

Anthropic 刚刚给所有开发者发了一张快车票。Claude Managed Agents 正式公测,你不需要自己搭 Docker、写沙箱、管状态、做错误恢复——三个 API 调用,十分钟,一个生产级智能体就跑起来了。
Notion、Asana、Rakuten、Sentry、Vibecode 已经在上面跑了。这不是实验室里的 demo,是真正在生产环境交付价值的基础设施。

01 痛点在哪
如果你现在想让 Claude 做”真正的活”——跑代码、读文件、浏览网页、执行 bash 命令——你需要自己搭全套基础设施。沙箱隔离、状态管理、错误恢复、凭证处理。还没让智能体干活呢,光搭架子就是几个月的工程量。
我自己搭过。写一个能跑 bash 的沙箱就得处理进程隔离、超时管理、输出截断、安全边界;再加上文件系统的挂载和清理、网络策略的配置、错误日志的收集和格式化……这甚至还没把多会话并发处理和状态持久化考虑在内。做完这些,你的智能体还一行业务代码没写呢。
这就好比你想开个餐厅,结果发现得先自己盖厨房、装水电、考消防证。大多数人还没开始炒菜就累趴了。
Managed Agents 就是 Anthropic 说:厨房我来盖,你负责炒菜就行。
你定义智能体做什么,Anthropic 在云端运行它。安全容器、长时间运行的会话(可以持续数小时)、内置工具执行、事件流……全部开箱即用。智能体可以写代码、运行代码、搜索网页、编辑文件,你不需要搭任何管道。
而且这不是一个简单的 API 包装层。Anthropic 在底下做了大量针对智能体场景的优化——容器冷启动速度、工具调用延迟、会话状态的可靠持久化——这些都是你自己搭时最容易踩坑的地方。
02 四个核心概念
整个系统建立在四个概念上,理解了这四个,剩下的都是细节:
Agent(智能体配置)——你的配置文件。选哪个模型(Sonnet 4.6 还是 Opus 4.6)、系统提示词写什么、能用哪些工具、连哪些 MCP 服务器。创建一次,所有会话复用。
Environment(运行环境)——智能体跑在哪个容器里。预装 Python、Node.js、Go,设网络规则,每个会话拿到一个隔离的容器。
Session(会话实例)——一个正在运行的智能体。引用你的 Agent 配置和 Environment,维护对话历史,跨交互保留文件。会话可以运行数小时。
Events(事件流)——你的应用和智能体之间的消息通道。你发用户消息进去,Claude 通过 SSE 流式返回响应、工具调用和状态更新。
就这四个。Agent、Environment、Session、Events。不需要理解更多。
这个抽象层设计得相当干净。Agent 和 Environment 是”静态资源”,创建一次就可以反复使用;Session 和 Events 是”运行时”,每次任务创建新的。这种分离意味着你可以用同一个 Agent 配置在不同环境里跑——开发环境用受限网络,生产环境开放网络——只需要切换 Environment 引用就行。
如果你写过 Docker Compose,这个心智模型会很熟悉:Agent 是镜像定义,Environment 是运行配置,Session 是容器实例。
03 十分钟部署
你需要一个 API 密钥和三个 API 调用。没了。
第一步:装 CLI。Anthropic 发布了一个新的命令行工具叫 ant,Homebrew 一行搞定:
brew install anthropic-cli
第二步:创建 Agent。一个 API 调用定义模型、系统提示词和工具。关键参数是 agent_toolset_,一开就全套——bash、文件读写、网页搜索、网页抓取、grep、glob,全内置。
第三步:创建 Environment。又一个 API 调用。定义容器配置和网络策略。需要 pandas 和 numpy?加一行 “packages”: {“pip”: [“pandas”, “numpy”]} 就行。
