
Agent之HarnessEngineering:OpenAI 如何在 agent-first 时代从空 git 仓库出发,以 Codex 为核心、以仓库知识为系统记录、以可读性和架构约束为边界、以高吞吐反馈回路和持续垃圾回收为机制,构建一个几乎零人工手写代码、可端到端驱动开发、测试、评审、修复与发布的内部软件工程体系
导读:这篇文章的核心不是“让 AI 帮忙写代码”,而是“把整个软件工程系统改造成适合代理工作的环境”:用仓库知识、架构约束、可观测性、自动 review 和持续清理,把 Codex 从代码生成器升级成端到端的工程执行者;而人类则把精力集中到环境设计、边界定义和判断升级上。
核心讲的是:OpenAI 团队在一个“agent-first”的工程体系里,用 Codex 作为主力,几乎不靠人工手写代码,从空仓库出发,在约 5 个月内把内部 beta 产品推进到约百万行代码、约 1,500 个 PR 的规模。在 agent-first 的开发范式里,工程竞争力不再主要体现为“谁写得更快”,而是“谁能把环境、知识、边界、可观测性和反馈回路设计得更适合代理工作”。OpenAI 团队把仓库本身做成代理可读、可验证、可持续维护的系统,让 Codex 不仅写业务代码,还参与测试、文档、CI、评审、修复和收敛技术债,最终形成了一个高吞吐、低人工编码、强自动闭环的开发体系。与此同时,文章也提醒:代理越强,越需要更严的架构纪律和更持续的垃圾回收机制,否则熵增会迅速吞噬效率。
>> 背景痛点:
● 从“写代码”转向“让代理能写代码”:这篇文章的出发点,是团队在一个内部 beta 产品上尝试“0 行人工手写代码”的新模式;在这种模式下,人类不再直接编码,而是负责设计环境、定义意图、搭建反馈回路。传统工程里“人写代码”的主任务被改变了,新的难点变成如何让 Codex 可靠地做事。
● 早期进展慢,根因不是模型不行,而是环境不够清晰:文章明确说,早期速度低于预期,主要原因是环境“未充分定义”,代理缺少完成高层目标所需的工具、抽象和内部结构。也就是说,瓶颈不再是“会不会写”,而是“有没有足够可执行的上下文与约束”。
● 人类 QA 与注意力成为硬瓶颈:随着代码吞吐上升,新的限制转移到人类 QA 能力、排查能力和注意力分配上。作者强调,真正稀缺的是人类时间与关注,而不是单纯的代码生成能力。
