
OpenClaw 软件本身完全免费,但它需要调用 AI 模型的 API,这部分通常要花钱。至少有 5 种方案可以零成本跑通:DeepSeek 免费额度、Google Gemini 免费 Tier、Ofox 注册赠送额度、Groq 免费调用、本地部署 Ollama。本文逐一拆解每种方案的配置步骤、适用场景和限制,附横向对比表格。
很多人第一次接触 OpenClaw 会困惑:不是说开源免费吗,怎么还要花钱?
这里有个关键区别——OpenClaw 是执行框架,AI 模型是大脑。框架免费,大脑要钱。
所以问题变成了:有没有免费的 API 方案? 有,而且不止一种。
推荐指数:⭐⭐⭐⭐⭐(首选方案)
DeepSeek 是目前国产模型中综合效果最好的,注册即送免费 API 额度。对于 OpenClaw 的日常使用场景,这份额度非常实用。
- 前往 DeepSeek 开放平台 注册账号
- 在控制台创建 API Key
- 配置 OpenClaw:
openclaw onboard # 选择 Custom API Provider # base_url: https://api.deepseek.com # API Key: 填入你的 Key # model: deepseek-chat或者直接编辑 ~/.openclaw/config.yaml:
ai: provider: custom base_url: https://api.deepseek.com api_key: sk-xxxxx model: deepseek-chat- 中文理解和生成能力在国产模型中最强
- 国内直连,延迟低(< 200ms)
- API 兼容 OpenAI 协议,OpenClaw 原生支持
- 代码能力接近 GPT-4o 水平
- 免费额度有上限,用完按量计费(但价格极低,约 ¥2/百万输入 token)
- 高峰期可能排队
- 只有 DeepSeek 自家模型可用
刚接触 OpenClaw 的新手、主要处理中文任务的用户、预算敏感的个人开发者。
推荐指数:⭐⭐⭐⭐⭐(长期免费首选)
Google 的 Gemini API 提供免费 Tier,最大的优势是没有总量上限——只要你不超过每分钟的速率限制,理论上可以一直免费用。
- 前往 Google AI Studio 获取 API Key
- 配置 OpenClaw:
openclaw onboard # 选择 Custom API Provider # base_url: https://generativelanguage.googleapis.com/v1beta/openai # API Key: 填入你的 Key # model: gemini-2.0-flashRPM = 每分钟请求数,TPM = 每分钟 token 数
- 无总量限制,不会”用完”
- Gemini Flash 速度极快
- 多模态支持(图片、视频理解)
- 超长上下文(Gemini 3 Pro 支持 200 万 token)
- 速率限制较严(免费 Tier 的 RPM 不高)
- 国内访问可能有延迟
- 中文能力不如 DeepSeek
- 免费 Tier 的请求数据可能被 Google 用于模型改进
需要长期免费方案的个人用户、英文为主的任务场景、需要多模态能力的项目。
推荐指数:⭐⭐⭐⭐(模型最全)
Ofox 是 API 聚合平台,注册赠送免费额度。和前两种方案最大的区别是:一份额度可以用所有模型——GPT、Claude、Gemini、DeepSeek,100+ 模型随便切换。
- 前往 Ofox 注册账号,获取 API Key
- 配置 OpenClaw:
openclaw onboard # 选择 Custom API Provider # base_url: https://api.ofox.ai/v1 # API Key: 填入你的 Ofox Key # model: anthropic/claude-sonnet-4.6(或任意支持的模型)- 一个 Key 用所有模型,不用到处注册
