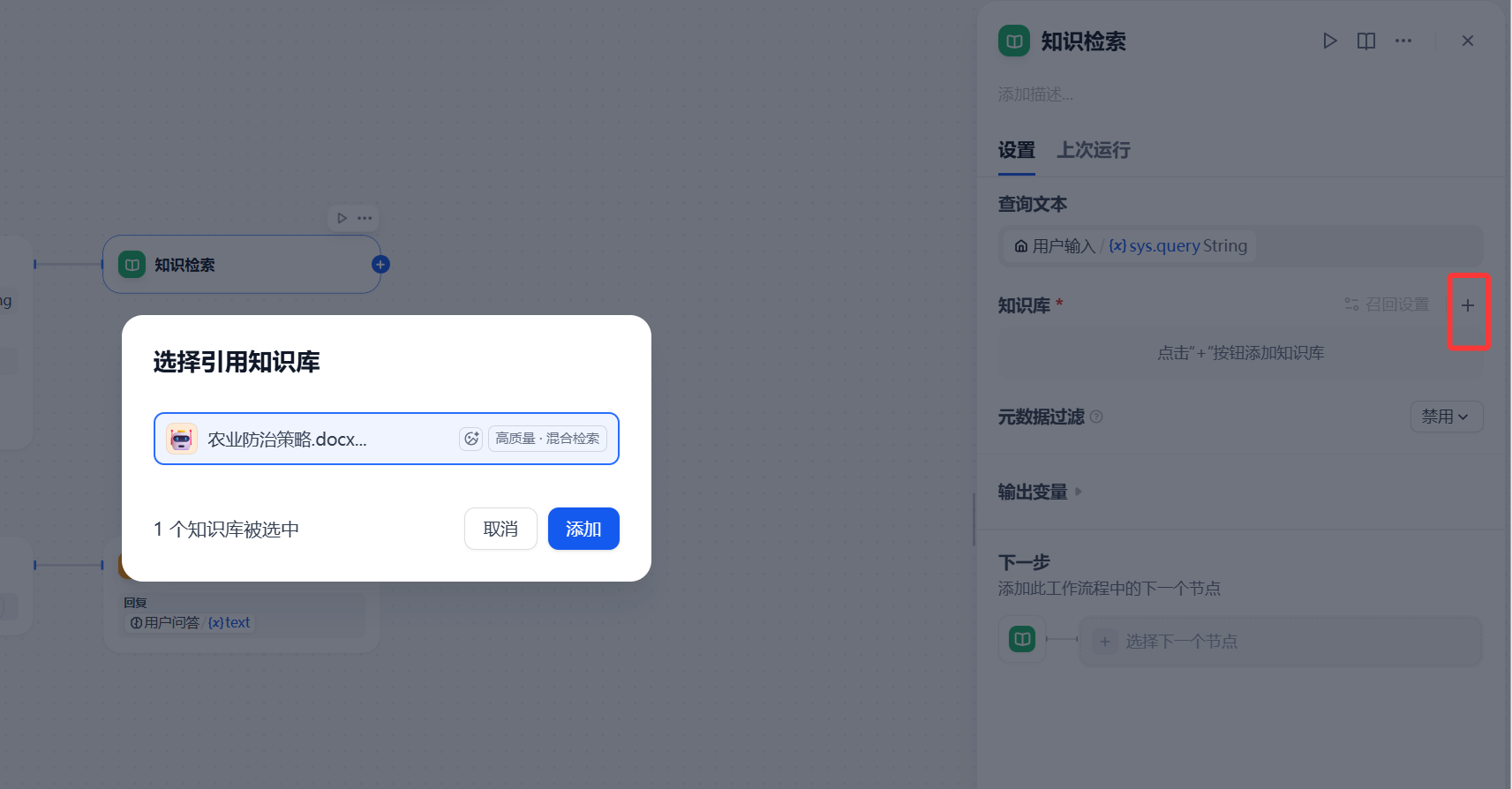
在Agent后添加 知识检索 节点,添加所需要的引用知识库
在 知识检索 后添加LLM,在上下文处,选择 知识检索的result
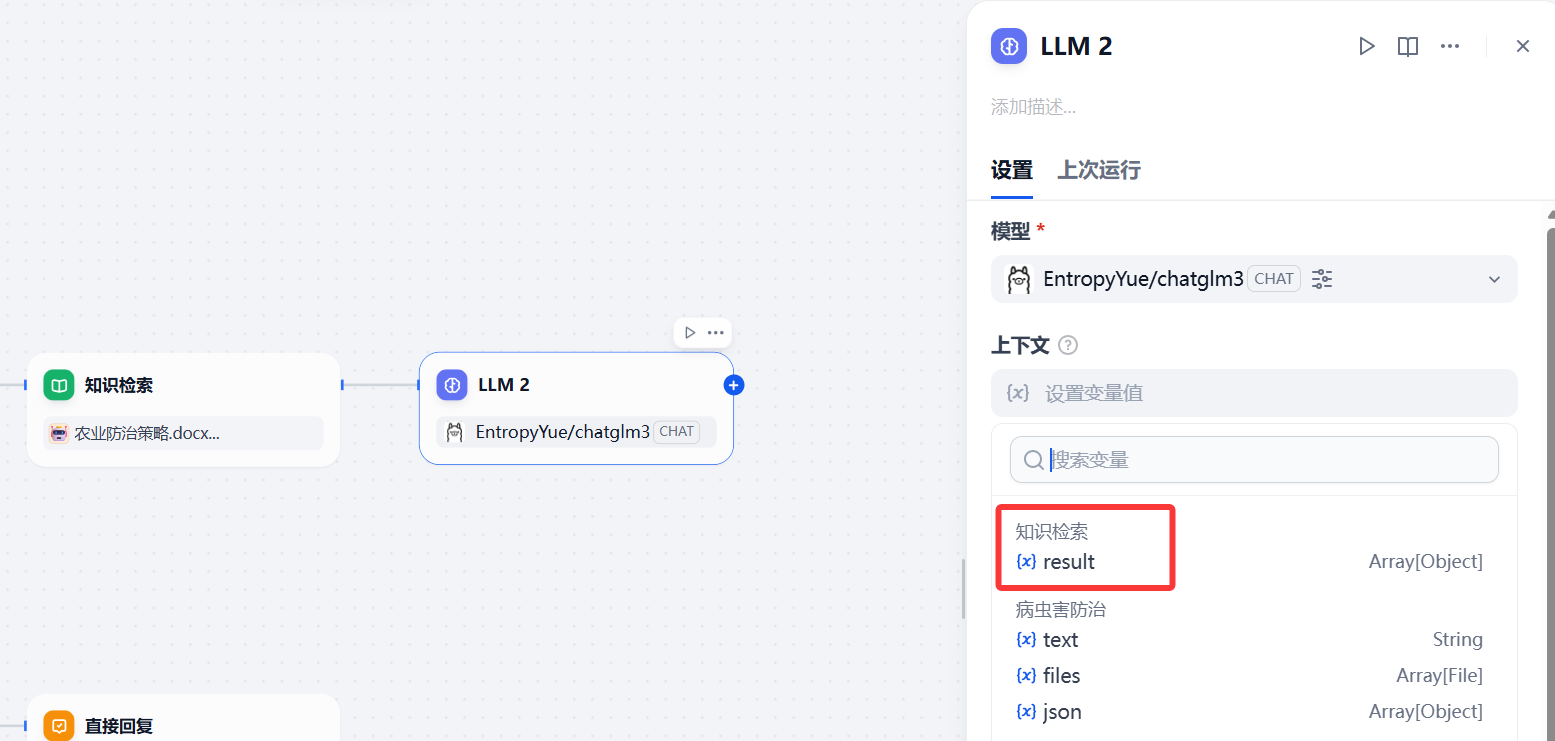
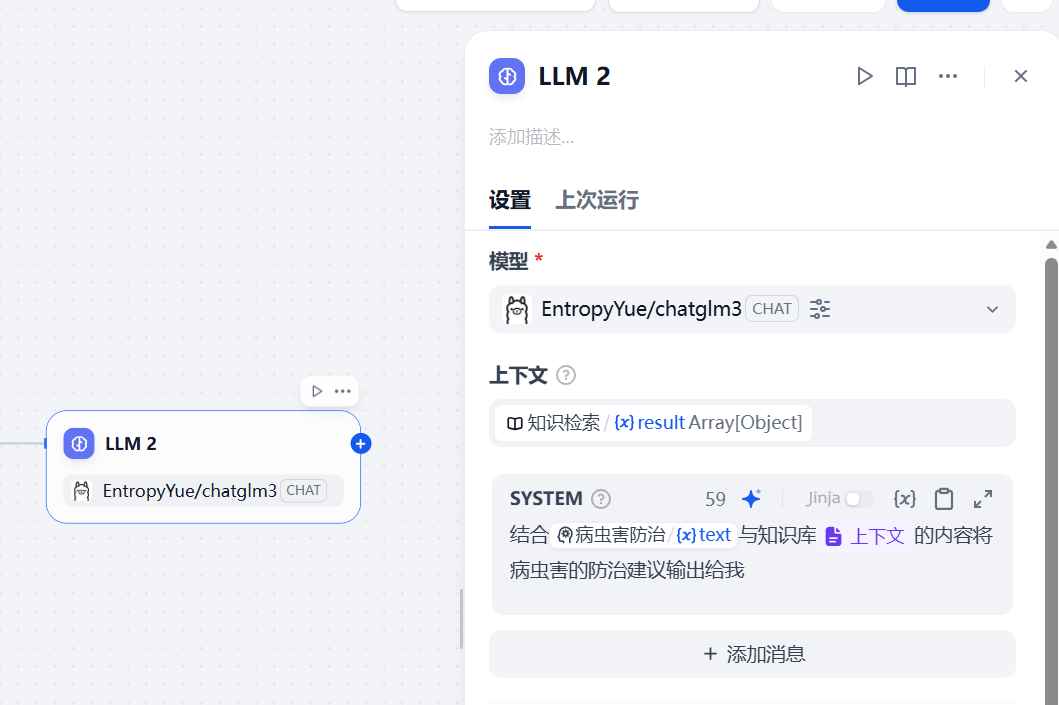
在LLM处,选择上下文后需要在SYSTEM中引用,在其中编写提示词,将Agent查询数据表的数据与Dify知识库的数据相结合
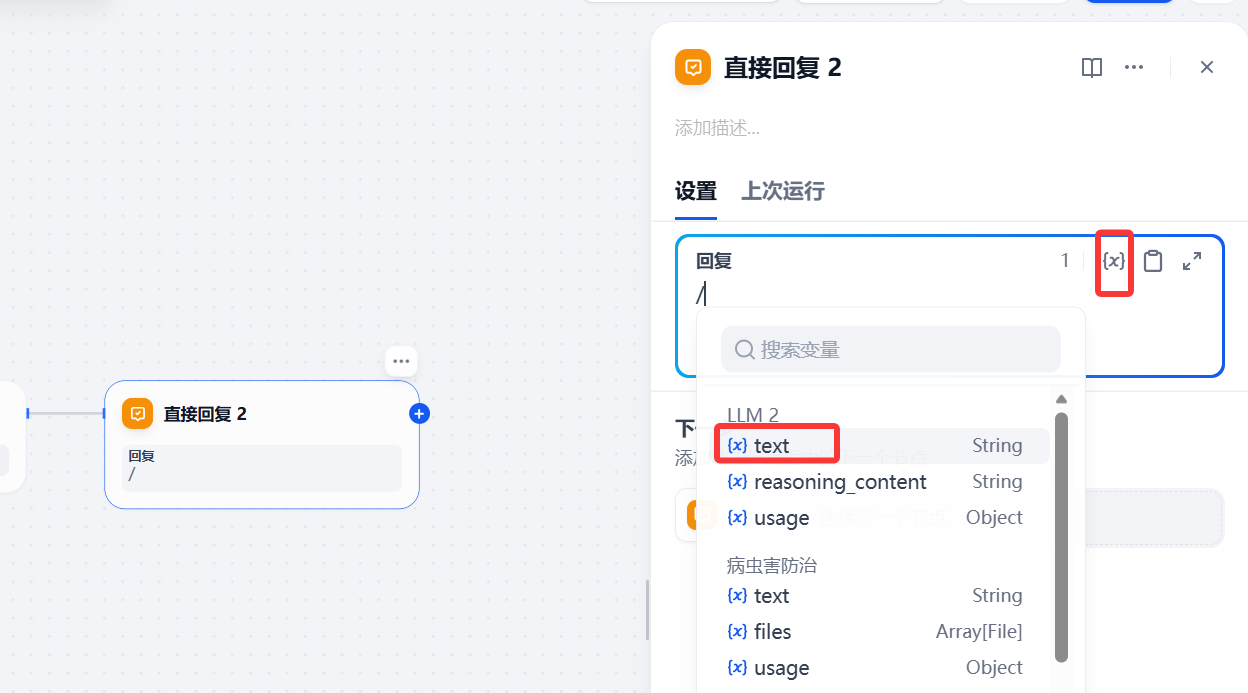
最后添加直接输出,在回复中点击 {x} ,选择LLM2的text即可
text为模型生成内容,reasoning_content为模型推理内容,usage为模型用量信息
2.3.3 农作物生长
在此部分重复上述操作即可,取决于是否需要查询本地数据库表内内容以及引用Dify知识库
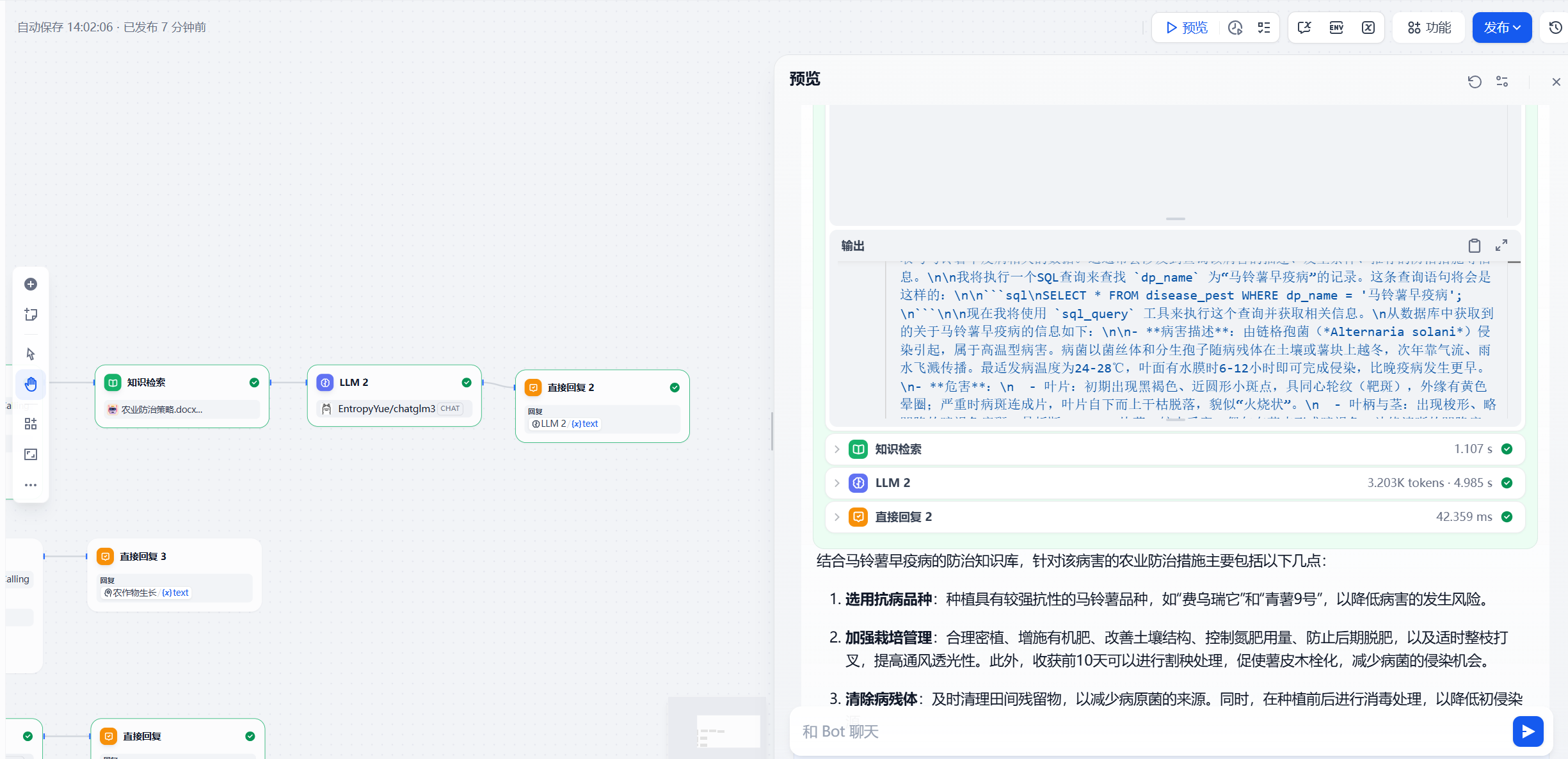
最终得到(注意:在编排好后记得点击右上角发布,发布更新)
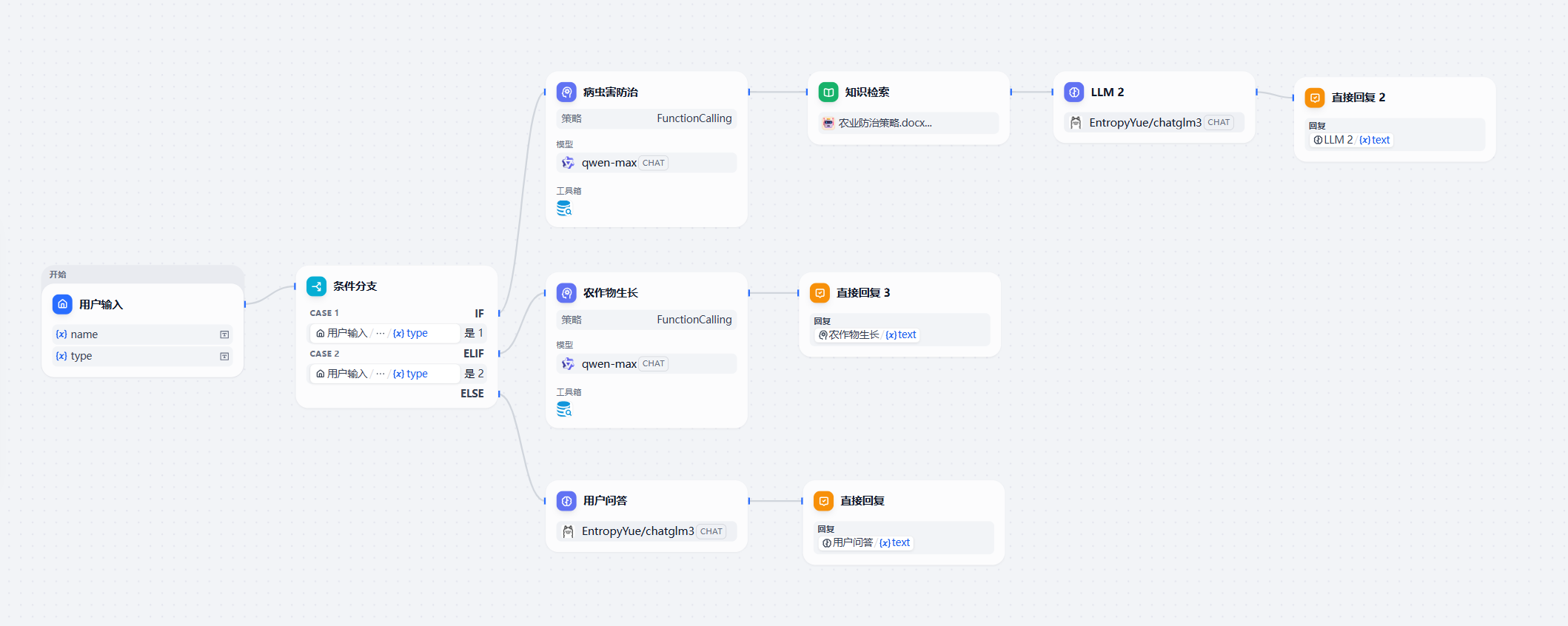
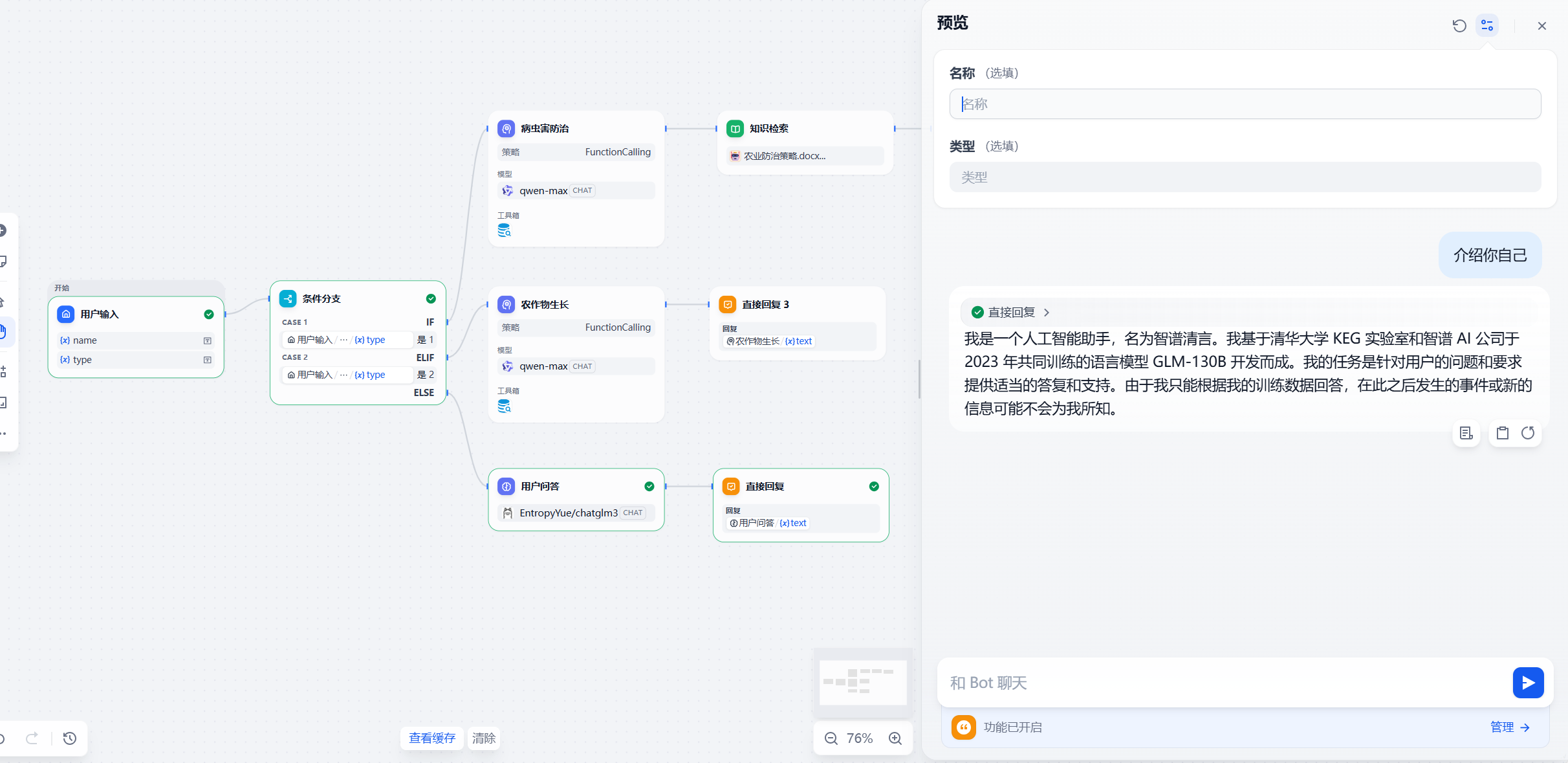
ChatFlow会根据用户输入的参数进行对应路径的流转,如图所示