● 仓库知识分散且易失真:Slack、Google Docs、人的经验和口头共识都无法被代理直接读取,导致很多关键知识对代理“不可见”。文章指出,如果知识不在仓库里版本化存在,对代理来说就等于不存在。
● 代理生成代码会带来新的熵增:Codex 会复制仓库中已有的模式,包括坏模式;如果没有持续治理,代码库会逐步漂移,出现“AI slop”和技术债累积。
>> 具体的解决方案:
● 从空仓库开始,由代理生成最初骨架:团队先让 Codex CLI 在 GPT-5 支持下生成仓库结构、CI、格式化规则、包管理和应用框架,连指导代理协作的 AGENTS.md 也由 Codex 编写。这样做的目的,是从第一天起就把仓库塑造成“代理原生”环境。
● 把仓库知识改造成“系统记录”:他们不再把 AGENTS.md 当百科全书,而是当目录,把真正的知识放进结构化的 docs/ 目录中,形成系统记录(system of record)。设计文档、执行计划、技术债、质量评分、可靠性和安全文档都被版本化并放在仓库内部。
● 把应用、日志、指标、链路追踪做成代理可读:为了突破人类 QA 的瓶颈,团队让应用可按 git worktree 独立启动,并把 Chrome DevTools Protocol 接入代理运行时,同时开放 DOM 快照、截图、导航、日志、指标和 traces,让 Codex 能直接验证 UI、复现 bug、检验修复。
● 用机械约束替代口头要求:团队通过固定的架构分层、严格的依赖方向、结构化 lint、结构测试和定制错误信息,把“品味”和“边界”编码进系统。重点不是规定实现细节,而是强制不变量,让代理在清晰边界内自由发挥。
● 把开发闭环直接编码进系统:Codex 不只是写代码,还要自动完成本地审查、请求额外代理审查、响应反馈、修复构建失败、打开 PR、合并变更,直到需要人类判断时才升级。文章描述的目标是把测试、验证、review、恢复等环节变成代理可执行的完整循环。
● 把质量治理自动化为“垃圾回收”:团队将“黄金原则”写入仓库,并通过周期性后台 Codex 任务扫描偏差、更新质量评分、打开重构 PR,用持续的小修代替人工周五大扫除。
>> 核心思路步骤:
● 第一步:建立代理能工作的最小可运行环境:先生成仓库结构、CI、格式化、包管理和基础框架,再让代理在这个环境里持续迭代;关键不是一开始写很多,而是让代理一开始就能稳定推进。
● 第二步:把大任务拆成可执行的小块:团队采用 depth-first 的推进方式,把设计、编码、评审、测试等拆成块,让代理逐个构造,再用这些块解锁更复杂任务。
● 第三步:把重要知识显式写入仓库:通过 docs/、架构文档、设计文档、执行计划、质量评分、产品规范等,把原本散落在聊天和脑中的信息转化为可检索、可验证、可更新的版本化资产。
● 第四步:用约束和可观测性把代理“扶上轨道”:通过分层架构、边界校验、structured logging、命名规范、文件大小限制、可靠性约束等,确保代理的输出既快又不散;同时给它足够的日志、指标、trace 和 UI 证据,帮助它自我修复。
● 第五步:将 review、反馈、修复与合并自动串联:Codex 先自审,再请求更多代理审查,再处理人类反馈,最后自主推进到 PR 合并;当它碰到问题时,系统会把问题视作“缺失能力”的信号,再回写到仓库里。
● 第六步:用持续清理对抗熵增:通过背景任务不断扫描文档和代码偏差、更新质量等级、打开定向修复 PR,把技术债治理从“人工集中处理”变成“持续自动回收”。
>> 优势:
● 开发速度显著提升:文章称,在大约五个月内,团队把一个内部 beta 产品推进到约百万行代码、约 1,500 个 PR 的规模,并估算整体效率约为手写代码的 1⁄10 时间。
● 人类注意力被用在更高杠杆的位置:工程师从“写代码的人”变成“设计环境、设定约束、翻译需求、判断升级”的人,真正稀缺的人类时间被用在最关键的决策上。
● 代理可独立完成更长任务链:Codex 可以单任务连续工作数小时,验证状态、复现 bug、录制失败视频、实现修复、复验、打开 PR、响应反馈,甚至合并变更。
● 系统稳定性与可维护性更强:通过机械 lint、结构测试、版本化文档和持续清理,代码库不再依赖个人记忆或口头共识,未来 agent 运行也更容易保持一致性。
● 可扩展到多个代理协作:把系统做成可 inspect、可 validate、可 modify 的形态,不只提升 Codex,也让其他代理能够在同一仓库中更高效工作。
