

大模型之家挨训 4月8日,智谱开源GLM-5.1。相比参数规模或单点能力,这一版本更强调一个新的指标——模型能持续工作多久。官方信息显示,GLM-5.1已可在单一任务中连续运行超过8小时,并完成从规划、执行到优化的完整闭环。
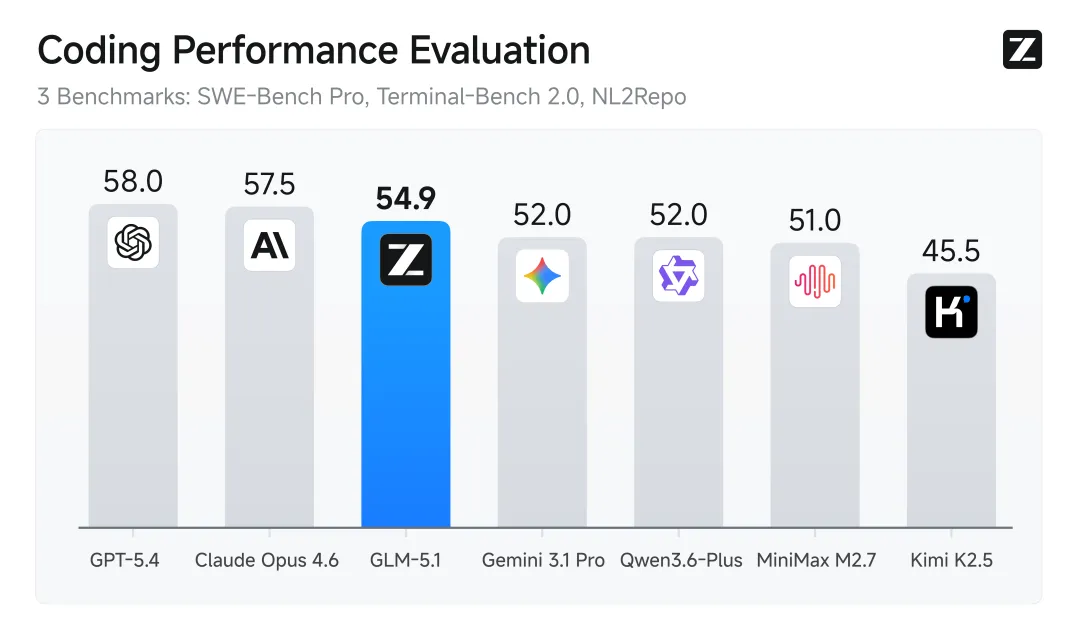
在代码能力上,GLM-5.1在SWE-Bench Pro、Terminal-Bench 2.0与NL2Repo等主流评测中取得较高排名。其中,在更贴近真实开发环境的SWE-Bench Pro测试中,其成绩超过部分闭源模型。这意味着模型不仅能生成代码,更开始具备理解复杂工程问题的能力。
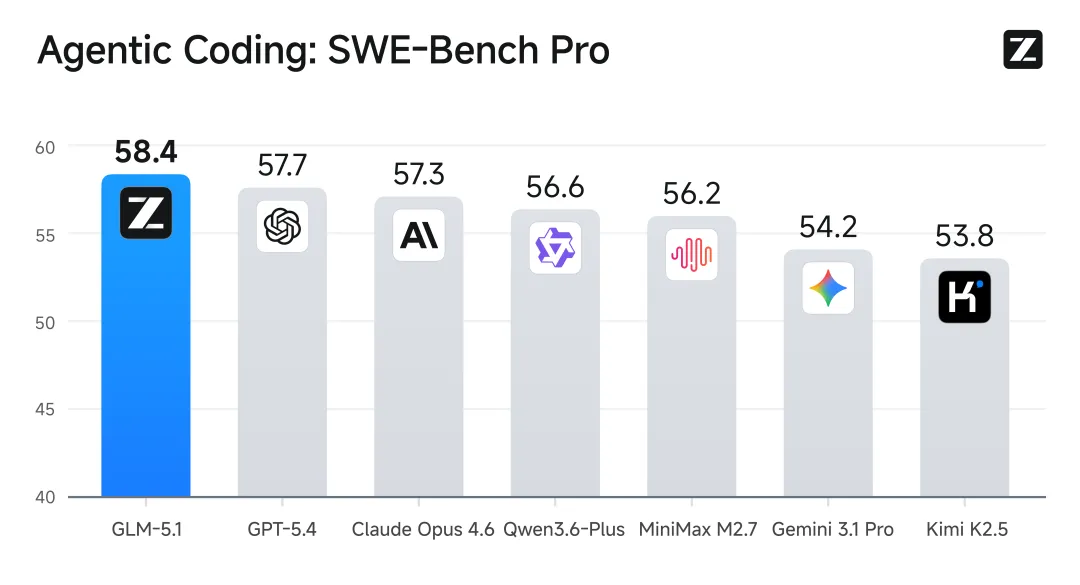
更值得关注的是其长程任务表现。在公开案例中,GLM-5.1可在8小时内独立完成Linux桌面系统构建,执行超过1200个步骤;在向量数据库优化任务中,通过数百轮自主迭代,将查询吞吐提升至初始版本的近7倍;在机器学习负载优化中,也实现了显著性能提升。
这些结果背后,是能力结构的变化。模型不再只是“生成答案”,而是能够在长时间内持续试错、调整策略,形成类似工程师的“实验—分析—优化”循环。
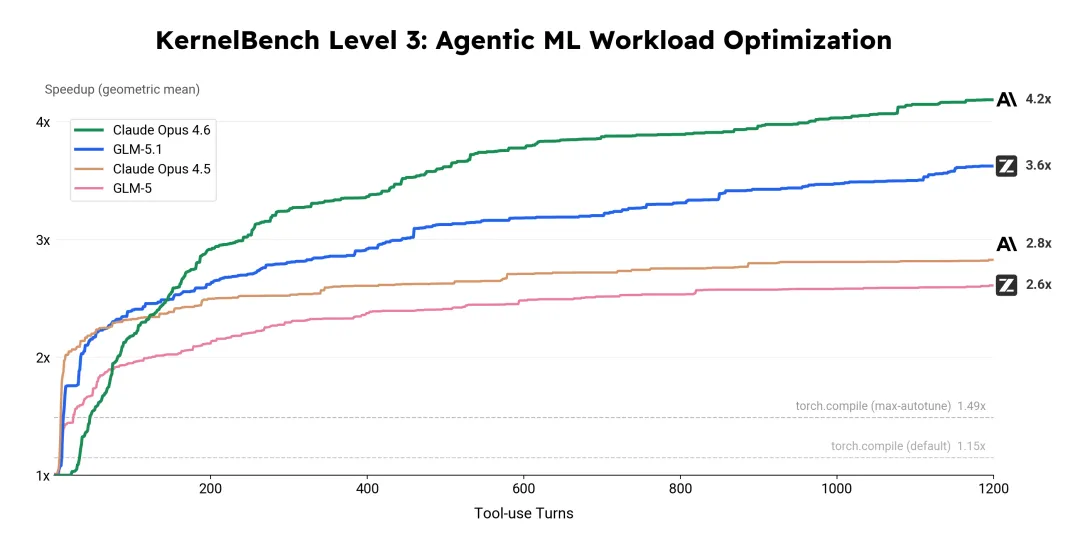
从行业角度看,GLM-5.1的意义不只在于一次性能提升,而在于提出了新的评估维度:AI的价值,正在从“有多聪明”,转向“能干多久、干成什么”。这也意味着,大模型正逐步逼近“自治智能体”的临界点。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/251708.html