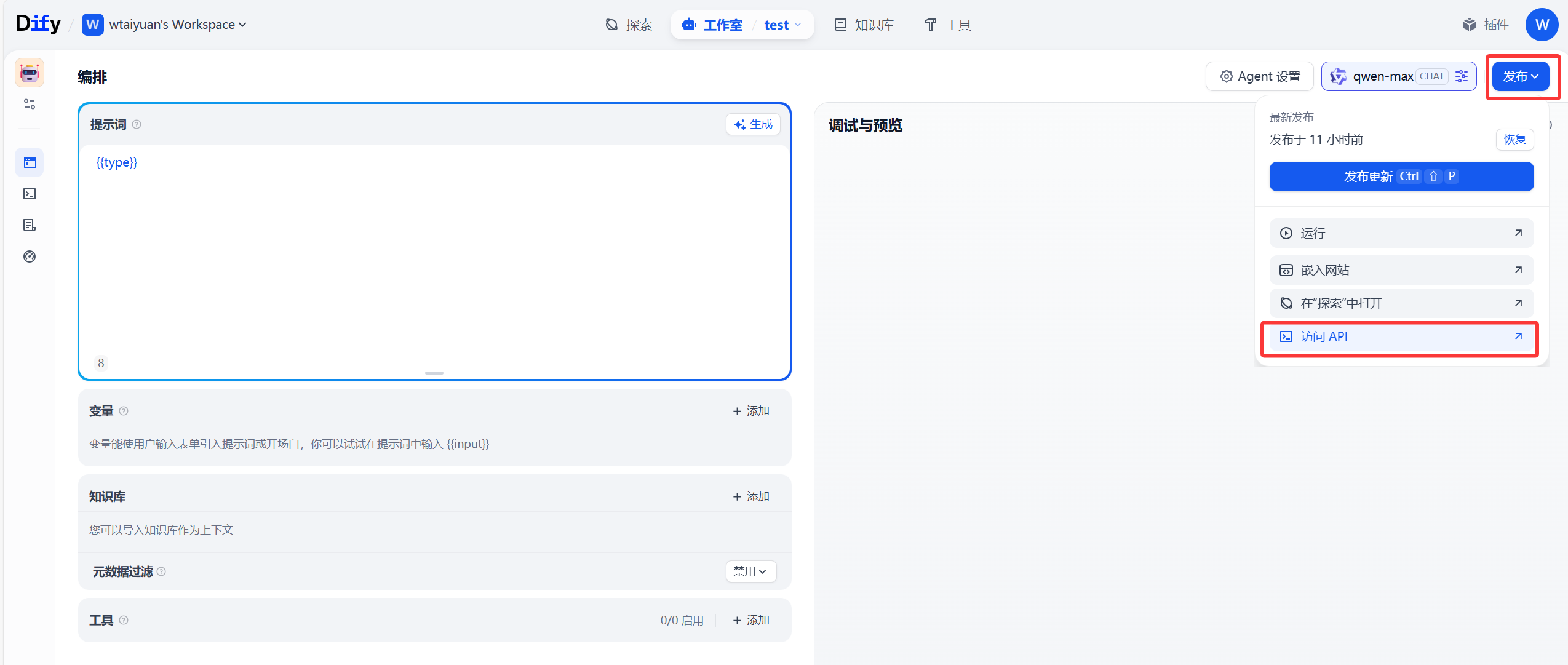
在智能体中选择右上角 发布,选择 访问API
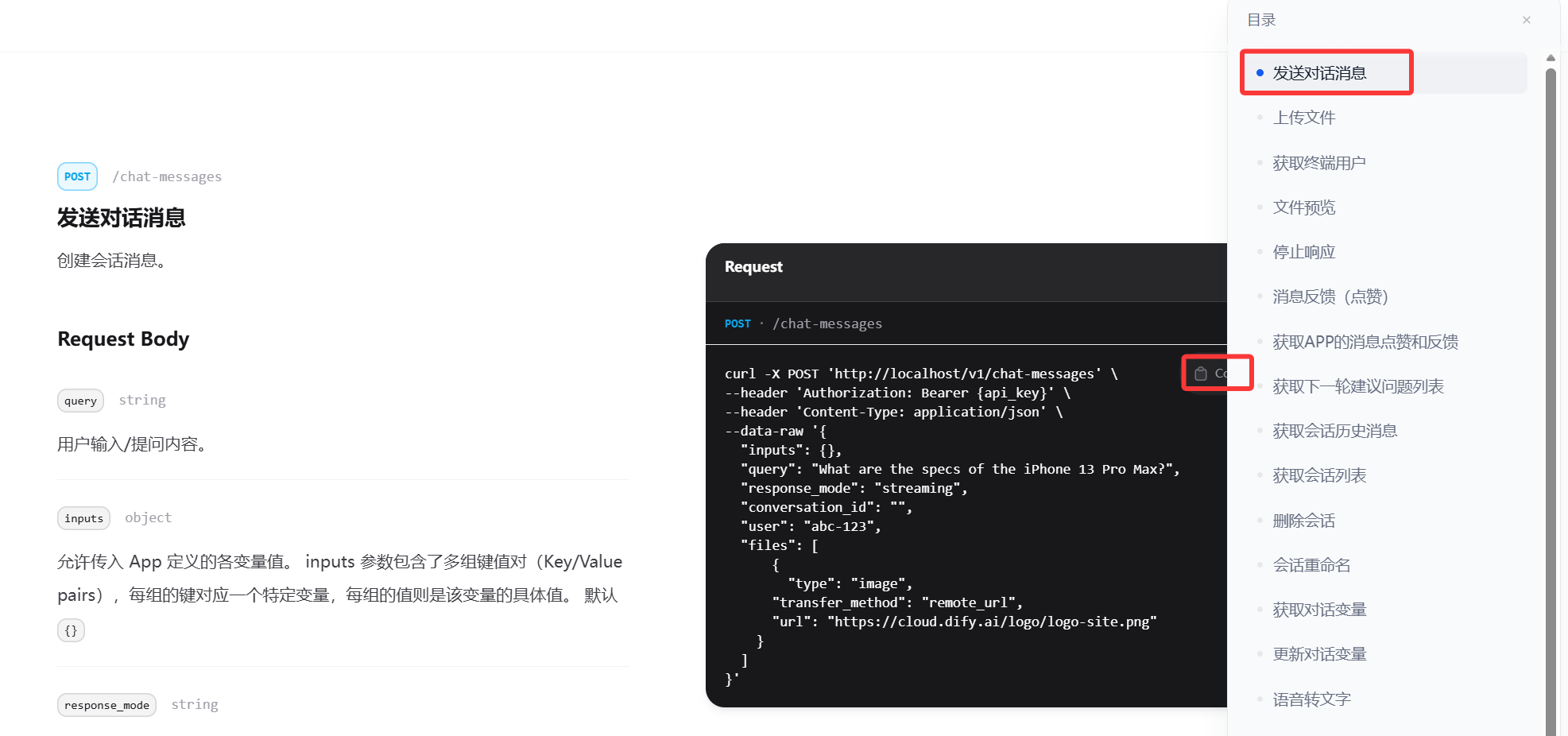
在目录中选择 发送对话消息,点击直接copy复制
这里博主使用Apifox进行演示操作,选择导入curl,将复制内容填入
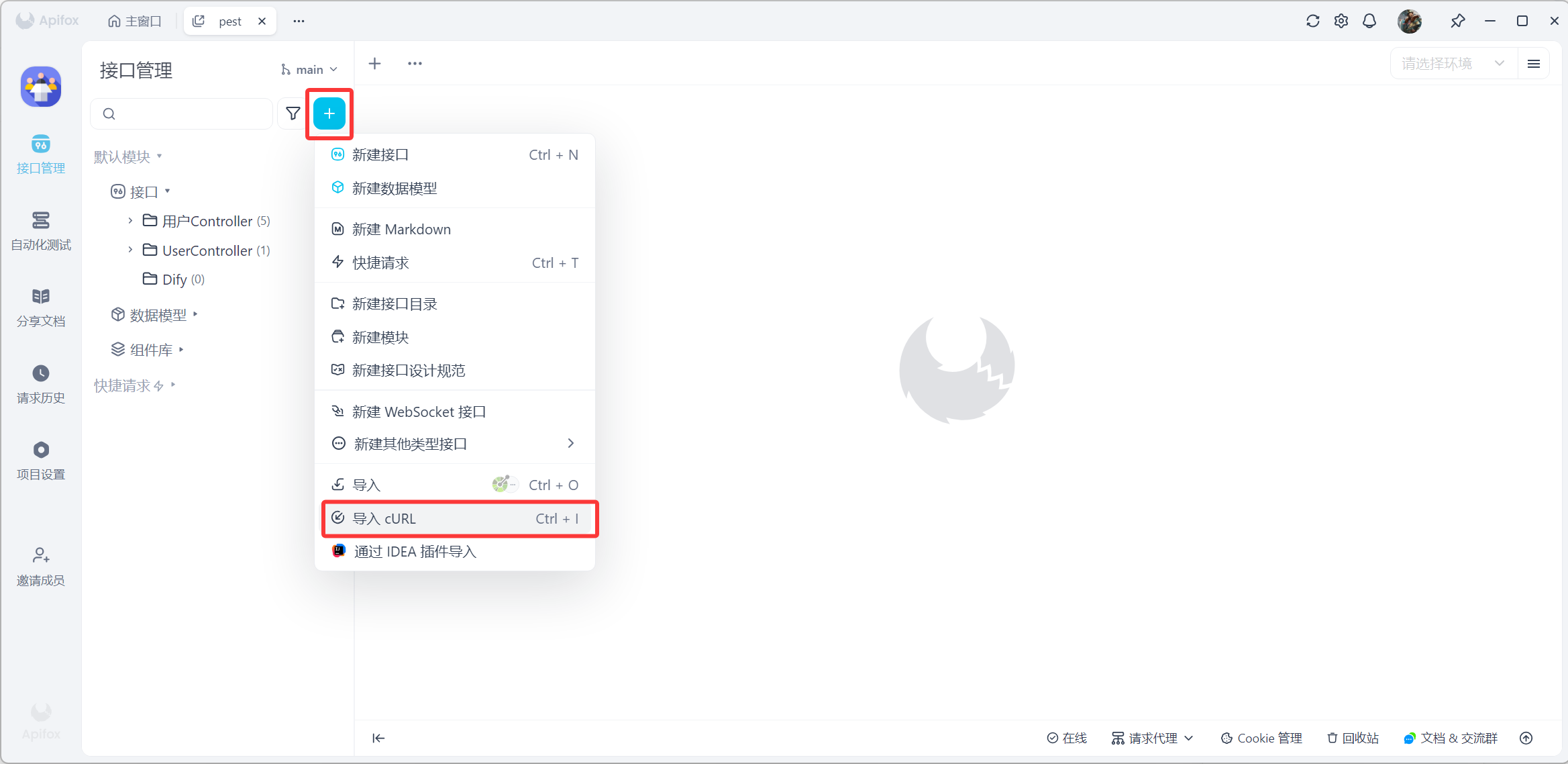
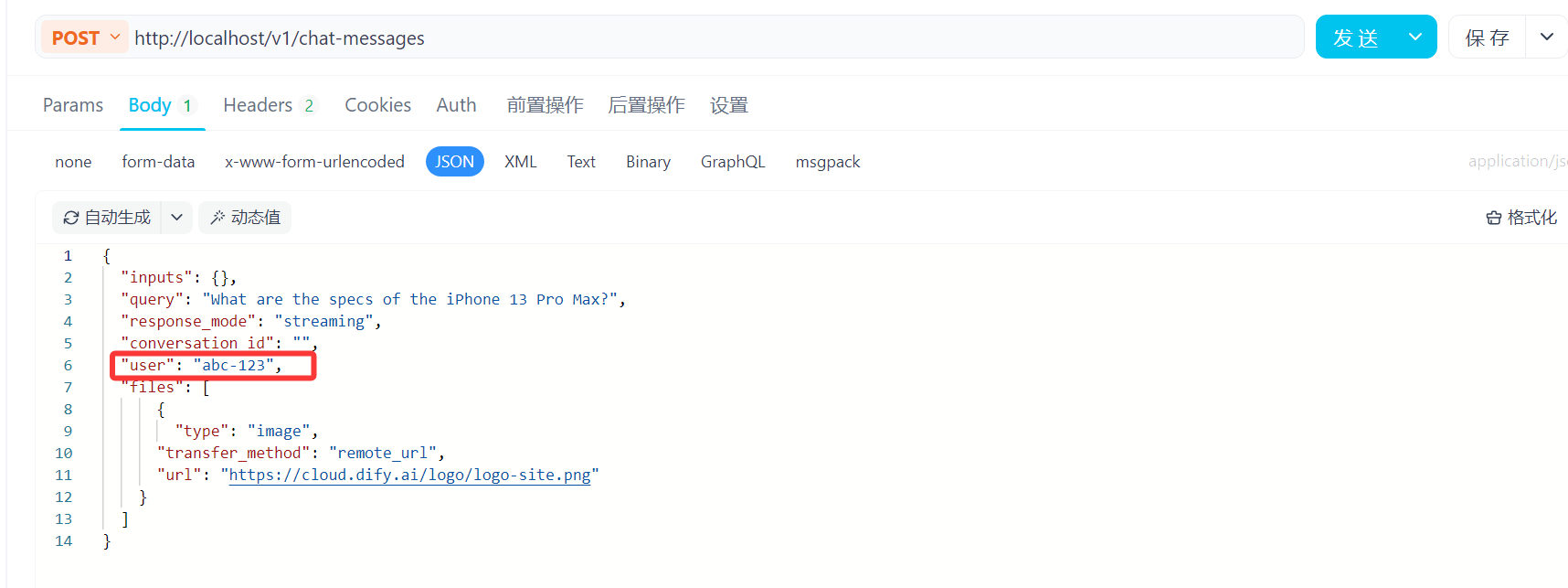
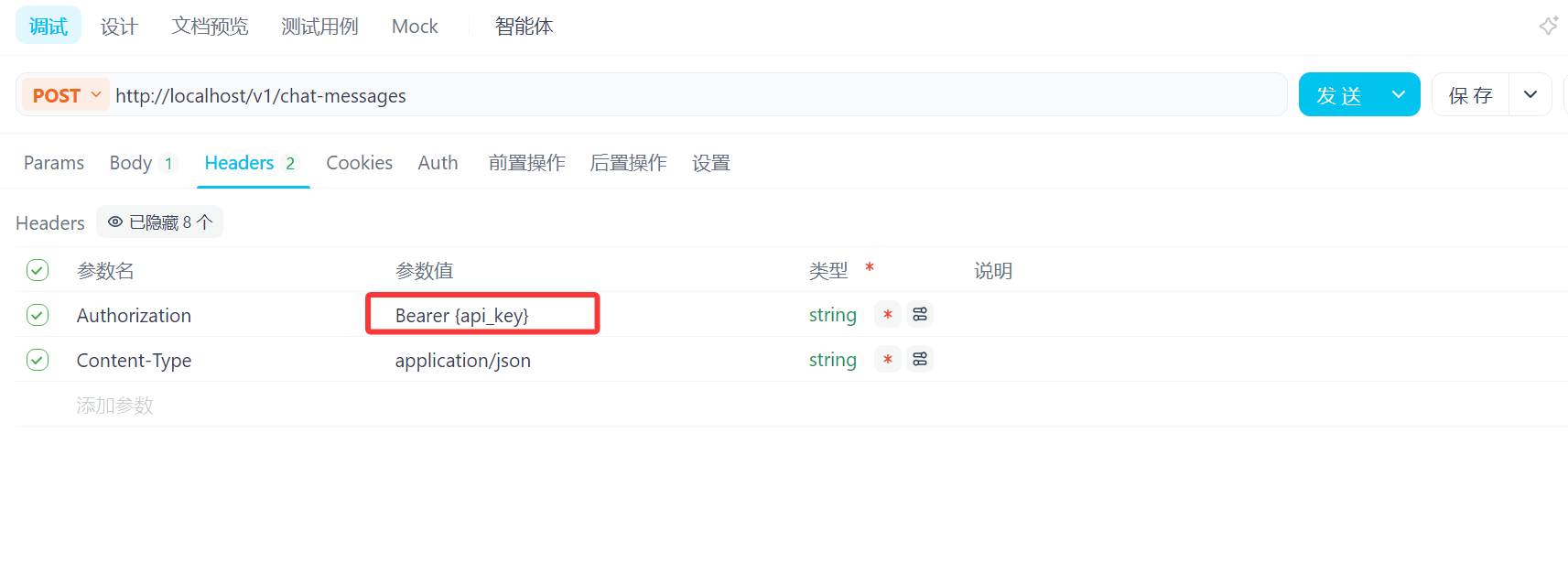
导入后对相关参数进行修改,在Body处将user改为用户名,在Headers处将Authorization中{api_key}值替换为当前密钥
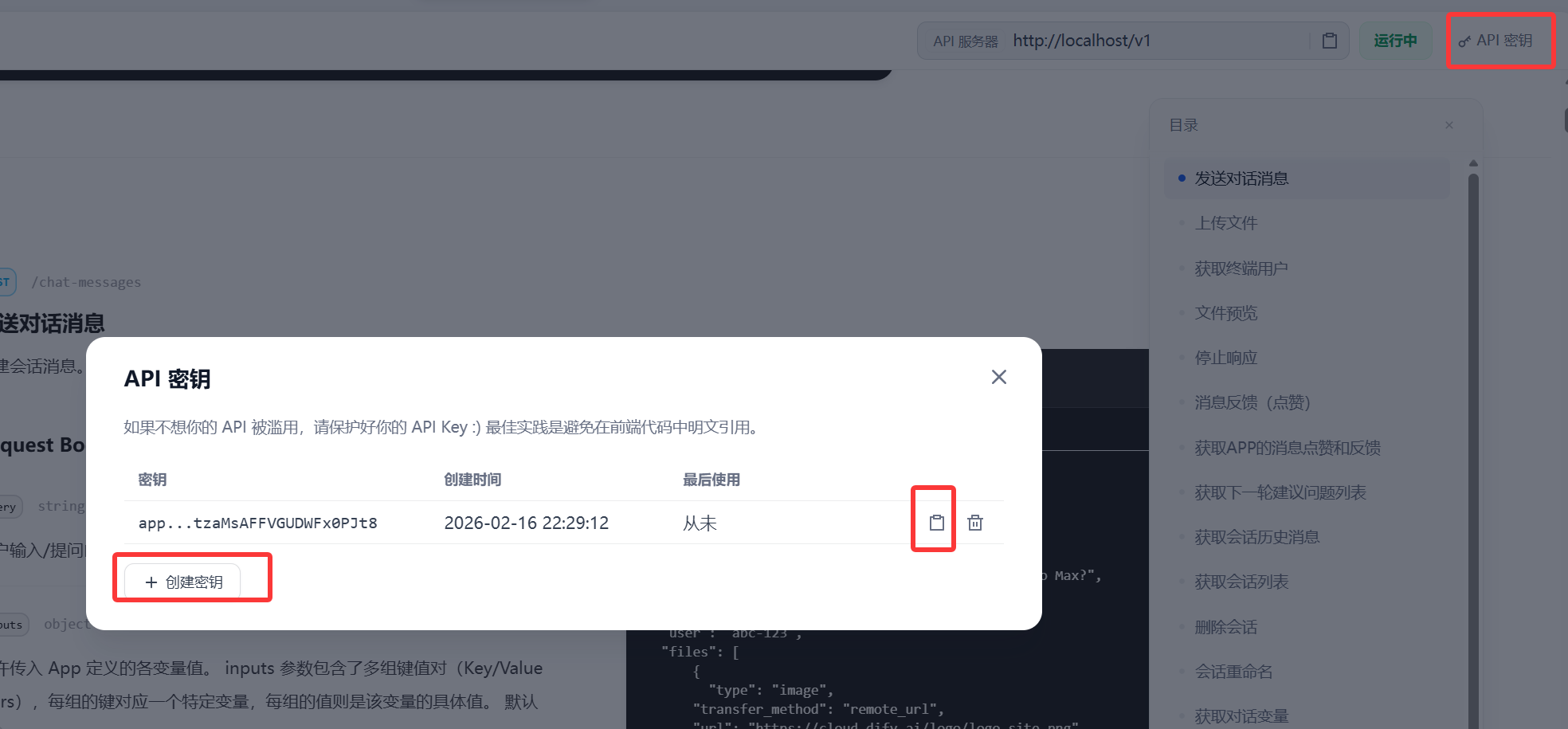
点击右上角 API密钥 》创建密钥 》复制
将相关参数修改后就能使用了,query为用户提问,效果如图
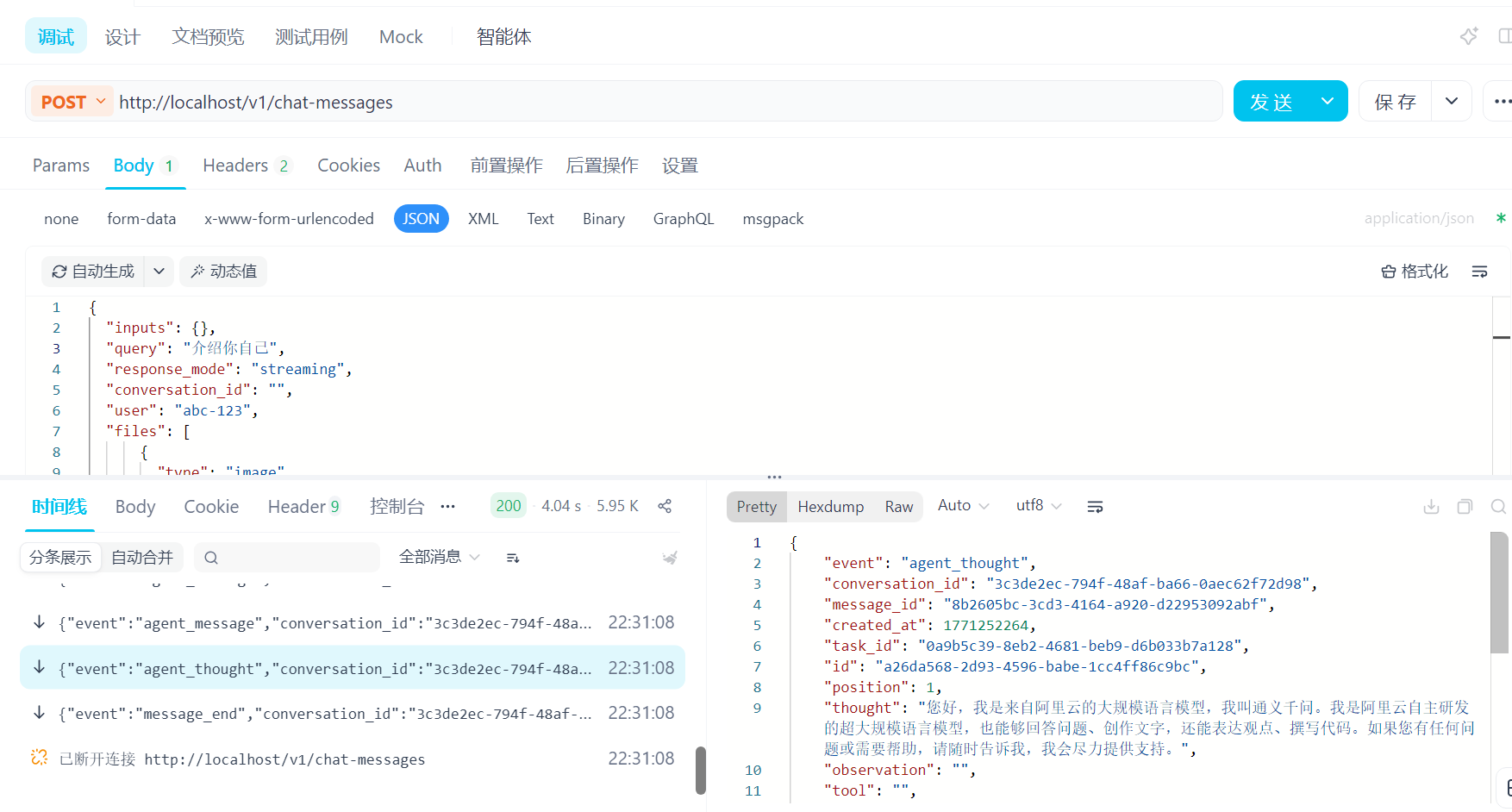
同上,点击右上角 》访问API 》选择 发送对话消息 》复制粘贴于Apifox中
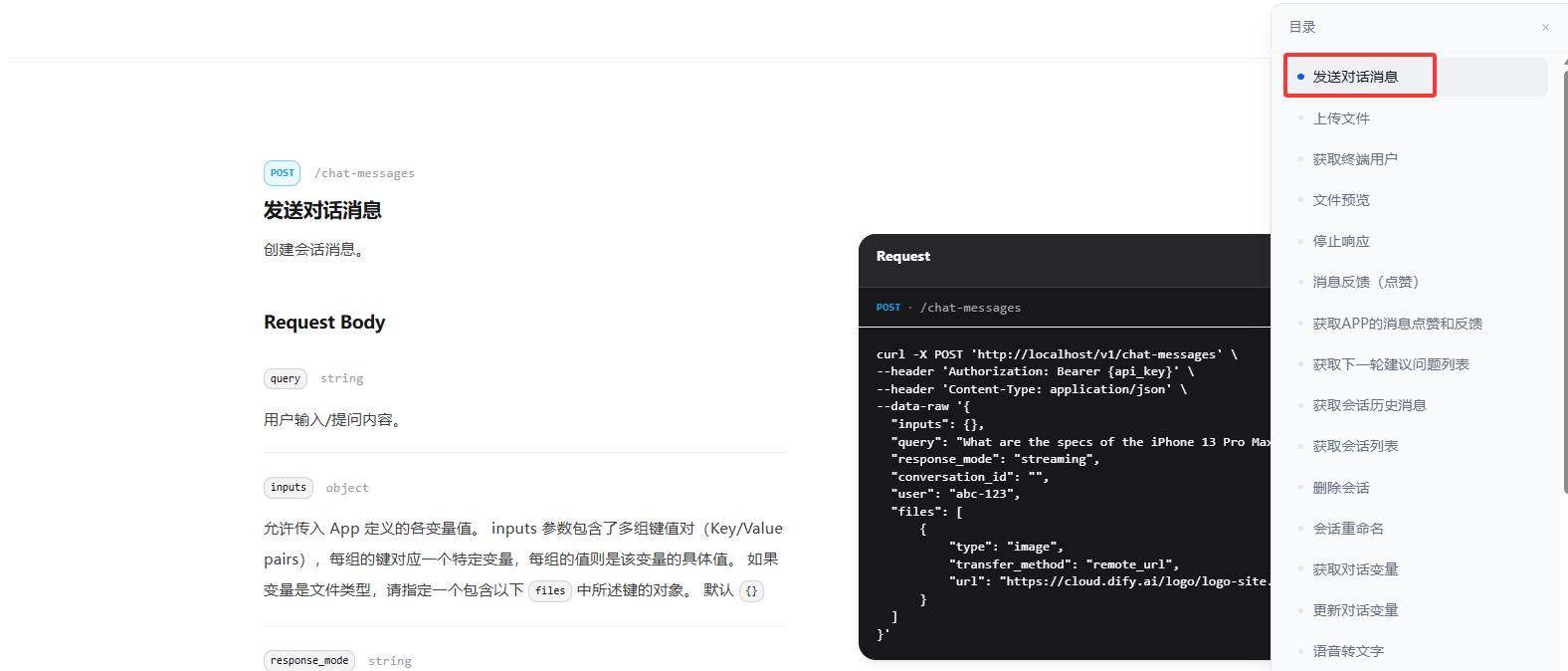
同样的,修改相关参数即可
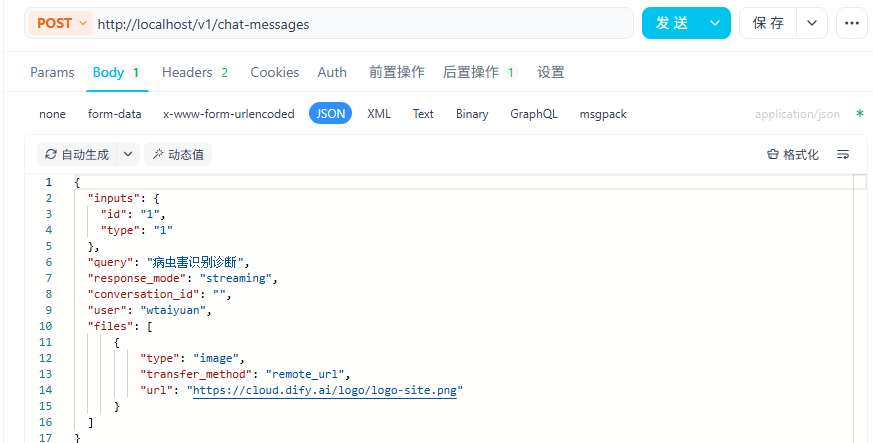