>> 结论和观点(侧重经验与建议):
● 不要把“写代码”当成工程工作的唯一核心:在 agent-first 场景里,更关键的是设计环境、定义意图、建立反馈回路。经验上,谁能把这些“工程基础设施”做得更好,谁就更能放大代理能力。
● 给代理一张“地图”,不要给一份超长说明书:作者明确表示,巨大的 AGENTS.md 会挤占上下文,变成不易验证的陈旧手册;更好的做法是用短入口 + 深层文档的 progressive disclosure。
● 约束是加速器,不是负担:对代理而言,清晰边界、固定层级和可机械验证的不变量,比自由发挥更重要;经验上,先把边界定严,速度才不会以失控为代价。
● 把质量规则变成代码与工具,而不是靠提醒:结构化 lint、定制错误信息、自动文档治理、周期性清理任务,这些机制一旦写进系统,就能对所有代理同时生效,远比人工提醒更可靠。
● 人类的“品味”要持续回写到系统里:review comments、重构 PR、用户 bug 都应被转化成文档更新或工具规则;当文档不够时,就把规则升格进代码。
● 高吞吐下,轻门禁可能比重阻塞更合理:当代理产能远高于人类注意力时,短生命周期 PR、少阻塞、后续补修通常比长时间等待更有效;但作者也提醒,这种做法只适合高吞吐环境。
● 别低估持续清理的重要性:代理会复制仓库中的坏模式,因此必须通过持续“垃圾回收”来抑制熵增;经验上,小步、频繁、自动化的修复,比周期性大扫除更可持续。
● 这套方法有效,但不要轻易泛化:作者特别说明,这一成果强依赖于仓库结构和工具投资,短期内不能简单套用到所有团队;长期演化仍在学习中。
目录
OpenAI 如何在 agent-first 时代从空 git 仓库出发,以 Codex 为核心、以仓库知识为系统记录、以可读性和架构约束为边界、以高吞吐反馈回路和持续垃圾回收为机制,构建一个几乎零人工手写代码、可端到端驱动开发、测试、评审、修复与发布的内部软件工程体系
一、从空 git 仓库开始
核心要点
经验技巧
二、重新定义工程师的角色
核心要点
经验技巧
三、提高应用的可读性
核心要点
经验技巧
四、把仓库知识做成系统记录
核心要点
经验技巧
五、让代理可读是终极目标
核心要点
经验技巧
六、强制架构与品味边界
核心要点