第四步:创建 Session 发消息。创建会话、发送任务,Claude 接管后面的一切——自己决定用什么工具,在容器里执行,流式返回结果。
不需要配 Docker。不需要写编排代码。不需要搭工具执行层。十分钟,从零到一个可用的智能体。
这里有个细节值得注意:agent_toolset_ 这个参数名带了日期版本号。这意味着 Anthropic 会持续迭代工具集,而你的 Agent 配置可以锁定到特定版本,不会因为上游更新而突然改变行为。这是一个成熟的 API 设计决策——说明他们是认真把这个当基础设施来做的,而非一个试水性质的临时方案。
04 谁已经在用
不是 PPT,是实打实的生产案例。
Sentry 的调试工具 Seer:智能体拿到错误报告后,先克隆代码库,读懂上下文,定位 bug,然后写补丁代码,跑测试确认修复没有破坏其他东西,最后直接开 Pull Request。从发现问题到提交修复,全自动——中间不需要人类碰一行代码。想想看,以前一个 on-call 工程师半夜被叫起来处理的事情,现在智能体在几分钟内就处理完了。
Rakuten 的金融团队:给产品、销售、市场、财务每个部门部署专属智能体,每个不到一周就上线了。拿到原始文件、提取结构化数据、输出干净的结果。
Asana 搭了 AI Teammates:智能体像一个真正的团队成员一样在 Asana 里接任务、做事。不是一个”帮你写文案”的按钮,而是一个会主动认领任务、汇报进度、交付结果的同事。这种交互范式和之前的”聊天机器人”完全不同——它不是在聊天窗口等你提问,而是直接在你的项目管理工具里和人类同事并肩协作。
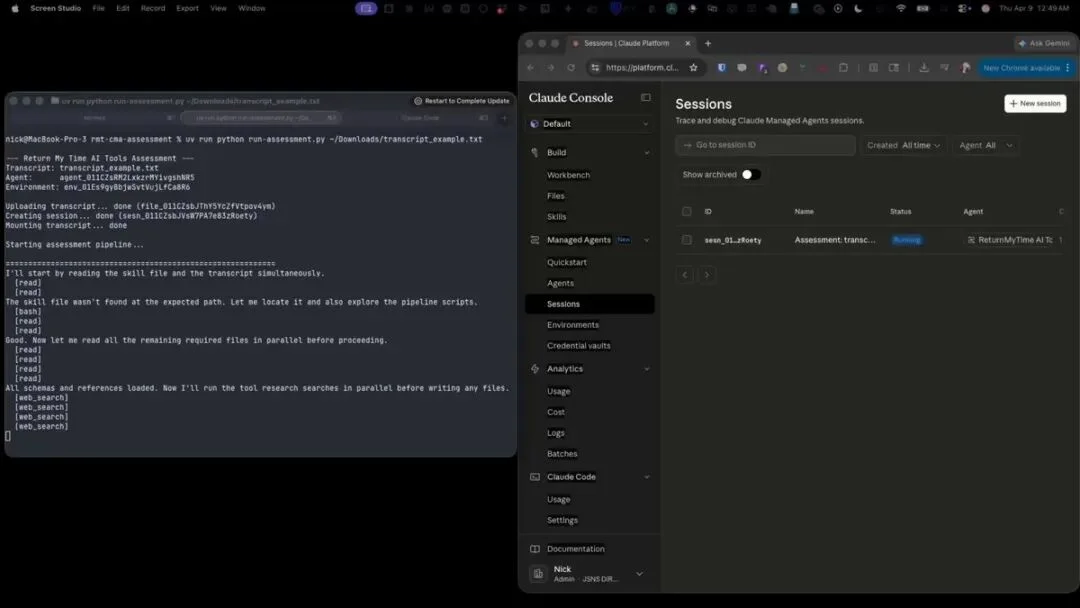
还有一个很有意思的模式:智能体现场写工具。有公司用 Managed Agents 做内部问答系统,智能体收到任何查询时不是调用预设的 API,而是当场写一段 Python 脚本来处理,因为环境里有完整的 Python 运行时。原文说得很直接:
智能体能处理几乎任何用户查询,因为它需要什么工具就现场写什么工具。
这意味着你不需要预先定义几百个 API 端点。一个智能体,一个运行时环境,就能覆盖大部分内部需求。传统做法是给每个查询写一个专门的处理函数,需求变了就改代码重新部署。现在智能体拿到需求后自己写处理逻辑、自己跑、自己返回结果。
这种模式有个专门的名字叫”运行时代码生成”,以前只在学术论文里讨论。Managed Agents 把它变成了一个开箱即用的生产方案。
还有一种场景文章里没有展开但值得说:数据分析智能体。给它一个 CSV 文件,它在环境里写 Python 脚本、用 pandas 处理数据、生成可视化图表、然后返回分析报告。整个过程不需要你写一行数据处理代码——因为环境里已经预装了 Python 和所有常用库。这对非技术团队来说是真正的解放。
05 权限系统
如果你要给其他人用,这部分必须看。
Managed Agents 有两种权限模式:always_allow(工具自动执行,适合内部可信场景)和 always_ask(会话暂停等你的应用审批后才执行,适合面向用户的场景)。
可以混合使用。让智能体自动读文件、搜网页,但执行 bash 命令前必须审批——每个工具单独设权限,一行配置。MCP 工具默认 alwaysask,不会有第三方工具偷偷自动执行。
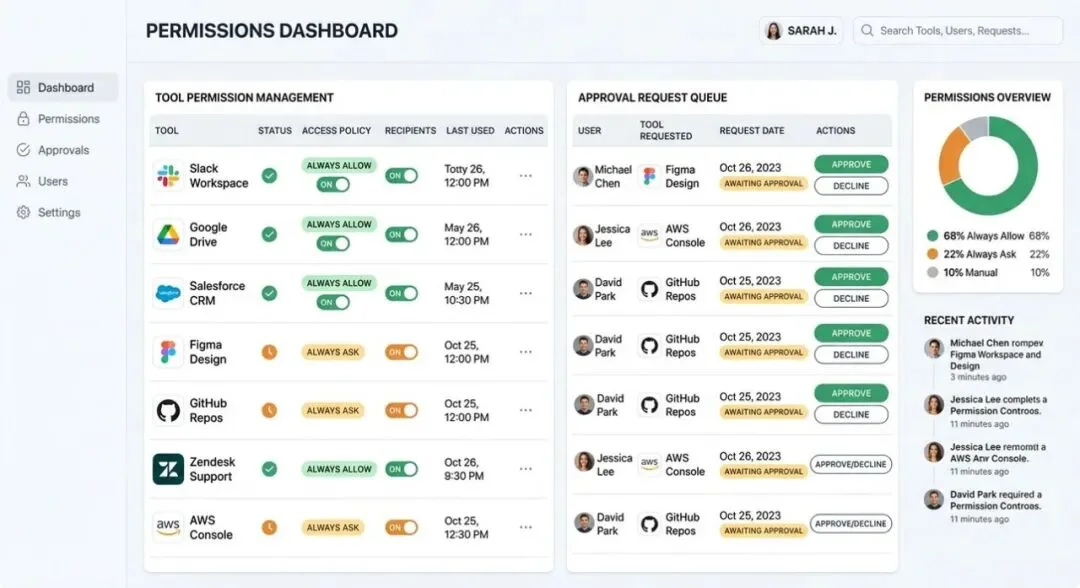
Nick Spisak 提出了一个相当犀利的观点:
光是这个权限系统,就比大多数开源智能体框架更适合上生产了。LangGraph、CrewAI、AutoGen,没有一个内置了按工具粒度的权限控制。你得自己搭。这里只是一个配置参数。
