
把智能体调度架构划分成四层:划分(Prompt 层、Context 层、Tool 层、Agent 层)在2025-2026年的Agent工程实践中是非常主流且准确的描述。
它本质上是对Agent "感知-推理-行动-协作" 四个核心智能特征的工程化映射,逻辑清晰、层次分明。
这个划分本质上是对Agentic Workflow的解耦:
- Prompt → 结构化输入输出与模版化生成,控制模型"怎么想"(behavior shaping)
- Context →动态上下窗口与RAG检索增强,提供"知道什么"(knowledge injection)
- Tool → MCP协议,让模型"能做什么"(action execution)
- Agent →规划、记忆以及多智能体,实现"整体怎么做"(orchestration & planning)
它比早期ReAct(单层Tool+Reason)或简单LangChain Agent更工程化,特别适合多轮、长任务、RAG+Tool混合场景。
一句话总结:
ReAct = 显式推理(Reasoning) + 工具调用(Acting)的交替循环
即:
Thought → Action → Observation → 循环
核心代码:
用最简单的方式,用伪代码 / 简化的 Python 风格表示 Thought → Action → Observation 的循环结构:
# 极简版 ReAct 循环(伪代码风格)
while not task_is_done():
# 1. 思考(Reasoning) thought = llm.generate_thought( current_state = observation_history + current_observation, task = original_task, available_tools = tool_list ) print("Thought:", thought) # 2. 决定要做什么(Action) action = llm.decide_action( thought=thought, allowed_format="use_tool" or "give_final_answer" ) if action.type == "Final Answer": return action.content # 任务结束,返回最终答案 # 3. 执行行动(调用工具) print("Action:", action) observation = execute_tool(action.tool_name, action.parameters) print("Observation:", observation) # 4. 把新观察加进历史,进入下一轮 observation_history.append({ "thought": thought, "action": action, "observation": observation })
总结:ReAct 循环的本质就这四步反复执行
Thought → Action → Observation → Thought → Action → …
ReAct 的循环本质就是:
- 先思考(Thought)→ 产生下一步计划
- 再决定行动(Action)→ 告诉系统我要调用哪个工具
- 系统执行后返回结果(Observation)→ 反馈给模型
- 回到第1步,用新的信息继续思考......
1、本质区别
- CoT:只"思考"
- ReAct:边"思考"边"行动"
Few-shot CoT = Few-shot Prompting + Chain-of-Thought
• Few-shot:在prompt 里给模型看 2~8 个「输入-完整推理过程-答案」的示范样例
• Chain-of-Thought:让模型学会输出中间推理步骤(step by step),而不是直接跳到最终答案
1、定义
多智能体协作主要有两种模式:
- 一是水平式,通过"并行专家模式",通过多Agent同时处理同类任务,最后通过投票等方式获得结果,提高吞吐和鲁棒性,适合RAG、多候选生成等场景。
- 二是垂直式,垂直式协作是"流水线分工模式",通过多Agent分阶段完成复杂任务,适合长链路推理和Agentic Workflow。
真实场景中,绝大多数系统不是单一模式,而是:
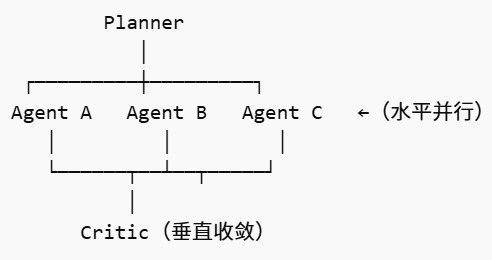
先垂直拆解 → 再水平扩展 → 最后垂直收敛
2、伪代码模块
区别只是:
- Planner:只做任务拆解(偏 Reasoning)
- Worker:执行任务(Reason + Tool)
- Critic:评估/融合结果(Reason为主)
完整伪代码:
from concurrent.futures import ThreadPoolExecutor
=========================================
通用 ReAct Agent(核心抽象)
=========================================
class ReActAgent:
def __init__(self, llm, tools=None, role="worker", max_steps=5): self.llm = llm self.tools = tools or {} self.role = role self.max_steps = max_steps def run(self, task, context=""): history = [] observation = context for step in range(self.max_steps): prompt = self.build_prompt(task, history, observation) response = self.llm(prompt) # 1️⃣ 判断是否结束 if "Final Answer:" in response: return self.extract_final(response) # 2️⃣ 解析 Thought / Action thought = self.extract_thought(response) action = self.extract_action(response) # 3️⃣ 执行工具(如果有) if action and action["name"] in self.tools: observation = self.tools[action["name"]](action["args"]) else: observation = "No tool used" # 4️⃣ 记录轨迹 history.append({ "thought": thought, "action": action, "observation": observation }) return "Max steps reached" # ===== 以下为简化函数 ===== def build_prompt(self, task, history, observation): return f"""