经验技巧
七、吞吐量改变合并哲学
核心要点
经验技巧
八、“代理生成”到底意味着什么
核心要点
经验技巧
九、提升自治级别
核心要点
经验技巧
十、熵增与垃圾回收
核心要点
经验技巧
十一、我们仍在学习
核心要点
经验技巧
地址
文章地址:https://openai.com/index/harness-engineering/
时间
2026年02月11日
作者
Ryan Lopopolo, Member of the Technical Staff
文章一开始就把前提讲得很清楚:团队从一个空仓库起步,最初的仓库骨架、CI、格式化规则、包管理和应用框架,都是由 Codex CLI 在 GPT-5 的帮助下生成的,连指导代理工作的 AGENTS.md 也由 Codex 编写。五个月后,仓库已经扩展到约百万行代码,涵盖业务逻辑、基础设施、工具、文档和内部开发工具,且整个过程没有人类直接手写代码。
“零人工手写代码”不是口号,而是团队明确设定的约束。
通过代理生成初始工程骨架,可以把工程团队从“写代码”转向“设计环境、定义意图、建立反馈回路”。
产出规模的提升,依赖的不是单纯加人,而是把人类时间集中在高杠杆决策上。
先让代理建立可工作的最小系统,再逐步扩展,而不是等“架构完美”后再开始。
把“如何让代理持续产出”当成第一性问题,而不是把写代码本身当成唯一目标。
尽早把仓库规范、运行方式和协作规则固化下来,因为代理会沿着这些规则快速放大结果。
这一章强调:当人不再直接写代码时,工程师的工作重心会转向系统搭建、脚手架设计、任务分解和能力补齐。团队发现,进展慢通常不是因为模型不行,而是因为环境定义得不够清楚,代理缺少完成高层目标所需的工具、抽象和结构。
工程师的角色从“生产代码的人”转成“让代理能生产代码的人”。
面对失败,重点不该是“再试一次”,而是识别“缺了什么能力”。
任务推进的正确姿势是深度优先:把大目标拆成设计、实现、评审、测试等可执行块。
把复杂任务拆成更小、更容易被代理理解和完成的块。
每次失败都追问:是提示词不够,还是结构不够,还是工具链不够。
让代理先自审、再请求其他代理审查、再循环修正,减少对人工逐步盯守的依赖。
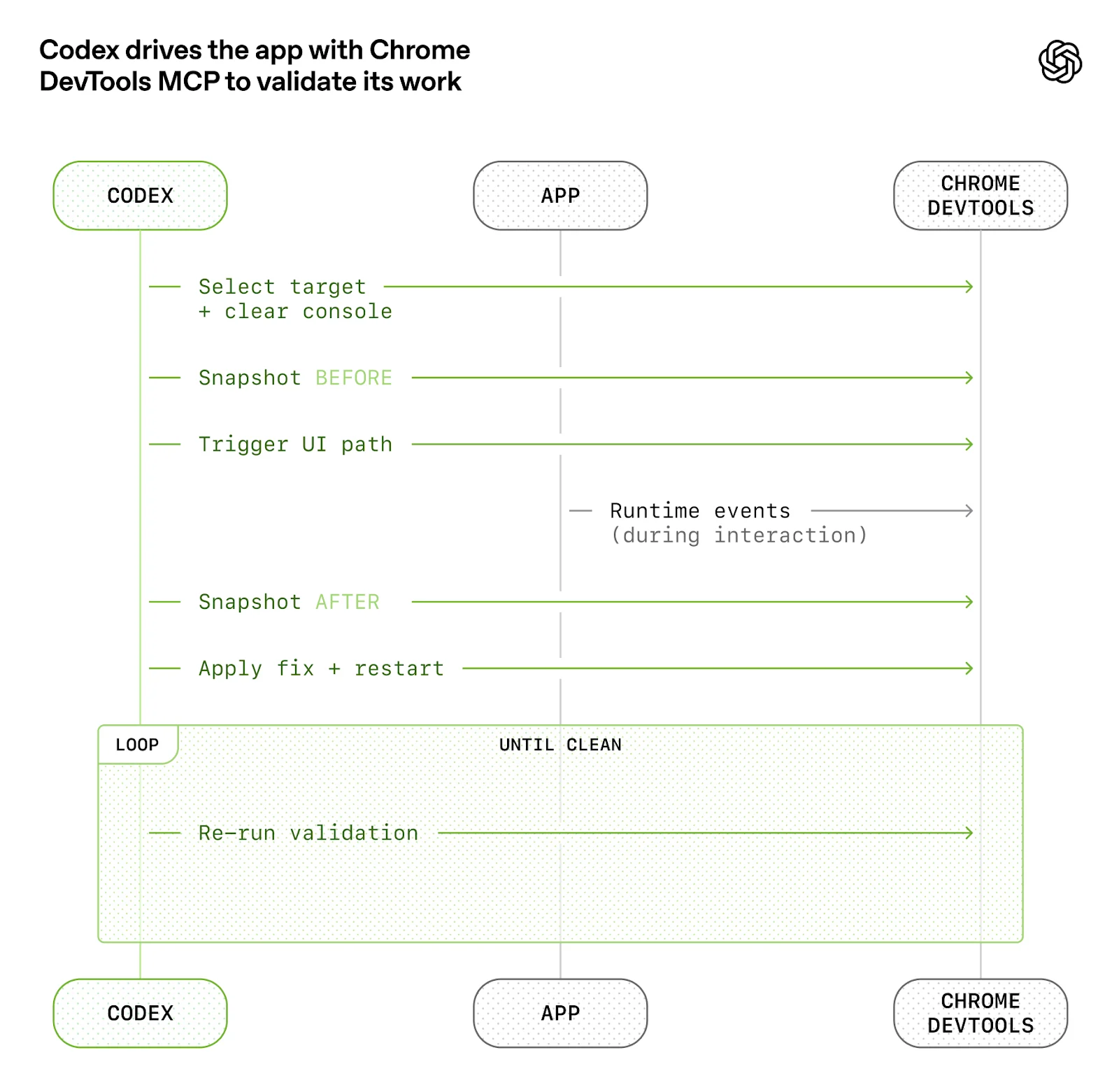