我同意。目前绝大多数开源框架在”让智能体好用”方面做了大量工作,在”让智能体安全可控”方面还差得远。Managed Agents 把这件事做到了配置层面。
实际场景中这有多重要呢?假设你搭了一个客户支持智能体,它可以查订单、查库存、退款、发邮件。你肯定希望查询操作自动执行(不然每次客户问一个问题都要你审批,体验很差),但退款操作必须有人类审批(不然一个提示词注入就可能导致大规模误退款)。之前你得自己写这整套审批流程的代码,现在一行 JSON 配置就搞定了。
06 快速启动
如果你已经在用 Claude Code,最快的方式是直接在 Claude Code 里输入一句话:
start onboarding for managed agents in Claude API
Claude Code 内置的 claude-api 技能会引导你走完全部流程。或者直接去 Claude Console(platform.claude.com)用可视化的 Agent Builder,在线配置、在线测试,然后把 Agent ID 复制到代码里。
定价是按用量计费的:标准的 Claude API token 费率,加上 每个会话每小时 \(0.08 的运行时费用。一个 10 分钟的编码智能体会话,算力成本只有几美分。
还有一个更快的路径:如果你只是想体验一下,在 Claude Console(platform.claude.com)上有一个可视化的 Agent Builder。你可以在浏览器里配置智能体、在线测试、看实时日志,不用写一行代码就能把整个流程走通。确认效果后再复制 Agent ID 到代码里做集成。对于不写代码的产品经理和业务负责人来说,这可能是最有意义的入口——他们第一次可以自己定义和测试一个智能体,而不需要排队等工程团队排期。
07 MCP 集成
Managed Agents 原生支持 MCP 服务器。连接 GitHub、Slack、你的 CRM,任何 MCP 服务器都可以。
凭证管理通过 Vault 系统处理——密钥永远不会出现在你的 Agent 配置文件里。这个设计意味着Agent 配置可以在团队内安全共享,无需担心敏感凭证外泄。
而且你还可以在 Claude Console 里直接上传你的 Skills、MCP 服务器配置。不用写代码,直接在平台上管理智能体的能力边界。
这意味着什么?意味着你可以给智能体连上 GitHub MCP 服务器,它就能读写代码仓库;连上 Slack MCP 服务器,它就能发消息、读频道历史;连上你自己的业务系统 MCP 服务器,它就能操作你的数据库和后台。每多连一个 MCP 服务器,智能体的能力就多一层。而这些连接全部在 Anthropic 的云端运行,你不需要在本地跑任何 MCP 代理。
对于已经在用 MCP 协议的团队来说,迁移到 Managed Agents 几乎是零成本的——你的 MCP 服务器不需要改一行代码,直接接入就行。

08 成本和限制
Nick Spisak 在文章里直说了:API 用量会很贵。这不是客套话。
Managed Agents 的智能体自主决定调用什么工具,每次工具调用都会消耗 token。一个复杂任务可能涉及十几次工具调用,每次都有上下文传递。如果用 Opus 4.6,成本会更高。
但换个角度想:一个初级工程师一个月工资多少?如果一个智能体能替代一部分重复性工作——每天跑测试、处理文档、写代码补丁——每月几十美元的 API 费用可能是最划算的"招聘"。
关键是想清楚场景。高频低复杂度的任务适合用 Sonnet 4.6 跑,低频高复杂度的任务再上 Opus。不要拿大炮打蚊子。
我算了一笔账:假设一个编码智能体平均每次会话 15 分钟,一天运行 20 次。运行时费用是 20 × 0.25h × \)0.08 = \(0.40/天,加上 token 费用大约 \)5-10/天(取决于任务复杂度和模型选择)。一个月算 $200-300。这个价格比一个外包开发者的日薪还低,但它 24 小时在线、不请假、不需要 onboarding。