Role: {self.role}
Task: {task} History: {history} Observation: {observation}
Follow ReAct format: Thought: Action: Observation: Final Answer: """
def extract_thought(self, text): ... def extract_action(self, text): ... def extract_final(self, text): ...
=========================================
1️⃣ 垂直拆解:Planner Agent
=========================================
class PlannerAgent(ReActAgent):
def run(self, task): prompt = f"""
You are a planner.
Break the task into independent subtasks.
Task: {task}
Return JSON list: ["subtask1", "subtask2", …] """
response = self.llm(prompt) return self.parse_subtasks(response) def parse_subtasks(self, text): # 假设返回 JSON import json return json.loads(text)
=========================================
2️⃣ 水平扩展:并行 Worker Agents
=========================================
def run_parallel_workers(subtasks, llm, tools):
def run_single(subtask): agent = ReActAgent(llm, tools, role="worker") return agent.run(subtask) results = [] # 线程池模拟并行(实际可用 Ray / Async) with ThreadPoolExecutor(max_workers=5) as executor: futures = [executor.submit(run_single, t) for t in subtasks] for f in futures: results.append(f.result()) return results
=========================================
3️⃣ 垂直收敛:Critic / Aggregator Agent
=========================================
class CriticAgent(ReActAgent):
def run(self, task, results): prompt = f"""
You are a critic and aggregator.
Original Task: {task}
Candidate Results: {results}
Please:
- Evaluate correctness
- Merge best parts
- Give final answer
Return: Final Answer: """
response = self.llm(prompt) return self.extract_final(response)
=========================================
4️⃣ 主调度器(核心:混合架构)
=========================================
class MultiAgentOrchestrator:
def __init__(self, llm, tools): self.llm = llm self.tools = tools def run(self, task): # ===== Step 1:垂直拆解 ===== planner = PlannerAgent(self.llm) subtasks = planner.run(task) print("Subtasks:", subtasks) # ===== Step 2:水平扩展 ===== results = run_parallel_workers(subtasks, self.llm, self.tools) print("Parallel Results:", results) # ===== Step 3:垂直收敛 ===== critic = CriticAgent(self.llm) final_answer = critic.run(task, results) return final_answer
=========================================
使用示例
=========================================
if name == "main":
llm = lambda prompt: call_llm_api(prompt) # 伪函数 tools = { "search": lambda q: f"search result for {q}", "calc": lambda x: str(eval(x)) } orchestrator = MultiAgentOrchestrator(llm, tools) task = "分析特斯拉股价影响因素并给出投资建议" result = orchestrator.run(task) print("Final Answer:", result)
首先通过 Planner Agent 做任务拆解(垂直拆解),然后将子任务分发给多个 Worker Agent 并行执行(水平扩展),每个 Worker 内部仍然是 ReAct 循环(Thought-Action-Observation),最后通过 Critic Agent 对结果进行评估与融合(垂直收敛)。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/259328.html