随着代码吞吐上升,真正的瓶颈变成了人类 QA 容量,于是团队反过来增强“应用对代理的可读性”。他们让应用可以按 git worktree 独立启动,把 Chrome DevTools Protocol 接进代理运行时,还为 DOM 快照、截图、导航、日志、指标和 traces 建了可查询的本地可观测性体系。
让代理“看懂”应用,比单纯给它更多文字说明更重要。
UI、日志、指标、链路追踪都应当成为代理可直接消费的信号。
当这些信号可用时,很多原本模糊的目标就变成了可验证的工程任务,比如启动耗时和关键用户路径延迟。
让代理能直接启动、驱动、验证独立实例,而不是共享一个脆弱环境。
把“可观察性”做成代理的原生能力,而不是只留给人类排障。
用结构化指标替代泛泛的主观描述,让任务目标更容易闭环。
团队意识到,代理效果的关键瓶颈之一是上下文管理:给它一大坨说明文档并不会更好,反而会压缩真正需要的任务信息。于是他们把 AGENTS.md 降格为“目录”,把真正的知识体系放进结构化的 docs/ 目录,作为系统记录来源,并用 CI、lint 和一个持续“整理文档”的代理来维护知识新鲜度。
大而全的手册会挤占上下文,且很快失效。
更好的办法是“进阶披露”:先给稳定入口,再引导代理逐层深入。
知识必须可检验、可交叉引用、可更新,否则会变成漂浮的旧规则。
让顶层说明文档足够短,只承担导航职责。
把设计文档、计划、技术债、参考资料分层存放,降低代理搜索成本。
用自动化检查文档是否过时、是否互相引用、是否与代码一致。
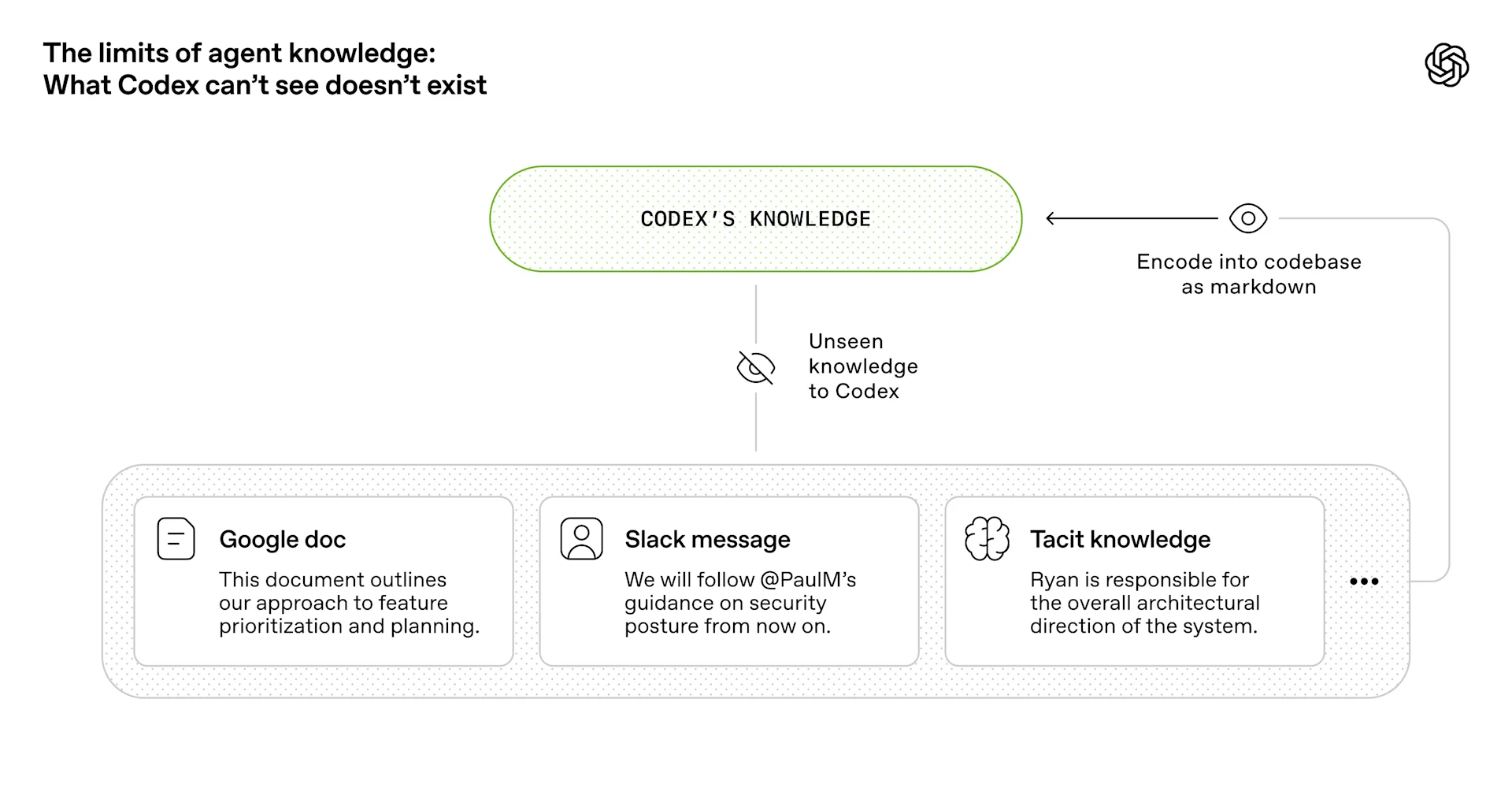
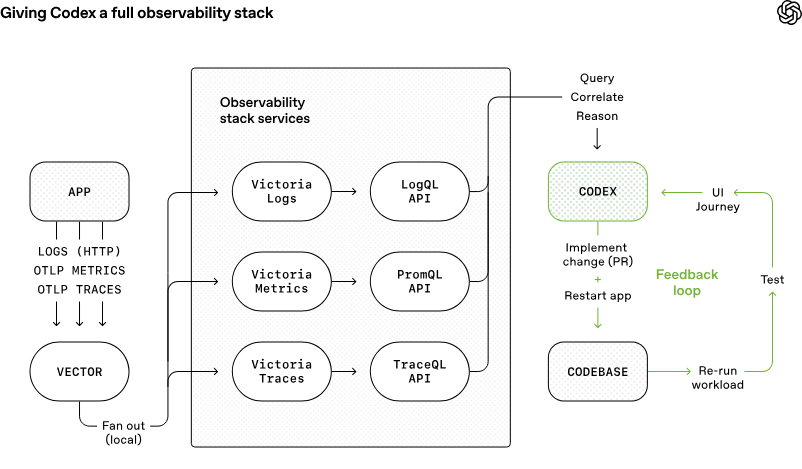
这一章把问题提升到“知识可见性”层面:对代理来说,仓库之外的知识基本等于不存在。Google Docs、Slack、人的脑内经验,都无法被直接读取;只有代码、Markdown、schema、可执行计划这类版本化工件,才是真正可用的上下文。因此,团队不断把更多背景信息编码进仓库,并偏好那些可组合、可稳定建模、可被内部理解的技术选择。
代理的世界边界,就是它运行时能看到的上下文边界。
把“人类心照不宣的知识”转成仓库里的显式知识,才能让代理稳定工作。