- 可以在免费额度内体验 Claude、GPT 等海外模型
- 国内有加速节点,延迟低
- OpenAI 兼容协议,配置简单
- 免费额度有限,用完需充值
- 依赖第三方平台
想一次体验多种模型的用户、需要使用海外模型(Claude/GPT)的开发者、不想到处注册账号的懒人。
推荐指数:⭐⭐⭐⭐(速度之王)
Groq 是做 AI 推理加速芯片的公司,提供免费的 API 调用。它的杀手锏是速度——Groq 的推理速度是普通 GPU 方案的 10 倍以上,体感上几乎是瞬间出结果。
- 前往 Groq Console 注册账号
- 创建 API Key
- 配置 OpenClaw:
openclaw onboard # 选择 Custom API Provider # base_url: https://api.groq.com/openai/v1 # API Key: 填入你的 Groq Key # model: llama-3.3-70b-versatile- 推理速度碾压所有云 API(token 生成速度 500+ token/s)
- Llama 3.3 70B 效果接近 GPT-4o
- 免费额度对个人使用足够
- 只支持开源模型(无 GPT、Claude、Gemini)
- 有每日请求次数限制
- 国内直连可能有延迟
- 模型选择相对有限
对响应速度有极致要求的场景、开源模型拥护者、需要实时交互体验的项目。
推荐指数:⭐⭐⭐⭐(完全离线免费)
终极方案——把模型跑在自己电脑上,彻底告别 API 费用。Ollama 让本地运行大模型变得和安装 App 一样简单。
- 安装 Ollama:
# macOS brew install ollama # Linux curl -fsSL https://ollama.com/install.sh | sh- 下载模型:
# 推荐:Qwen2.5 14B(中文最好的本地模型) ollama pull qwen2.5:14b # 或者:Llama 3.3 8B(英文全能) ollama pull llama3.3:8b- 启动 Ollama 并配置 OpenClaw:
ollama serve # Ollama 默认监听 http://localhost:11434 openclaw onboard # 选择 Custom API Provider # base_url: http://localhost:11434/v1 # API Key: ollama(随便填,本地不校验) # model: qwen2.5:14b- 永久免费,无任何 API 费用
- 完全离线,断网也能用
- 隐私最好,数据不出本机
- 无速率限制,想跑多少跑多少
- 依赖硬件配置,低配电脑只能跑小模型
- 小模型效果和云端大模型差距明显
- 占用本机计算资源,跑模型时电脑会变慢
- 不支持 GPT、Claude 等闭源模型
有高配电脑(尤其是 Mac M 系列)的用户、对数据隐私有严格要求的场景、想离线使用 AI Agent 的人。
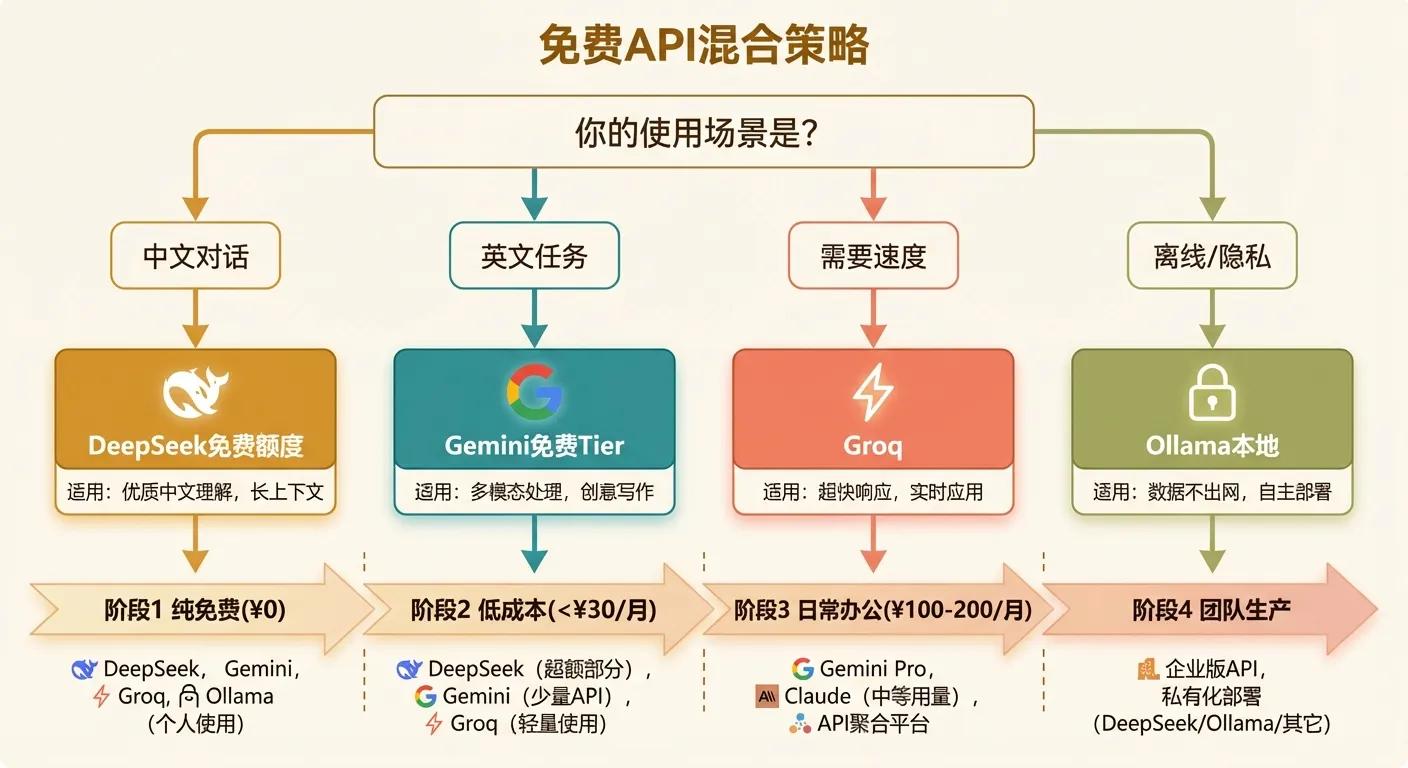
聪明的做法不是只用一种方案,而是组合使用,让免费额度覆盖尽可能多的场景。
日常中文对话 → DeepSeek 免费额度(效果好) 简单英文任务 → Gemini 免费 Tier(无限量) 需要快速响应 → Groq(速度快) 离线或隐私场景 → Ollama 本地(零成本)这套组合可以覆盖 90% 的日常使用场景,完全不花钱。
