
分享十个 Claude实用的Token 节省方案
1、在已发送的消息上修改,而不是另发一条消息
当 AI 回答不符合我们的预期时,尽量不要发一条「不对,我是指……」来跟进。
因为每发一条新消息,大模型都要把前面的所有聊天记录重新读一遍,导致 Token 消耗成倍翻滚。正确的做法是:直接点击原消息的「编辑」按钮,修改提示词,然后重新生成。
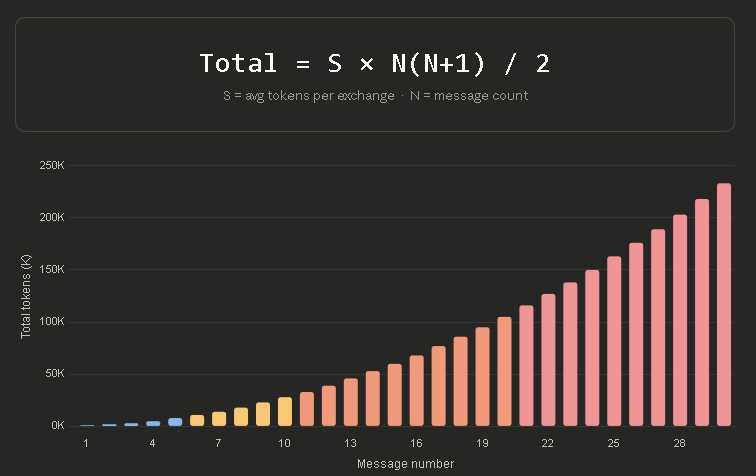
消息越多,消耗的 token 也越多。原文来源:https://x.com/0x_kaize/status/
2、每 15–20 条消息就开启一个新对话
长对话是 Token 的无底洞,在一百多条消息的对话中,可能有 98.5% 的 Token 都浪费在让 AI 重读历史记录上。
当对话变长时,我们可以让 AI 先总结一下当前进度,然后拿着这段总结去开一个新的对话。
3、将所有问题都集中到一个消息里面发送
不要把「总结这篇文章」、「列出这篇文章的要点」、「给这篇文章想个标题」分成三条消息发送。
把它们合并成一段完整的提示词,不仅能减少系统加载上下文的次数,还能让 AI 因为看到了全貌而给出更高质量的回答。
4、把反复使用的文件上传到 Projects 中
如果我们在多个聊天窗口里反复上传同一份长文档,每次上传都会重新消耗大量的 Token。
这个时候我们可以利用 Projects 的缓存功能,文件只需上传一次,后续在这个项目里怎么问关于这份文件的内容,都不会再重复烧 Token 了。
5、提前设置好「记忆」与用户偏好
大多数时候,我们会按照以前的提示词技巧,在发每次开新对话时,都会「浪费额度」去写「现在你是一个文案策划,用轻松的语气写……」。
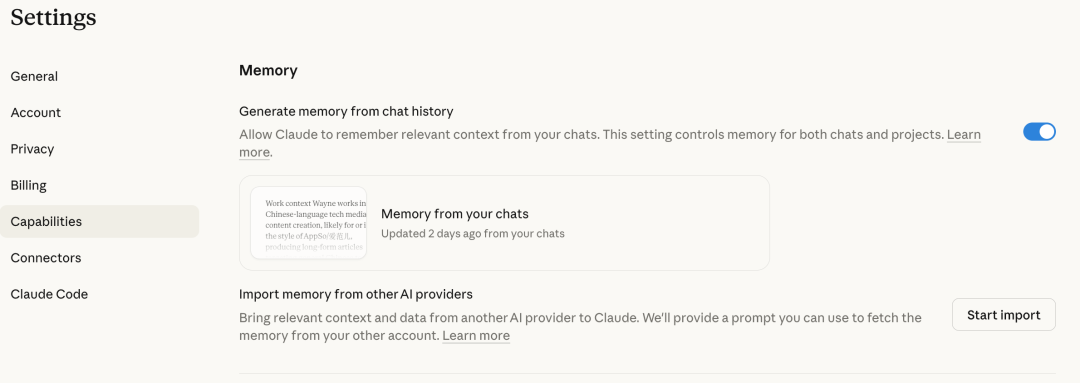
现在 AI 都有用户偏好和记忆功能,我们可以把职业、行文风格、项目信息等偏好保存在设置里,它就会自动生效,帮我们省下大量重复交代背景的 Token。
6、关掉不需要的附加功能
联网搜索(Web search)和高级思考(Advanced Thinking)等功能只要开着,每一轮都会额外消耗 Token。