有些看似朴素的技术方案,反而更适合代理,因为可推理性和可验证性更强。
把团队共识写进仓库,而不是只留在聊天记录里。
倾向选择更容易被代理理解的依赖和抽象。
在必要时重写局部功能,比在 opaque 的外部库上绕路更划算。
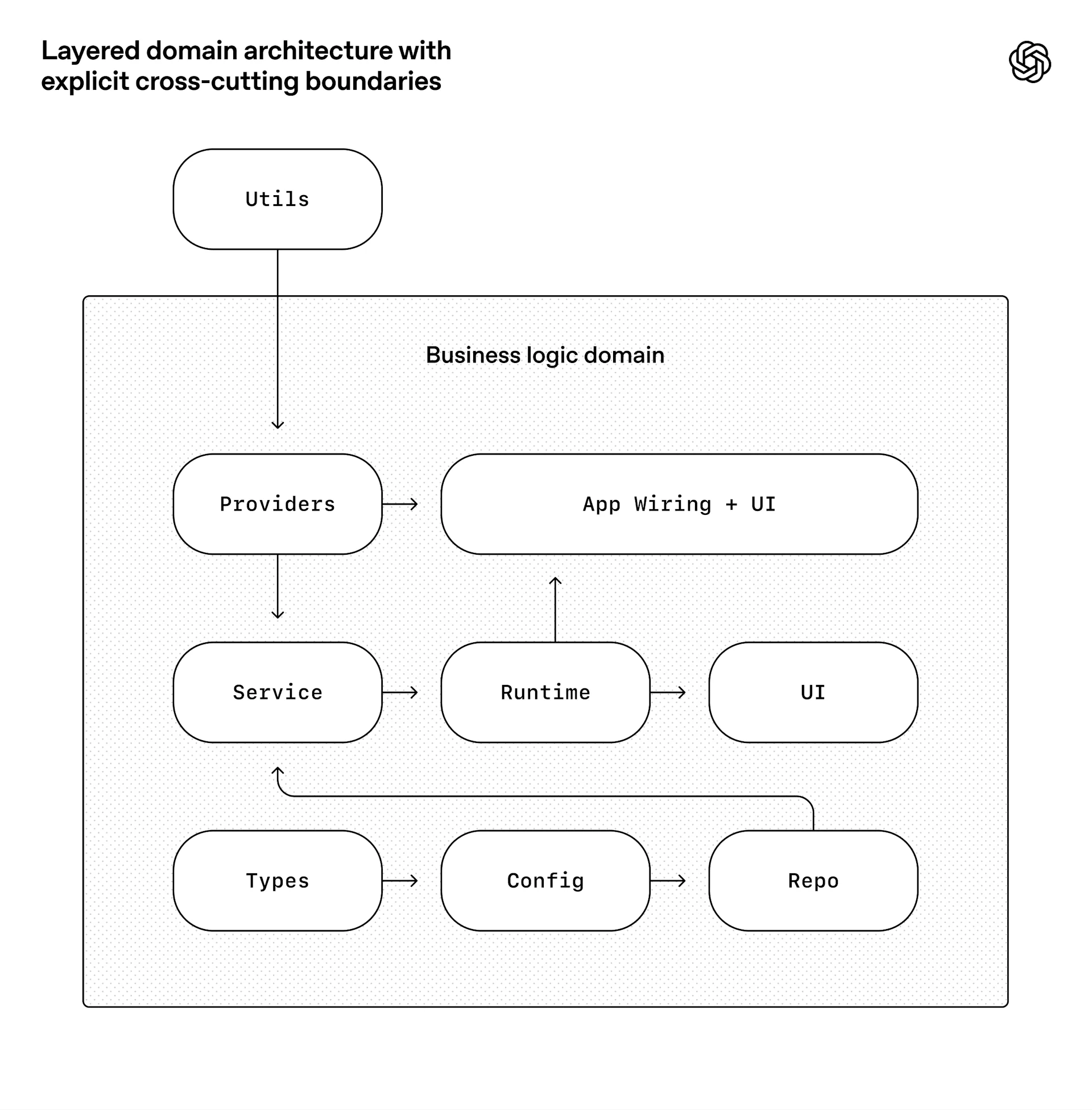
文章强调:单靠文档不足以维持一个完全代理生成的代码库,必须靠“约束”来防止失控。团队通过严格的架构层级、依赖方向限制、边界校验和自定义 lint,把代理可做的事情定义清楚;他们只要求代理遵守 invariants,不强行规定实现细节。
对代理而言,架构约束不是阻力,而是加速器。
只要边界清晰、结构可预测,代理就更容易稳定扩展。
“品味”不是靠口头要求,而是靠可执行规则不断回写到系统里。
把边界规则做成机械检查,而不是靠人工记忆。
让 lint 报错本身携带修复建议,直接进入代理上下文。
在中央严格控制边界,在局部保留表达自由,这样既能快又不容易烂。
当 Codex 的产能足够高后,传统工程流程中的一些“重阻塞”机制反而拖慢了进度。于是团队采用更轻的合并门槛、短生命周期 PR 和更偏向事后修复的方式:在代理吞吐远高于人类注意力时,等待往往比修复更昂贵。
低吞吐团队适合严格阻塞;高吞吐代理团队则更适合轻门禁。
测试波动可以先继续推进,再通过后续运行修复。
工程流程必须适配产能变化,否则流程本身会成为瓶颈。
重新评估“必须阻塞”的门槛,别把低产能时代的规则原封不动带到代理时代。
让 PR 更短、更快合并,再用后续自动化持续收敛质量。
以系统的整体节奏为准,而不是以单个失败测试为绝对中心。
文章明确界定:所谓“代理生成”,不是只写业务代码,而是整个代码库中的所有内容都由代理产出,包括测试、CI、发布工具、内部开发工具、文档、设计历史、评测框架、审查意见、仓库脚本和生产监控定义。人类仍在环路中,但更多承担的是优先级排序、需求翻译、结果验证和判断升级。
代理接管的是“软件生命周期”的大部分环节,不只是编码。
人类的价值上移到“定义问题”和“判断何时需要人工介入”。
当代理卡住时,问题通常被视为系统反馈:说明还缺工具、文档或护栏。
不要把“写代码”当成唯一交付物,要把支撑交付的周边系统也纳入代理产出范围。
让代理直接使用标准开发工具完成反馈闭环。