可以参考官网内容
但是官网内容粘贴后无法直接使用,缺少必要参数,博主也是浏览了其他帖子才API请求成功,现在给出完整参数。
首先配置密钥,知识库的密钥不在具体数据库内,而在首页进行选择
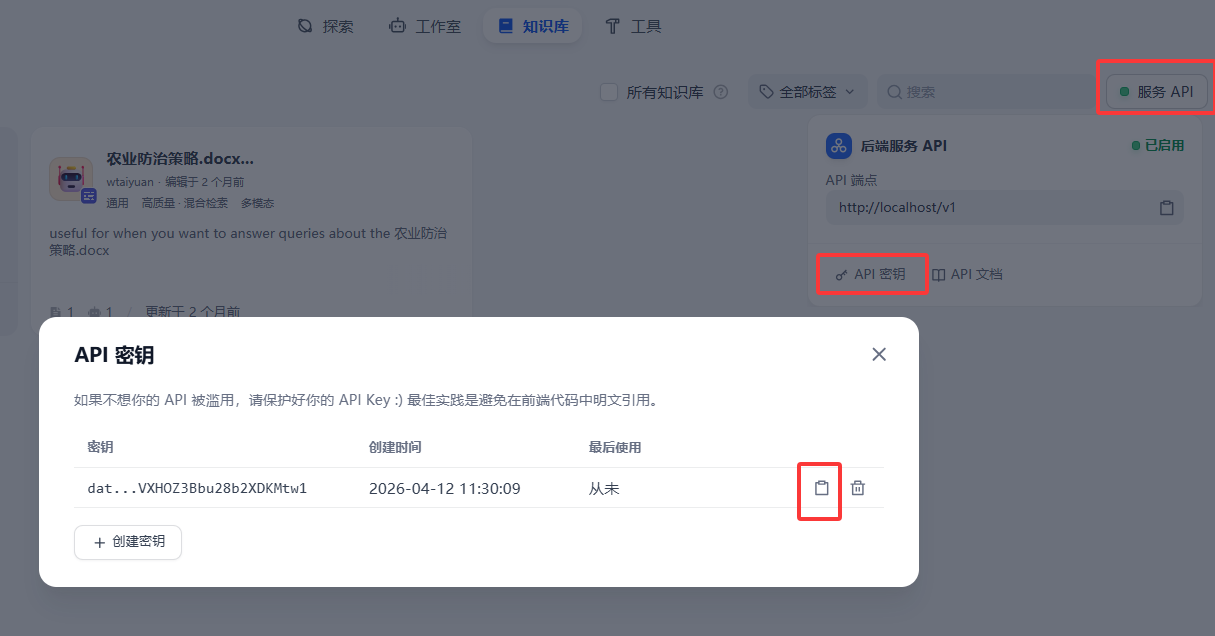
3.3.1 新增知识库
修改网址、密钥、模型参数后即可使用
curl –location –request POST ‘http://xxx/v1/datasets'; –header ’Authorization: Bearer xxx‘ –header ’Content-Type: application/json‘ –data-raw ’{ “name”: “ ”, “description”: “ ”, “indexing_technique”: “high_quality”, “permission”: “all_team_members”, “provider”: “vendor”, “external_knowledge_api_id”: “”, “external_knowledge_id”: “”, “embedding_model”: “multimodal-embedding-v1”, “embedding_model_provider”: “tongyi”, “retrieval_model”: {"search_method": "hybrid_search", "reranking_enable": true, "reranking_mode": "reranking_model", "reranking_model": { "reranking_provider_name": "tongyi", "reranking_model_name": "gte-rerank-v2" }, "top_k": 3, "score_threshold_enabled": true, "score_threshold": 0.5, "weights": {"model_name": 0.5} } }‘
注意在新增后,记住新增知识库的id,因为在Dify平台是看不见知识库id的。也可以选择使用 查询知识库列表 来查看每个知识库的详细信息,其中就包含id
3.3.2 删除知识库
curl –location –request DELETE ’http://xxx/v1/datasets/知识库id'; –header ‘Authorization: Bearer xxx’
3.3.3 更新知识库
curl –location –request PATCH ‘http://xxx/v1/datasets/知识库id'; –header ’Authorization: Bearer xxx‘ –header ’Content-Type: application/json‘ –data-raw ’{ “name”: “ ”, “description”: “ ”, “indexing_technique”: “high_quality”, “permission”: “all_team_members”, “embedding_model_provider”: “tongyi”, “embedding_model”: “multimodal-embedding-v1”, “retrieval_model”: {"search_method": "hybrid_search", "reranking_enable": true, "reranking_mode": "reranking_model", "reranking_model": { "reranking_provider_name": "tongyi", "reranking_model_name": "gte-rerank-v2" }, "top_k": 3, "score_threshold_enabled": true, "score_threshold": 0.5, "weights": {"model_name": 0.5} }, “partial_member_list”: [
] }‘
3.3.4 查询知识库列表
curl –location –request GET ’http://xxx/v1/datasets?page=1&limit=20'; –header ‘Authorization: Bearer xxx’