当然,如果你无脑让 Opus 跑大量低价值任务,账单确实会很吓人。但这不是工具的问题,是用法的问题。
还有一个隐性成本容易被忽略:调试时间。智能体在沙箱里跑出了奇怪的结果,你能不能快速定位问题?Managed Agents 在这方面做了一些工作——Claude Console 提供了会话日志、工具调用记录、事件流追踪。比起自己搭的系统里翻容器日志、拼凑上下文,这个可观测性确实好不少。但说实话,智能体调试仍然是一个不成熟的领域,你需要做好心理准备:有些 bug 是模型层面的,再好的基础设施也帮不了你。
09 对我们意味着什么
这件事的本质是:部署智能体的门槛,从”几个月的工程”降到了”一下午的配置”。
1. 基础设施不再是瓶颈。以前搭智能体最难的不是模型调用,而是容器、沙箱、状态管理、错误恢复那一堆”周边工程”。Managed Agents 把这些全包了。你的精力可以 100% 放在业务逻辑上。
2. 权限控制是第一等公民。不是事后补的安全层,而是设计之初就内置的配置参数。这让”把智能体交给终端用户”从一件冒险的事变成了一件可控的事。
3. 会话持久化改变了可能性。之前的智能体都是”一问一答”式的,干完一件事就忘了。Managed Agents 的会话可以持续数小时,文件跨交互保留。这意味着智能体能做长流程任务——读代码库、规划方案、写代码、跑测试、开 PR,一气呵成。
4. 开源框架的压力来了。LangGraph、CrewAI、AutoGen 在编排层面做了很多创新,但在基础设施层面一直是短板。Anthropic 自己下场做了这一层,开源框架要么补上基础设施,要么聚焦在 Managed Agents 覆盖不了的差异化场景。
5. 智能体不再是”锦上添花”。当部署成本从几个月降到十分钟,团队会开始把智能体用在以前觉得”不值得自动化”的场景上。一个只节省 30 分钟的自动化流程,在以前不值得花两周去搭,但如果十分钟就能部署,投入产出比就完全不同了。这会引发一波”微自动化”浪潮。
6. 这是 Anthropic 的平台战略。做模型的公司最怕被”API 商品化”——今天你用 Claude,明天 OpenAI 降价你就跑了。Managed Agents 的真正目的是增加迁移成本。你的 Agent 配置、Environment 模板、MCP 连接、会话历史,全部在 Anthropic 的平台上。用得越深,越难离开。
这不是坏事。对开发者来说,锁定效应意味着平台会持续投入让体验更好。对 Anthropic 来说,这是从”卖 token”到”卖平台”的关键一步。
Nick Spisak 说他这周就要用 Managed Agents 搭一个内容流水线和一个客户入职智能体。他的原话是:
如果你一直在等基础设施赶上 Claude 的能力——现在就是了。
我也这么觉得。过去一年我看到太多团队在搭智能体基础设施上花了几个月,最后因为维护成本太高而放弃。问题从来不是”AI 不够聪明”,而是”搭架子太累,运维太痛”。现在 Anthropic 说这些我全包了——容器帮你管、沙箱帮你隔、状态帮你存、工具帮你跑。你只需要关心一件事:你的智能体要解决什么业务问题。
架子不用搭了。该搭业务了。
相关链接:
• 原文:https://x.com/NickSpisak/status/
• Claude 平台:https://platform.claude.com
数据来源:Nick Spisak (@NickSpisak_), X Article, April 8, 2026
文章来自于”深思SenseAI”,作者 “深思SenseAI”。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/255233.html