人类只在需要判断时介入,把决策稀缺性用到最值钱的地方。
当测试、验证、评审、反馈处理和恢复机制都被编码进系统后,Codex 已经跨过一个关键门槛:它可以从单个提示出发,端到端驱动新功能开发。它能验证当前状态、复现 bug、录制失败视频、实现修复、验证修复、打开 PR、处理反馈、发现构建失败并修复,只有在确实需要判断时才升级给人类。
自治不是一步到位,而是靠一层层把开发循环编码进系统。
代理越能自己闭环,人类越少被动救火。
这种能力高度依赖具体仓库结构与工具链,不能简单外推。
把 bug 复现、修复、验证、回放都标准化,减少人工口头转述。
让代理以视频、日志、测试结果等证据来证明自己完成了工作。
只有当问题涉及明确判断时,再让人类进入回路。
完全自治也会带来新问题:代理会复制仓库里已有的模式,包括不优雅甚至有缺陷的模式,久而久之就会产生漂移和“AI slop”。团队曾经用人工周五清理来对抗,但不可扩展,于是改为把“黄金原则”写入仓库,并建立周期性的背景清理任务,像垃圾回收一样持续收敛技术债。
代理不会天然创造秩序,它会复制现有结构,包括坏结构。
质量维护必须从“人工定期大扫除”升级为“系统化持续回收”。
技术债最怕积累,最好的策略通常是小步、持续、自动化地偿还。
把抽象原则改写成机械规则,持续执行。
用后台任务扫描偏差、更新质量评分、发起定向重构 PR。
让少量、快速、可自动合并的修复代替高成本的大清理。
文章最后保持了克制:这套方法目前在内部产品和真实用户场景中运作良好,但团队仍不确定在多年尺度上,完全代理生成系统的架构一致性会如何演化,也不确定未来模型更强后,这套体系会怎样变化。真正重要的挑战,已经从“怎么写代码”转向“怎么设计环境、反馈回路和控制系统”。
目前的成功不代表长期答案已经找到。
未来竞争点不是单个模型能力,而是整个工程环境的设计能力。
能否持续把人类判断编码成可复用的系统,是更大的问题。
把注意力放在“让系统可持续工作”而不是短期堆产出。
关注哪些判断值得固化成规则,哪些必须保留人工裁量。
继续优化 scaffolding、抽象和反馈回路,这些会比单次编码更值钱。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/257811.html