3.3.5 新增文件
在对应数据库下新增文件
curl –location –request POST ‘http://xxx/v1/datasets/知识库id/document/create-by-file'; –header ’Authorization: Bearer dataset-hzKxz6vnM21UqRQtL0FLppiu‘ –form ’data=“{"name": "测试文档", "indexing_technique": "high_quality", "doc_form": "hierarchical_model", "process_rule": { "mode": "hierarchical", "rules": { "pre_processing_rules": [ { "id": "remove_extra_spaces", "enabled": true } ], "segmentation": { "separator": "\n\n", "max_tokens": 2000 }, "parent_mode": "paragraph", "subchunk_segmentation": { "separator": "\n", "max_tokens": 200 } } }, "retrieval_method": { "search_method": "hybrid_search", "hybrid_search": { "semantic_weight": 0.7, "full_text_weight": 0.3 }, "top_k": 3 } }”‘ –form ’file=@“”‘

注意将file的类型改为file
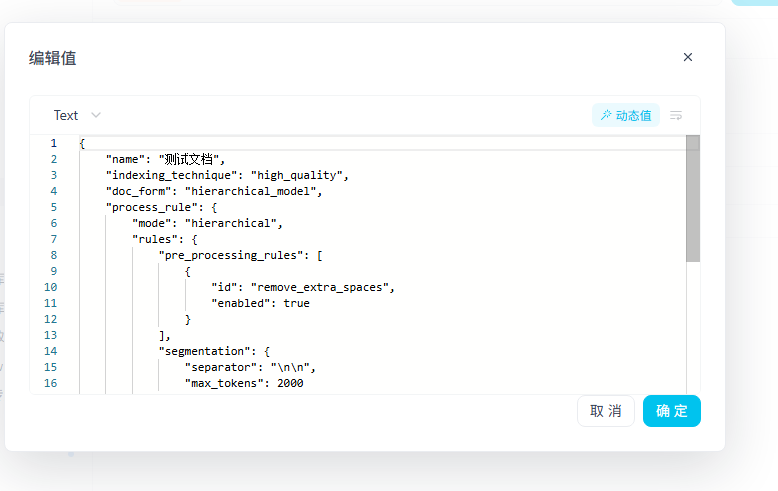
3.3.6 修改文件
curl –location –request POST ’https://xxx/v1/datasets/知识库id/documents/文件id/update-by-file'; –header ‘Authorization: Bearer xxx’ –form ‘data=“{ ”doc_form“: ”hierarchical_model“, ”process_rule“: {"mode": "hierarchical", "rules": { "pre_processing_rules": [ { "id": "remove_extra_spaces", "enabled": true } ], "segmentation": { "separator": "\n\n", "max_tokens": 2000 }, "parent_mode": "paragraph", "subchunk_segmentation": { "separator": "\n", "max_tokens": 200 } } } }”’ –form ‘file=@“D:\Desktop\附件5安全责任书(1).docx”’
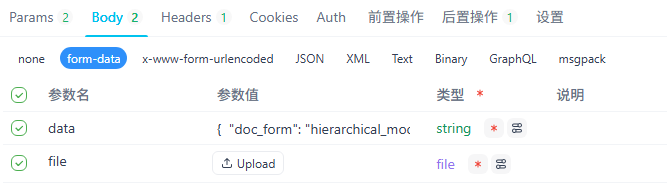
3.3.7 删除文件
同样需要知识库和文件的id
curl –location –request DELETE ‘http://xxx/v1/datasets/知识库id/documents/文件id'; –header ’Authorization: Bearer xxx‘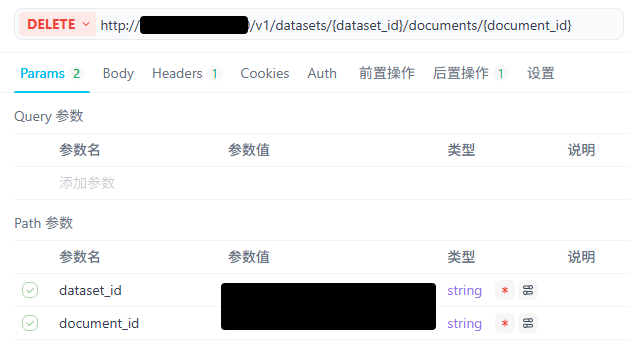
3.3.8 获取知识库的文档列表
curl –location –request GET ’http://xxx/v1/datasets/知识库id/documents?page=1&limit=20'; –header ‘Authorization: Bearer xxx’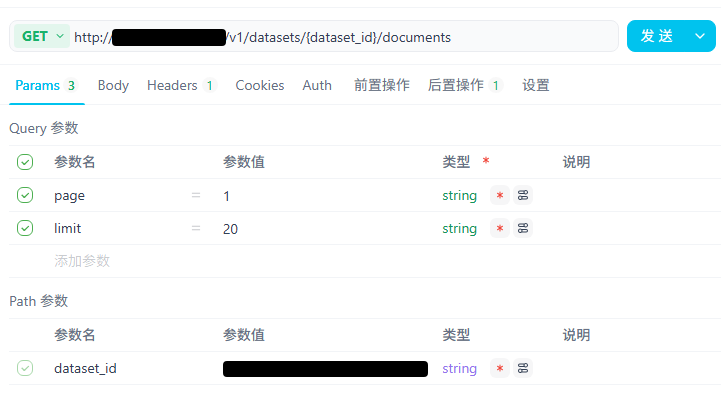
自此Dify的本地部署、工作流编排和API基础使用就已经介绍完毕,后续发现Dify的其余新用法后进行更新
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/259534.html