除非我们对初步的回答不满意,或者明确需要这些功能,平时在简单地聊天时,可以关闭这些附加功能。
7、用不同的模型解决不同的问题
一些简单的任务,像检查语法、简单排版、快速翻译这些基础活,完全可以使用成本最低的 Haiku 模型。把节省下来 50%–70% 的额度,留给那些真正需要深度思考的复杂任务,交给 Sonnet 或 Opus。
8、把工作分散到全天的不同时段
Claude 的使用限制是基于「滚动 5 小时」窗口来计算的,而不是半夜统一清零。
如果我们早上把额度耗光了,下午就会很难受。建议把工作分成早、中、晚几个时段,这样额度会不断自动恢复。
9、尽量避开高峰时段
从 2026 年 3 月 26 日开始,如果在工作日的高峰期(太平洋时间早上 5 点到 11 点)使用,同样的请求会更快地消耗限额。如果把重度耗费算力的任务挪到非高峰期(比如晚上或周末),额度会经用得多。
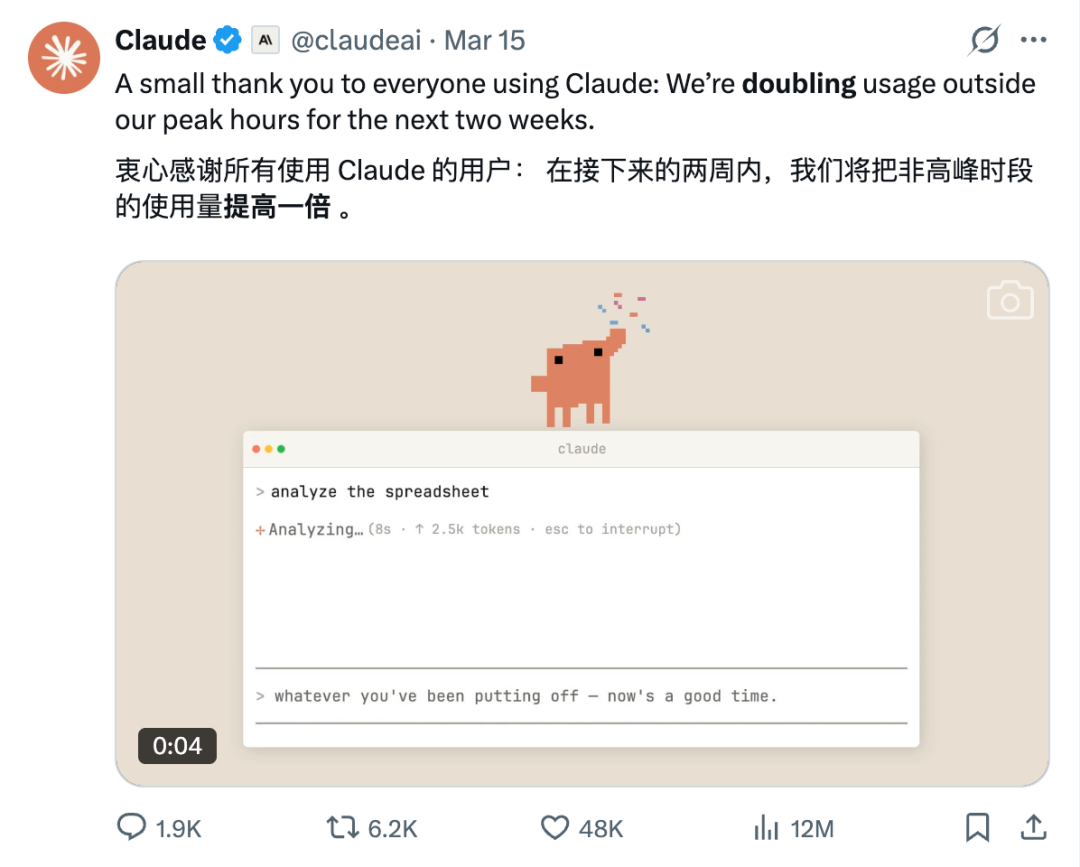
这是基于 Claude 之前推出的错峰双倍福利,一方面是 Anthropic 的尖峰服务器压力大,给一些福利希望用户在平谷时候使用 Claude,另一方面也确实给北京时间的用户实实在在的优惠。
目前在 Cursor 等应用内使用大模型,有时候还是会碰到请求过多的提示,尤其是在晚上的时间。
10、开启超额使用 (Extra Usage)作为安全网
如果是 Claude 付费用户,可以在设置里开启超额功能并设定预算上限。
这个方法虽然不省 Token,但可以保证当我们的额度耗尽时,系统会自动切换到按量计费,防止在十万火急的工作关头突然被强制阻断。
无论是靠 Skills 还是我们自己调整提示词,这些方案的底层逻辑都是要减少毫无意义的上下文重读。从千禧年按字算钱的短信,到如今按 Token 计费的大模型,人类追求沟通效率的本质其实从未改变。
在使用 AI 的过程中,逐渐养成这些习惯,用「山顶洞人」的语言,只说重点,把 Token 用在刀刃上,或许是这个 Token 堪比真金白银的时代,最顶级的提示词技巧。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/256559.html