日常任务 → Gemini Flash 免费 Tier(不限量,够用) 中文重任务 → DeepSeek V3.2(免费额度 + 按量付费,极便宜) 复杂推理 → 聚合平台调用 Claude Sonnet(注册赠送额度 + 按需充值)这套组合月成本通常在 30 元以内,大部分场景不花钱。
OpenClaw 支持 fallback 模型链,自动在多个模型间切换:
ai: # 主模型:Gemini 免费 Tier(日常使用) provider: custom base_url: https://generativelanguage.googleapis.com/v1beta/openai api_key: your-gemini-key model: gemini-2.0-flash # Fallback:DeepSeek(Gemini 限流时切换) fallback: - provider: custom base_url: https://api.deepseek.com api_key: your-deepseek-key model: deepseek-chat免费方案很香,但它有明确的天花板。以下信号出现时,说明该考虑付费了:
- 频繁触发速率限制:Gemini 免费 Tier 的 15 RPM 已经不够用了
- 任务复杂度上升:需要 Claude Opus 或 GPT-5.4 级别的推理能力
- 开始用于生产:免费方案没有 SLA 保障,宕机没人管
- 团队多人使用:免费额度被多人分摊,消耗加快
- 需要稳定性:免费政策随时可能变化
阶段 1(免费)→ DeepSeek + Gemini 免费 Tier,零成本跑通 阶段 2(低成本)→ DeepSeek 按量付费,月 30 元以内 阶段 3(日常办公)→ 聚合平台,混合模型策略,月 100-200 元 阶段 4(团队/生产)→ 聚合平台团队版,统一管理,按团队规模付费每个阶段都可以长期停留,不必急着升级。关键是根据自己的实际需求选择——够用就行,别为用不到的能力买单。
- 80/20 法则:80% 的任务用便宜模型就够了,只有 20% 需要旗舰模型
- 模型分级:简单任务用 DeepSeek/Gemini Flash,复杂任务才上 Claude/GPT
- 设置预算上限:OpenClaw 支持配置 token 预算,避免 Agent 循环调用导致成本失控
- 定期复盘:每月检查 API 用量,砍掉不必要的高成本调用
推荐优先级:DeepSeek 免费额度(中文最强)> Gemini 免费 Tier(无总量限制)> Ofox 注册赠送(模型最全)> Groq(速度最快)> Ollama 本地(完全离线)。
先用多个免费方案轮换延长免费期,确认哪个模型最适合自己后对应充值。DeepSeek 按量付费极便宜(约 ¥2/百万输入 token),月成本通常不超过 30 元。
目前可以。没有总量上限,只有速率限制(RPM/TPM)。但 Google 有权调整政策,建议不要完全依赖单一方案。
可以。OpenClaw 支持 fallback 模型链,主模型触发速率限制时自动切换到备用模型。
14B 参数的本地模型效果大约相当于 GPT-3.5 到 GPT-4 之间。70B 参数模型效果接近 GPT-4o,但需要 48GB+ 内存。简单对话和基础编程够用,复杂推理仍有差距。
快速行动清单:
- 5 分钟跑通:注册 DeepSeek,拿到 API Key,配置 OpenClaw
- 长期免费:注册 Gemini API,配置为 fallback 模型(无限量免费)
- 体验海外模型:注册 Ofox,用赠送额度试试 Claude 和 GPT
- 极致速度:注册 Groq,体验高速推理
- 离线备用:装个 Ollama,下载 Qwen2.5,断网也能用
之后需不需要付费、什么时候付费,取决于实际需求。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/249991.html